ДГВЙГІГІВЙАљЛхSЪ§ЄЮМЦЫуЪНЄШЬиеЃЈ2ЃЉ
?
2 likes?9,208 views

гСПЅЦЅЅЙЅШЗжЮіЄЮЄПЄсЄЮЅеЅъЉ`ЅНЅеЅШЅІЅЇЅЂЁИKH CoderЁЙЄЧЄЯJaccardSЪ§ЄђЖргУЄЗЄЦЄЄЄоЄЙЁЃЄПЄШЄЈЄаЙВЦ№ЅЭЅУЅШЅяЉ`ЅЏЄЮCФмЄЧЄтЁЂеZЄШеZЄЮЙВЦ№ЄЮГЬЖШЄђyЄыЄПЄсЄЫJaccardSЪ§ЄђдгУЄЗЄЦЄЄЄоЄЙЁЃЄГЄЮJaccardSЪ§ЄЮгЫуЪНЄШЬиеЄђЁЂэНтЄЧеhУїЄЗЄЦЄЄЄоЄЙЁЃ


ДГВЙГІГІВЙАљЛхSЪ§ЄЮМЦЫуЪНЄШЬиеЃЈ2ЃЉ
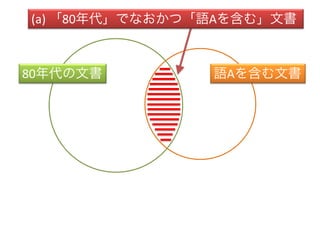
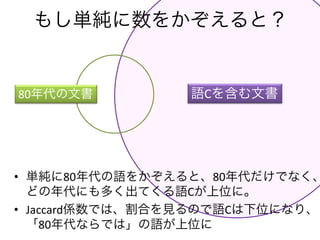
- 4. (Ѓт) ЁИ80ФъДњЁЙЄЋЁИеZAЄђКЌЄрЁЙЄЋ1ЗНЄЧЄтЕБЄЦЄЯЄоЄыЮФј 80ФъДњЄЮЮФј еZAЄђКЌЄрЮФј (a) ЁИ80ФъДњЁЙЄЧЄЪЄЊЄЋЄФЁИгяДЁЄђКЌЄрЁЙЮФЪщ
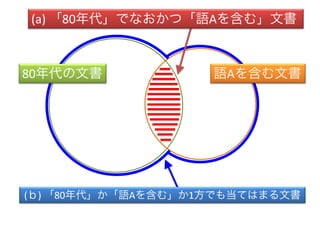
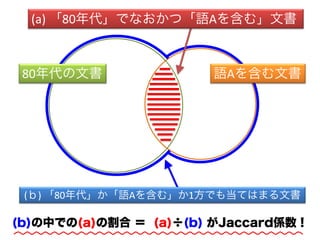
- 5. (b)ЄЮжаЄЧЄЮ(a)ЄЮИюКЯ ЃН (a)ЁТ(b) ЄЌJaccardSЪ§ЃЁ 80ФъДњЄЮЮФј еZAЄђКЌЄрЮФј (a) ЁИ80ФъДњЁЙЄЧЄЪЄЊЄЋЄФЁИгяДЁЄђКЌЄрЁЙЮФЪщ (Ѓт) ЁИ80ФъДњЁЙЄЋЁИеZAЄђКЌЄрЁЙЄЋ1ЗНЄЧЄтЕБЄЦЄЯЄоЄыЮФј
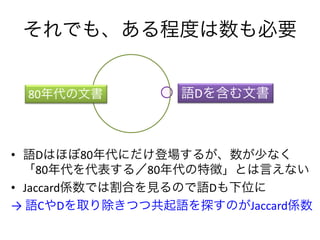
- 7. ЄНЄьЄЧЄтЁЂЄЂЄыГЬЖШЄЯЪ§ЄтБивЊ еZDЄђКЌЄрЮФј ? еZDЄЯЄлЄм80ФъДњЄЫЄРЄБЕЧіЄЙЄыЄЌЁЂЪ§ЄЌЩйЄЪЄЏ ЁИ80ФъДњЄђДњБэЄЙЄыЃЏ80ФъДњЄЮЬиеЁЙЄШЄЯбдЄЈЄЪЄЄ ? JaccardSЪ§ЄЧЄЯИюКЯЄђвЄыЄЮЄЧеZDЄтЯТЮЛЄЫ Ёњ еZCЄфDЄђШЁЄъГ§ЄЄФЄФЙВЦ№еZЄђЬНЄЙЄЮЄЌJaccardSЪ§ 80ФъДњЄЮЮФј
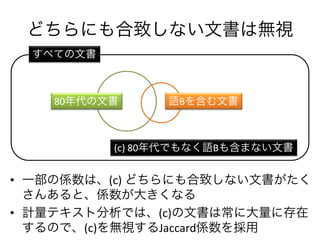
- 8. ЄЩЄСЄщЄЫЄтКЯжТЄЗЄЪЄЄЮФјЄЯoв ? вЛВПЄЮSЪ§ЄЯЁЂ(c) ЄЩЄСЄщЄЫЄтКЯжТЄЗЄЪЄЄЮФјЄЌЄПЄЏ ЄЕЄѓЄЂЄыЄШЁЂSЪ§ЄЌДѓЄЄЏЄЪЄы ? гСПЅЦЅЅЙЅШЗжЮіЄЧЄЯЁЂ(c)ЄЮЮФјЄЯГЃЄЫДѓСПЄЫДцдк ЄЙЄыЄЮЄЧЁЂ(c)ЄђoвЄЙЄыJaccardSЪ§ЄђёгУ 80ФъДњЄЮЮФј еZBЄђКЌЄрЮФј ЄЙЄйЄЦЄЮЮФј (c) 80ФъДњЄЧЄтЄЪЄЏеZBЄтКЌЄоЄЪЄЄЮФј
- 9. ЄШЄГЄэЄЧЁИЮФјЁЙЄУЄЦЄЪЄЫЃП ? дOЖЈЄђфЄЈЄЪЄБЄьЄаЃЈЅЧЅеЅЉЅыЅШЄЧЄЯЃЉ ЈC Excel?CSVЅЧЉ`ЅПЄЮіКЯЄЯЁЂ1ЄФЄЮЅЛЅыЄЌ1ЄФЄЮЁИЮФјЁЙ ЈC ЅЦЅЅЙЅШЅЧЉ`ЅПЄЮіКЯЄЯЁЂ1ЄФЄЮЖЮТфЃЈИФааЄЧЧјЧаЄьЄщЄь ЄПВПЗжЃЉЄЌ1ЄФЄЮЁИЮФјЁЙ ? ЗжЮіrЄЫЁИМЏг gЮЛЁЙЄЮдOЖЈЄђЁИЮФЁЙЄЫфИќЄЙЄьЄаЁЂ 1ЄФЄЮЮФЄђ1ЄФЄЮЁИЮФјЁЙЄШвЄЪЄЛЄы ? KH CoderЄЧЄЯH1ЄЋЄщH5ЄЫЄшЄывГіЄЗЄђМгЄЈЄыЄГЄШЄЧЁЂ Й?еТ?ВПЄЪЄЩЁЉЄЪ gЮЛЄЧЄЮЗжЮіЄЌПЩФм