

Elastic Map Reduce 101
- 1. Intro to Using Hadoop on Amazon Cloud Ajay Ohri
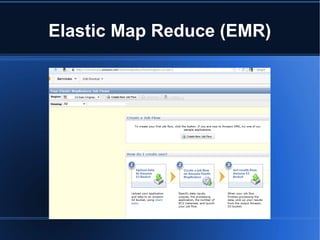
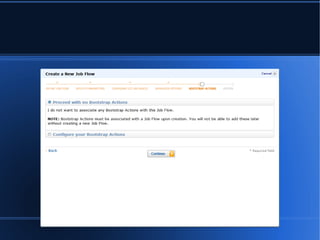
- 2. Elastic Map Reduce (EMR)
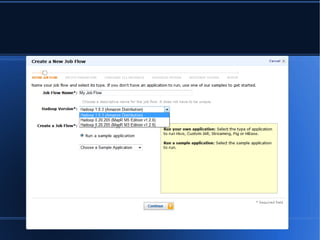
- 3. ’ü¼ ’ü¼
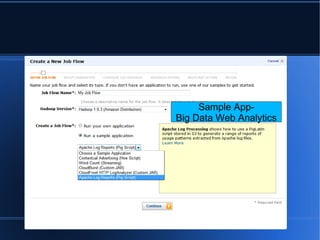
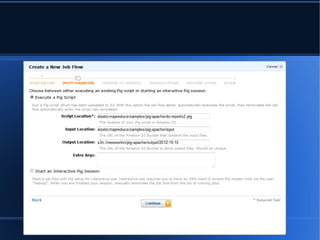
- 4. ’ü¼ Sample App- Big Data Web Analytics
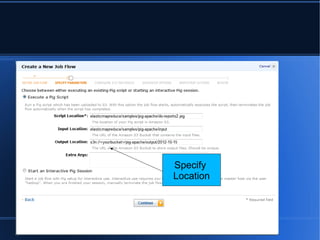
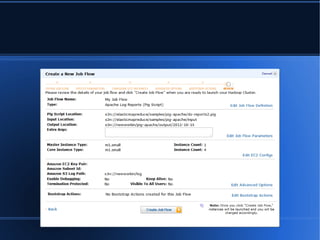
- 5. ’ü¼ ’ü¼ Specify Location
- 6. ’ü¼
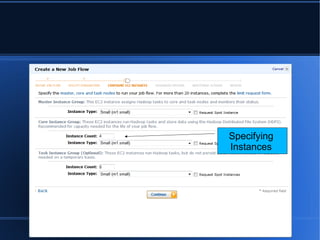
- 7. ’ü¼ Specifying Instances
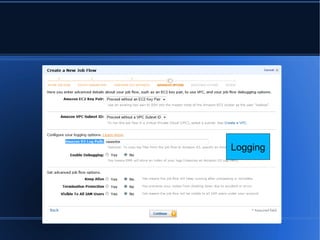
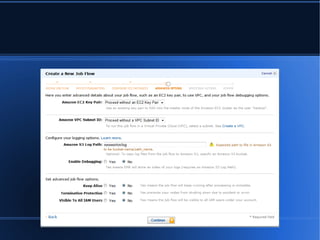
- 8. Logging
- 12. Next ’ü¼ Running R on Hadoop on Amazon EMR (for ordinary people!) ’ü¼ Wishlist- Easier Tutorials on Running optimized Parallel Processing on Big Data Jobs using Amazon EMR and R ŌĆō http://jeffreybreen.wordpress.com/2012/03/10/big-data-step-by-step-slides/ ’ü¼ Also see -segue package tutorial ’ĆŁ http://jeffreybreen.wordpress.com/2011/01/10/segue-r-to-amazon-elastic-mapreduce-hadoop/