







Ankus ýá£ÝÆêýåîÛ░£ýä£
- 2. 1 01. ýá£ÝÆê Û░£Ù░£ Ù░░Û▓¢ 02. ýá£ÝÆê ýåîÛ░£(ankus) TableofContents 03. Ù│äý▓¿
- 3. 2 ýáòÙ│┤Û©░ýêá(IT)ýØÿ Ù░£Ùï¼Ùí£ ÙïñýûæÝò£ ÝÿòÝâ£ýØÿ ÙîÇýܮكë Ùì░ýØ┤Ýä░ÙÑ╝ ýïáýåìÝ×ê ý▓ÿÙª¼Ýò┤ýò╝ ÝòÿÙèö ÝÖÿÛ▓¢ýùÉ ýºüÙ®┤ ÝòÿÛ▓î ÙÉÿÙ®┤ýä£, Ù╣àÙì░ýØ┤Ýä░ 1ýä©ÙîÇýùÉýä£Ùèö Ùì░ýØ┤Ýä░ýØÿ 3Û░ÇýºÇ Ýè╣ýºò (Volume, Velocity, Variety)ýùÉ ýú╝Ù¬®ÝòÿÛ▓î ÙÉÿýùêýèÁÙïêÙïñ. ýØ┤Ùƒ¼Ýò£ Ù░░Û▓¢ýåìýùÉýä£ ÔÇÿÝòÿÙæíÛ│╝ Û░ÖýØÇ Ù╣àÙì░ýØ┤Ýä░ ýï£ýèñÝà£(ýØ©ÝöäÙØ╝)ÔÇÖÙÂäýò╝Û░Ç Ù╣áÙÑ┤Û▓î Ù░£ýáäÝûêýèÁÙïêÙïñ. 1.1Ù╣àÙì░ýØ┤Ýä░ýØÿÙ│ÇÝÖö Ù╣àÙì░ýØ┤Ýä░ýØÿ 3V
- 4. 3 Ù╣àÙì░ýØ┤Ýä░ 2ýä©ÙîÇýùÉýä£Ùèö Ùì░ýØ┤Ýä░ýùÉ ýê¿ýû┤ý×êÙèö ÔÇÿÛ░Çý╣ÿÔÇÖÙÑ╝ ý░¥Ùèö ýØ╝ ýùÉ ýºæýñæÝò®ÙïêÙïñ. ÙîÇýܮكëýØÿ Ùì░ýØ┤Ýä░ÙÑ╝ ýêÿýºæÝòÿÛ│á Û┤ÇÙª¼ÝòÿÙìÿ Ù¼©ýá£Ùèö Û©░ýùàýØ┤ Ù│┤ý£áÝò£ Ùì░ýØ┤Ýä░ýùÉýä£ ÝòÁýï¼ Û░Çý╣ÿÙÑ╝ ý░¥ýòäÙé┤Ùèö Ù¼©ýá£Ùí£ Ù░£ýáäÝûêýèÁÙïêÙïñ. ýØ┤ýá£Ùèö Ùì░ýØ┤Ýä░Ùí£ÙÂÇÝä░ ýê¿Û▓¿ýºä ÔÇÿÛ░Çý╣ÿÔÇÖÙÑ╝ ý░¥Û©░ ý£äÝò£ ÔÇÿÙì░ýØ┤Ýä░ ÙÂäýäØ Û©░ýêáÔÇÖýØ┤ ÝòäýÜö Ýò£ Ùòîý×àÙïêÙïñ. 1.1Ù╣àÙì░ýØ┤Ýä░ýØÿÙ│ÇÝÖö Ù╣àÙì░ýØ┤Ýä░ýØÿ 4V KNOWLEDGE
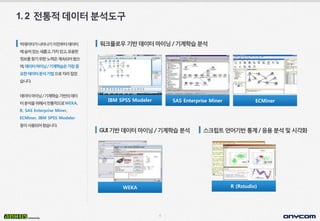
- 5. 4 1.2 ýáäÝåÁýáüÙì░ýØ┤Ýä░ÙÂäýäØÙÅäÛÁ¼ GUIÛ©░Ù░ÿÙì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÙÂäýäØ ýèñÝü¼Ùª¢Ýè©ýû©ýû┤Û©░Ù░ÿÝåÁÛ│ä/ýØæýÜ®ÙÂäýäØÙ░Åýï£Û░üÝÖö ýøîÝü¼ÝöîÙí£ýÜ░Û©░Ù░ÿÙì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÙÂäýäØ IBM SPSS Modeler SAS Enterprise Miner ECMiner WEKA R (Rstudio) Ù╣àÙì░ýØ┤Ýä░Û░ÇÙéÿÝâÇÙéÿÛ©░ýØ┤ýáäÙÂÇÝä░Ùì░ýØ┤Ýä░ ýùÉýê¿ýû┤ý×êÙèöýâêÙí¡Û│á,Û░Çý╣ÿý×êÛ│á,ý£áýÜ®Ýò£ ýáòÙ│┤ÙÑ╝ý░¥Û©░ý£äÝò£Ùà©ÙáÑýØÇÛ│äýåìÙÉÿýû┤ýÖöý£╝ Ù®░,Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁýØÇÛ░Çý×Ñýñæ ýÜöÝò£Ùì░ýØ┤Ýä░ÙÂäýäØÛ©░Ù▓òý£╝Ùí£ý×ÉÙª¼ý×íýòÿ ýèÁÙïêÙïñ. Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÛ©░Ù░ÿýØÿÙì░ýØ┤ Ýä░ÙÂäýäØýØäý£äÝò┤ýä£ýáäÝåÁýáüý£╝Ùí£WEKA, R, SAS Enterprise Miner, ECMiner, IBM SPSS Modeler Ùô▒ýØ┤ýé¼ýÜ®ÙÉÿýû┤ýÖöýèÁÙïêÙïñ.
- 6. 5 1.3 ýáäÝåÁýáüÙì░ýØ┤Ýä░ÙÂäýäØÙÅäÛÁ¼ýØÿ Ýò£Û│ä Ùì░ýØ┤Ýä░ ýáäý▓ÿÙª¼ ýÜöý▓¡ ÝòÿÙæí Û©░Ù░ÿ Ù╣àÙì░ýØ┤Ýä░ ýØ©ÝöäÙØ╝ ÔǪ namenode datanode-1 datanode-2 datanode-3 datanode-n ýáäý▓ÿÙª¼ Ùì░ýØ┤Ýä░ ýÂöý£ Û┤ÇÙª¼ Ùì░ýØ┤Ýä░ýêÿýºæÙ░ÅÙÂäýäØýä£Ù▓ä ýáäÝåÁýáü ÙÅäÛÁ¼ÙÑ╝ ýØ┤ýÜ®Ýò£ Ù╣àÙì░ýØ┤Ýä░ ÙÂäýäØ ÙÂäýé░/Ù│æÙá¼ý▓ÿÙª¼ýØ©ÝöäÙØ╝ ýùÉýä£ýØÿÙÂäýäØÝòäýÜö ÔÇó ÙÂäýäØÝòÿÛ│áý×É ÝòÿÙèö Ùì░ýØ┤Ýä░ýØÿ ýáäý▓ÿÙª¼ Ù░Å ýÂöý£ ý×æýùàÝòäýÜö ÔÇó ÙÂäýäØ ýêÿÝûëýØä ý£äÝò£ Ù│äÙÅäýØÿ ýä£Ù▓ä ÝòäýÜö ÔÇó ÙÂäýäØ ýä£Ù▓ä ýܮكëýØä ý┤êÛ│╝ÝòÿÙèö ÙîÇýܮكëÙì░ýØ┤ Ýä░ ý▓ÿÙª¼ÙÂêÛ░Ç Hadoop Û©░Ù░ÿýØÿ ÙÂäýé░ Ù╣àÙì░ýØ┤Ýä░ ÝÖÿÛ▓¢ ýáäÝåÁýáüÙì░ýØ┤Ýä░ÙÂäýäØÙÅäÛÁ¼ÙôñýØÇÙÂäýäØÙÅäÛÁ¼ Û░Çýäñý╣ÿÙÉ£Û░£Ù│äýä£Ù▓äýùÉýä£ÙÂäýäØýØ┤ýØ┤Ùú¿ýû┤ ýºæÙïêÙïñ. ÝòÿÙæíÛ│╝Û░ÖýØÇÙ╣àÙì░ýØ┤Ýä░ýØ©ÝöäÙØ╝ýÖÇÙì░ýØ┤Ýä░ ýù░Û│äÙèöÛ░ÇÙèÑÝòÿýºÇÙºî,ÙÂäýäØý×Éý▓┤ÙÑ╝ÝòÿÙæíýØÿ ÙÂäýé░┬ÀÙ│æÙá¼ý▓ÿÙª¼ýØ©ÝöäÙØ╝ýùÉýä£ýêÿÝûëÝòÿýºÇÙ¬╗ ÝòÿÛ│á,Ù│äÙÅäýØÿÙÂäýäØýä£Ù▓äýùÉýä£ýêÿÝûëÝò┤ýò╝ Ýò®ÙïêÙïñ. ýØ┤ÙòîÙ¼©ýùÉ,ÝòÿÙæíÛ©░Ù░ÿýØÿÙ╣àÙì░ýØ┤Ýä░ÝÖÿÛ▓¢ ýùÉýä£ýºüýáæýÜ┤ýÜ®Û░ÇÙèÑÝò£ÙÂäýé░Û©░Ù░ÿÙì░ýØ┤ Ýä░ÙÂäýäØÙÅäÛÁ¼ÙôñýØÿÝòäýÜöýä▒ýØ┤ÙîÇÙæÉÙÉÿýùêýèÁ ÙïêÙïñ.
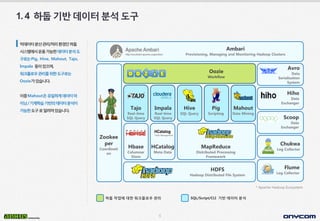
- 7. 6 Hbase Columnar Store HCatalog Meta Data MapReduce Distributed Processing Framework 1.4 ÝòÿÙæíÛ©░Ù░ÿÙì░ýØ┤Ýä░ÙÂäýäØÙÅäÛÁ¼ * Apache Hadoop Ecosystem Ambari Provisioning, Managing and Monitoring Hadoop Clusters Oozie Workflow HDFS Hadoop Distributed File System Tajo Real-time SQL Query Impala Real-time SQL Query Hive SQL Query Pig Scripting Mahout Data Mining Zookee per Coordinati on Avro Data Serialization System Hiho Data Exchanger Scoop Data Exchanger Chukwa Log Collector Flume Log Collector ÝòÿÙæí ý×æýùàýùÉ ÙîÇÝò£ ýøîÝü¼ÝöîÙí£ýÜ░ Û┤ÇÙª¼ SQL/Script/CLI Û©░Ù░ÿ Ùì░ýØ┤Ýä░ ÙÂäýäØ Ù╣àÙì░ýØ┤Ýä░ÙÂäýé░Û┤ÇÙª¼/ý▓ÿÙª¼ÝÖÿÛ▓¢ýØ©ÝòÿÙæí ýï£ýèñÝà£ýùÉýä£ýÜ┤ýÜ®Û░ÇÙèÑÝò£Ùì░ýØ┤Ýä░ÙÂäýäØÙÅä ÛÁ¼Ùí£ÙèöPig, Hive, Mahout, Tajo, Impala Ùô▒ýØ┤ý×êý£╝Ù®░, ýøîÝü¼ÝöîÙí£ýÜ░Û┤ÇÙª¼ÙÑ╝ý£äÝò£ÙÅäÛÁ¼Ùí£Ùèö OozieÛ░Çý×êýèÁÙïêÙïñ. ýØ┤ýñæMahoutýØÇý£áýØ╝ÝòÿÛ▓îÙì░ýØ┤Ýä░Ùºê ýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÛ©░Ù░ÿýØÿÙì░ýØ┤Ýä░ÙÂäýäØýØ┤ Û░ÇÙèÑÝò£ÙÅäÛÁ¼Ùí£ýòîÙáñýá©ý×êýèÁÙïêÙïñ.
- 8. 7 1.5 ÝòÿÙæíÛ©░Ù░ÿÙì░ýØ┤Ýä░ÙÂäýäØÙÅäÛÁ¼ýØÿý£ÝÿäÙ░░Û▓¢ ÝòÿÙæíÛ©░Ù░ÿýØÿÙÂäýäØÙÅäÛÁ¼ÙôñýØÇýáäÝåÁýáüÙì░ýØ┤ Ýä░ÙÂäýäØÙÅäÛÁ¼ýÖÇÛ░ÖýØ┤Ù│äÙÅäýØÿÙÂäýäØýä£Ù▓ä ÙÑ╝ýØ┤ýÜ®ÝòÿýºÇýòèÛ│á,ÝòÿÙæíÛ©░Ù░ÿÙ╣àÙì░ýØ┤Ýä░ ýØ©ÝöäÙØ╝Ùé┤ýùÉýä£ÙÂäýäØýØäýºüýáæýêÿÝûëÝòáýêÿ ý×êÙÅäÙíØÝòÿÙèöÛ©░ÙèÑýØäýá£Û│ÁÝò®ÙïêÙïñ. Ýè╣Ý×ê,ÝòÿÙæíÛ©░Ù░ÿÙ╣àÙì░ýØ┤Ýä░ýØ©ÝöäÙØ╝ýùÉýä£ Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÙÂäýäØýØ┤Û░ÇÙèÑ Ýò£ÙÅäÛÁ¼Ùí£mahoutýØÿÝò£Û│äýáÉýØäÛÀ╣Ù│Á ÝòÿÛ©░ý£äÝò£ankusÛ░ÇÛ░£Ù░£ÙÉÿýùêýèÁÙïêÙïñ. Ùì░ýØ┤Ýä░ ýáäý▓ÿÙª¼ Ù░Å ýÂöý£ Ùì░ýØ┤Ýä░ ÙÂäýäØ Ùô▒ ýòîÛ│áÙª¼ýªÿ ýêÿÝûë ýáäÝåÁýáüÙÅäÛÁ¼Û©░Ù░ÿýØÿÙì░ýØ┤Ýä░ÙÂäýäØ Ùì░ýØ┤Ýä░ýêÿýºæÙ░ÅÙÂäýäØýä£Ù▓ä ÝòÿÙæíýØ©ÝöäÙØ╝Û©░Ù░ÿýØÿÙì░ýØ┤Ýä░ÙÂäýäØ ÔÇó ýáäý▓ÿÙª¼ Ù░Å ýÂöý£ Ùô▒ ý▓ÿÙª¼Û©░Ù░ÿ Ùì░ýØ┤Ýä░ ÙÂäýäØ ÙÅäÛÁ¼ ÔÇó Ùì░ýØ┤Ýä░ ÙºêýØ┤ÙïØ/ Û©░Û│ä ÝòÖýèÁ Û©░Ù░ÿ Ùì░ýØ┤Ýä░ ÙÂäýäØ ÙÅäÛÁ¼ ÝòÿÙæí Û©░Ù░ÿ Ù╣àÙì░ýØ┤Ýä░ ýØ©ÝöäÙØ╝ ÔǪ namenode datanode-1 datanode-2 datanode-3 datanode-n Û┤ÇÙª¼ Hadoop Û©░Ù░ÿýØÿ ÙÂäýé░ Ù╣àÙì░ýØ┤Ýä░ ÝÖÿÛ▓¢
- 9. 8 2.1 ankus ýøîÝü¼ÝöîÙí£ýÜ░Û©░Ù░ÿÝòÿÙæí ÙÂäýäØÙ░ÅýÜ┤ýÿüÛ┤ÇÙª¼ ÙÂäýé░Û©░Ù░ÿÙì░ýØ┤Ýä░ÙºêýØ┤ÙïØÙ░Å Û©░Û│äÝòÖýèÁÙÂäýäØýòîÛ│áÙª¼ýªÿ ÝòÿÙæíÝü┤Ùƒ¼ýèñÝä░Û┤ÇÙª¼ Ù░ÅÙ¬¿ÙïêÝä░Ùºü ÙÂäýé░Ù╣àÙì░ýØ┤Ýä░ÝÖÿÛ▓¢ýùÉýä£ýÜ┤ýÜ®Û░ÇÙèÑÝò£ ýø╣ Û©░Ù░ÿ Ù╣àÙì░ýØ┤Ýä░ ÙºêýØ┤ÙïØ ÙÅäÛÁ¼ ´â╝ ÙÂäýé░Û©░Ù░ÿÙì░ýØ┤Ýä░ÙºêýØ┤ÙïØÙ░ÅÛ©░Û│äÝòÖýèÁ ÙÂäýäØýòîÛ│áÙª¼ýªÿÛ©░ýêá ´â╝ ýø╣UI Û©░Ù░ÿýøîÝü¼ÝöîÙí£ýÜ░ý×æýä▒Ù░ÅÛ┤ÇÙª¼Ù¬¿Ùôê ´â╝ ÝòÿÙæíÙì░ýØ┤Ýä░Û┤ÇÙª¼Ù░Åý×æýùàýêÿÝûëÙ¬¿ÙïêÝä░Ùºü ankusÙèöÝòÿÙæíÛ©░Ù░ÿýØÿÙÂäýé░Ù╣àÙì░ýØ┤Ýä░ ÝÖÿÛ▓¢ýùÉýä£Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÙÂä ýäØýØäÝòáýêÿý×êÙÅäÙíØÝòÿÙèöýø╣Û©░Ù░ÿ Ù╣àÙì░ýØ┤ Ýä░ÙºêýØ┤ÙïØÙÅäÛÁ¼ý×àÙïêÙïñ. ankusÙèömahoutÛ│╝Û░ÖýØ┤Ùì░ýØ┤Ýä░Ùºê ýØ┤ÙïØ/Û©░Û│äÝòÖýèÁÙÂäýäØÛ©░ÙèÑýØäýá£Û│ÁÝòÿÙèö Û▓âýÖ©ýùÉÝòÿÙæíýùÉý¢öýï£ýèñÝà£ýØ©oozie, ambariýØÿ ýú╝ýÜöÛ©░ÙèÑýØäÝòÿÙéÿýØÿÝöäÙáêý×ä ýøîÝü¼ýòêýùÉýä£ýá£Û│ÁÝò¿ý£╝Ùí£ýì¿Ù╣àÙì░ýØ┤Ýä░ÙÂä ýäØýØäý£äÝò£ÝåÁÝò®ÝÖÿÛ▓¢ýØäÛÁ¼ýÂòÝòáýêÿý×êýèÁ ÙïêÙïñ.
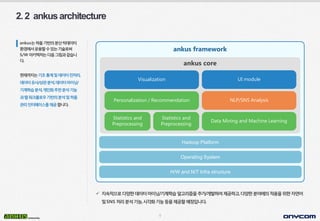
- 10. 9 ´â╝ ýºÇýåìýáüý£╝Ùí£ÙïñýûæÝò£Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁýòîÛ│áÙª¼ýªÿýØäýÂöÛ░Ç/Û░£Ù░£Ýòÿýù¼ýá£Û│ÁÝòÿÛ│á,ÙïñýûæÝò£ÙÂäýò╝ýùÉýØÿýáüýÜ®ýØäý£äÝò£ý×Éýù░ýû┤ Ù░ÅSNS ý▓ÿÙª¼ÙÂäýäØÛ©░ÙèÑ,ýï£Û░üÝÖöÛ©░ÙèÑÙô▒ýØäýá£Û│ÁÝòáýÿêýáòý×àÙïêÙïñ. ankusÙèöÝòÿÙæíÛ©░Ù░ÿýØÿÙÂäýé░Ù╣àÙì░ýØ┤Ýä░ ÝÖÿÛ▓¢ýùÉýä£ýÜ┤ýÜ®Ýòáýêÿý×êÙèöÛ©░ýêáÙí£ýì¿ S/W ýòäÝéñÝàìý▓ÿÙèöÙïñýØîÛÀ©Ùª╝Û│╝Û░ÖýèÁÙïê Ùïñ. Ýÿäý×¼Û╣îýºÇÙèöÛ©░ý┤êÝåÁÛ│äÙ░ÅÙì░ýØ┤Ýä░ýáäý▓ÿÙª¼, Ùì░ýØ┤Ýä░ý£áýé¼/ýâüÛ┤ÇÙÂäýäØ,Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/ Û©░Û│äÝòÖýèÁÙÂäýäØ,Û░£ýØ©ÝÖöýÂöý▓£ÙÂäýäØÛ©░ÙèÑ Û│╝ýø╣ýøîÝü¼ÝöîÙí£ýÜ░Û©░Ù░ÿýØÿÙÂäýäØÙ░ÅÝòÿÙæí Û┤ÇÙª¼ýØ©Ýä░ÝÄÿýØ┤ýèñÙÑ╝ýá£Û│ÁÝò®ÙïêÙïñ. ankus framework Hadoop Platform Operating System H/W and N/T Infra structure ankus core Visualization UI module Personalization / Recommendation NLP/SNS Analysis Data Mining and Machine Learning Statistics and Preprocessing Statistics and Preprocessing 2.2 ankusarchitecture
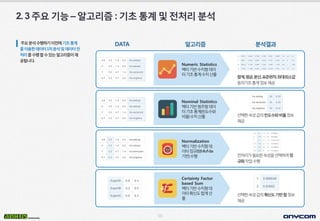
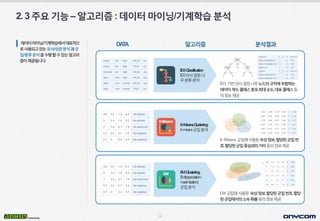
- 11. 10 DATA ÙÂäýäØÛ▓░Û│╝ýòîÛ│áÙª¼ýªÿ 2.3ýú╝ýÜöÛ©░ÙèÑÔÇôýòîÛ│áÙª¼ýªÿ:Û©░ý┤êÝåÁÛ│äÙ░Åýáäý▓ÿÙª¼ÙÂäýäØ ýú╝ýÜöÙÂäýäØýêÿÝûëÝòÿÛ©░ýØ┤ýáäýùÉÛ©░ý┤êÝåÁÛ│ä ÙÑ╝ýØ┤ýÜ®Ýò£Ùì░ýØ┤Ýä░1ý░¿ÙÂäýäØÙ░ÅÙì░ýØ┤Ýä░ýáä ý▓ÿÙª¼ÙÑ╝ýêÿÝûëÝòáýêÿý×êÙèöýòîÛ│áÙª¼ýªÿýØ┤ýᣠÛ│ÁÙÉ®ÙïêÙïñ. Numeric Statistics Ù▓íÝä░Û©░Ù░ÿýêÿý╣ÿÝÿòÙì░ýØ┤ Ýä░Û©░ý┤êÝåÁÛ│äýêÿý╣ÿýé░ý£ Ýò®Û│ä,ÝÅëÛÀá,ÙÂäýé░,Ýæ£ýñÇÝÄ©ý░¿,ýÁ£ÙîÇ┬ÀýÁ£ýåîÛ░Æ Ùô▒ýØÿÛ©░ý┤êÝåÁÛ│äýáòÙ│┤ýá£Û│Á ýäáÝâØÝò£ýåìýä▒Û░ÆýØÿÙ╣êÙÅäýêÿýÖÇÙ╣äý£¿ýáòÙ│┤ ýá£Û│Á ýäáÝâØÝò£ýåìýä▒Û░ÆýØÿÝÖòýïáÙÅäÛ©░Ù░ÿÝò®ýáòÙ│┤ ýá£Û│Á Nominal Statistics Ù▓íÝä░Û©░Ù░ÿÙ▓öýú╝ÝÿòÙì░ýØ┤ Ýä░Û©░ý┤êÝåÁÛ│ä(Ù╣êÙÅäýêÿýÖÇ Ù╣äý£¿)ýêÿý╣ÿýé░ý£ Normalization Ù▓íÝä░Û©░Ù░ÿýêÿý╣ÿÝÿòÙì░ ýØ┤Ýä░ýáòÛÀ£ÝÖö(Min/Max Û©░Ù░ÿ)ýêÿÝûë Certainty Factor based Sum Ù▓íÝä░Û©░Ù░ÿýêÿý╣ÿÝÿòÙì░ ýØ┤Ýä░ÝÖòýïáÙÅäÝò®Û│äýé░ ý£ ýáäý▓ÿÙª¼Û░ÇÝòäýÜöÝò£ýåìýä▒ýØäýäáÝâØÝòÿýù¼ýáò ÛÀ£ÝÖöý×æýùàýêÿÝûë
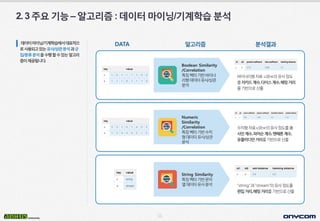
- 12. 11 2.3ýú╝ýÜöÛ©░ÙèÑÔÇôýòîÛ│áÙª¼ýªÿ:Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁ ÙÂäýäØ Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁýùÉýä£ÙîÇÝæ£ýáüý£╝ Ùí£ýé¼ýÜ®ÙÉÿÛ│áý×êÙèöý£áýé¼/ýâüÛ┤ÇÙÂäýäØÛ│╝ÛÁ░ ýºæ/ÙÂäÙÑÿÙÂäýäØýØäýêÿÝûëÝòáýêÿý×êÙèöýòîÛ│áÙª¼ ýªÿýØ┤ýá£Û│ÁÙÉ®ÙïêÙïñ. DATA ÙÂäýäØÛ▓░Û│╝ Boolean Similarity /Correlation Ýè╣ýºòÙ▓íÝä░Û©░Ù░ÿÙ░öýØ┤Ùäê Ùª¼ÝÿòÙì░ýØ┤Ýä░ý£áýé¼/ýâüÛ┤Ç ÙÂäýäØ Ù░öýØ┤ÙäêÙª¼Ýÿòý×ÉÙúî uýÖÇwýØÿý£áýé¼ýáòÙÅä ÙÑ╝ý×Éý╣┤Ùô£Û│äýêÿ,ÙïñýØ┤ýèñÛ│äýêÿ,Ýò┤Ù░ìÛ▒░Ùª¼ ÙÑ╝Û©░Ù░ÿý£╝Ùí£ýé░ý£ ýêÿý╣ÿÝÿòý×ÉÙúîuýÖÇwýØÿý£áýé¼ýáòÙÅäÙÑ╝ý¢ö ýé¼ýØ©Û│äýêÿ,Ýö╝ýû┤ýè¿Û│äýêÿ,Ùº¿Ýò┤Ýè╝Û│äýêÿ, ý£áÝü┤Ùª¼ÙööýòêÛ▒░Ùª¼ÙÑ╝Û©░Ù░ÿý£╝Ùí£ýé░ý£ ÔÇ£stringÔÇØÛ│╝ÔÇ£streamÔÇØýØÿý£áýé¼ýáòÙÅäÙÑ╝ ÝÄ©ýºæÛ▒░Ùª¼,Ýò┤Ù░ìÛ▒░Ùª¼ÙÑ╝Û©░Ù░ÿý£╝Ùí£ýé░ý£ Numeric Similarity /Correlation Ýè╣ýºòÙ▓íÝä░Û©░Ù░ÿýêÿý╣ÿ ÝÿòÙì░ýØ┤Ýä░ý£áýé¼/ýâüÛ┤Ç ÙÂäýäØ String Similarity Ýè╣ýºòÙ▓íÝä░Û©░Ù░ÿÙ¼©ý×É ýù┤Ùì░ýØ┤Ýä░ý£áýé¼ÙÂäýäØ ýòîÛ│áÙª¼ýªÿ
- 13. 12 2.3ýú╝ýÜöÛ©░ÙèÑÔÇôýòîÛ│áÙª¼ýªÿ:Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁ ÙÂäýäØ Ùì░ýØ┤Ýä░ÙºêýØ┤ÙïØ/Û©░Û│äÝòÖýèÁýùÉýä£ÙîÇÝæ£ýáüý£╝ Ùí£ýé¼ýÜ®ÙÉÿÛ│áý×êÙèöý£áýé¼/ýâüÛ┤ÇÙÂäýäØÛ│╝ÛÁ░ ýºæ/ÙÂäÙÑÿÙÂäýäØýØäýêÿÝûëÝòáýêÿý×êÙèöýòîÛ│áÙª¼ ýªÿýØ┤ýá£Û│ÁÙÉ®ÙïêÙïñ. DATA ÙÂäýäØÛ▓░Û│╝ ID3Classification ID3ýØÿýé¼Û▓░ýáòÙéÿ Ù¼┤ÙÂäÙÑÿÙÂäýäØ ID3 Û©░Ù░ÿýØÿýé¼Û▓░ýáòÙéÿÙ¼┤Ùà©Ùô£ýØÿÛÀ£ý╣ÖýùÉÙÂÇÝò®ÝòÿÙèö Ùì░ýØ┤Ýä░Û░£ýêÿ,Ýü┤Ù×ÿýèñÙÂäÝżýÁ£ÙîÇýê£ÙÅä,ÙîÇÝæ£Ýü┤Ù×ÿýèñÙô▒ ýØÿýáòÙ│┤ýá£Û│Á K-Means ÛÁ░ýºæýùÉýé¼ýÜ®ÙÉ£ýåìýä▒ýáòÙ│┤,ÝòáÙï╣ÙÉ£ÛÁ░ýºæÙ▓ê Ýÿ©,ÝòáÙï╣ÙÉ£ÛÁ░ýºæýñæýï¼Û│╝ýØÿÛ▒░Ùª¼Ùô▒ýØÿýáòÙ│┤ýá£Û│Á EM ÛÁ░ýºæýùÉýé¼ýÜ®ÙÉ£ ýåìýä▒ýáòÙ│┤,ÝòáÙï╣ÙÉ£ÛÁ░ýºæÙ▓êÝÿ©,ÝòáÙï╣ ÙÉ£ÛÁ░ýºæýùÉýä£ýØÿýåîýåìÝÖòÙÑáÙô▒ýØÿýáòÙ│┤ýá£Û│Á K-MeansClustering K-meansÛÁ░ýºæÙÂäýäØ EMClustering EM(expectation- maximization) ÛÁ░ýºæÙÂäýäØ ýòîÛ│áÙª¼ýªÿ
- 14. 13 2.3ýú╝ýÜöÛ©░ÙèÑÔÇôýòîÛ│áÙª¼ýªÿ:Ùº×ýÂñÝÿòýÂöý▓£ÙÂäýäØ ýÿ¿ÙØ╝ýØ©ýç╝ÝòæÙ¬░,ÛÀ╣ý×ÑÙô▒ý¢ÿÝàÉý©áý£áÝåÁÙÅä Ù®öýØ©ýùÉýä£ýáüýÜ®Û░ÇÙèÑÝò£ýé¼ýÜ®ý×ÉÙº×ýÂñÝÿò ýòäýØ┤Ýà£ýÂöý▓£ÙÂäýäØýòîÛ│áÙª¼ýªÿýØ┤ýá£Û│ÁÙÉ® ÙïêÙïñ. DATA ÙÂäýäØÛ▓░Û│╝ýòîÛ│áÙª¼ýªÿ Content based Similarity ý¢ÿÝàÉý©áÙé┤ýܮ۩░Ù░ÿ(content- based collaborative filtering)ýâüÛ┤Çýä▒ÙÂäýäØ ý¢ÿÝàÉý©áÛ░äýØÿý£áýé¼ÙÅäýá£Û│Á ýé¼ýÜ®ý×ÉýÖÇýòäýØ┤Ýà£ýØÿý£áýé¼ÙÅäýá£Û│Á ýòäýØ┤Ýà£Û░äýØÿý£áýé¼ÙÅäýá£Û│Á CF based Similarity ÝÿæÙáÑýáüýù¼Û│╝collaborative filtering)Û©░Ù░ÿýé¼ýÜ®ý×É/ýòäýØ┤ Ýà£ýâüÛ┤Çýä▒ÙÂäýäØ User based Recommendation ýé¼ýÜ®ý×ÉýâüÛ┤Çýä▒Û©░Ù░ÿ ýÂöý▓£ÙÂäýäØ Item based Recommendation ýòäýØ┤Ýà£ýâüÛ┤Çýä▒Û©░Ù░ÿ ýÂöý▓£ÙÂäýäØ ýé¼ýÜ®ý×ÉÛ░äýØÿý£áýé¼ÙÅäýá£Û│Á
- 15. 14 2.3ýú╝ýÜöÛ©░ÙèÑÔÇôÛ©░ÝâÇ:ÝòÿÙæíýØ©ÝöäÙØ╝Û┤ÇÙª¼ Ù░ÅÙ¬¿ÙïêÝä░Ùºü ankusýùÉýä£Ùèöýø╣ýØ©Ýä░ÝÄÿýØ┤ýèñÙÑ╝ÝåÁÝòÿ ýù¼ÝòÿÙæíÙÂäýäØý×æýùàýØäýøîÝü¼ÝöîÙí£ýÜ░Û©░Ù░ÿý£╝ Ùí£Û┤ÇÙª¼Ýòáýêÿý×êý£╝Ù®░,HDFSÙé┤ýØÿÙÂäýé░ ÝîîýØ╝Û┤ÇÙª¼Ù░ÅÝòÿÙæíý×æýùàýØÿýêÿÝûë/ýóàÙúîýâü ÝÖ®ýØäÙ¬¿ÙïêÝä░ÙºüÝòáýêÿý×êýèÁÙïêÙïñ. ýø╣ýøîÝü¼ÝöîÙí£ýÜ░Û©░Ù░ÿÝòÿÙæíÙÂäýäØý×æýùàÛ┤ÇÙª¼ ´éº ýø╣Ù©îÙØ╝ýÜ░ýáÇýùÉýä£Ùô£Ù×ÿÛÀ©ýòñÙô£Ùí¡ýØäÝåÁÝòÿýù¼ÙÂäýäØýòîÛ│áÙª¼ýªÿýØäýäáÝâØÝòÿÛ│á,ÙÂäýäØý×æýùà ýØÿýêÿÝûëýøîÝü¼ÝöîÙí£ýÜ░ÙÑ╝ýäñÛ│ä ´éº ÙÂäýäØýòîÛ│áÙª¼ýªÿýØÿýâüýä©ÝîîÙØ╝Ù»©Ýä░ýäñýáòýØäý£äÝò£ýØ©Ýä░ÝÄÿýØ┤ýèñ ´éº ýäñÛ│äÙÉ£ý×æýùàýØÿýáÇý×Ñ/Ùí£Ùô£Ù░ÅÝòÿÙæíÝü┤Ùƒ¼ýèñÝä░ýù░ÙÅÖýïñÝûë Ùì░ýØ┤Ýä░ ÝîîýØ╝ Û┤ÇÙª¼ÙÑ╝ ý£äÝò£ HDFS ÝîîýØ╝ Ù©îÙØ╝ýÜ░ýáÇ ´éº ý£êÙÅäýÜ░ÝîîýØ╝Ù©îÙØ╝ýÜ░ýáÇýÖÇÙÅÖýØ╝Ýò£UI/UXÙÑ╝ÝåÁÝò£HDFSÙé┤ÝîîýØ╝Û┤ÇÙª¼ýØ©Ýä░ÝÄÿýØ┤ýèñ ´éº ÝîîýØ╝Ù│Áýé¼,ýØ┤ÙÅÖ,Ù│ÇÛ▓¢,ýùàÙí£Ùô£,ÙïñýÜ┤Ùí£Ùô£,ýé¡ýá£Ùô▒ýØÿÛ┤ÇÙª¼ ÝòÿÙæí ÙÂäýäØ ý×æýùàýùÉ ÙîÇÝò£ ýïñÝûë/ýóàÙúî Ù¬¿ÙïêÝä░Ùºü ´éº ÙîÇýï£Ù│┤Ùô£ÙÑ╝ÝåÁÝò£ýïñÝûë/ýóàÙúîÙ░ÅýïñÝî¿Ùô▒ÝòÿÙæíý×æýùàýØÿýêÿÝûëýâüÝÖ®ýØäÙ¬¿ÙïêÝä░Ùºü ´éº ÝòÿÙæíý×æýùàýùÉÙîÇÝò£ýêÿÝûëýØ╝ý×É,ýåîýÜöýï£Û░ä,ýºäÝûëÙ╣äý£¿Ùô▒ýØäÝÖòýØ© ´éº Ùéáýº£ÙÿÉÙèöýøîÝü¼ÝöîÙí£ýÜ░ýØ┤ÙªäýØäÝåÁÝòÿýù¼ýêÿÝûëý×æýùàÛ▓Çýâë ´éº ýùÉÙƒ¼Ù░ÅýïñÝûëÙí£ÛÀ©ÝÖòýØ©Ù░ÅÙÂäýäØ
- 16. 15 2.3ýú╝ýÜöÛ©░ÙèÑÔÇôÛ©░ÝâÇ:ýé¼ýÜ®ý×ÉÛ┤ÇÙª¼ ankusýùÉýä£Ùèöýé¼ýÜ®ý×ÉÛ┤ÇÙª¼Ù░ÅÛ│äýáòÙ│┤ýòê ýØäý£äÝòÿýù¼ÝÜîýøÉÛ░Çý×à,ýé¼ýÜ®ý×ÉÛ│äýáòÙ░ÅÙ╣äÙ░Ç Ù▓êÝÿ©ý░¥Û©░Û©░ÙèÑÛ│╝Û┤ÇÙª¼ý×ÉÛ░Çýé¼ýÜ®ý×ÉÙôñýØÿ ÛÂîÝò£Ù░ÅÙô▒Û©ëýØä Û┤ÇÙª¼Ýòáýêÿý×êýèÁÙïêÙïñ. ýé¼ýÜ®ý×ÉÛ┤ÇÙª¼ÙÑ╝ý£äÝò£ÝÜîýøÉÛ░Çý×àÛ©░ÙèÑ ´éº ýé¼ýÜ®ý×ÉýØ┤Ùªä,ýØ┤Ù®öýØ╝,Ù╣äÙ░ÇÙ▓êÝÿ©Ýò¡Ù¬®ýá£Û│Á ´éº ýé¼ýÜ®ý×ÉÛ┤ÇÙª¼ÙÑ╝ý£äÝò£ýÁ£ýåîÝòäýÜöÝò£ýáòÙ│┤Ùºîý×àÙáÑÙ░øýòäÙ╣áÙÑ©ÝÜîýøÉÛ░Çý×àÛ©░ÙèÑýá£Û│Á ýé¼ýÜ®ý×É Û│äýáò Ù░Å Ù╣äÙ░ÇÙ▓êÝÿ© ý░¥Û©░ Û©░ÙèÑ ´éº ýØ┤Ù®öýØ╝Û│╝Ù╣äÙ░ÇÙ▓êÝÿ©ÙÑ╝ýé¼ýÜ®Ýòÿýù¼ýé¼ýÜ®ý×ÉÛ│äýáòý░¥Û©░Û©░ÙèÑýá£Û│Á ´éº ýé¼ýÜ®ý×ÉÛ│äýáòÛ│╝ýØ┤Ù®öýØ╝ýØäýé¼ýÜ®Ýòÿýù¼Ù╣äÙ░ÇÙ▓êÝÿ©ý░¥Û©░Û©░ÙèÑýá£Û│Á ýé¼ýÜ®ý×É Û│äýáòÙôñýØä Û┤ÇÙª¼ÝòÿÙèö ýé¼ýÜ®ý×É Û┤ÇÙª¼ ´éº Û┤ÇÙª¼ý×ÉÛ│äýáòÙºîýé¼ýÜ®Û░ÇÙèÑ ´éº Ù¬¿Ùôáýé¼ýÜ®ý×ÉÙôñýØäÛ┤ÇÙª¼ ´éº ýí░Û▒┤ýùÉÙö░ÙÑ©ýé¼ýÜ®ý×ÉÛ▓ÇýâëÛ©░ÙèÑ ´éº ýé¼ýÜ®ý×ÉÛÂîÝò£Ù░ÅÙô▒Û©ëÙ│ÇÛ▓¢Û┤ÇÙª¼
- 17. 16 ankus mahout ý×àÙáÑÝîîýØ╝ ´éº ÝàìýèñÝè©ÝÿòÝâ£ýØÿý×àÙáÑÝîîýØ╝ýùÉÙ│äÙÅäýØÿýáäý▓ÿÙª¼ý×æýùàýùå ýØ┤ÙÂäýäØýêÿÝûëÛ░ÇÙèÑ ´éº ÙÂäýäØýØäÝòÿÛ©░ý£äÝò┤ýä£Ùèöý×àÙáÑÝîîýØ╝ýØäSequence ÝîîýØ╝ ÝÿòÝâ£Ùí£Ù│ÇÝÖÿÝòäýÜö ÙÂäýäØ ´éº ýøÉÙ│©ýäáÝâØÝòÿýù¼ýâêÙí£ýÜ┤Ùì░ýØ┤Ýä░ÝîîýØ╝ýØäýâØýä▒ÝòÿýºÇýòè Û│áÙÂäýäØýêÿÝûë ´éº Ùì░ýØ┤Ýä░ÝîîýØ╝Ùí£ÙÂÇÝä░ÙÂäýäØÝòÿÛ│áý×ÉÝòÿÙèöýåìýä▒ÙºîýØä ´éº ýøÉÙ│©Ùì░ýØ┤Ýä░ÝîîýØ╝Ùí£ÙÂÇÝä░ÙÂäýäØÝòÿÛ│áý×ÉÝòÿÙèöýåìýä▒ý£╝Ùí£ÛÁ¼ ýä▒ÙÉ£Ùì░ýØ┤Ýä░ÝîîýØ╝ýØäýâêÙí¡Û▓îýâØýä▒Ýòÿýù¼ÙÂäýäØýØäýêÿÝûë ýØ©Ýä░ÝÄÿýØ┤ýèñ ´éº ýø╣GUI Û©░Ù░ÿýØÿýøîÝü¼ÝöîÙí£ýÜ░ÙÑ╝ýØ┤ýÜ®Ýò£ýØ©Ýä░ÝÄÿýØ┤ýèñ ´éº Û░£Ù░£/ýä£Ù▓äýºÇýïØýØ┤ÝòäýÜöÝò£CLIýñæýï¼ýØ©Ýä░ÝÄÿýØ┤ýèñ ankusÙÑ╝ ýØ┤ýÜ®Ýò£ K-means ÙÂäýäØ ýÿê mahoutýØä ýØ┤ýÜ®Ýò£ K-means ÙÂäýäØ ýÿê ankusÙèömahoutÛ│╝ÙèöÙïñÙÑ┤Û▓î,Û░£Ù░£ ýºÇýïØýØ┤ÙÂÇýí▒Ýò£Ùºêý╝ÇÝä░ÙéÿÛ©░ÝÜìý×ÉÙô▒Û©░ýí┤ ýØÿÙì░ýØ┤Ýä░ÙÂäýäØýùàÙ¼┤ÙÑ╝ÝòÿÙìÿýé¼ýÜ®ý×ÉÙôñýØ┤ Ù╣àÙì░ýØ┤Ýä░Û©░Ù░ÿýØÿÙÂäýäØýØäÙïñýûæÝòÿÛ│á,ýåÉýë¢ Û▓îýêÿÝûëÝòáýêÿý×êÙÅäÙíØÝòÿÙèöÝÖÿÛ▓¢ýØäýá£Û│Á Ýò®ÙïêÙïñ. 2.4ankusvsmahout
- 19. 18 3.1ýÂöÛ░ÇýáòÙ│┤ ýï£ýèñÝà£ýÜöÛÁ¼ýé¼Ýò¡ ÙôÇýû╝ÙØ╝ýØ┤ýäáýèñ Û©░ýêáýºÇýøÉ ankus ÝöäÙáêý×äýøîÝü¼ýÜ┤ýÿüÝÖÿÛ▓¢ýÜöÛÁ¼ ýé¼Ýò¡ý×àÙïêÙïñ. ÔÇó Java 7.0 ýØ┤ýâü ÔÇó Hadoop 1.0.3 ýØ┤ýâü ÔÇó MySQL 5.5 ýØ┤ýâü ÔÇó Tomcat 7.0 ýØ┤ýâü ÔÇó Linux OS ankusÙèöÙôÇýû╝ÙØ╝ýØ┤ýäáýèñýáòý▒àýØäÙö░ÙªàÙïêÙïñ. ÔÇó Community License ýù░ÛÁ¼ÙÿÉÙèöÙ╣äýÿüÙª¼Ù¬®ýáüý£╝Ùí£ýé¼ýÜ®ÝòÿÙèöÙ¬¿ÙôáÛ░£ýØ© ýé¼ýÜ®ý×ÉýùÉÛ▓î ýáüýÜ®ÙÉÿÙèöÙØ╝ýØ┤ýäáýèñÙí£apache 2.0, GPL v3ýØÿÛ│ÁÛ░£SW ÙØ╝ýØ┤ýäáýèñÛÀ£ýáòýØ┤ýáüýÜ®ÙÉ®Ùïê Ùïñ. ÔÇó Commercial License ýÿüÙª¼Ù¬®ýáüý£╝Ùí£ýé¼ýÜ®ÝòÿÛ▒░ÙéÿÛ│ÁÛ│Á/Û©░Û┤ÇÙô▒Û░£ýØ©ýé¼ ýÜ®ý×ÉÛ░ÇýòäÙïîÛ▓¢ýÜ░ýùÉýáüýÜ®ÙÉÿÙèöÙØ╝ýØ┤ýäáýèñý×àÙïêÙïñ.ýÂö Û░Çýáüý£╝Ùí£ýá£ÝÆêÙ░░Ýżýï£ýáüýÜ®ÙÉÿÙèöý¢öÙô£Û│ÁÛ░£Ùô▒ýØÿ Û│ÁÛ░£SWÙØ╝ýØ┤ýäáýèñýØÿÙ¼┤ýé¼Ýò¡ýØäÝÜîÝö╝ÝòÿÛ│áýïÂýØÇÛ▓¢ ýÜ░ýùÉÙÅäýáüýÜ®Û░ÇÙèÑÝò®ÙïêÙïñ. ankus frameworkÙÑ╝ ýØ┤ýÜ®Ýòÿýù¼ýâêÙí£ýÜ┤ýâüýùàýÜ®SWÙÑ╝Û░£Ù░£ÝòÿÛ▒░ÙéÿÙ»╝Û░ä/ Û│ÁÛ│ÁÝöäÙí£ýáØÝè©ýùÉýåöÙú¿ýàÿÝÿòÝâ£Ùí£ýé¼ýÜ®ÝòÿÛ│áý×ÉÝòÿÙèö Û▓¢ýÜ░ýùÉÙÅäCommercial LicenseÛ░ÇýáüýÜ®ÙÉÿýû┤ýò╝ Ýò®ÙïêÙïñ. ÙïñýØîÛ│╝Û░ÖýØÇÙïñýûæÝò£Û▓¢Ùí£ÙÑ╝ÝåÁÝò┤Û©░ýêáýºÇýøÉýØäÙ░øýØäýêÿý×êýèÁÙïêÙïñ. ÔÇó ankus Û│ÁýïØÝÖêÝÄÿýØ┤ýºÇ Û│ÁÛ░£SWýØ©ankusÙÑ╝ÙïñýÜ┤Ùí£Ùô£Ù░øÛ│á,Ù®öÙë┤Ù│äýáòýØÿýä£,ýé¼ýÜ®ý×ÉÙºñÙë┤ýû╝,ÝàîýèñÝè©ý╝ÇýØ┤ ýèñÙô▒ýØäÝÖòýØ©Ýòÿýïñýêÿý×êýèÁÙïêÙïñ. http://www.openankus.org ÔÇó ankus ÝöäÙáêý×äýøîÝü¼ÙïñýÜ┤Ùí£Ùô£ http://github.com/suhyunjeon/ankus http://github.com/suhyunjeon/ankus-web http://sourceforge.net/projects/ankus ÔÇó ankus ÝöäÙáêý×äýøîÝü¼ýáòÙ│┤ÝÖòýØ©Ù░ÅÝåáÙíáýØ┤Û░ÇÙèÑÝò£ýé¼ýÜ®ý×ÉÛÀ©Ùú╣ý×àÙïêÙïñ. http://www.facebook.com/groups/openankus http://goo.gl/d8nP81 (ÛÁ¼Û©ÇÛÀ©Ùú╣ýèñýé¼ýÜ®ý×ÉÝżك╝) ÔÇó Ùì░Ù¬¿ÙÅÖýÿüýâü Ù¼©ý×ÉÝÿòÙì░ýØ┤Ýä░ýàïý£áýé¼ÙÅä http://goo.gl/YjR05G ÔÇó Ù░öýØ┤ÙäêÙª¼ÝÿòÙì░ýØ┤Ýä░ýàïý£áýé¼ÙÅä http://goo.gl/0vp3pO ÔÇó Ù¼©ýØÿý▓ÿ ankus@openankus.org
- 20. 19 3.2ÝÜîýé¼ýåîÛ░£ ýä▒Û│ÁýáüýØ© Ù╣äýªêÙïêýèñÙí£ ýä©ýâüýØä ýØ┤Ùüîýû┤Û░ÇÙèö ýú╝ýù¡ ÔÇÿýû┤Ùïêý╗┤´╝ç ýû┤Ùïêý╗┤ ýú╝ýïØÝÜîýé¼Ùèö ýäñÙª¢ýØ┤Ù×ÿ Ýò¡ýâü ýï£ÙîÇýØÿ ýú╝ýù¡ýØ┤ ÙÉÿÛ©░ ý£äÝò┤ Ùüèý×äýùåýØ┤ Ùà©ÙáÑÝòÿÛ│á ýä▒ý×ÑÝòÿÛ│á ý×êýèÁÙïêÙïñ. ýû┤Ùïêý╗┤ýØÇ ITýùÉ ÙîÇÝò£ Û©░ýêáýáü ýáäÙ¼©ýä▒Û│╝ Û│áÛ░Øýé░ýùàýùÉ ÙîÇÝò£ ýØ┤Ýò┤ÙÑ╝ Ù░öÝâòý£╝Ùí£ Û│áÛ░ØýºÇ ýøÉýåöÙú¿ýàÿ, BCI, Application Ùô▒ ÙïñýûæÝò£ ýé░ýùà ÙÂäýò╝ ýáäÙ░ÿýùÉ Û▒©ý│É ý╗¿ýäñÝîàýùÉýä£ ýï£ýèñÝ࣠ÛÁ¼ýÂò Ù░Å ý£áýºÇ Ù│┤ýêÿýùÉ ýØ┤ÙÑ┤Û©░Û╣îýºÇ ITýÖÇ Û┤ÇÙá¿ÙÉ£ Total ServiceÙÑ╝ ýá£Û│ÁÝòÿÙ®░ Û│áÛ░ØÛ░Ç ý╣ÿ ÛÀ╣ÙîÇÝÖöýùÉ Û©░ýù¼Ýò┤ ýÖöýèÁÙïêÙïñ. ÙÿÉÝò£, Ù¬¿Ù░öýØ╝ Û┤ÇÙá¿ ÙÂäýò╝ÙÑ╝ ýñæýáÉý£╝Ùí£ SmartSolution, Smart Service, SI ÙÂäýò╝Ùí£ SmartÝò£ ýä©ýâüýùÉ Ýò£Ù░£ ýò×ýä£ ÙéÿÛ░ÇÛ©░ ý£äÝò┤ Ùüèý×äýùåÙèö Ùà©ÙáÑýØä ÝòÿÛ│á ý×êýèÁÙïêÙïñ. ýû┤Ùïêý╗┤ýØÇ ýä▒Û│ÁýáüýØ© Ù╣äýªêÙïêýèñÙí£ ýâêÙí£ýÜ┤ ýä©ýâüýØä ýØ┤Ùüîýû┤ Û░ÇÙèö ýú╝ýù¡ýØ┤ ÙÉÿÛ▓áýèÁÙïêÙïñ. ýØ©ýªØ Ù░Å ýêÿýâüÙé┤ýù¡ Û©░ýùàýáòÙ│┤ ýäñÙª¢ýØ╝:1998Ùàä 9ýøö ÝÜîýé¼Ù¬à:ýû┤Ùïêý╗┤ ýú╝ýïØÝÜîýé¼ ÙîÇÝæ£ýØ┤ýé¼:ýºÇýÿüÙºî ýºüýøÉýêÿ:200Ù¬à ýé¼ýùàÙÂäýò╝:SmartSolution/ SmartService/ SI ý£äý╣ÿýáòÙ│┤ Ù│©ýé¼ ýä£ýÜ©ýï£ ýñæÛÁ¼ ýä©ýóàÙîÇÙí£21Û©©, 22 Ýâ£ýä▒Ù╣îÙö®4ý©Á Û©░ýùàÙÂÇýäñýù░ÛÁ¼ýåî Û▓¢Û©░ÙÅä ýÜ®ýØ©ýï£ Û©░ÝØÑÛÁ¼ ýÿüÙìòÙÅÖ 1029 U-Tower 2809Ýÿ© ýû┤Ùïêý╗┤Òê£ Û©░ýùàÙÂÇ ýäñýù░ÛÁ¼ýåî