Data Mining With SQL Server
âĒDownload as PPTX, PDFâĒ
1 likeâĒ974 views

This document provides an overview of data mining using SQL Server. It discusses what data mining is, the data mining process, and key concepts and terminology. The technical platform for data mining in SQL Server is presented, including the server mining architecture with Analysis Services. The main steps for building a data mining model are outlined. Various data mining tasks and approaches for working with data mining in SQL Server are also highlighted, including using DMX queries. Finally, a demo of the data mining process using DMX is proposed.
























Data Mining With SQL Server
- 1. Data Mining With SQL Server Nguyen To Hoan Phuc Pham Huu Khanh
- 2. 2 Objectives âĒ Understand What is Data Mining âĒ Learn the Data Mining Process âĒ How to work with Data Mining
- 3. 3 Agenda âĒ Data vs. Information âĒ What is Data Mining? âĒ Technical Platform âĒ Data Mining Process Overview âĒ Key Concepts and Terminology âĒ DEMO: Data Mining Process in Detail Using DMX
- 5. 5
- 6. 6
- 7. 7
- 8. 8 What is Data Mining?
- 9. 9 Data Mining âĒ Technologies for analysis of data and discovery of (very) hidden patterns âĒ Uses a combination of statistics, probability analysis and database technologies âĒ Fairly young (<20 years old) but clever algorithms developed through database research
- 10. 10 What does Data Mining Do? Explores Your Data Finds Patterns - Trends Performs Predictions
- 11. 11 Data Mining Tasks âĒ Classification âĒ PhÃĒn loaĖĢi, xÊĖp haĖĢng âĒ Regression âĒ HÃīĖi quy âĒ Segmentation âĒ PhÃĒn khuĖc âĒ Association âĒ LiÊn kÊĖt âĒ Sequence Analysis âĒ PhÃĒn tiĖch chuÃīĖi, daĖy
- 13. 13 ïŽ Data acquisition and integration from multiple sources ïŽ Data transformation and synthesis ïŽ Knowledge and pattern detection through Data Mining ïŽ Data enrichment with logic rules and hierarchical views ïŽ Data presentation and distribution ïŽ Data publishing for mass recipients Integrate Analyze Report SQL Server We Need More Than Just Database Engine
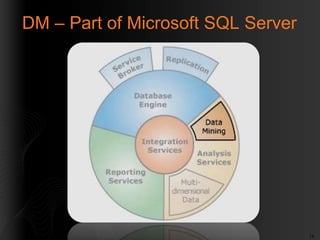
- 14. 14 DM â Part of Microsoft SQL Server
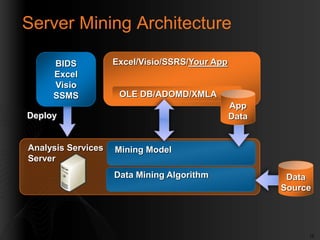
- 15. 15 Server Mining Architecture Analysis Services Server Mining Model Data Mining Algorithm Data Source Excel/Visio/SSRS/Your App OLE DB/ADOMD/XMLA Deploy BIDS Excel Visio SSMS App Data
- 16. 16 Data Mining Process Overview
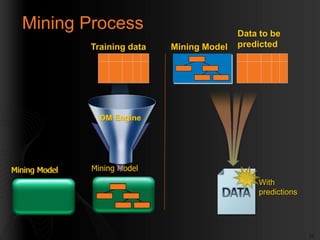
- 17. 17 Mining Model Mining ModelMining Model Mining Process DM EngineDM Engine Training data Data to be predictedMining Model With predictions
- 18. 18 Steps for Building a DM Model 1. Model Creation âĒ Define columns for cases: visually (BIDS), using DMX, or from PMML 2. Model Training âĒ Feed lots of data from a real database, or from a system log Congratulations! We now have a model 3. Model Testing âĒ Test on sample data to check predictions. âĒ Testing data must be different from training âĒ If we get nonsense, adjust the algorithm, its parameters, model design, or even data 4. Model Use (Exploration and Prediction) âĒ Use the model on new data to predict outcomes
- 19. 19 Many Approaches âĒ Work the way you like: âĒ Database experts and SQL veterans: âĒ Write queries in DMX (similar to T-SQL) âĒ Everyone else: âĒ Use Business Intelligence Development Studio (BIDS) â rich GUI included with SSAS âĒ Hosted in Visual Studio (included!) âĒ You donât have to program â click-click instead âĒ Use Excel 2007 with Data Mining Add-Ins âĒ The âData Miningâ tab has everything you need âĒ âTable Analysisâ tab is easier but simplified
- 20. 20 Key Concepts and Terminology
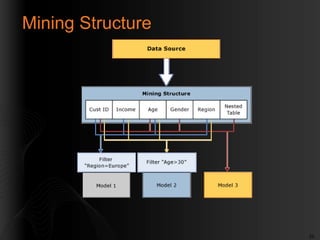
- 21. 21 Mining Structure âĒ Describes data to be mined âĒ Columns from a data source and their: âĒ Data Type âĒ Content Type âĒ Contains Mining Models âĒ Often we build several different models in one structure âĒ Holds training data, known as Cases (if required) âĒ Holds testing data, known as Holdout (in SQL 2008)
- 23. 23 Data Mining Model âĒ Container of patterns discovered by a Data Mining Algorithm amongst the training Cases âĒ A table containing patterns âĒ Expressed by visualisers âĒ Specifies usage of columns already defined in the Mining Structure
- 24. 24 Cases: The Things We Study âĒ Case â set of columns (attributes) you want to analyse âĒ Age, Gender, Region, Annual Spending âĒ Case Key â unique ID of a case
- 25. 25 DEMO Data Mining Process in Detail Using DMX
- 26. 26 Data Mining Extensions DMX âĒ âT-SQLâ for Data Mining âĒ Easy! Like scripting for IT Pros âĒ Two types of statements: âĒ Data Definition âĒ CREATE, ALTER, EXPORT, IMPORT, DROP âĒ Data Manipulation âĒ INSERT INTO, SELECT, DELETE
- 27. 27 DMX â Just Like T-SQL CREATE MINING MODEL CreditRisk (CustID LONG KEY, Gender TEXT DISCRETE, Income LONG CONTINUOUS, Profession TEXT DISCRETE, Risk TEXT DISCRETE PREDICT) USING Microsoft_Decision_Trees INSERT INTO CreditRisk (CustId, Gender, Income, Profession, Risk) Select CustomerID, Gender, Income, Profession,Risk From Customers Select NewCustomers.CustomerID, CreditRisk.Risk, PredictProbability(CreditRisk.Risk) FROM CreditRisk PREDICTION JOIN NewCustomers ON CreditRisk.Gender=NewCustomer.Gender AND CreditRisk.Income=NewCustomer.Income AND CreditRisk.Profession=NewCustomer.Profession
- 28. 28 Demoâs Steps 1 âĒ Create Mining Structure 2 âĒ Create Mining Model 3 âĒ Process Mining Model 4 âĒ Test Model 5 âĒ Execute Prediction
- 29. 29
- 30. 30
Editor's Notes
- #6: VÃĒĖnÄÊĖ lÆ°utrÆ°Ė, kinh phiĖ, quaĖnlyĖ, baĖoquaĖnPhaĖtsinhngaĖycaĖngnhiÊĖuKhoĖ khÄnchoviÊĖĢc âhiÊĖuâ NhucÃĒĖudoanhnghiÊĖĢp: ruĖttriĖchÄÆ°ÆĄĖĢcthÃīng tin tÆ°Ė dÆ°Ė liÊĖĢu, hÃīĖ trÆĄĖĢ raquyÊĖtÄiĖĢnh, tÄngtiĖnhcaĖĢnhtranhtrÊnthiĖĢ trÆ°ÆĄĖng.
- #8: NhucÃĒĖuvÊĖ Information: dÆ°ĖĢ ÄoaĖn, hÃīĖ trÆĄĖĢ raquyÊĖtÄiĖĢnh
- #10: Statistics: thongkeProbability: xacsuatLa mot linhvuc con khatre, duocphattriencach day chua den 20 namnhungcacthuattoanduocphattrienkharo rang
- #12: GiášĢi thuášt phÃĒn loᚥi (Classification Algorithm) â dáŧą ÄoÃĄn ra máŧt hoáš·c nhiáŧu giÃĄ tráŧ biášŋn ráŧi rᚥc, dáŧąa trÊn cÃĄc thuáŧc tÃnh khÃĄc cáŧ§a tášp dáŧŊ liáŧu. Äiáŧn hÃŽnh là giášĢi thuášt CÃĒy Quyášŋt Äáŧnh â Microsoft Decision Trees Algorithm.GiášĢi thuášt Äáŧ qui (Regression Algorithm) â dáŧą ÄoÃĄn máŧt hoáš·c nhiáŧu biášŋn giÃĄ tráŧ liÊn táŧĨc, nhÆ° láŧĢi nhuášn và giÃĄ tráŧ thua láŧ, dáŧąa trÊn cÃĄc thuáŧc tÃnh dáŧŊ liáŧu khÃĄc trong tášp dáŧŊ liáŧu. Äiáŧn hÃŽnh là giášĢi thuášt chuáŧi tháŧi gian â Microsoft Time Series Algorithm.GiášĢi thuášt phÃĒn Äoᚥn (Segmentation Algorithm) â phÃĒn chia dáŧŊ liáŧu thà nh nhiáŧu nhÃģm gáŧm cÃĄc thà nh phᚧn cÃģ thuáŧc tÃnh tÆ°ÆĄng táŧą nhau. GiášĢi thuášt Äiáŧn hÃŽnh là Microsoft Clustering Algorithm.GiášĢi thuášt tÆ°ÆĄng quan (Assocication Algorithm) â tÃŽm sáŧą tÆ°ÆĄng quan giáŧŊa cÃĄc thuáŧc tÃnh trong cáŧ§ng tášp dáŧŊ liáŧu. áŧĻng dáŧĨng pháŧ biášŋn nhášĨt cáŧ§a giášĢi thuášt nà y là xÃĒy dáŧąng cÃĄc luášt tÆ°ÆĄng quan, phÃĒn tÃch giáŧ hà ng. GiášĢi thuášt Äiáŧn hÃŽnh loᚥi giášĢi thuášt nà y là Microsoft Assocciation AlgorithmGiášĢi thuášt phÃĒn tÃch tuyášŋn tÃnh (Sequence Analysis Allgorithm) â táŧng kášŋt cÃĄc chuáŧi hoáš·c mášĢng dáŧŊ liáŧu trong tášp dáŧŊ liáŧu. Äiáŧn hÃŽnh cho loᚥi giášĢi thuášt nà y là Microsoft Sequence Clustering Algorithm
- #16: SSMS: SQL Server Management StudioCÃīng cuĖĢ ÄÊĖ taĖĢoracaĖc Mining Model. CaĖccÃīng cuĖĢ ÄÆ°ÆĄĖĢc Microsoft cungcÃĒĖpgÃīĖm coĖ: Business Inteligence Development Studio, Excel, Visio, SQL Server Management Studio. SaukhitaĖĢoracaĖc Mining Model, cÃĒĖnphaĖitriÊĖnkhailÊnhÊĖĢ thÃīĖng Analysis Services (A.S). Analysis Service laĖ nÆĄivÃĒĖĢnhaĖnh, quaĖnlyĖ caĖc Model.LÆ°u yĖ rÄĖngcaĖc Model saukhiÄÆ°ÆĄĖĢctriÊĖnkhailÊn A.S chiĖ laĖ caĖc Model rÃīĖng. ÄÊĖ coĖ thÊĖ ÄÆ°avaĖosÆ°Ė duĖĢng, cÃĒĖnphaĖi qua mÃīĖĢt quaĖ triĖnhgoĖĢi laĖ Training Model (hoÄĖĢc Process Model). ViĖ thÊĖ cÃĒĖnÄÊĖnthaĖnhphÃĒĖnthÆ°Ė 3 ÄoĖ laĖ Data Source. Data source laĖ nÆĄichÆ°ĖadÆ°Ė liÊĖĢucÃĒĖnthiÊĖtchoviÊĖĢc Training Model vaĖ caĖ quaĖ triĖnh Test Model. ViĖ thÊĖ cÃĒĖnphaĖi chia lÆ°ÆĄĖĢng Data thaĖnh 2 phÃĒĖnriÊngbiÊĖĢtÄÊĖ phuĖĢc vuĖĢ cho 2 taĖc vuĖĢ trÊn.ThaĖnhphÃĒĖnthÆ°Ė 4, ÄoĖ laĖ caĖcÆ°ĖngduĖĢngkhaithaĖccaĖc Mining Model ÄaĖ ÄÆ°ÆĄĖĢcxÃĒydÆ°ĖĢng. CaĖcÆ°ĖngduĖĢng coĖ thÊĖ laĖ caĖcphÃĒĖnmÊĖmÄÆ°ÆĄĖĢc Microsoft cungcÃĒĖpnhÆ° Excel, Visio hoÄĖĢcÆ°ĖngduĖĢng do ngÆ°ÆĄĖiduĖngxÃĒydÆ°ĖĢng. CaĖcÆ°ĖngduĖĢngnaĖygÆĄĖidÆ°Ė liÊĖĢucuĖamiĖnhxuÃīĖng Analysis Service vaĖ nhÃĒĖĢnphaĖnhÃīĖi laĖ kÊĖt quaĖ cuĖa quaĖ triĖnh Data Mining trÆĄĖ laĖĢi.
- #20: Approaches: phÆ°ÆĄngphaĖptiÊĖpcÃĒĖĢn
- #21: Concepts:khaĖiniÊĖĢmTerminology: thuÃĒĖĢtngÆ°Ė
- #22: Mining Structures (Analysis Services - Data Mining)The mining structure defines the data from which mining models are built: it specifies the source data view, the number and type of columns, and an optional partition into training and testing sets. A single mining structure can support multiple mining models that share the same domain. The following diagram illustrates the relationship of the data mining structure to the data source, and to its constituent data mining models.
- #23: The mining structure in the diagram is based on a data source that contains multiple tables, joined on the CustomerID field. One table contains information about customers, such as the geographical region, age, income and gender, while the related nested table contains multiple rows of additional information about each customer, such as products the customer has purchased. The diagram shows that multiple models can be built on one mining structure, and that the models can use different columns from the structure. Model 1Â Â Â Uses CustomerID, Income, Age, Region, and filters the data on Region.Model 2 Â Â Â Uses CustomerID, Income, Age, Region and filters the data on Age.Model 3 Â Â Â Uses CustomerID, Age, Gender, and the nested table, with no filter.Because the models use different columns for input, and because two of the models additionally restrict the data that is used in the model by applying a filter, the models might have very different results even though they are based on the same data. Note that the CustomerID column is required in all models because it is the only available column that can be used as the case key.This section explains the basic architecture of data mining structures. For more information about how to create, manage, modify, or view data mining structures, see Managing Data Mining Structures and Models.
- #24: A data mining model gets data from a mining structure and then analyzes that data by using a data mining algorithm. The mining structure and mining model are separate objects. The mining structure stores information that defines the data source. A mining model stores information derived from statistical processing of the data, such as the patterns found as a result of analysis. A mining model is empty until the data provided by the mining structure has been processed and analyzed. After a mining model has been processed, it contains metadata, results, and bindings back to the mining structure.