















Document Summarizer
- 1. Prepared By:- Group No. 27 Ashrith Jalagam(201202126) Shefali Soni(201405619) Aditya Lunawat(201405559) Mentored By : Litton J Kurisinkel
- 2. ïą Document Summarizer is a platform used to generate the summaries using pre-defined summarizers and get the most relevant summary by passing it to a model. ïą The relevancy of a document with respect to Computer Science is determined using WordToVec model and get the most relevant summary out of it. ïą Various pre-built systems such as Apache-tika, WordToVec models have been used for buiding the platform. This platfrom can further be used by other developers.
- 3. ïą Several summarizers makes it difficult to judge which summarizer suits the best for a scenario. ïą Ability of the platform to test different summarizers based on a domain helps the developers to make a choice. ïą This can be achieved by rating the documents based on their relevancy achieved.
- 4. ï― Crawl the data and create a corpus of related to Computer Science domain and create a model using WordToVec tool. ï― Given a URL/file, extract the textual content and create a summary using different summarizers. ï― Pass the summaries one by one to the WordToVec model and get the relevancy of the summaries with respect to computer science.
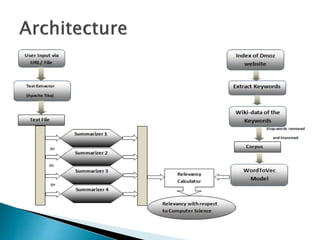
- 7. ïķCorpus Creation ïķText Extraction ïķSummary Generation ïķRelevancy Calculation
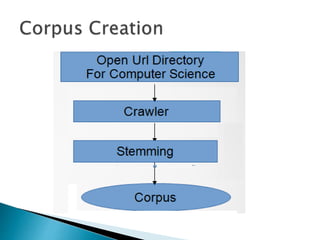
- 9. ï― Define a crawler that will crawl through the Dmoz website and get the desired data. ï― Get the wikipedia pages of all of these keywords and store them in a text file which is the corpus of our system. ï― The wiki pages are being accessed using the Apache- tika tool to get the pages.
- 10. ï Input for the system can be an URL or any type of file such as pdf, excel, odt, odp etc.These type of files must be converted to text file for the summarizers to manipulate. This work is done using Apache-tika tool. Read the input from either the URL or the file, pass it to Apache- tika API and collect the output stream and write it to a file.
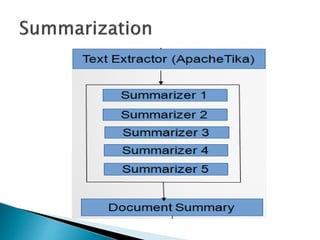
- 11. ïķ Four Different Summarizers were used to generate the summary for each parsed text document/URL. ïķ Summarizer 1 : This Summarizer simply tokenizes the given document and splits it into sentences. Then, it calculates the rank of each sentence according to the TF- IDF Model. ïķ Summarizer 2 : This Summarizer is similar to the previous one but has a âminâ and a âmaxâ threshold. So, only those sentences are considered which lie in that range.
- 12. ïķ Summarizer 3/4 : In these summarizers, there is an inbuilt tokenizer and stemmer, uses help of nltk to rank the final sentences. ïķ Summarizer 5 : This summarizer is the âOpen Text Summarizerâ. This summarizer gives us the best relevant results based on the summary ratio we provide to it as input.
- 14. ïķ There are a available set of summarizers added to the system and more summarizers can be added to the framework. ïķ User chooses among the available summarizers and generate the summary. ïķ These summaries are being forwarded to the model for relevancy calculation
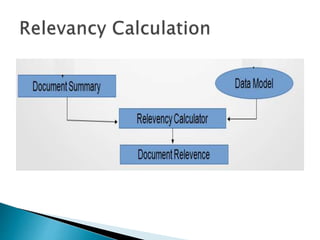
- 16. ïą The input to the model is the textual summary from all the summarizers. Pass the summary one by one to the model. ïą Based on certain parameters the model gives the relevancy factor as the output to all the summaries. ïą Based on this factor the user decides, which summary suits the most to the domain.
- 17. ï― News Feed (Relevancy based on searched category) which means analysing the news and displaying only the summary of the news rather than displaying the whole content. ï― Developed as a platform for the researchers working on summarization as they can add new features to this project.
- 18. ï― The project has been developed as a platform into which new summarizers can easily be added. ï― Ease for developers to decide which summarizer works best for their domain by testing their data on the summaries and calculating the relevance factor. ï― Now the file factor is not the point for the developerâs to think. Input any type of file or URL to the platform.
- 19. ïą Open Url Directory For Computer Science (http://www.dmoz.org/Computers/Computer_Science ïą WORD2VEC model Link: http://radimrehurek.com/gensim/index.html ïą Summarizers ï― http://glowingpython.blogspot.in/2014/09/text- summarization-with-nltk.html ï― https://pypi.python.org/pypi/sumy/0.3.0 ï― http://pythonwise.blogspot.in/2008/01/simple-text- summarizer.html