Mevd2012 tub esra_acar
2 likes302 views

The document presents a method for detecting violent scenes in movies using affective audio and visual features. Low-level audio and visual features are extracted from movie segments and used to generate mid-level audio representations based on Bag of Audio Words. Audio and visual features are then fused and used to train an SVM classifier to detect violence. Experimental results on 3 movies showed that mid-level representations achieved slightly better performance than low-level features, but affect-related features need improvement, especially for visual representations. Future work will explore using mid-level features like facial features and more sophisticated motion descriptors.











Mevd2012 tub esra_acar
- 1. Detection of Violent Scenes using Affective Features Esra Acar Competence Center Information Retrieval and Machine Learning 4. October 2012
- 2. Outline ▶ Motivation ▶ Background ▶ The Method  Audio Features  Visual Features ▶ Results & Discussion ▶ Conclusions & Future Work 4. October 2012 Detection of Violent Scenes using Affective Features 2
- 3. Motivation ▶ The MediaEval 2012 Affect Task aims at detecting violent segments in movies. ▶ A recent work on horror scene recognition detects horror scenes by affect-related features. ▶ We investigate whether  affect-related features provide good representation of violence, and  making abstractions from low-level features is better than directly using low-level data. 4. October 2012 Detection of Violent Scenes using Affective Features 3
- 4. Background ▶ The affective content of a video corresponds to  the intensity (i.e. arousal), and  the type (i.e. valence) of emotion expected to arise in the user while watching that video. ▶ Recent research efforts propose methods to map low-level features to high-level emotions. ▶ Film-makers intend to elicit some particular emotions (i.e. expected emotions) in the audience. ▶ When we refer to violence as an expected emotion in videos, affect-related features are applicable for violence detection. 4. October 2012 Detection of Violent Scenes using Affective Features 4
- 5. The Method â–¶ The method uses affect-related audio and visual features to represent violence. â–¶ Low-level audio and visual features are extracted. â–¶ Mid-level audio features are generated based on the low- level ones. â–¶ The audio and visual features are then fused at the feature- level and a two-class SVM is trained. 4. October 2012 Detection of Violent Scenes using Affective Features 5
- 6. Audio Features - 1 ▶ Affect-related audio features used in the work are:  Audio energy  related to the arousal aspect.  high/low energy corresponds to high/low emotion intensity.  used for vocal emotion detection.  Mel-Frequency Cepstral Coefficients (MFCC)  related to the arousal aspect.  works well for the detection of excitement/non-excitement.  Pitch  related to the valence aspect.  significant for emotion detection in speech and music. 4. October 2012 Detection of Violent Scenes using Affective Features 6
- 7. Audio Features - 2 ▶ Each video shot has different numbers of audio energy, pitch and MFCC feature vectors (due to varying shot durations). ▶ Audio representations are obtained by computing mean and standard deviation for these audio features. ▶ Abstraction for MFCC:  MFCC-based Bag of Audio Words (BoAW) approach is chosen to generate mid-level audio representations.  Two different audio vocabularies are constructed: violence and non-violence vocabularies (by k-means clustering).  MFCC of violent/non-violent movie segments are used to construct violence/non-violence words.  Violence and non-violence word occurrences within a video shot are represented by a BoAW histogram. 4. October 2012 Detection of Violent Scenes using Affective Features 7
- 8. Visual Features ▶ Average motion  related to the arousal aspect.  Motion vectors are computed using block-based motion estimation.  Average motion is found as the average magnitude of all motion vectors. ▶ We compute average motion around the keyframe of video shots. 4. October 2012 Detection of Violent Scenes using Affective Features 8
- 9. Results & Discussion - 1 ▶ The performance of our method was assessed on 3 Hollywood movies (evaluation criteria: MAP at 100). ▶ We submitted five runs:  r1-low-level: low-level audio and visual features,  Runs based on mid-level audio and low-level visual features  r2-mid-level-100k: 100k samples for dictionary construction,  r3-mid-level-300k: 300k samples for dictionary construction,  r4-mid-level-300k-default: 300k samples for dictionary construction + SVM default parameters, and  r5-mid-level-500k: 500k samples for dictionary construction. 4. October 2012 Detection of Violent Scenes using Affective Features 9
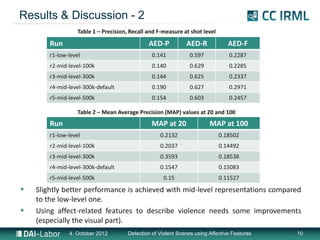
- 10. Results & Discussion - 2 Table 1 – Precision, Recall and F-measure at shot level Run AED-P AED-R AED-F r1-low-level 0.141 0.597 0.2287 r2-mid-level-100k 0.140 0.629 0.2285 r3-mid-level-300k 0.144 0.625 0.2337 r4-mid-level-300k-default 0.190 0.627 0.2971 r5-mid-level-500k 0.154 0.603 0.2457 Table 2 – Mean Average Precision (MAP) values at 20 and 100 Run MAP at 20 MAP at 100 r1-low-level 0.2132 0.18502 r2-mid-level-100k 0.2037 0.14492 r3-mid-level-300k 0.3593 0.18538 r4-mid-level-300k-default 0.1547 0.15083 r5-mid-level-500k 0.15 0.11527 ▶ Slightly better performance is achieved with mid-level representations compared to the low-level one. ▶ Using affect-related features to describe violence needs some improvements (especially the visual part). 4. October 2012 Detection of Violent Scenes using Affective Features 10
- 11. Conclusions & Future Work ▶ The aim of this work was to investigate whether affect- related features are well-suited to describe violence. ▶ Affect-related audio and visual features are merged in a supervised manner using SVM. ▶ Our main finding is that more sophisticated affect-related features are necessary to describe the content of videos (especially the visual part). ▶ Our next step in this work is to use  mid-level features such as human facial features, and  more sophisticated motion descriptors such as Lagrangian measures for video content representation. 4. October 2012 Detection of Violent Scenes using Affective Features 11
- 12. Thank you! Questions? 4. October 2012 Detection of Violent Scenes using Affective Features 12