Van experiment naar structurele oplossing: gezichtsherkenning in functie van metadatacreatie
Download as pptx, pdf0 likes40 views

Van experiment naar structurele oplossing: gezichtsherkenning in functie van metadatacreatie



















































Van experiment naar structurele oplossing: gezichtsherkenning in functie van metadatacreatie
- 2. ŌŚÅ organisatoren? ŌŚŗ Digitaal Archief Vlaanderen, meemoo, UGent en VRT ŌŚÅ waarom? ŌŚŗ delen van recente ontwikkelingen en innovatieve projecten op vlak van digitale preservering delen en samen problemen oplossen ŌŚÅ deelnemers? ŌŚŗ wetenschappers, studenten, onderzoekers, archivarissen, bibliothecarissen, dienstverleners en andere deskundigen iPRES 2024
- 4. Van experiment naar structurele oplossing: gezichtsherkenning in functie van metadatacreatie David Chambaere, Matthias Priem & Rony Vissers (meemoo)
- 6. Metadata ŌŚÅ Uitdaging ŌŚŗ beschrijvende metadata ontbreekt of is heel beknopt ŌŚÅ Cre├½ren en verrijken van metadata is tijdsintensief > dus duur ŌŚŗ herkennen van afgebeelde personen vereist veel kennis; ŌŚŗ vaak omvangrijke collecties die niet tot kerncollectie van organisatie behoren en dus geen prioriteit zijn; ŌŚŗ aard van materiaal zorgt voor extra drempels: Ō¢Ā om afgebeelde personen manueel te beschrijven, moeten videoŌĆÖs afgespeeld worden - wat zeer tijdsintensief is; Ō¢Ā zolang ze niet gedigitaliseerd zijn, zijn videoŌĆÖs niet of moeilijk afspeelbaar, waardoor het onmogelijk is om hun inhoud te beschrijven
- 7. Metadata ŌŚÅ Geautomatiseerde metadatacreatie of - verrijking m.b.v. artifici├½le intelligentie? ŌŚŗ Speech-to-Text ŌŚŗ Named Entity Recognition en Named Entity Linking ŌŚŗ Computer Vision Ō¢Ā Optical Character Recognition Ō¢Ā Face Detection en Face Recognition ŌŚŗ ...
- 9. Gezichtsherkenning ŌĆó FAME (FAce MEtadata): operationalisering van metadata-gedreven gezichtsherkenning in de registratiepraktijk
- 10. FAME ŌŚÅ Culturele organisaties slagen er onvoldoende in om omvangrijke collecties fotoŌĆÖs en videoŌĆÖs van goede metadata te voorzien. Dit tekort belemmert de online toegang en bevraging, alsook het hergebruik van digitale fotoŌĆÖs en videoŌĆÖs. ŌŚÅ Dit project ontwikkelt best practices om personen op die fotoŌĆÖs en videoŌĆÖs te identificeren via (semi-)geautomatiseerde gezichtsherkenning. ŌŚÅ Daarnaast onderzoekt dit project ook hoe bestaande metadata de accuraatheid van de gezichtsherkenning kunnen verbeteren.
- 11. FAME: partners ŌŚÅ Projectco├Črdinator: meemoo ŌŚÅ Technische partner: IDLab UGent ŌŚÅ Contentpartners: ŌŚŗ ADVN | archief voor nationale bewegingen ŌŚŗ archief van het Vlaams Parlement ŌŚŗ KOERS, museum van de wielersport ŌŚŗ Kunstenpunt ŌŚÅ Looptijd: maart 2021- september 2022
- 12. FAME: werkpakketten ŌŚÅ Werkpakket 1: voorbereidend onderzoek ŌŚÅ Werkpakket 2: pilootproject politici en activisten herkennen ŌŚÅ Werkpakket 3: pilootproject sportmensen herkennen ŌŚÅ Werkpakket 4: pilootproject podiumkunstenaars herkennen ŌŚÅ Werkpakket 5: rapportering en disseminatie ŌŚÅ Werkpakket 6: projectadministratie
- 13. FAME: terminologie ŌĆó Gezichtsdetectie: het lokaliseren van gezichten op een foto of in een video ŌĆó Gezichtsherkenning: het toekennen van een naam aan een gezicht ŌĆó Referentieset: portretfotoŌĆÖs waarvan we door metadata weten wie er op staat ŌĆó Onderzoeksset: portretfotoŌĆÖs, groepsfotoŌĆÖs en allerhande andere fotoŌĆÖs waarvan we willen weten wie erop staat
- 14. Onderzoeksset: fotoŌĆÖs en videoŌĆÖs ŌŚÅ In totaal: 154.287 foto's en 9 video's: ŌŚŗ podiumkunstenaars: Ō¢Ā 19.576 foto's en 2 videoŌĆÖs van Kunstenpunt; ŌŚŗ wielrenners: Ō¢Ā 123.911 fotoŌĆÖs van KOERS; ŌŚŗ politici: Ō¢Ā 5.587 foto's en 3 videoŌĆÖs van ADVN; Ō¢Ā 5.213 fotoŌĆÖs en en 4 videoŌĆÖs van archief van Vlaams Parlement; Ō¢Ā in totaal: 10.800 fotoŌĆÖs en 7 videoŌĆÖs. ŌŚÅ Oorspronkelijk meer videomateriaal in onderzoeksset voorzien: ŌŚŗ tijdsgebrek ŌŚŗ opstart luik gezichtsherkenning in GIVE-metadataproject
- 15. Onderzoeksset: videoŌĆÖs ŌŚÅ VideoŌĆÖs omgezet in reeks van stilstaande beelden > doorlopen nadien dezelfde workflow als fotoŌĆÖs ŌŚÅ VideoŌĆÖs bestaan vaak uit 25 stilstaande beelden (frames) per seconde > 1 uur video = 90.000 frames of fotoŌĆÖs ŌŚÅ Volstaat om beperkt aantal frames te analyseren uit shot dat persoon afbeeldt! ŌŚÅ Willen weten van welk moment tot welk ander moment persoon in beeld komt ŌŚÅ Shots gezocht in videoŌĆÖs: shot detection m.b.v. PySceneDetect ŌŚÅ Uit ieder shot 3 willekeurige frames gekozen waarop gezichtherkenningsworkflow toegepast werd ŌŚÅ Voorbeeld: video van 103.500 frames (72 min) > 714 frames of stilstaande beelden
- 16. Referentieset ŌŚÅ Gezichtsherkenning werkt op basis van vergelijking van gezichten > referentieset ŌŚÅ In totaal 54.540 portretfotoŌĆÖs van in totaal 6.075 verschillende personen aangelegd ŌŚŗ podiumkunstenaars: Ō¢Ā 2.393 podiumkunstenaars in referentieset (37.172 referentiefotoŌĆÖs); Ō¢Ā richtgetal: 3.982 te herkennen personen; ŌŚŗ wielrenners: Ō¢Ā 2.791 wielrenners in referentieset (15.323 referentiefotoŌĆÖs); Ō¢Ā geen richtgetal voor te herkennen personen; ŌŚŗ politici: Ō¢Ā 891 politici in referentieset (2.045 referentiefotoŌĆÖs) Ō¢Ā geen richtgetal voor te herkennen personen.
- 17. Samenstelling referentieset: metadata ŌŚÅ Samenstelling van referentiesets is waar mogelijk gebaseerd op beschikbaarheid van bestaande metadata. ŌŚŗ Podiumkunstenaars: Ō¢Ā ontleden pad- en bestandsnamen Kunstenpunt > naam podiumkunstenproducties > ophalen van namen van betrokken podiumkunstenaars uit Wikidata Ō¢Ā vereiste dataschoning en reconciliatie Ō¢Ā Wikidata: enkel data vanaf 1990 ŌŚŗ Politici: Ō¢Ā aanspreken Vlaams Parlement Open Data endpoint: data alle huidige en gewezen vertegenwoordigers, plus detailinformatie over vergaderingen en commissies Ō¢Ā ADVN: authority-databank over de personen in het archief nog in ontwikkeling ŌŚŗ Wielrenners: Ō¢Ā waar mogelijk gebruik gemaakt van gegevens van gespecialiseerde websites over wielersport
- 18. Samenstelling referentieset: metadata ŌŚÅ Identifiers overgenomen uit Wikidata voor personen die we willen herkennen > personen ondubbelzinnig ge├»dentificeerd ŌŚÅ Maar ook: ŌŚŗ podiumkunstenaars: identifiers voor personen uit Kunstenpuntdatabank ├®n IMDb; ŌŚŗ politici: identificatiecodes van Vlaams Parlement ├®n Belgische Senaat voor personen; ŌŚŗ wielrenners: identifiers van De Wielersite en ProCyclingStats voor personen. ŌŚÅ Afkomst referentiefotoŌĆÖs: ŌŚŗ collectiebeherende projectpartners; ŌŚŗ enkele andere archieven (o.a. Amsab-ISG, KADOC, Liberas); ŌŚŗ Wikimedia Commons; ŌŚŗ world wide web.
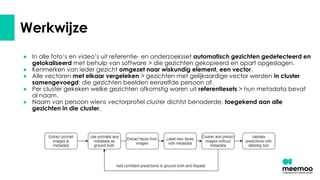
- 19. Werkwijze ŌŚÅ In alle fotoŌĆÖs en videoŌĆÖs uit referentie- en onderzoeksset automatisch gezichten gedetecteerd en gelokaliseerd met behulp van software > die gezichten gekopieerd en apart opgeslagen. ŌŚÅ Kenmerken van ieder gezicht omgezet naar wiskundig element, een vector. ŌŚÅ Alle vectoren met elkaar vergeleken > gezichten met gelijkaardige vector werden in cluster samengevoegd: die gezichten beelden eenzelfde persoon af. ŌŚÅ Per cluster gekeken welke gezichten afkomstig waren uit referentiesets > hun metadata bevat al naam. ŌŚÅ Naam van persoon wiens vectorprofiel cluster dichtst benaderde, toegekend aan alle gezichten in die cluster.
- 21. Manuele validatie ŌŚÅ Doel: bekomen van zo betrouwbaar mogelijke gezichtsherkenningsresultaten. ŌŚÅ Medewerkers van collectiebeherende organisaties konden automatisch bekomen resultaten valideren met behulp van online tool. ŌŚÅ Toekennen validatielabels aan herkende gezichten: ŌĆśgeaccepteerdŌĆÖ, ŌĆśgeweigerdŌĆÖ of ŌĆśongeschiktŌĆÖ. ŌŚÅ ŌĆśOngeschiktŌĆÖ: geen gezicht afgebeeld, of foto te onduidelijk om gezicht te herkennen. ŌŚÅ Aantal te labelen gezichten beperkt > filtering (op basis van similariteitsscore) ŌŚÅ Iedere collectiebeherende organisaties valideerde resultaten eigen collectie. ŌŚÅ Niet alle aangeboden resultaten gevalideerd, wel zeer groot aantal. ŌŚÅ Mate van validatie niet bij alle collectiebeherende organisaties dezelfde.
- 22. Similariteitsscore ŌŚÅ In FAME gewerkt met similariteitsscore. ŌŚÅ Duidt mate van gelijkenis van gezicht en met andere gezichten in cluster automatisch aan > probabliteit. ŌŚÅ In combinatie met gebruik van validatietool berekend in hoeverre resultaten met similariteitscore van 0,5 als betrouwbaar werden beschouwd door medewerkers van collectiebeherende organisaties.
- 23. Betrouwbaarheid ŌŚÅ Vaststelling: automatisch herkende gezichten met similariteitsscore van minstens 0,5 zijn gemiddeld 93,6 % betrouwbaar: ŌŚŗ Kunstenpunten: idem > 93,6%; ŌŚŗ KOERS en ADVN: hoger > respectievelijk 94,8% en 99,8%; ŌŚŗ Archief van Vlaams Parlement: lager > 82,7%.
- 24. Relevantie similariteitsscore ŌŚÅ Indien collectiebeherende instellingen zeer kleine foutenmarge aanvaarden, kunnen ze al deze resultaten opnemen in hun beheersystemen, zonder dat ze zelf (alles) moeten valideren > verhoudingsgewijs vooral grote winst voor Kunstenpunt doordat zij relatief weinig resultaten hebben gevalideerd met similariteitsscore van minstens 0,5. ŌŚÅ Toekomstige projecten organisaties die manuele en tijdsintensieve validatie willen vermijden kunnen similaiteitsscore van 0,5 of hoger hanteren als drempel voor automatisch aanvaarden van resultaten > zekerheid van resultaten met zeer grote mate van betrouwbaarheid hebben, zonder manuele validatie.
- 25. Bruikbare eindresultaten 1 ŌŚÅ Indien enkel rekening gehouden met resultaten van manuele validatie door medewerkers van collectiebeherende instellingen: 78.440 herkende gezichten van 1.693 unieke publieke personen (= 27,9% van personen uit aangelegde referentieset): ŌŚŗ 2.818 herkende gezichten van 125 unieke podiumkunstenaars; ŌŚŗ 63.397 herkende gezichten van 953 unieke wielrenners; ŌŚŗ 12.225 herkende gezichten van 616 unieke politici.
- 26. Bruikbare eindresultaten 2 ŌŚÅ Indien Kunstenpunt tevreden met betrouwbaarheid van 93,6% > toevoeging van groot aantal herkende gezichten en unieke podiumkunstenaars mogelijk ŌŚÅ Nieuwe eindresultaat: 81.144 gezichten van 2.578 unieke publieke personen (= 42,4% van personen uit door ons aangelegde referentieset). ŌŚÅ Maar: kans dat klein aantal gezichten van podiumkunstenaars en unieke podiumkunstenaars foutief automatisch zijn herkend.
- 27. Juridische aspecten ŌŚÅ Auteursrecht ŌŚŗ auteursrechtelijk beschermde fotoŌĆÖs en videoŌĆÖs; ŌŚŗ beroep op de onderwijs- en onderzoeksexceptie. ŌŚÅ Recht op afbeelding ŌŚŗ toelating nodig voor maken en gebruiken van afbeelding van persoon, en ook voor iedere reproductie en publicatie daarvan; ŌŚŗ keuze voor publieke personen: toestemming vermoed, op voorwaarde dat afbeeldingen zijn gemaakt tijdens uitoefening van publieke activiteit.
- 28. Juridische aspecten ŌŚÅ Algemene Verordening Gegevensbescherming (AVG of GDPR) ŌŚŗ maken, opslaan en gebruiken fotoŌĆÖs met personen is verwerking van (persoons)gegevens > strikt gereglementeerd: verwerking van ŌĆśbiometrischeŌĆÖ gegevens met het oog op identificatie enkel mogelijk mits uitzondering; ŌŚŗ verwerking is noodzakelijk voor vervulling van decretale opdracht; ŌŚŗ versoepeld regime met oog op archivering in algemeen belang. ŌŚÅ Terms of Service sociale mediaplatformen
- 29. Ethische aspecten ŌŚÅ Samenstelling referentiesets ŌŚŗ keuze voor publieke figuren beperkt impact op priv├®- personen; ŌŚŗ afweging uiteindelijke doel tegenover eventuele negatieve gevolgen voor afgebeelde personen; ŌŚŗ delen van referentiesets? effici├½ntiewinst, maar ook gevaar op verlies aan controle > nood aan beroepsethiek. ŌŚÅ Vooringenomenheid (bias) in algoritmes ŌŚŗ zorgvuldig gecre├½erde referentiesets; ŌŚŗ controle van gebruikte algoritme op bias aan hand van manuele steekproef: worden alle mensen even goed herkend worden, ongeacht hun fysieke eigenschappen of kledij?
- 30. Ethische aspecten ŌŚÅ Automatisering als bedreiging voor jobs ŌŚŗ focus: automatisering van werk dat vandaag wegens tijdgebrek / personeelstekort niet gebeurt; ŌŚŗ samenwerking tussen mens en algoritme blijft cruciaal. ŌŚÅ Werkomstandigheden van data labellers ŌŚŗ we weten wie door ons gebruikte toolbox Insightface heeft ontwikkeld, maar niet met welk doel en in welke omstandigheden dat is gebeurd; ŌŚŗ aandachtspunt: manier waarop cultureelerfgoedorganisaties manuele validatie van matchingresultaten aanpakken. ŌŚÅ Impact op het milieu ŌŚŗ vergt veel rekenkracht en energie; ŌŚŗ energie mogelijk niet afkomstig uit hernieuwbare bronnen; ŌŚŗ aandachtspunten: terugdringen van nefaste effecten (bv. door energie-effici├½ntere workflows en algoritmes) en transparantie.
- 31. Lessons learned ŌŚÅ Bottlenecks: ŌŚŗ samenstelling van namenlijsten en referentiesets > tijdsintensief ŌŚŗ manuele validatie > tijdsintensief ŌŚÅ Beschikbare informatiebeheersystemen zijn vandaag vaak niet voorzien op wegschrijven van dergelijke (complexe) beschrijvende metadata ŌŚÅ Juridische en ethische aspecten blijven belangrijke aandachtspunten
- 33. GiVE Metadata - Scope Spraakherkenning (Speech-To-Text of STT) - Input: audio (uit zowel audio als video files) - Output: transcripties Entiteitsherkenning (Named Entity Recognition of NER) - Input: transcripties - Output: metadata updates met semantiek en links naar authentieke bronnen (bvb. wikidata) Gezichtsdetectie & Herkenning - Input: video - Output: metadata updates met herkende personen Over alles heen: 1/ uniforme metadata 2/ gelinkt aan externe authorities (bvb. wikidata)
- 34. Schaal ŌŚÅ 126 contentpartners betrokken ŌŚÅ Per activiteit ŌŚŗ Spraakherkenning en Entiteit Herkenning : 130.000 gearchiveerde stuks of 160.000 uur media ŌŚŗ Gezichtsdetectie en -herkenning : 100.000 gearchiveerde stuks of 120.000 uur media Dit is 5500 keer meer data dan in FAME
- 35. Schaalvergroting: uitdagingen ŌŚÅ Oplossing die werkt op grote schaal, voor veel partners ŌŚŗ Communicatie en samenwerking ŌŚŗ Juridische en ethische vraagstukken ŌŚŗ Technische uitdagingen Ō¢Ā software : zo ontworpen dat het snel geschaald kan worden Ō¢Ā hardware : cloud gebaseerd, snel uitbreiden en inkrimpen ŌŚÅ Kwalitatieve aspect ŌŚŗ Manuele validatie is niet langer mogelijk ŌŚŗ Grondige parametrisering, vertrouwen en goed gekozen thresholds worden cruciaal
- 36. Veel partners ŌŚÅ We werken met materiaal van heel veel partners ŌŚÅ Vaak ook nieuwe uitdagingen / inzichten ŌŚÅ Informatie via communicatieplan ŌŚÅ Betrokkenheid via werkgroep ŌŚŗ krijgen meer in-depth informatie ŌŚŗ bepalen mee wat we doen en niet doen Ō¢Ā parametrisering gezichtsherkenning Ō¢Ā beheer referentieset gezichten Ō¢Ā workshops rond ethiek Ō¢Ā feedback op functionaliteit Ō¢Ā feedback op wireframes Brede oproep naar alle 120 partners, uiteindelijk +/- 10 partners vertegenwoordigd.
- 37. Juridische aspecten ŌĆó AI toepassen: het kan volgens GDPR (archivering in het algemeen belang) ŌĆó Maar DPIA is nodig want: ŌĆó Grootschalige verwerking ŌĆó ŌåÆ Aantal betrokkenen ŌĆó ŌåÆ Volume van de gegevens ŌĆó ŌåÆ Duur van de activiteit ŌĆó Creatie van nieuwe metadata kan linken leggen tussen personen en lidmaatschap vakbond/etniciteit/politieke voorkeurŌĆ” ŌåÆ Verwerking van ŌĆśbijzondere categorie├½n persoonsgegevensŌĆÖ
- 38. Data Protection Impact Assessment ŌŚÅ Deel 1 : omschrijf wat je wil doen ŌŚŗ Algemene beschrijving beoogde verwerking ŌŚŗ Beschrijving type persoonsgegevens ŌŚŗ Doel van de verwerking ŌŚŗ Bronnen van de persoonsgegevens ŌŚŗ Betrokkenen ŌŚÅ Deel 2 : Risico analyse ŌŚŗ Wat zijn de taken in het project? ŌŚŗ Welke risico's zijn hieraan verbonden? ŌŚŗ Hoe gaan we deze minimaliseren? ŌćÆ Checklist voor privacy aspecten binnen project
- 39. Ethische aspecten ŌŚÅ ism. Kenniscentrum data & maatschappij ŌŚÅ Meerdere workshops, focus op gezichtsherkenning ŌŚŗ breng alle stakeholders samen Ō¢Ā archivarissen, personen die herkend zullen worden, technici ŌŚŗ Probeer tot een principes document te komen of gedeeld inzicht / proces ŌŚŗ Bvb. referentielijst Ethische / juridische conclusies worden samengevat & gedeeld
- 40. Technische aspecten - kopen of bouwen? Spraakherkenning (Speech-To-Text of STT) - Mature tooling op de markt - Kosteneffici├½nte oplossing, makkelijk te integreren Entiteitsherkenning (Named Entity Recognition of NER) - Mature tooling op de markt - Kosteneffici├½nte oplossing, makkelijk te integreren Gezichtsdetectie & Herkenning (Face detection and recognition) - Deels beschikbaar op de markt - Hoge kost per uur - Reeds kennis opgedaan via FAME ŌćÆ KOPEN ŌćÆ KOPEN ŌćÆ BOUWEN
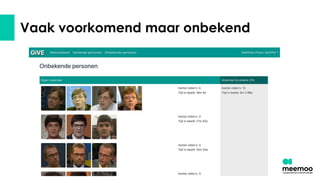
- 41. ŌŚÅ Gezichtsdetectie ŌŚŗ identificeer een stuk van een beeld als 'gezicht' en stop in een cluster voor een persoon ŌŚÅ Gezichtsherkenning ŌŚŗ ga na of er een match is tussen de persoon en iemand in de referentieset ŌŚÅ Vaak voorkomende 'onbekenden' ŌŚŗ Kunnen we veel voorkomende, niet gematchte gezichten aanbieden aan de archivaris (om toe te voegen aan de referentieset) ŌŚÅ Daarnaast: beheer van de referentieset ŌŚŗ hergebruik van de bestaande set uit FAMe ŌŚŗ kunnen we komen tot gedeeld beheer? Gezichtsherkenning - Wat willen we?
- 42. Gezichtsherkenning - Video Pipeline Face Detection Face Tracking Face Clustering Face Embedding Face Matching Video pipeline Faces Persoon 0 Goede gelijkenis Zelfde persoon Subset obv kwaliteit
- 43. Gezichtsherkenning - parameters Gezichtskwaliteit ŌŚÅ Box-grootte ŌŚÅ Pose (landmarks) ŌŚÅ Belichting ŌŚÅ Blurriness ŌŚÅ Confidence Schermtijd ŌŚÅ Duur van gezicht binnen 1 shot (tracker) ŌŚÅ Aantal keer dat gezicht terugkomt (aantal trackers per persoon) ŌŚÅ Totale schermtijd van 1 persoon in video
- 44. Nu: parametrisering met werkgroep Oranje gezichten komen te kort voor (bv. kort shot binnen reportage); gezichten in de achtergrond leveren vaak geen metadata op omdat ze te klein zijn 05:48 http://give-face- qas.private.cloud.meemoo.be/task_results/baba7b5ef1d2459180c2ea8fffa49d02cf2aed7b29ba41758f43c7e1eae 457a1b6a6377d6b4d4e2c8b032c69a4597bbc_af862059c93c6475d5320919c7c48b7d 2:00 http://give-face- qas.private.cloud.meemoo.be/task_results/99496d03b4904e1fa23c6b0a203d36db8651dc32f64049bb995ffd93d bc395c28cb9a1f48db84a5c9b10192aba6e9d2c_af862059c93c6475d5320919c7c48b7d
- 45. Gezichtsherkenning - werken op schaal ŌŚÅ Verwerking opgedeeld in kleine (micro)services ŌŚŗ doen 1 bepaalde taak en geven resultaat door ŌŚŗ kan geparallelliseerd worden ŌŚÅ Effectieve processing in de cloud ŌŚŗ Snelle opschaling en ook downscaling ŌŚŗ 120k uur verwerkt op 10 weken ŌŚŗ Tijdens verwerking ingezien dat het te lang zou duren: Ō¢Ā dubbel zoveel hardware ingezet Ō¢Ā verwerkingstijd kunnen halveren Alle machine learning algoritmes die we gebruikten zijn open source, voorgetrainde modellen. Geen specifieke training nodig.
- 46. Gezichtsherkenning - tussentijdse resultaten - Gezichtsdetectie - Loopt 1x om alle gezichten te detecteren op alle archieven - heel rekenintensief, tientallen nodes actief om verwerking te doen - verwerking alle videoŌĆÖs afgelopen (10 weken) - 3,3 mio personen gedetecteerd (~ 27 per video) - Gezichtsherkenning (matching) - Referentie set (+ referentieset beheer) - Loopt herhaaldelijk (vergelijking van alle video vs refset duurt +/- 2 uur) - extra persoon aan de referentieset toegevoegd ŌćÆ mogelijk nieuwe matches. - 208.000 personen gelinkt aan 2500 personen uit de huidige referentieset
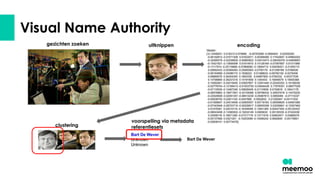
- 47. Referentieset ŌŚÅ Essentie ŌŚŗ Een lijst van personen + foto's + links naar wikidata + authorities CP's ŌŚŗ Gedeeld beheer, steunen op elkaars kennis (bvb. Koers / Huis van Alijn) ŌŚŗ Transparantie rond aanpassingen (wie, wat, wanneer) ŌŚÅ Cruciale schakel ŌŚŗ Referentieset maakt de brug tussen detectie en matching ŌŚŗ Ethisch: iemand in de referentieset steken betekent die persoon herkennen Ō¢Ā Belangrijk dat het een mens is die dit uitvoert
- 48. Beheer van de referentieset
- 49. Beheer van de referentieset - aanpassen
- 50. Beheer van de referentieset - historiek
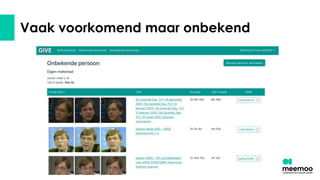
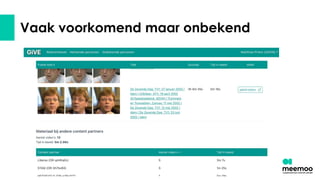
- 51. Vaak voorkomend maar onbekend
- 52. Vaak voorkomend maar onbekend
- 53. Vaak voorkomend maar onbekend
- 54. Dit project kadert binnen het relanceplan Vlaamse Veerkracht en wordt gerealiseerd met de steun van het Europees Fonds voor Regionale Ontwikkeling.
- 55. Andere projecten en toekomst
- 56. Toekomst en andere projecten ŌŚÅ SHARED AI ŌŚŗ Oktober 2023 - Dec 2024 ŌŚŗ GiVE project, maar voor regionale media + VRT ŌŚÅ Visual Name Authority ŌŚŗ 2023 - 2026 (3 fases, 3 jaar) ŌŚŗ Project waarin we overkoepelende namenlijst en gedeelde referentieset breder inzetbaar willen maken ŌŚŗ Processen, juridisch, ethische kwesties ŌŚŗ Maar ook de bouw van een tool