




















![29
Migration example
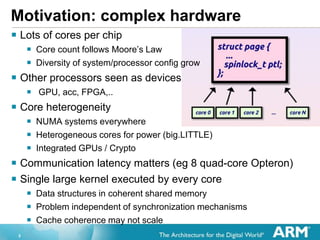
static void span_complete(void *arg, errval_t err)
{
span = 1;
}
int main(int argc, char *argv[])
{
domain_new_dispatcher(1, &span_complete, 0);
while(!span) thread_yield();
domain_thread_move_to(thread_self(), 1);
printf("MOVEDn");
return 0;
}](https://image.slidesharecdn.com/53e0a7a2-35a1-467b-8313-c610c31ee9ed-151025114325-lva1-app6891/85/bfarm-v2-29-320.jpg)


![36
Timing considerations
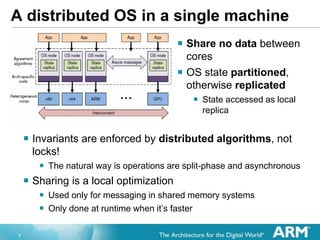
? Linux thread migration can take up to ~60 ¦Ěs to 100 ¦Ěs
? There is no apparent difference to migrate a thread for the first time
and do it successive times
? Barrelfish thread migration can take
? Creating a new dispatcher: up to 26 milliseconds!! Due to the
duplication of the virtual memory map (hundreds of [blocking] RPC
calls to the memory server process)
? Migrating the thread to the new dispatcher takes about 68 ¦Ěs, similar
to Linux](https://image.slidesharecdn.com/53e0a7a2-35a1-467b-8313-c610c31ee9ed-151025114325-lva1-app6891/85/bfarm-v2-36-320.jpg)


bfarm-v2
- 1. 1 Barrelfish OS on ARM Zeus G¨®mez Marmolejo, Matt Horsnell
- 2. 2 About myself ? PhD student at Barcelona Supercomputer Center ? Interests in Operating Systems ? Designed ZeOS, used now in Operating System Project in FIB/UPC ? Focus on new OS ideas, like Barrelfish ? Hardware and FPGAs ? Designed Zet, an open source x86 processor booting Windows ? ARM Norway, prototyping Mali-400 in FPGA ? ARM R&D since October 2012
- 4. 4 Barrelfish introduction ? Research operating system built by ETH Zurich ? With the assistance of Microsoft Research in Cambridge ? Supported architectures: ? 32- and 64-bit x86 AMD/Intel ? Intel Single-chip Cloud Computer ? Intel MIC (Xeon Phi) ? ARM v7 (& Xscale) ? Beehive (experimental softcore) ? First snapshot in September 2009 ? MIT open source license ? Many contributors: www.barrelfish.org
- 5. 5 Motivation: complex hardware ? Lots of cores per chip ? Core count follows MooreˇŻs Law ? Diversity of system/processor config grow ? Other processors seen as devices ? GPU, acc, FPGA,.. ? Core heterogeneity ? NUMA systems everywhere ? Heterogeneous cores for power (big.LITTLE) ? Integrated GPUs / Crypto ? Communication latency matters (eg 8 quad-core Opteron) ? Single large kernel executed by every core ? Data structures in coherent shared memory ? Problem independent of synchronization mechanisms ? Cache coherence may not scale
- 6. 6 Motivation II: hardware diversity ? Hardware is changing and diversifying (SoCs) ? Devices increasingly programmable ? Less fraction of code controlled by a conventional OS ? We donˇŻt know how machines will look like in the future ? HPC systems tuned for a single machine ? HW changes faster than System Software ? Evolving monolithic kernels is hard (eg RCU Linux, Win7 disp lock) ? Become obsolete as hardware changes (tradeoff donˇŻt stay const)
- 7. 7 A distributed OS in a single machine ? Share no data between cores ? OS state partitioned, otherwise replicated ? State accessed as local replica ? Invariants are enforced by distributed algorithms, not locks! ? The natural way is operations are split-phase and asynchronous ? Sharing is a local optimization ? Used only for messaging in shared memory systems ? Only done at runtime when itˇŻs faster
- 8. 8 Why the name Barrelfish? ItˇŻs a container for different kind of fish There are a number of DSL for OS development, most of them written in Haskell: ? Hake. Dependency driven build system that generates the Makefile ? Flounder. Asynchronous message passing infrastructure ? Fugu. DSL for error definition ? Mackerel. A strawman device definition DSL ? Molly. Simple boot loader for M5 ? Hamlet. DSL for capability definition ? Elver. Intermediate stage bootloader to switch to 64-bit.
- 9. 9 System Knowledge Base ? General name server / service registry ? Coordination service / lock manager ? Device management ? Driver startup / hotplug ? PCIe bridge configuration ? A surprisingly hard CSAT problem! ? Intra-machine routing ? Efficient multicast tree construction ? Port of popular ECLiPse CLP system ? Constraint Logic Programming ? Very expressive but quite slow ? It holds practical info from the system: ? Number of cores, topology of the interconnect, memory
- 10. 10 Barrelfish is a research OS ? It is good for systems research ? ItˇŻs very small compared to other OS ? Some disadvantages ? It is written by students ? There is a lot of missing functionality ? No shared libraries (executables are very big) ? Many missing drivers (only few supported configurations) ? No graphics ? A lot of unconnected ideas tested at the same time ? Haskell with some specific libraries ? Specific languages designed like THC ? CLP solver for device configuration for SKB ? Specific DSL for device definition, message interfaces,... ? Big learning curve and almost inexistent documentation
- 11. 11 What runs on Barrelfish? ? Many micro benchmarks ? Parallel benchmarks: Parsec, SPLASH-2, NAS ? Web server: http://www.barrelfish.org/ ? Databases: SQLite, PostgreSQL, other... ? OpenSSH server, etc. ? Virtual machine monitor ? Linux kernel binary ? Microsoft Office 2010! ? Via Microsoft Drawbridge
- 12. 12 Barrelfish booting on x86_64
- 13. 13 ARM BARRELFISH AND GEM5
- 14. 14 Purpose of internship Porting Barrelfish OS to the ARMv7 gem5 model ? When announced, only capable of booting on x86 models of Gem5 ? It could also boot an ARMv5 system in Qemu ? But not on the current ARMv7 Gem5 model Motivations: ? Great extensible tool for operating system development: ? Easy to extend and change the ˇ°hardwareˇ± to see changes in the OS ? Gem5 in being used in ARM R&D for internal simulation benchmarks
- 15. 15 Gem5 port Status ? First half of 2012 Samuel Hitz at ETH did it as BSc thesis ? It was not working on Gem5 ? Lots of new ARM code added for the Panda board ? Made Gem5 specific code not working ? Work done ? Search for the specific mercurial revision that was working (Samuel branch) ? ARM GCC > 4 (up to 4.7) has a bug with inline functions, updated #pragmas all over the ARM Barrelfish code ? Gem5 Versatile Express VLT old platform used ? Discussion & port to the new Versatile EMM platform ? Patch submitted and accepted ? Release 2013-01-11 with all ARM architectures working ?
- 16. 16 Problems regarding ARM ? Lots of configurations ? SoC ? memory maps ? devices ? Cannot be solved using SKB because ? Booting code and module loader need to know the memory map (physical addressing) ? Initial page table setup needs also memory map ? Console driver (starts before SKB) needs device address ? PIC and other controllers needed before SKB ? Planned static configuration for different platforms ? Haskell used for that, using C template common procedures ? Generated C code ? Available for Gem5, panda board, etc...
- 17. 17 ARM Barrelfish booting on Gem5
- 18. 18 Future directions ? Problems we had ? Merge with Panda board and other ARM configurations made us to wait too long ? Too much engineering work and very little research ? O3CPU model port ? Current code runs on O3 but single core ? Some problems with speculative execution ? Now they can be addressed as the tip is merged with other ARM configurations ? ARMv8 port of Barrelfish ? Barrelfish is a 64 bit native operating system ? Backported to Intel 32 for the SCC experiments ? ARMv8 should use x86_64 as the base port ? ARMv8 and Gem5 as emulation target
- 20. 20 New research topic ? Following Timothy Roscoe visit to Cambridge on 26th Nov ? Memory coherence islands ? Barrelfish networked and hierarchical clustering ? Process migration ? Due to ARM big.LITTLE architecture and future trend ? Possible research on heterogeneous scheduling ? Global vs. Local scheduling ? Is it possible in Barrelfish? Motivation ? Barrelfish heterogeneous design favouring ? Specific per-core scheduling ? Policies for thread migration ? No shared memory requirement among heterogeneous cores
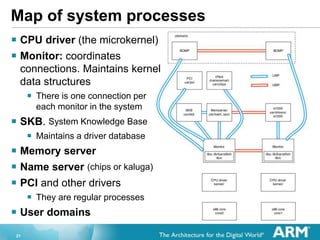
- 21. 21 Map of system processes ? CPU driver (the microkernel) ? Monitor: coordinates connections. Maintains kernel data structures ? There is one connection per each monitor in the system ? SKB. System Knowledge Base ? Maintains a driver database ? Memory server ? Name server (chips or kaluga) ? PCI and other drivers ? They are regular processes ? User domains
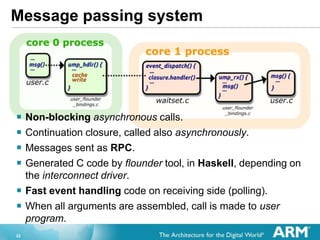
- 22. 22 Message passing system ? Non-blocking asynchronous calls. ? Continuation closure, called also asynchronously. ? Messages sent as RPC. ? Generated C code by flounder tool, in Haskell, depending on the interconnect driver. ? Fast event handling code on receiving side (polling). ? When all arguments are assembled, call is made to user program.
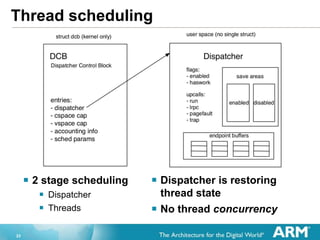
- 23. 23 Thread scheduling ? 2 stage scheduling ? Dispatcher ? Threads ? Dispatcher is restoring thread state ? No thread concurrency
- 24. 24 Thread migration in Linux ? One run-queue per core (from v2.6) ? load_balance() is called: ? When schedule() finds a runqueue with no runnable tasks ? Every tick when system is idle ? Every 100ms otherwise ? load_balance() looks for the busiest runqueue and takes a task that is (in order of preference): ? inactive (likely to be cache cold) ? high priority ? When decided to migrate, an IPI is sent to source core ? Migration/source thread executes, creates a new task (it cannot block) ? The new task removes thread from runqueue, then IPI to dest core ? Recv core gets IPI, schedules migr task (high prio), adds thread to runqueue
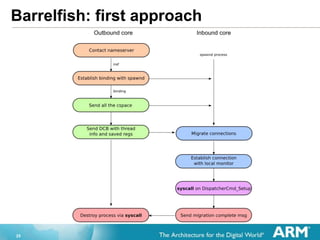
- 26. 26 First approach (II) 1. Contact the nameserver and get the iref for the spawnd process in core y 2. Establish a binding to the spawnd 3. Send the capability space (cspace) entirely (that would mean copying the page tables, thread stacks, binary images, allocated pages, etc...) via IDC 4. Send the Dispatcher Control Block with all thread information and saved registers 5. Wait from message from core y for dispatcher completion 6. Destroy process via syscall. Spawnd on core y: 1. Migrate connections on new dispatcher. LMP connections are changed to UMP 2. Establishes connection with local monitor and sets it up in place of the previous one. 3. Spawnd on core y performs a syscall SYSCALL_INVOKE on the DispatcherCmd_Setup, where the kernel insert the new dispatcher into the running queue and sets de new cspace and vspace. 4. After call, send a message to spawnd on core x telling that migration is completed.
- 27. 27 Thread migration problems ? Other systemsˇŻ processes ? As there is no shared memory, all is message passing ? What happens with existing connections? ? Open files are also connections ? What about the name server, which is tracking coreˇŻs processes ? The memory server keeps track of allocated pages to cores ? The monitor LMP connection has to be re-established ? User domains are very hardware bound, not ˇ°neutralˇ± ? Distributed scheduling ? There is no centralized process to do that. It would be not efficient ? There is no per-core load tracker ? No load balancer ? It has to be done in the user domain
- 28. 28 Second approach Use the possibility of having 2 dispatchers per domain 1. Create a new dispatcher for the current domain on the destination core ? Extend vspace to the destination core (use the monitor for that) 2. Migrate the thread using IDC This way application is always aware about whatˇŻs going on
- 29. 29 Migration example static void span_complete(void *arg, errval_t err) { span = 1; } int main(int argc, char *argv[]) { domain_new_dispatcher(1, &span_complete, 0); while(!span) thread_yield(); domain_thread_move_to(thread_self(), 1); printf("MOVEDn"); return 0; }
- 30. 30 Creating a new dispatcher 1. Get the memory from memory server for the remote dispatcher 2. Create the thread for the new dispatcher to init on (unrunnable) 3. Create new dispatcher frame 4. Set and setup dispatcher on the new thread 5. Send the vroot to the monitor 6. Establish the inter-dispatcher message channel 7. Create 2 event handlers (threads) in the source dispatcher ? For the default waitset (events coming from mem server and monitor) ? For the interdisp waitset (events from the other dispatcher)
- 31. 31 Moving thread to destination dispatcher 1. Get the next thread to be run, in the list of threads 2. Remove the current thread from the queue 3. Disable it and wake it up on dest coreid by sending IDC msg ? Check if the domain has been spawned to that core 4. If it fails, re-enqueue the thread in the current queue 5. Run next thread in queue ? There are minimum 2 more: those handling the waitsets ? If original application only had 1 thread, only event dispatchers remain executing
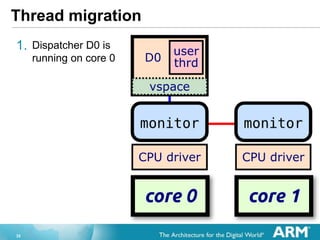
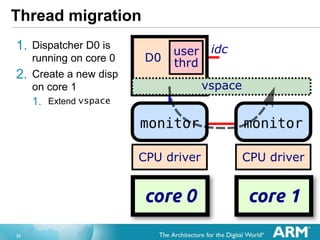
- 32. 32 Thread migration 1. Dispatcher D0 is running on core 0
- 33. 33 Thread migration 1. Dispatcher D0 is running on core 0 2. Create a new disp on core 1 1. Extend vspace
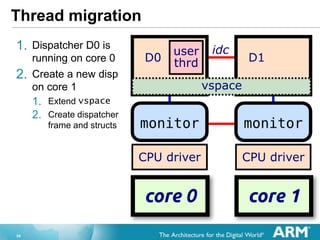
- 34. 34 Thread migration 1. Dispatcher D0 is running on core 0 2. Create a new disp on core 1 1. Extend vspace 2. Create dispatcher frame and structs
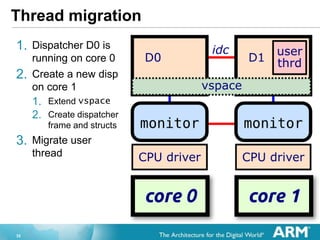
- 35. 35 Thread migration 1. Dispatcher D0 is running on core 0 2. Create a new disp on core 1 1. Extend vspace 2. Create dispatcher frame and structs 3. Migrate user thread
- 36. 36 Timing considerations ? Linux thread migration can take up to ~60 ¦Ěs to 100 ¦Ěs ? There is no apparent difference to migrate a thread for the first time and do it successive times ? Barrelfish thread migration can take ? Creating a new dispatcher: up to 26 milliseconds!! Due to the duplication of the virtual memory map (hundreds of [blocking] RPC calls to the memory server process) ? Migrating the thread to the new dispatcher takes about 68 ¦Ěs, similar to Linux
- 37. 37 Limitations and future work ? Connections endpoints are associated to dispatchers ? So established connections are lost on migration ? It cannot be transparent to user code ? Shutting down cores entirely would be possible ? Has to be implemented as a kernel trap in the destination CPU driver Now that it is working... ? Which is the one making the decision? ? The own process can decide to migrate upon dispatcher activation ? A centralized load balancer which sends a message to migrate ? In any case, core load has to be monitored ? If itˇŻs centralized we can have scalability problems ? Hierarchical balancing can lead to ˇ°load balancingˇ± islands ? Interesting..., ideas can be taken from distributed algorithms in big clusters
Editor's Notes
- #2: This presentation is to show my work during the last 4 months as an intern at ARM
- #5: We had a Barrelfish introduction by Timothy Roscoe on Nov 26th
- #6: Along with data sharing we have problems like: Access locks False sharing Memory contention Hardware cache coherence
- #7: Explain The complex structure of ARM SoC Machines in the future will be different HPC systems tuned for a single machine affordable?
- #8: They can be different architectures They donˇŻt need to share memory
- #17: Say that these problems will be solved in next releases...
- #22: Explain the order on how a dispatcher on core 1 (BOMP) can establish a connection with BOMP on core 0: name server, Explain the difference between LMP and UMP: LMP: via syscall on the local core UMP: via shared memory Everything above the CPU driver is a software thread
- #23: Explain how a large message is being sent Explain how flounder can generate different back ends for: UMP SCC
- #24: Explain cspace and vspace capability objects
- #25: For each IPI the context has to be saved (itˇŻs a costly operation)