![Part 2:
What are data?
[Hands-on exercise]](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-1-320.jpg)


![Research Data
Lays out a nice definition of data and how they vary in different disciplines
The Digital Future is Now: A Call to Action for the Humanities
(please read sections 25-44).
[http://www.digitalhumanities.org/dhq/vol/3/4/000077/000077.html]
Presidential Chair & Professor of
Information Studies,
University of California, Los Angeles
Christine Borgman](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-4-320.jpg)
![Definitions associated with archival information systems offer a
useful starting point:
Definition of data
A reinterpretable representation of
information in a formalized manner suitable
for communication, interpretation, or
processing.
Examples of data include a sequence of bits, a
table of numbers, the characters on a page, the
recording of sounds made by a person speaking,
or a moon rock specimen.
Source: Reference model for an open archival information system 2002, 1-9.
[http://public.ccsds.org/publications/archive/650x0b1s.pdf]
Technical definition](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-5-320.jpg)






![1. Form a group based on subject or discipline.
[Those without subject role can join in any group]
2. Hands-on exercise for Librarians (please work in group)
- use OneSearch/ Databases/ DR-NTU/ Google to get an article published by
any of your faculty or researcher.
- quickly go through the research paper, particularly the methodology section.
3. Librarians among the group to ask and answer the following questions.
[see next slide]
4. Post the findings (title of the research article, question and answer) to PD blog.
Instructions:](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-13-320.jpg)


![1. Who are they? What research community do they belong to? What larger discipline is that
community a part of?
Dianne Cmor and Victoria Marshall. Library science research community. Information Science.
2. What data are they creating (i.e., data types, formats, etc)? How are they creating these data?
1. Diary entries
2. Qualitative data from Ethnograph and SPSS
3. Reftracker report
4. Interview notes
5. Survey feedback
The data are mostly text and numeric social scientific and humanities & arts data.
3. What are the roles of data in their research?
The information collected was converted/ translated into data. The researchers analysed the
data and got the findings out from the data. They examined and evaluated the outcomes/
findings and then built a convincing evidence to answer all the questions they have posed
earlier for their research.
Example: [Before the interview]](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-16-320.jpg)
![Who are they? What research community do they belong to? What larger discipline is that community a part of?
Dianne Cmor is the lead researcher for a research project. Victoria Marshall is another member of the research project. Dianne
and Victoria are both librarian in a university library.
The project is a library related research and the topic of her research is "Librarian class attendance: methods, outcomes and
opportunities". [Library science research community]
The discipline of the research project belongs to Information Science.
What data are they creating (i.e., data types, formats, etc)? How are they creating these data?
The researchers attended a number of seminars called Ī░Journal clubĪ▒ for about 9 weeks. They have jotted down all their
observation in the seminar on a diary. The diary entries were typed out in MS Word and eventually converted to some
qualitative data by using the Ethnograph software and SPSS software.
Reftracker was used each week to document time spent and associated outcomes in relation to meetings with students,
studentsĪ» attendance, and the creation of course support content.
The researchers conducted a few interview with the students and faculty members to collect information. A paper survey
form was also created to collect feedback from the students and some faculty members. The researchers typed out all the
notes collected from the interview and survey in MS Word.
The hard copy of the diaries and survey forms were scanned and saved in PDF format.
The data are mostly text and numeric social scientific and humanities & arts data.
What are the roles of data in their research?
The information collected through the observation at various university lectures and seminars/ tutorials, interviews and
survey conducted for students and faculty members was translated into data. The team analysed the data and got the findings
out from the data. They examined and evaluated the outcomes/ findings and then built a convincing evidence to answer all
the questions they have posed earlier for their research.
Example: [After the interview]
[For reference only]](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-17-320.jpg)
![Data Stage Output
# of Files / Typical
Size Format Other / Notes
Primary Data
Raw Diary, interview notes
and survey forms
25 files/ unknown Handwritten hard copy
Processed Diary and survey forms 2 files/ < 3MB PDF Scanned copy of the diary (1 file)
and survey forms (1 file).
Original data from the
diary, interview notes
and survey forms
3 files/ < 3MB .doc [MS Word] All entries in the diary, notes &
feedback from the interview and
survey were typed out in MS
Word.
Analyzed Qualitative and
quantitative data
2 files/ < 500KB .CHN [Ethnograph]
.csv [MS Excel]
The researchers used
Ethnograph software and SPSS
software to generate qualitative
data.
A report generated from
RefTracker.
Finalized Report [tables and
figures]
<100KB .csv [MS Excel]
Note: The data specifically designated by the scientist to make publicly available are indicated by the
rows shaded in gray (the Ī░AnalyzedĪ▒ row is shaded here as an example). Empty cells represent cases in
which information was not collected or the scientist could not provide a response.
The data table [For reference only. You donĪ»t have to do this]
Example: Data curation profile](https://image.slidesharecdn.com/whataredata-140508202158-phpapp01/85/What-are-Data-18-320.jpg)






























More Related Content
Similar to What are Data? (20)
Recently uploaded (20)


















What are Data?
- 1. Part 2: What are data? [Hands-on exercise]
- 3. Data are one part of scholarly capital, along with human capital and instrumentation. Data have become essential scholarly objects to be captured, mined, used and reused. Research in all academic fields relies on data.
- 4. Research Data Lays out a nice definition of data and how they vary in different disciplines The Digital Future is Now: A Call to Action for the Humanities (please read sections 25-44). [http://www.digitalhumanities.org/dhq/vol/3/4/000077/000077.html] Presidential Chair & Professor of Information Studies, University of California, Los Angeles Christine Borgman
- 5. Definitions associated with archival information systems offer a useful starting point: Definition of data A reinterpretable representation of information in a formalized manner suitable for communication, interpretation, or processing. Examples of data include a sequence of bits, a table of numbers, the characters on a page, the recording of sounds made by a person speaking, or a moon rock specimen. Source: Reference model for an open archival information system 2002, 1-9. [http://public.ccsds.org/publications/archive/650x0b1s.pdf] Technical definition
- 6. Definition of data In BucklandĪ»s terms, data are Ī░alleged evidenceĪ▒ Source: Buckland,M.K. (1991). Ī░Information as thing.Ī▒ Journal of the American Society for Information Science, 42 (5): 351-360. Socio-technical definition
- 7. What are data? Think about data by its origin. In the context of cyberinfrastructure, the four categories of data identified in an influential U.S. policy report Long-lived Data Collections 2005, and incorporated in National Science Foundation strategy Cyberinfrastructure Vision for 21st Century Discovery 2007, are now widely accepted. 1. Observational data- include weather measurements and attitude surveys... 2. Computational data- result from executing a computer model or simulation whether for physics or cultural virtual reality. 3. Experimental data- include results from laboratory studies such as measurements of chemical reactions ĪŁ 4. Records of government, business and public and private life yield useful data for scientific, social scientific, and humanistic research.
- 8. Example 1 Audio analyser Frequency analyser Intelligent Speech Analyser MS Excel spread sheet Audio clips Text reports Certain parts of the content for example 1 have been removed due to sensitive content and copyright issue. Please contact WY for more information. Video recorders Voice recorders Diary Video clips Audio clips Diary entries
- 9. Data Variety To give you a better idea of what can be data, Christine Borgman later expands on her examples and sources of data and how they vary by branch of research.
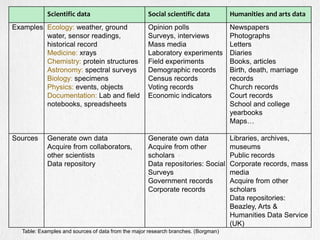
- 10. Scientific data Social scientific data Humanities and arts data Examples Ecology: weather, ground water, sensor readings, historical record Medicine: xrays Chemistry: protein structures Astronomy: spectral surveys Biology: specimens Physics: events, objects Documentation: Lab and field notebooks, spreadsheets Opinion polls Surveys, interviews Mass media Laboratory experiments Field experiments Demographic records Census records Voting records Economic indicators Newspapers Photographs Letters Diaries Books, articles Birth, death, marriage records Church records Court records School and college yearbooks MapsĪŁ Sources Generate own data Acquire from collaborators, other scientists Data repository Generate own data Acquire from other scholars Data repositories: Social Surveys Government records Corporate records Libraries, archives, museums Public records Corporate records, mass media Acquire from other scholars Data repositories: Beazley, Arts & Humanities Data Service (UK) Table: Examples and sources of data from the major research branches. (Borgman)
- 11. Example 2 Example 2 has been removed due to sensitive content. Please contact WY for more information.
- 12. Exercise
- 13. 1. Form a group based on subject or discipline. [Those without subject role can join in any group] 2. Hands-on exercise for Librarians (please work in group) - use OneSearch/ Databases/ DR-NTU/ Google to get an article published by any of your faculty or researcher. - quickly go through the research paper, particularly the methodology section. 3. Librarians among the group to ask and answer the following questions. [see next slide] 4. Post the findings (title of the research article, question and answer) to PD blog. Instructions:
- 14. 1. Who are they? What research community do they belong to? What larger discipline is that community a part of? 2. What data are they creating (i.e., data types, formats, etc)? How are they creating these data? 3. What are the roles of data in their research?
- 15. Title: Librarian Class Attendance: Methods, Outcomes and Opportunities http://docs.lib.purdue.edu/cgi/viewcontent.cgi?article=1757&context=iatul http://www.iatul.org/doclibrary/public/Conf_Proceedings/2006/CmorMarshallpaper.pdf Example sharing
- 16. 1. Who are they? What research community do they belong to? What larger discipline is that community a part of? Dianne Cmor and Victoria Marshall. Library science research community. Information Science. 2. What data are they creating (i.e., data types, formats, etc)? How are they creating these data? 1. Diary entries 2. Qualitative data from Ethnograph and SPSS 3. Reftracker report 4. Interview notes 5. Survey feedback The data are mostly text and numeric social scientific and humanities & arts data. 3. What are the roles of data in their research? The information collected was converted/ translated into data. The researchers analysed the data and got the findings out from the data. They examined and evaluated the outcomes/ findings and then built a convincing evidence to answer all the questions they have posed earlier for their research. Example: [Before the interview]
- 17. Who are they? What research community do they belong to? What larger discipline is that community a part of? Dianne Cmor is the lead researcher for a research project. Victoria Marshall is another member of the research project. Dianne and Victoria are both librarian in a university library. The project is a library related research and the topic of her research is "Librarian class attendance: methods, outcomes and opportunities". [Library science research community] The discipline of the research project belongs to Information Science. What data are they creating (i.e., data types, formats, etc)? How are they creating these data? The researchers attended a number of seminars called Ī░Journal clubĪ▒ for about 9 weeks. They have jotted down all their observation in the seminar on a diary. The diary entries were typed out in MS Word and eventually converted to some qualitative data by using the Ethnograph software and SPSS software. Reftracker was used each week to document time spent and associated outcomes in relation to meetings with students, studentsĪ» attendance, and the creation of course support content. The researchers conducted a few interview with the students and faculty members to collect information. A paper survey form was also created to collect feedback from the students and some faculty members. The researchers typed out all the notes collected from the interview and survey in MS Word. The hard copy of the diaries and survey forms were scanned and saved in PDF format. The data are mostly text and numeric social scientific and humanities & arts data. What are the roles of data in their research? The information collected through the observation at various university lectures and seminars/ tutorials, interviews and survey conducted for students and faculty members was translated into data. The team analysed the data and got the findings out from the data. They examined and evaluated the outcomes/ findings and then built a convincing evidence to answer all the questions they have posed earlier for their research. Example: [After the interview] [For reference only]
- 18. Data Stage Output # of Files / Typical Size Format Other / Notes Primary Data Raw Diary, interview notes and survey forms 25 files/ unknown Handwritten hard copy Processed Diary and survey forms 2 files/ < 3MB PDF Scanned copy of the diary (1 file) and survey forms (1 file). Original data from the diary, interview notes and survey forms 3 files/ < 3MB .doc [MS Word] All entries in the diary, notes & feedback from the interview and survey were typed out in MS Word. Analyzed Qualitative and quantitative data 2 files/ < 500KB .CHN [Ethnograph] .csv [MS Excel] The researchers used Ethnograph software and SPSS software to generate qualitative data. A report generated from RefTracker. Finalized Report [tables and figures] <100KB .csv [MS Excel] Note: The data specifically designated by the scientist to make publicly available are indicated by the rows shaded in gray (the Ī░AnalyzedĪ▒ row is shaded here as an example). Empty cells represent cases in which information was not collected or the scientist could not provide a response. The data table [For reference only. You donĪ»t have to do this] Example: Data curation profile