

![Intro
ļ©╝ņĀĆ Recurrent Neural NetworksņØś ņØ┤ļĪĀņØĆ ņĢīĻ│Ā ņ׳ļŗż
Ļ│Ā Ļ░ĆņĀĢ, apiļź╝ ņé¼ņÜ®ĒĢśļŖö ļ▓Ģļ¦ī ņé┤ĒÄ┤ļ┤ä
ļ¬©ļōĀ ņāüĒÖ®ņØĆ variable sequence lengthļź╝ Ļ░ĆņĀĢ, ņśłļź╝ ļōż
ļ®┤ ņĢäļלņÖĆ Ļ░ÖņØ┤..
# ļ¼ĖņןņØś ļŗ©ņ¢┤ļź╝ RNNņŚÉ ĒĢśļéśĒĢśļéśņö® ļäŻļŖöļŗżĻ│Ā ĒĢśļ®┤?
# RNNņØĆ ņĢäļלņ▓śļ¤╝ Ļ░ü ļ¼Ėņן ļ│äļĪ£ ļŗ©ņ¢┤ņØś Ļ░£ņłśļ¦īĒü╝ sequenceļź╝ ņ▓śļ”¼ĒĢ┤ņĢ╝ĒĢ£ļŗż.
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework',
'for','deep','learning'],
['tensorflow', 'is', 'very',
'fast', 'changing']]
4](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-4-320.jpg)

![Intro : Padding
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
# '<pad>'ļØ╝ļŖö ņØśļ»ĖņŚåļŖö token ņČöĻ░Ć
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx,
word in enumerate(word_list)}
6](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-6-320.jpg)
![Intro : Padding
# max_lenņØś ĻĖĖņØ┤ņŚÉ ļ¬╗ļ»Ėņ╣śļŖö ļ¼ĖņןņØĆ <pad>ļĪ£ max_lenļ¦īĒü╝ padding
def pad_seq(sequences, max_len, dic):
seq_len, seq_indices = [], []
for seq in sequences:
seq_len.append(len(seq))
seq_idx = [dic.get(char) for char in seq]
# 0 is idx of meaningless token "<pad>"
seq_idx += (max_len - len(seq_idx)) *
[dic.get('<pad>')]
seq_indices.append(seq_idx)
return seq_len, seq_indices
7](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-7-320.jpg)
![Intro : Padding
max_length = 8
sen_len, sen_indices = pad_seq(sequences = sentences,
max_len = max_length,
dic = word_dic)
[3, 4, 7, 5]
[[1, 7, 10, 0, 0, 0, 0, 0],
[13, 11, 14, 5, 0, 0, 0, 0],
[13, 11, 2, 9, 8, 4, 12, 0],
[13, 11, 14, 6, 3, 0, 0, 0]]
8](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-8-320.jpg)

![Intro : Look up
# tf.nn.embedding_lookupņØś params, ids argņŚÉ ņĀäļŗ¼ĒĢśĻĖ░ņ£äĒĢ£
# placeholder ņäĀņ¢Ė
seq_len = tf.placeholder(dtype = tf.int32, shape = [None])
seq_indices = tf.placeholder(dtype = tf.int32,
shape = [None, max_length])
one_hot = np.eye(len(word_dic)) # ļŗ©ņ¢┤ ļ│ä one-hot encoding
# embedding vectorļŖö training ņĢłĒĢĀ Ļ▓āņØ┤ļ»ĆļĪ£
one_hot = tf.get_variable(name='one_hot',
initializer = one_hot,
trainable = False)
seq_batch = tf.nn.embedding_lookup(params = one_hot,
ids = seq_indices)
10](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-10-320.jpg)
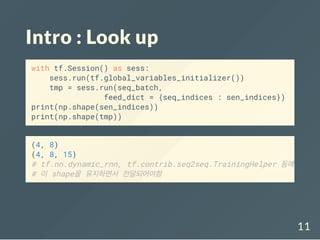

![Example data
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for',
'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast',
'changing']]
label = [[0.,1.], [0.,1.], [1.,0.], [1.,0.]]
13](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-13-320.jpg)
![Example data
sentencesņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary
ņāØņä▒
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
# '<pad>'ļØ╝ļŖö ņØśļ»ĖņŚåļŖö token ņČöĻ░Ć
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx,
word in enumerate(word_list)}
14](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-14-320.jpg)
![Example data
dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼
[3, 4, 7, 5]
[[1, 7, 10, 0, 0, 0, 0, 0],
[13, 11, 14, 5, 0, 0, 0, 0],
[13, 11, 2, 9, 8, 4, 12, 0],
[13, 11, 14, 6, 3, 0, 0, 0]]
max_length = 8
sen_len, sen_indices = pad_seq(sequences = sentences, max_len =
dic = word_dic)
pprint(sen_len)
pprint(sen_indices)
15](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-15-320.jpg)

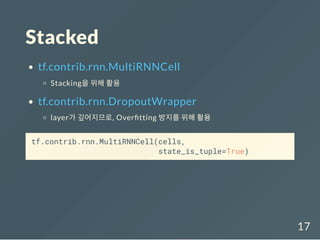



![Example data
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for',
'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast',
'changing']]
pos = [['pronoun', 'verb', 'adjective'],
['noun', 'verb', 'adverb', 'adjective'],
['noun', 'verb', 'determiner', 'noun',
'preposition', 'adjective', 'noun'],
['noun', 'verb', 'adverb', 'adjective', 'verb']]
21](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-21-320.jpg)
![Example data
sentencesņØśwordļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary
ņāØņä▒
posņØś tokenļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx, word
in enumerate(word_list)}
22](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-22-320.jpg)
![Example data
sentencesņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary
ņāØņä▒
posņØśtokenļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØņä▒
# pos dic
pos_list = []
for elm in pos:
pos_list += elm
pos_list = list(set(pos_list))
pos_list.sort()
pos_list = ['<pad>'] + pos_list
pos_dic = {pos : idx for idx, pos in enumerate(pos_list)}
23](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-23-320.jpg)

![Example data
dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼
pprint(sen_len)
pprint(sen_indices)
[3, 4, 7, 5]
[[1, 7, 10, 0, 0, 0, 0, 0],
[13, 11, 14, 5, 0, 0, 0, 0],
[13, 11, 2, 9, 8, 4, 12, 0],
[13, 11, 14, 6, 3, 0, 0, 0]]
25](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-25-320.jpg)
![Example data
dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼
pprint(pos_indices)
[[6, 7, 1, 0, 0, 0, 0, 0],
[4, 7, 2, 1, 0, 0, 0, 0],
[4, 7, 3, 4, 5, 1, 4, 0],
[4, 7, 2, 1, 7, 0, 0, 0]]
26](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-26-320.jpg)
![Simple
CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝
ļŗ© tf.nn.dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ®
tf.contrib.rnn.OutputProjectionWrapper
stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.sequence_mask
ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.contrib.seq2seq.sequence_loss
tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī
targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼
27](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-27-320.jpg)
![Stacked
CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝
ļŗ© tf.nn.dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ®
tf.contrib.rnn.OutputProjectionWrapper
stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.sequence_mask
ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.contrib.seq2seq.sequence_loss
tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī
targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼
28](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-28-320.jpg)
![Bi-directional
CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝
ļŗ© tf.nn.bidirectional_dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ®
tf.map_fn
stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.sequence_mask
ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.contrib.seq2seq.sequence_loss
tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī
targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼
29](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-29-320.jpg)
![Stacked Bi-directional
CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝
ļŗ© tf.contrib.rnn.stack_bidirectional_dynamic_rnnņØś return Ļ░Æņżæ
outputsņØä ĒÖ£ņÜ®
tf.map_fn
stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.sequence_mask
ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ®
tf.contrib.seq2seq.sequence_loss
tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī
targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼
30](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-30-320.jpg)

![Example data
targets = [['ļéśļŖö', 'ļ░░Ļ░Ć', 'Ļ│ĀĒöäļŗż'],
['ĒģÉņä£ĒöīļĪ£ņÜ░ļŖö', 'ļ¦żņÜ░', 'ņ¢┤ļĀĄļŗż'],
['ĒģÉņä£ĒöīļĪ£ņÜ░ļŖö', 'ļöźļ¤¼ļŗØņØä', 'ņ£äĒĢ£', 'ĒöäļĀłņ×äņøīĒü¼ņØ┤ļŗż'],
['ĒģÉņä£ĒöīļĪ£ņÜ░ļŖö', 'ļ¦żņÜ░', 'ļ╣Āļź┤Ļ▓ī', 'ļ│ĆĒÖöĒĢ£ļŗż']]
sources = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for', 'deep',
['tensorflow', 'is', 'very', 'fast', 'changing']]
32](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-32-320.jpg)
![Example data
sourcesņØśwordļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØ
ņä▒
targetsņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒
# word dic for sentences
source_words = []
for elm in sources:
source_words += elm
source_words = list(set(source_words))
source_words.sort()
source_words = ['<pad>'] + source_words
source_dic = {word : idx for idx, word
in enumerate(source_words)}
33](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-33-320.jpg)
![Example data
sourcesņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒
targetsņØśwordļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØ
ņä▒
# word dic for translations
target_words = []
for elm in targets:
target_words += elm
target_words = list(set(target_words))
target_words.sort()
# ļ▓łņŚŁļ¼ĖņØś ņŗ£ņ×æĻ│╝ ļüØņØä ņĢīļ”¼ļŖö 'start', 'end' token ņČöĻ░Ć
target_words = ['<pad>']+ ['<start>'] + ['<end>'] +
target_words
target_dic = {word : idx for idx, word
in enumerate(target_words)} 34](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-34-320.jpg)




To quickly implementing RNN
- 2. Contents Intro Many to One Many to Many Seq2Seq QnA 2
- 3. Intro ņ¦äĒ¢ēĒĢśĻĖ░ņĀäņŚÉ..... ņŖ¼ļØ╝ņØ┤ļō£ņØś ļ¬©ļōĀ code snippetsņØĆ ņĢäļלņØś ļ¦üĒü¼ļĪ£ ļŗżņÜ┤ ļ░ø Ļ▒░ļéś, ņĢäļלņØś ņé¼ņØ┤ĒŖĖņŚÉņä£ ļ│┤ņŗ£ļ®┤ ļÉ®ļŗłļŗż. Download : http://tagme.to/aisolab/To_quickly_implementin g_RNN Click : To quickly implementing RNN.ipynb 3
- 4. Intro ļ©╝ņĀĆ Recurrent Neural NetworksņØś ņØ┤ļĪĀņØĆ ņĢīĻ│Ā ņ׳ļŗż Ļ│Ā Ļ░ĆņĀĢ, apiļź╝ ņé¼ņÜ®ĒĢśļŖö ļ▓Ģļ¦ī ņé┤ĒÄ┤ļ┤ä ļ¬©ļōĀ ņāüĒÖ®ņØĆ variable sequence lengthļź╝ Ļ░ĆņĀĢ, ņśłļź╝ ļōż ļ®┤ ņĢäļלņÖĆ Ļ░ÖņØ┤.. # ļ¼ĖņןņØś ļŗ©ņ¢┤ļź╝ RNNņŚÉ ĒĢśļéśĒĢśļéśņö® ļäŻļŖöļŗżĻ│Ā ĒĢśļ®┤? # RNNņØĆ ņĢäļלņ▓śļ¤╝ Ļ░ü ļ¼Ėņן ļ│äļĪ£ ļŗ©ņ¢┤ņØś Ļ░£ņłśļ¦īĒü╝ sequenceļź╝ ņ▓śļ”¼ĒĢ┤ņĢ╝ĒĢ£ļŗż. sentences = [['I', 'feel', 'hungry'], ['tensorflow', 'is', 'very', 'difficult'], ['tensorflow', 'is', 'a', 'framework', 'for','deep','learning'], ['tensorflow', 'is', 'very', 'fast', 'changing']] 4
- 5. Intro : Padding tensor owņŚÉņä£ variable sequence lengthļź╝ ļŗżļŻ©ĻĖ░ ņ£äĒĢ┤ņä£ļŖö ņØ╝ļŗ© ņĀüļŗ╣ĒĢ£ ĻĖĖņØ┤ļĪ£ paddingņØä ĒĢ┤ņĢ╝ĒĢ© ņÖ£ļāÉĒĢśļ®┤ eager modeļź╝ ĒÖ£ņÜ®ĒĢśņ¦ĆņĢŖļŖö ņØ┤ņāü tensor ow ļŖö ņĀĢņĀüņØĖ frameworkņØ┤ĻĖ░ ļĢīļ¼Ė paddingņØä ņ£äĒĢ£ tensor ow graphļź╝ ņĀĢņØśĒĢśĻ▒░ļéś, python ĒĢ©ņłśļź╝ ņĀĢņØśĒĢśņŚ¼ ĒÖ£ņÜ® paddingņŗ£ ņĀüļŗ╣ĒĢ£ ņĄ£ļīĆ ĻĖĖņØ┤ļź╝ ņĀĢĒĢ┤ņżä Ļ▓ā 5
- 6. Intro : Padding # word dic word_list = [] for elm in sentences: word_list += elm word_list = list(set(word_list)) word_list.sort() # '<pad>'ļØ╝ļŖö ņØśļ»ĖņŚåļŖö token ņČöĻ░Ć word_list = ['<pad>'] + word_list word_dic = {word : idx for idx, word in enumerate(word_list)} 6
- 7. Intro : Padding # max_lenņØś ĻĖĖņØ┤ņŚÉ ļ¬╗ļ»Ėņ╣śļŖö ļ¼ĖņןņØĆ <pad>ļĪ£ max_lenļ¦īĒü╝ padding def pad_seq(sequences, max_len, dic): seq_len, seq_indices = [], [] for seq in sequences: seq_len.append(len(seq)) seq_idx = [dic.get(char) for char in seq] # 0 is idx of meaningless token "<pad>" seq_idx += (max_len - len(seq_idx)) * [dic.get('<pad>')] seq_indices.append(seq_idx) return seq_len, seq_indices 7
- 8. Intro : Padding max_length = 8 sen_len, sen_indices = pad_seq(sequences = sentences, max_len = max_length, dic = word_dic) [3, 4, 7, 5] [[1, 7, 10, 0, 0, 0, 0, 0], [13, 11, 14, 5, 0, 0, 0, 0], [13, 11, 2, 9, 8, 4, 12, 0], [13, 11, 14, 6, 3, 0, 0, 0]] 8
- 9. Intro : Look up variable sequenceļź╝ Ļ░Ćņ¦ĆļŖö inputņØä RNNņØś inputņ£╝ ļĪ£ ļäŻņØä ņłś ņ׳ļÅäļĪØ ņל padding Ē¢łļŖö ļŹ░... padding ĒĢ£ Ļ▓āņØä ĻĘĖļīĆļĪ£ RNNņØś inputņ£╝ļĪ£ ļäŻļŖö Ļ▓ī ļ¦×ļéś? idx ļ│ä ļŁöĻ░Ć dense vector (eg. word2vec) ļō▒ņØä ņé¼ņÜ®ĒĢ┤ ņĢ╝ĒĢ©, tf.nn.embedding_lookupņØä ĒÖ£ņÜ®ĒĢśņ×É! tf.nn.embedding_lookup( params, ids, partition_strategy='mod', name=None, validate_indices=True, max_norm=None) 9
- 10. Intro : Look up # tf.nn.embedding_lookupņØś params, ids argņŚÉ ņĀäļŗ¼ĒĢśĻĖ░ņ£äĒĢ£ # placeholder ņäĀņ¢Ė seq_len = tf.placeholder(dtype = tf.int32, shape = [None]) seq_indices = tf.placeholder(dtype = tf.int32, shape = [None, max_length]) one_hot = np.eye(len(word_dic)) # ļŗ©ņ¢┤ ļ│ä one-hot encoding # embedding vectorļŖö training ņĢłĒĢĀ Ļ▓āņØ┤ļ»ĆļĪ£ one_hot = tf.get_variable(name='one_hot', initializer = one_hot, trainable = False) seq_batch = tf.nn.embedding_lookup(params = one_hot, ids = seq_indices) 10
- 11. Intro : Look up with tf.Session() as sess: sess.run(tf.global_variables_initializer()) tmp = sess.run(seq_batch, feed_dict = {seq_indices : sen_indices}) print(np.shape(sen_indices)) print(np.shape(tmp)) (4, 8) (4, 8, 15) # tf.nn.dynamic_rnn, tf.contrib.seq2seq.TrainingHelper ļō▒ņŚÉ # ņØ┤ shapeņØä ņ£Āņ¦ĆĒĢśļ®┤ņä£ ņĀäļŗ¼ļÉśņ¢┤ņĢ╝ĒĢ© 11
- 12. Many to One eg. ņśüņ¢┤ ļ¼ĖņןņØś ĻĖŹ/ļČĆņĀĢņØä ĒÅēĻ░ĆĒĢśļŖö RNN (with GRU)
- 13. Example data sentences = [['I', 'feel', 'hungry'], ['tensorflow', 'is', 'very', 'difficult'], ['tensorflow', 'is', 'a', 'framework', 'for', 'deep', 'learning'], ['tensorflow', 'is', 'very', 'fast', 'changing']] label = [[0.,1.], [0.,1.], [1.,0.], [1.,0.]] 13
- 14. Example data sentencesņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒ # word dic word_list = [] for elm in sentences: word_list += elm word_list = list(set(word_list)) word_list.sort() # '<pad>'ļØ╝ļŖö ņØśļ»ĖņŚåļŖö token ņČöĻ░Ć word_list = ['<pad>'] + word_list word_dic = {word : idx for idx, word in enumerate(word_list)} 14
- 15. Example data dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼ [3, 4, 7, 5] [[1, 7, 10, 0, 0, 0, 0, 0], [13, 11, 14, 5, 0, 0, 0, 0], [13, 11, 2, 9, 8, 4, 12, 0], [13, 11, 14, 6, 3, 0, 0, 0]] max_length = 8 sen_len, sen_indices = pad_seq(sequences = sentences, max_len = dic = word_dic) pprint(sen_len) pprint(sen_indices) 15
- 16. Simple tf.nn.dynamic_rnn cellņØä ļÅīļ”┤ ļĢī ĒÖ£ņÜ®, return Ļ░Æ ņżæ stateļ¦īņØä ĒÖ£ņÜ® sequence_lengthņŚÉ padding ĒĢśĻĖ░ņĀä ļ¼ĖņןņØś ĻĖĖņØ┤ļź╝ ļäŻņ¢┤ņŻ╝ļ®┤ ņĢīņĢäņä£ ņøÉ ļ¼Ėņן ņØś sequenceļ¦īĒü╝ ņ▓śļ”¼ tf.losses.softmax_cross_entropy ņØ╝ļ░śņĀüņØĖ NNņØś lossņÖĆ ļÅÖņØ╝ tf.nn.dynamic_rnn(cell, inputs, sequence_length=None, initial_state=None, dtype=None, parallel_iterations=None, swap_memory=False, time_major=False, scope=None) 16
- 17. Stacked tf.contrib.rnn.MultiRNNCell StackingņØä ņ£äĒĢ┤ ĒÖ£ņÜ® tf.contrib.rnn.DropoutWrapper layerĻ░Ć Ļ╣Ŗņ¢┤ņ¦Ćļ»ĆļĪ£, Over tting ļ░®ņ¦Ćļź╝ ņ£äĒĢ┤ ĒÖ£ņÜ® tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True) 17
- 18. Bi-directional tf.nn.bidirectional_dynamic_rnn fw_cellĻ│╝ bw_cellņØä ļÅīļ”┤ ļĢī ĒÖ£ņÜ®, return Ļ░Æ ņżæ output_statesļ¦īņØä ĒÖ£ņÜ®, output_statesļŖö fw_cellĻ│╝ bw_cellņØś nal state Ļ░ÆņØä Ļ░¢Ļ│Ā ņ׳ņ¢┤ņä£, loss Ļ│äņé░ ņŗ£ ļæśņØä concatenateĒĢ┤ņä£ ĒÖ£ņÜ® tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw, inputs, sequence_length=None, initial_state_fw=None, initial_state_bw=None, dtype=None, parallel_iterations=None, swap_memory=False, time_major=False, scope=None) 18
- 19. Stacked Bi-directional tf.contrib.rnn.stack_bidirectional_dynamic_rnn Ļ░üĻ░üņØś fw_cells, bw_cells (list ĒśĢĒā£)ļź╝ ļÅīļ”┤ ļĢī ĒÖ£ņÜ® return Ļ░Æ ņżæ output_state_fw, output_state_bwļź╝ concatenateĒĢ┤ņä£ ĒÖ£ ņÜ® tf.contrib.rnn.stack_bidirectional_dynamic_rnn( cells_fw, cells_bw, inputs, initial_states_fw=None, initial_states_bw=None, dtype=None, sequence_length=None, parallel_iterations=None, time_major=False, scope=None) 19
- 20. Many to Many eg. ĒśĢĒā£ņåī ļČäņäØņØä ĒĢśļŖö RNN (with GRU)
- 21. Example data sentences = [['I', 'feel', 'hungry'], ['tensorflow', 'is', 'very', 'difficult'], ['tensorflow', 'is', 'a', 'framework', 'for', 'deep', 'learning'], ['tensorflow', 'is', 'very', 'fast', 'changing']] pos = [['pronoun', 'verb', 'adjective'], ['noun', 'verb', 'adverb', 'adjective'], ['noun', 'verb', 'determiner', 'noun', 'preposition', 'adjective', 'noun'], ['noun', 'verb', 'adverb', 'adjective', 'verb']] 21
- 22. Example data sentencesņØśwordļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØņä▒ posņØś tokenļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒ # word dic word_list = [] for elm in sentences: word_list += elm word_list = list(set(word_list)) word_list.sort() word_list = ['<pad>'] + word_list word_dic = {word : idx for idx, word in enumerate(word_list)} 22
- 23. Example data sentencesņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒ posņØśtokenļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØņä▒ # pos dic pos_list = [] for elm in pos: pos_list += elm pos_list = list(set(pos_list)) pos_list.sort() pos_list = ['<pad>'] + pos_list pos_dic = {pos : idx for idx, pos in enumerate(pos_list)} 23
- 24. Example data dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼ sen_len, sen_indices = pad_seq(sequences = sentences, max_len = max_length, dic = word_dic) _, pos_indices = pad_seq(sequences = pos, max_len = max_length, dic = pos_dic) 24
- 25. Example data dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼ pprint(sen_len) pprint(sen_indices) [3, 4, 7, 5] [[1, 7, 10, 0, 0, 0, 0, 0], [13, 11, 14, 5, 0, 0, 0, 0], [13, 11, 2, 9, 8, 4, 12, 0], [13, 11, 14, 6, 3, 0, 0, 0]] 25
- 26. Example data dictionaryļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀäņ▓śļ”¼ pprint(pos_indices) [[6, 7, 1, 0, 0, 0, 0, 0], [4, 7, 2, 1, 0, 0, 0, 0], [4, 7, 3, 4, 5, 1, 4, 0], [4, 7, 2, 1, 7, 0, 0, 0]] 26
- 27. Simple CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝ ļŗ© tf.nn.dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ® tf.contrib.rnn.OutputProjectionWrapper stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.sequence_mask ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.contrib.seq2seq.sequence_loss tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼ 27
- 28. Stacked CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝ ļŗ© tf.nn.dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ® tf.contrib.rnn.OutputProjectionWrapper stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.sequence_mask ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.contrib.seq2seq.sequence_loss tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼ 28
- 29. Bi-directional CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝ ļŗ© tf.nn.bidirectional_dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ® tf.map_fn stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.sequence_mask ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.contrib.seq2seq.sequence_loss tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼ 29
- 30. Stacked Bi-directional CellņØä ņé¼ņÜ®ĒĢśļŖö ļ░®ņŗØņØĆ Many to One ņ£ä CaseņÖĆ ļÅÖņØ╝ ļŗ© tf.contrib.rnn.stack_bidirectional_dynamic_rnnņØś return Ļ░Æņżæ outputsņØä ĒÖ£ņÜ® tf.map_fn stepļ¦łļŗż classifyļź╝ ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.sequence_mask ņøÉļל sequenceņŚÉ ļīĆĒĢ┤ņä£ļ¦ī lossļź╝ Ļ│äņé░ĒĢśĻĖ░ņ£äĒĢ┤ ĒÖ£ņÜ® tf.contrib.seq2seq.sequence_loss tf.sequence_maskņØś outputņØä weights argņŚÉ ņĀäļŗ¼ ļ░øņØī targets argņŚÉ [None, sequence_length]ņØś label ņĀäļŗ¼ 30
- 31. Seq2Seq eg. ļ¼ĖņןņØä ļ▓łņŚŁĒĢśļŖö RNN (with GRU)
- 32. Example data targets = [['ļéśļŖö', 'ļ░░Ļ░Ć', 'Ļ│ĀĒöäļŗż'], ['ĒģÉņä£ĒöīļĪ£ņÜ░ļŖö', 'ļ¦żņÜ░', 'ņ¢┤ļĀĄļŗż'], ['ĒģÉņä£ĒöīļĪ£ņÜ░ļŖö', 'ļöźļ¤¼ļŗØņØä', 'ņ£äĒĢ£', 'ĒöäļĀłņ×äņøīĒü¼ņØ┤ļŗż'], ['ĒģÉņä£ĒöīļĪ£ņÜ░ļŖö', 'ļ¦żņÜ░', 'ļ╣Āļź┤Ļ▓ī', 'ļ│ĆĒÖöĒĢ£ļŗż']] sources = [['I', 'feel', 'hungry'], ['tensorflow', 'is', 'very', 'difficult'], ['tensorflow', 'is', 'a', 'framework', 'for', 'deep', ['tensorflow', 'is', 'very', 'fast', 'changing']] 32
- 33. Example data sourcesņØśwordļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØ ņä▒ targetsņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒ # word dic for sentences source_words = [] for elm in sources: source_words += elm source_words = list(set(source_words)) source_words.sort() source_words = ['<pad>'] + source_words source_dic = {word : idx for idx, word in enumerate(source_words)} 33
- 34. Example data sourcesņØś wordļōżņØś idxļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö dictionary ņāØņä▒ targetsņØśwordļōżņØśidxļź╝Ļ░Ćņ¦ĆĻ│Āņ׳ļŖödictionary ņāØ ņä▒ # word dic for translations target_words = [] for elm in targets: target_words += elm target_words = list(set(target_words)) target_words.sort() # ļ▓łņŚŁļ¼ĖņØś ņŗ£ņ×æĻ│╝ ļüØņØä ņĢīļ”¼ļŖö 'start', 'end' token ņČöĻ░Ć target_words = ['<pad>']+ ['<start>'] + ['<end>'] + target_words target_dic = {word : idx for idx, word in enumerate(target_words)} 34
- 36. QnA
- 38. ļōżņ¢┤ņŻ╝ņģöņä£Ļ░Éņé¼ĒĢ®ļŗłļŗż. ┬Ā Github : github.com/aisolab ┬Ā Blog : aisolab.github.io ┬Ā E-mail : bsk0130@gmail.com