Performance prediction and evaluation in Recommender Systems: an Information Retrieval perspective
1 like506 views

1 of 85
Downloaded 11 times


















































Ad
Recommended
Managing Crowdsourced Human Computation: A Tutorial
Managing Crowdsourced Human Computation: A TutorialPanos Ipeirotis
╠²
The document discusses managing crowdsourced human computation, outlining the evolution from human computers to the need for human input in AI-complete tasks. Key topics include quality management, task optimization, incentivizing crowds, and case studies involving platforms like Amazon Mechanical Turk. It emphasizes the importance of combining votes for quality assurance and addresses challenges such as distinguishing between genuine contributors and spammers.Tiny Batches, in the wine: Shiny New Bits in Spark Streaming
Tiny Batches, in the wine: Shiny New Bits in Spark StreamingPaco Nathan
╠²
The document discusses the evolution and capabilities of Apache Spark, a powerful engine for big data processing that supports both batch and real-time analytics. It highlights Spark's advantages, such as in-memory computing, ease of development, and its integration with various data sources, which is particularly useful for streaming applications. The presentation includes insights on Spark Streaming, its requirements, use cases, and projected advancements in stability and support for additional environments.Recommender Systems and Misinformation: The Problem or the Solution?
Recommender Systems and Misinformation: The Problem or the Solution?Alejandro Bellogin
╠²
The document discusses the relationship between recommender systems and the spread of misinformation in digital platforms, identifying factors that influence this spread. It evaluates existing algorithms and proposes adaptations to mitigate misinformation, highlighting the need for a human-centered approach. The authors aim to understand and modify recommendation techniques to better combat misinformation through user profiling and algorithm adjustments.Revisiting neighborhood-based recommenders for temporal scenarios
Revisiting neighborhood-based recommenders for temporal scenariosAlejandro Bellogin
╠²
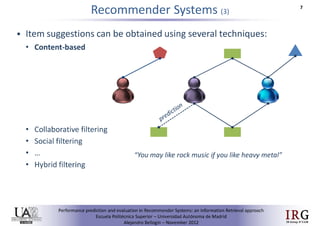
This document presents a new formulation of neighborhood-based recommender systems that incorporates temporal information. It proposes representing each neighbor's recommendations as a ranked list of items around the user's last interaction, and combining these lists using rank aggregation techniques. The approach is evaluated on the Epinions dataset against baseline methods. Results show the backward-forward method outperforms classical kNN and sequential recommender baselines, with improvements depending on the evaluation methodology used. Future work is discussed to further explore the approach.Evaluating decision-aware recommender systems
Evaluating decision-aware recommender systemsAlejandro Bellogin
╠²
The document discusses evaluating decision-aware recommender systems by balancing precision, coverage, and correctness. It proposes a correctness metric adapted from question answering that gives credit to systems that decide not to make recommendations instead of incorrect ones. The authors apply this to collaborative filtering recommenders, introducing strategies for estimating prediction uncertainty based on nearest neighbors or probabilistic matrix factorization. Experiments show tighter uncertainty constraints decrease novelty and diversity but improve precision.Replicable Evaluation of Recommender Systems
Replicable Evaluation of Recommender SystemsAlejandro Bellogin
╠²
This document summarizes a tutorial on replicable evaluation of recommender systems presented at ACM RecSys 2015. The tutorial covered background on recommender systems and motivation for proper evaluation. It discussed evaluating recommender systems as a "black box" process involving data splitting, recommendation generation, candidate item selection, and metric computation. The presenters emphasized the importance of replicating and reproducing evaluation results to validate findings and advance the field. They provided guidelines for reproducible experimental design and highlighted the need to distinguish between replicability and reproducibility. The tutorial included a demonstration of replicating results and concluded by discussing next steps like agreeing on standard implementations and incentivizing reproducibility.Implicit vs Explicit trust in Social Matrix Factorization
Implicit vs Explicit trust in Social Matrix FactorizationAlejandro Bellogin
╠²
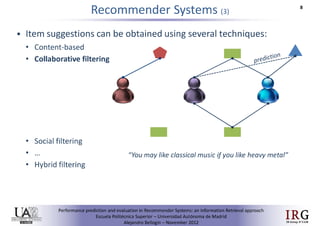
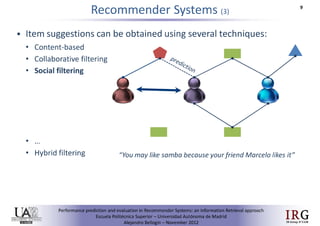
1) The document discusses implicit vs explicit trust in social matrix factorization for recommender systems. It aims to evaluate methods for predicting implicit trust scores between users when explicit trust scores are unavailable.
2) Several trust metrics are evaluated to find the best method for inferring implicit trust scores based on user interaction data. The metric from O'Donovan and Smyth performed best at predicting implicit trust scores.
3) Social matrix factorization using the best implicit trust scoring method performed as accurately as using explicit trust scores, showing that implicit trust can be incorporated when explicit trust is unavailable.RiVal - A toolkit to foster reproducibility in Recommender System evaluation
RiVal - A toolkit to foster reproducibility in Recommender System evaluationAlejandro Bellogin
╠²
RiVal is an open source recommender system evaluation toolkit written in Java that allows control over evaluation dimensions like data splitting, evaluation strategies, and metrics computation. It integrates three recommendation frameworks - Mahout, LensKit, and MyMediaLite. The toolkit is available as Maven dependencies and as a standalone program. Future work includes integrating more recommendation libraries and evaluating metrics beyond accuracy like novelty and diversity.HT2014 Tutorial: Evaluating Recommender Systems - Ensuring Replicability of E...
HT2014 Tutorial: Evaluating Recommender Systems - Ensuring Replicability of E...Alejandro Bellogin
╠²
This document presents a tutorial on evaluating recommender systems, discussing the importance of replicability and reproducibility in experimental design. It explores various evaluation metrics used in recommender systems, highlighting issues with inconsistent results and emphasizing the need for comprehensive guidelines to improve evaluation practices. Key takeaways include the impact of every decision on results, the necessity for transparency in methodology, and the importance of critical assessment of measurement tools.CWI @ Contextual Suggestion track - TREC 2013
CWI @ Contextual Suggestion track - TREC 2013Alejandro Bellogin
╠²
CWI participation at Contextual Suggestion TREC2013 trackCWI @ Federated Web Track - TREC 2013
CWI @ Federated Web Track - TREC 2013Alejandro Bellogin
╠²
CWI participation in Federated Web TREC 2013 trackProbabilistic Collaborative Filtering with Negative Cross Entropy
Probabilistic Collaborative Filtering with Negative Cross EntropyAlejandro Bellogin
╠²
This document proposes using relevance models from information retrieval to improve probabilistic collaborative filtering recommendation algorithms. It introduces a relevance-based language model (RMUB) and a complete probabilistic model (RMCE) that incorporates negative cross entropy. Experiments on MovieLens datasets show both methods outperform baseline user-based and neighbourhood-based collaborative filtering, with RMCE achieving the best performance.Understanding Similarity Metrics in Neighbour-based Recommender Systems
Understanding Similarity Metrics in Neighbour-based Recommender SystemsAlejandro Bellogin
╠²
The document discusses understanding which similarity metrics perform best in neighbor-based recommender systems. It analyzes how the choice of similarity metric, like cosine vs Pearson, affects recommendation quality. It finds metrics' performance correlates with their "quality" - whether most users are close or far in the similarity distribution. The document aims to transform "bad" metrics into better ones by adjusting values based on these correlations, but normalizing distributions did not conclusively improve performance. The analysis provides insight into how a metric's stability relates to discriminating good vs bad neighbors.Artist popularity: do web and social music services agree?
Artist popularity: do web and social music services agree?Alejandro Bellogin
╠²
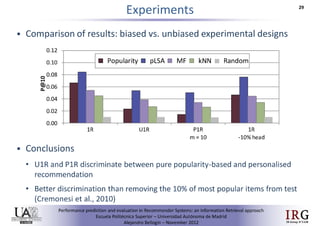
This document compares artist popularity rankings across different web and social music services using datasets from Last.fm, EchoNest, and Spotify spanning January to March 2021. It finds:
1) While no two services are equivalent, comparing rankings across multiple sources can help promote a more diverse set of artist recommendations.
2) Web-based rankings are highly dynamic while service-based rankings change more slowly.
3) Despite differences, rankings show moderate to high correlations, with stability increasing as more artists are considered.Improving Memory-Based Collaborative Filtering by Neighbour Selection based o...
Improving Memory-Based Collaborative Filtering by Neighbour Selection based o...Alejandro Bellogin
╠²
The document presents research on improving memory-based collaborative filtering recommender systems by selecting neighbors based on user preference overlap rather than similarity metrics. It finds that user preference overlap is a good surrogate for similarity in neighbor selection and can provide equivalent or better results than traditional similarity-based approaches. The research compares different neighbor selection methods based on overlap, similarity, and hybrid approaches and evaluates their performance on precision and error metrics across different neighborhood sizes. It determines that selection methods based on preference overlap provide as good or better performance than the baseline similarity approach.Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...Alejandro Bellogin
╠²
Using graph partitioning techniques like Normalised Cut (NCut) for neighbourhood selection in user-based collaborative filtering outperforms other clustering methods like k-Means. NCut models users as nodes in a graph and clusters them based on their similarities. It was tested on the Movielens 100K dataset against baselines like user-based CF with Pearson correlation and matrix factorization. NCut achieved higher precision and coverage than the baselines, showing the benefit of using graph partitioning for neighbourhood selection in collaborative filtering.Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...Alejandro Bellogin
╠²
This document proposes using spectral clustering techniques like normalized cuts for identifying neighbors in user-based collaborative filtering. It shows that this approach works better than k-means clustering and standard user-based collaborative filtering, providing higher prediction accuracy and coverage for recommendations. The approach identifies neighbors based on clustering users based on their ratings rather than selecting the nearest users.Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...Alejandro Bellogin
╠²
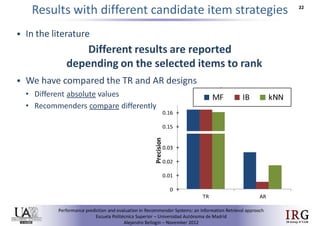
This document compares different methodologies for evaluating recommender systems using precision-oriented metrics. It presents an approach that builds a target item list for each user and ranks items by predicted rating. It evaluates how precision metrics are affected by the construction of the non-relevant item set. An empirical comparison on MovieLens data shows significant differences in results depending on the evaluation methodology used. The discussion indicates precision and error-based metrics may give different comparative recommender results.Predicting performance in Recommender Systems - ║▌║▌▀Żs
Predicting performance in Recommender Systems - ║▌║▌▀ŻsAlejandro Bellogin
╠²
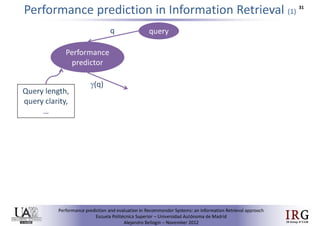
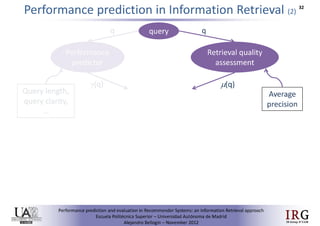
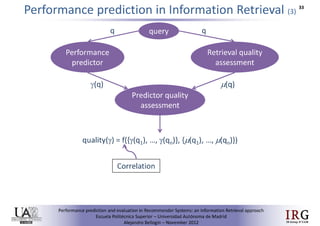
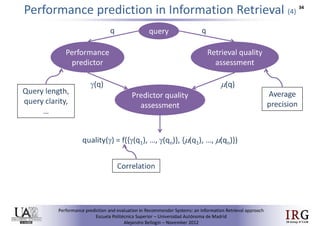
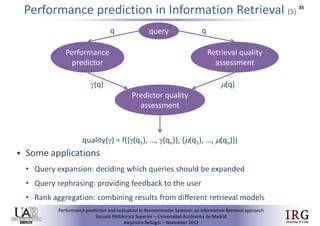
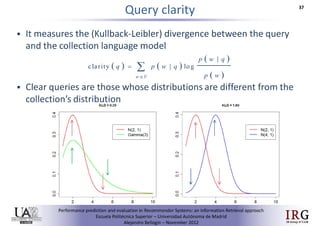
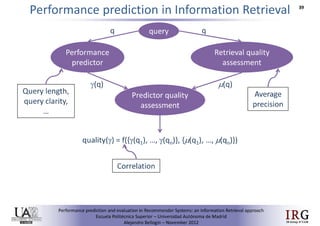
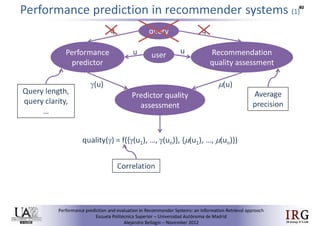
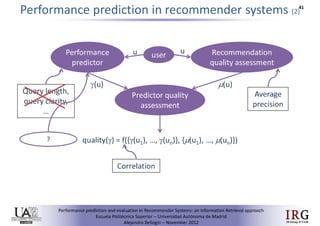
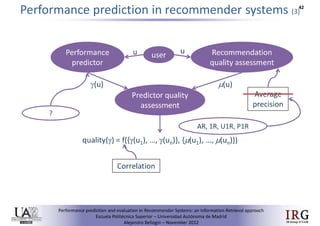
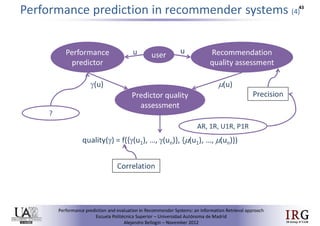
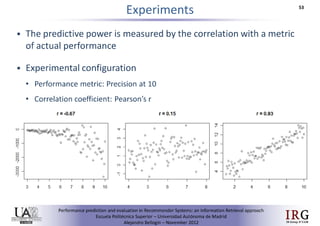
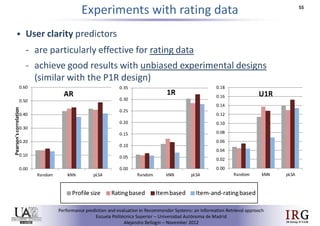
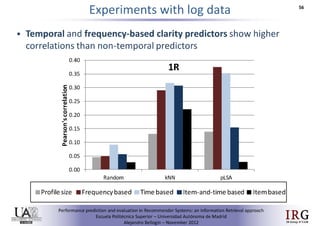
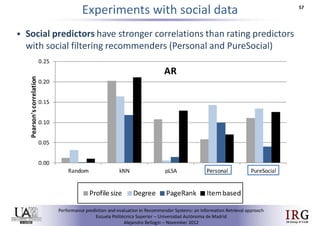
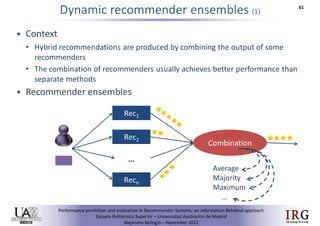
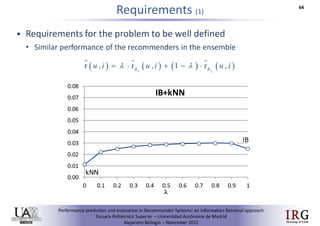
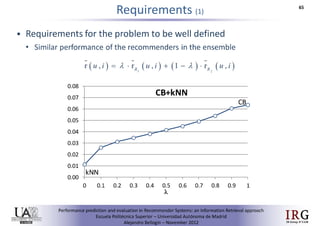
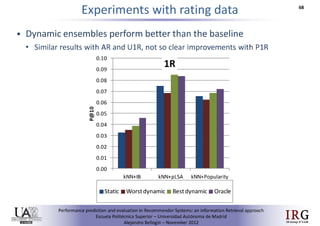
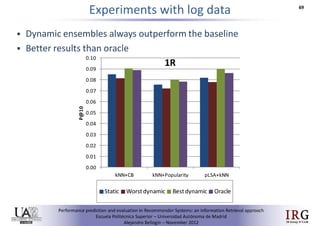
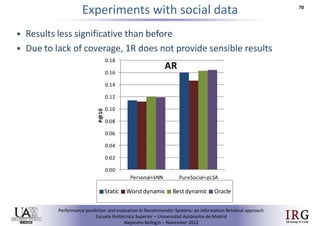
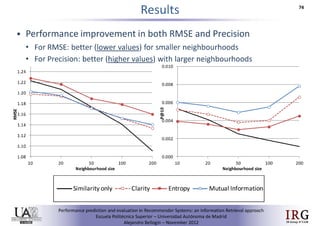
The document discusses predicting performance in recommender systems. It proposes adapting techniques from information retrieval to define performance prediction models for recommender systems. Specifically, it explores adapting the concept of "query clarity" to define user clarity models that capture uncertainty in a user's preferences. The models are used to build dynamic recommendation strategies like dynamic neighbor weighting and dynamic hybrid recommendations. Initial results show the dynamic strategies outperform static baselines and user clarity predictors correlate positively with performance metrics. Future work includes exploring additional input sources for performance prediction models.Predicting performance in Recommender Systems - Poster slam
Predicting performance in Recommender Systems - Poster slamAlejandro Bellogin
╠²
The document discusses the potential to predict recommendation accuracy in recommender systems, presented at the ACM Conference on Recommender Systems in 2011. It explores the hypothesis that data signals can forecast performance and introduces performance predictors based on these signals. The findings indicate that dynamic recommenders outperform static ones in predictive power, supporting the application of dynamic strategies like hybrid recommendations and neighbor selection.Predicting performance in Recommender Systems - Poster
Predicting performance in Recommender Systems - PosterAlejandro Bellogin
╠²
This document discusses predicting the performance of recommender systems. It proposes that data commonly available to recommender systems could enable estimating the success of recommendations. Specifically, it aims to 1) define a performance prediction theory for recommender systems, 2) adapt query performance techniques from information retrieval to recommendations, and 3) evaluate appropriate performance metrics. The research also explores applying these models when combining multiple recommendation strategies or hybrid recommender systems.Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...Alejandro Bellogin
╠²
The document discusses three questions about evaluating recommender systems: 1) How comparable are results reported using precision-oriented metrics? 2) How meaningful are absolute performance metric values? 3) How sensitive are recommenders to different evaluation methodologies? It presents comparative experiments using different metrics and evaluation designs to analyze recommenders' performance under precision-oriented evaluation.More Related Content
More from Alejandro Bellogin (14)
HT2014 Tutorial: Evaluating Recommender Systems - Ensuring Replicability of E...
HT2014 Tutorial: Evaluating Recommender Systems - Ensuring Replicability of E...Alejandro Bellogin
╠²
This document presents a tutorial on evaluating recommender systems, discussing the importance of replicability and reproducibility in experimental design. It explores various evaluation metrics used in recommender systems, highlighting issues with inconsistent results and emphasizing the need for comprehensive guidelines to improve evaluation practices. Key takeaways include the impact of every decision on results, the necessity for transparency in methodology, and the importance of critical assessment of measurement tools.CWI @ Contextual Suggestion track - TREC 2013
CWI @ Contextual Suggestion track - TREC 2013Alejandro Bellogin
╠²
CWI participation at Contextual Suggestion TREC2013 trackCWI @ Federated Web Track - TREC 2013
CWI @ Federated Web Track - TREC 2013Alejandro Bellogin
╠²
CWI participation in Federated Web TREC 2013 trackProbabilistic Collaborative Filtering with Negative Cross Entropy
Probabilistic Collaborative Filtering with Negative Cross EntropyAlejandro Bellogin
╠²
This document proposes using relevance models from information retrieval to improve probabilistic collaborative filtering recommendation algorithms. It introduces a relevance-based language model (RMUB) and a complete probabilistic model (RMCE) that incorporates negative cross entropy. Experiments on MovieLens datasets show both methods outperform baseline user-based and neighbourhood-based collaborative filtering, with RMCE achieving the best performance.Understanding Similarity Metrics in Neighbour-based Recommender Systems
Understanding Similarity Metrics in Neighbour-based Recommender SystemsAlejandro Bellogin
╠²
The document discusses understanding which similarity metrics perform best in neighbor-based recommender systems. It analyzes how the choice of similarity metric, like cosine vs Pearson, affects recommendation quality. It finds metrics' performance correlates with their "quality" - whether most users are close or far in the similarity distribution. The document aims to transform "bad" metrics into better ones by adjusting values based on these correlations, but normalizing distributions did not conclusively improve performance. The analysis provides insight into how a metric's stability relates to discriminating good vs bad neighbors.Artist popularity: do web and social music services agree?
Artist popularity: do web and social music services agree?Alejandro Bellogin
╠²
This document compares artist popularity rankings across different web and social music services using datasets from Last.fm, EchoNest, and Spotify spanning January to March 2021. It finds:
1) While no two services are equivalent, comparing rankings across multiple sources can help promote a more diverse set of artist recommendations.
2) Web-based rankings are highly dynamic while service-based rankings change more slowly.
3) Despite differences, rankings show moderate to high correlations, with stability increasing as more artists are considered.Improving Memory-Based Collaborative Filtering by Neighbour Selection based o...
Improving Memory-Based Collaborative Filtering by Neighbour Selection based o...Alejandro Bellogin
╠²
The document presents research on improving memory-based collaborative filtering recommender systems by selecting neighbors based on user preference overlap rather than similarity metrics. It finds that user preference overlap is a good surrogate for similarity in neighbor selection and can provide equivalent or better results than traditional similarity-based approaches. The research compares different neighbor selection methods based on overlap, similarity, and hybrid approaches and evaluates their performance on precision and error metrics across different neighborhood sizes. It determines that selection methods based on preference overlap provide as good or better performance than the baseline similarity approach.Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...Alejandro Bellogin
╠²
Using graph partitioning techniques like Normalised Cut (NCut) for neighbourhood selection in user-based collaborative filtering outperforms other clustering methods like k-Means. NCut models users as nodes in a graph and clusters them based on their similarities. It was tested on the Movielens 100K dataset against baselines like user-based CF with Pearson correlation and matrix factorization. NCut achieved higher precision and coverage than the baselines, showing the benefit of using graph partitioning for neighbourhood selection in collaborative filtering.Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...Alejandro Bellogin
╠²
This document proposes using spectral clustering techniques like normalized cuts for identifying neighbors in user-based collaborative filtering. It shows that this approach works better than k-means clustering and standard user-based collaborative filtering, providing higher prediction accuracy and coverage for recommendations. The approach identifies neighbors based on clustering users based on their ratings rather than selecting the nearest users.Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...Alejandro Bellogin
╠²
This document compares different methodologies for evaluating recommender systems using precision-oriented metrics. It presents an approach that builds a target item list for each user and ranks items by predicted rating. It evaluates how precision metrics are affected by the construction of the non-relevant item set. An empirical comparison on MovieLens data shows significant differences in results depending on the evaluation methodology used. The discussion indicates precision and error-based metrics may give different comparative recommender results.Predicting performance in Recommender Systems - ║▌║▌▀Żs
Predicting performance in Recommender Systems - ║▌║▌▀ŻsAlejandro Bellogin
╠²
The document discusses predicting performance in recommender systems. It proposes adapting techniques from information retrieval to define performance prediction models for recommender systems. Specifically, it explores adapting the concept of "query clarity" to define user clarity models that capture uncertainty in a user's preferences. The models are used to build dynamic recommendation strategies like dynamic neighbor weighting and dynamic hybrid recommendations. Initial results show the dynamic strategies outperform static baselines and user clarity predictors correlate positively with performance metrics. Future work includes exploring additional input sources for performance prediction models.Predicting performance in Recommender Systems - Poster slam
Predicting performance in Recommender Systems - Poster slamAlejandro Bellogin
╠²
The document discusses the potential to predict recommendation accuracy in recommender systems, presented at the ACM Conference on Recommender Systems in 2011. It explores the hypothesis that data signals can forecast performance and introduces performance predictors based on these signals. The findings indicate that dynamic recommenders outperform static ones in predictive power, supporting the application of dynamic strategies like hybrid recommendations and neighbor selection.Predicting performance in Recommender Systems - Poster
Predicting performance in Recommender Systems - PosterAlejandro Bellogin
╠²
This document discusses predicting the performance of recommender systems. It proposes that data commonly available to recommender systems could enable estimating the success of recommendations. Specifically, it aims to 1) define a performance prediction theory for recommender systems, 2) adapt query performance techniques from information retrieval to recommendations, and 3) evaluate appropriate performance metrics. The research also explores applying these models when combining multiple recommendation strategies or hybrid recommender systems.Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...Alejandro Bellogin
╠²
The document discusses three questions about evaluating recommender systems: 1) How comparable are results reported using precision-oriented metrics? 2) How meaningful are absolute performance metric values? 3) How sensitive are recommenders to different evaluation methodologies? It presents comparative experiments using different metrics and evaluation designs to analyze recommenders' performance under precision-oriented evaluation.HT2014 Tutorial: Evaluating Recommender Systems - Ensuring Replicability of E...
HT2014 Tutorial: Evaluating Recommender Systems - Ensuring Replicability of E...Alejandro Bellogin
╠²
Improving Memory-Based Collaborative Filtering by Neighbour Selection based o...
Improving Memory-Based Collaborative Filtering by Neighbour Selection based o...Alejandro Bellogin
╠²
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...Alejandro Bellogin
╠²
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...
Using Graph Partitioning Techniques for Neighbour Selection in User-Based Col...Alejandro Bellogin
╠²
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...Alejandro Bellogin
╠²
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...
Precision-oriented Evaluation of Recommender Systems: An Algorithmic Comparis...Alejandro Bellogin
╠²