OneR vs Naive Bayes vs Decision Tree
?
1 like?4,043 views

Perbandingan antara clasifier OneR, Naive Bayes dan Decision Tree. Dilengkapi dengan contoh soal.









OneR vs Naive Bayes vs Decision Tree
- 1. COMPARISSON OF ONE-R, DECISION TREE & NAIVE BAYES putu.sundika@gmail.com
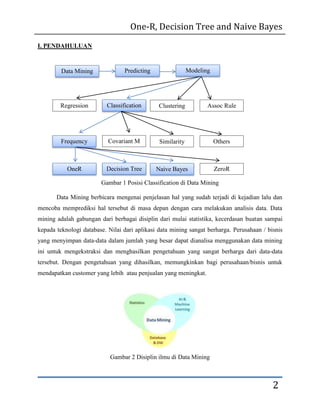
- 2. One-R, Decision Tree and Naive Bayes I. PENDAHULUAN Data Mining Predicting Modeling Regression Classification Clustering Assoc Rule Frequency Covariant M Similarity Others OneR Decision Tree Naive Bayes ZeroR Gambar 1 Posisi Classification di Data Mining Data Mining berbicara mengenai penjelasan hal yang sudah terjadi di kejadian lalu dan mencoba memprediksi hal tersebut di masa depan dengan cara melakukan analisis data. Data mining adalah gabungan dari berbagai disiplin dari mulai statistika, kecerdasan buatan sampai kepada teknologi database. Nilai dari aplikasi data mining sangat berharga. Perusahaan / bisnis yang menyimpan data-data dalam jumlah yang besar dapat dianalisa menggunakan data mining ini untuk mengekstraksi dan menghasilkan pengetahuan yang sangat berharga dari data-data tersebut. Dengan pengetahuan yang dihasilkan, memungkinkan bagi perusahaan/bisnis untuk mendapatkan customer yang lebih atau penjualan yang meningkat. Gambar 2 Disiplin ilmu di Data Mining 2
- 3. One-R, Decision Tree and Naive Bayes Seperti terlihat pada Gambar 1, bahwa untuk dapat melakukan prediksi kejadian di masa depan maka data mining akan membuat sebuah model. Outcame dari model ini jika terkategori maka disebut sebagai classification. Jika outcomenya adalah berupa numeric maka disebut regression. Model yang membagi hasil observasi menjadi beberapa cluster yang sejenis disebut sebagai clustering. Association rules seperti namanya akan mencari hal yang paling terkait. Gambar 3 Contoh hasil model One-R, Decision Tree dan Naive Bayes temasuk di dalam classification berbasis frequency table atau frekuensi kemunculan, seperti yang ditunjukkan pada gambar 1. II.Classifier II.1.One-R Adalah singkatan dari One Rule. Algoritmanya akan membangkitkan sebuah rule untuk setiap atribut kemudia memilih rule dengan error paling kecil dan digunakan sebagai One Rule nya. Untuk membuat rule setiap atribut (predictor) yang ada maka perlu membuat table kemunculan (frequency table) untuk setiap atribut dengan targetnya. Contoh bagaimana algoritma OneR ini bekerja dapat dilihat pada kasus di bawah ini. OUTLOOK TEMPERATURE HUMIDITY WINDY PLAY GOLF sunny hot high false no sunny hot high true no overcast hot high false yes rainy mild high false yes rainy cool normal false yes rainy cool normal true no overcast cool normal true yes 3
- 4. One-R, Decision Tree and Naive Bayes sunny mild high false no sunny cool normal false yes rainy mild normal false yes sunny mild normal true yes overcast mild high true yes overcast hot normal false yes rainy mild high true no Tabel 1 Contoh predictor dan target Play Play Yes No Yes No Sunny 3 2 Hot 2 2 Outlook Overcast 4 0 Temp Mild 4 2 Rainy 2 3 Cool 3 1 e 0.267 e 0.361 Play Play Yes No Yes No High 3 4 FALSE 6 2 Humidity Windy Normal 6 1 TRUE 3 3 e 0.36 e 0.375 Tabel 2 Hasil Table Frequency Dengan melihat table frekuensi di atas maka didapatkan bahwa error terkecil ada pada predictor/atribut Outlook, sehingga Outlook yang akan dijadikan sebagai One Rule nya yaitu : IF Outlook = sunny THEN play=yes IF Outlook = overcast THEN play=yes IF Outlook = rainy THEN play=yes Tabel 3 OneRule yang dihasilkan Rule ini dapat digunakan untuk memprediksi kejadian Play yang akan datang. Selama mengikuti rule ini maka OneR akan memprediksi bahwa akan bermain golf. 4
- 5. One-R, Decision Tree and Naive Bayes II.2 Decision Tree Sesuai dengan namanya model yang dibangun berbentuk struktur tree/pohon. Decision tree akan membagi dataset ke dalam subset kecil dan bersamaan dengan itu melakukan asosiasi keputusan. Hasil akhirnya adalah decision nodes dan leaf nodes. Dengan menggunakan table 1 di atas sebagai contoh kasus yang sama, maka yang disebut sebagai decision node adalah atributnya seperti Outlook. Masing-masing node akan mempunya 2 atau lebih cabang (synny, overcast dan rainy). Leaf node adalah menggambarkan keputusan atau klasifikasinya. Decision node puncak dari tree disebut sebagai root node. Algoritma dasar yang digunakan pada decision tree disebut ID3 (J. R. Quinla) dan menggunakan enthropy serta information gain untuk pembentuk tree nya. Untuk dapat membangun tree, ada 2 tipe entrophy yang perlu dihitung dari frequency table. a. Terhadap target : Play Entropy(Play) Yes No = Entropy (5,9) Entropy (0.36, 9 5 = 0.64) = -(0.36 log2 0.36) - (0.64 log2 0.64) = 0.94 b. Terhadap Atribut Play Yes No Sunny 3 2 5 Outlook Overcast 4 0 4 Rainy 2 3 5 14 E(Play,Outlook) = P(Sunny)*E(3,2) + P(Overcast)*E(3,2) + P(Overcast)*E(4,0) + P(Rainy)*E(2,3) = (5/14)*0.971 + (4/14)*0 + (5/14)*0.971 = 0.693 5
- 6. One-R, Decision Tree and Naive Bayes Informasi Gain Informasi gain didapatkan berdasarkan penurunan entropy setelah dataset di split atribut. Membangun decision tree adalah menemukan atribut yang mempunyai information gain paling tinggi. Rumus yang digunakan adalah : Play Play Yes No Yes No Sunny 3 2 Hot 2 2 Outlook Overcast 4 0 Temp Mild 4 2 Rainy 2 3 Cool 3 1 G 0.247 G 0.029 Play Play Yes No Yes No High 3 4 FALSE 6 2 Humidity Windy Normal 6 1 TRUE 3 3 G 0.152 G 0.048 Tabel 4 Gain Informasi yang didapatkan Atribut dengan Gain tertinggi adalah atribut terpilih (outlook) sebagai decision node. Jika dilihat decision node Outlook akan mempunyai 3 (sunny, overcast, rainy) branch/cabang. Entropy bernilai 0 menandakan leaf node (klasifikasi). Artinya outlook overcast sudah menemukan klasifikasinya yaitu Play=Yes. Proses ini diteruskan dengan mensplit dataset pada outlook sunny dan outlook rainy. Proses penghitungan dilakukan terus sampai akhirnya semua mendapatkan leaf node. Gambar 4 Decision Tree yang sudah terbentuk 6
- 7. One-R, Decision Tree and Naive Bayes Rule yang terbentuk dari tree di atas adalah : IF (Outlook=sunny) AND (Windy=false) THEN Play=Yes IF (Outlook=sunny) AND (Windy=true) THEN Play=No IF (Outlook=overcast) THEN Play=Yes IF (Outlook=rain) AND (Humidity=high) THEN Play=No IF (Outlook=rain) AND (Humidity=normal) THEN Play=Yes II.3 Naive Bayes Naive Bayes Classifier menggunakan teori bayes dengan mengasumsikan tidak ada hubungan antar predictor. Model ini mudah untuk dibangun dan tidak complicated sehingga dianggap tepat untuk database yang besar. Walaupun sederhana, hasil dari Naive Bayes ini dianggap baik karena banyak hasil penggunaan Naive Bayes ini mampu melakukan klasifikasi dengan baik. Algoritma Bayes ini menghitung probabilitas kejadian masa datang dari kejadian sebelumnya dimana masing-masing predictor dianggap tidak saling tergantung atau sering disebut class conditional independence. Rumus menghitung probabilitas masa datangnya : keterangan : ? P(c|x) posterior probability dari class (target) tiap predictor (attribute). ? P(c) prior probability dari class. ? P(x|c) likelihood : probability dari predictor tiap class. ? P(x) prior probability dari predictor. Dengan menggunakan contoh yang sama dari table 1, posterior probability dapat dihitung dengan cara membuat frequency table atribut terhadap target. Tabel ini kemudian dijadika likelihood tables. Kemudian dengan persamaan Naive Bayes dihitung posterior probabilitynya. Class yang memiliki probablitias tertinggi adalah outcome dari prediksinya. 7
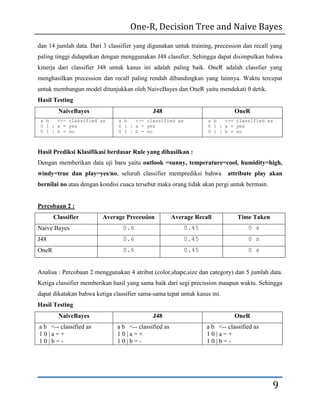
- 8. One-R, Decision Tree and Naive Bayes The zero-frequency problem adalah kejadian dimana tidak ada frekuensi kemunculan sama sekali pada kejadian sebelumnya. Hal ini bisa diatasi dengan penambahan 1 untuk setiap atribut. (Laplace estimator). Contoh ketika Outlook=Overcast tidak muncul pada kelasnya (0). III.PERBANDINGAN PERCOBAAN DATASET DAN DATATEST UNTUK MASING- MASING CLASSFIER Dengan menggunakan tool WEKA untuk membantu perhitungan, dari 3 percobaan didapatkan hasil seperti berikut : Percobaan 1 : Classifier Average Precession Average Recall Time Taken Naive Bayes 0.936 1 0 s J48 1 1 0.2 s OneR 0.714 0.714 0 s Analisa : Percobaan 1 menggunakan 5 atribut (outlook, temperature, humidity, windy dan play) 8
- 9. One-R, Decision Tree and Naive Bayes dan 14 jumlah data. Dari 3 classifier yang digunakan untuk training, precession dan recall yang paling tinggi didapatkan dengan menggunakan J48 classfier. Sehingga dapat disimpulkan bahwa kinerja dari classifier J48 untuk kasus ini adalah paling baik. OneR adalah classfier yang menghasilkan precession dan recall paling rendah dibandingkan yang lainnya. Waktu tercepat untuk membangun model ditunjukkan oleh NaiveBayes dan OneR yaitu mendekati 0 detik. Hasil Testing NaiveBayes J48 OneR a b <-- classified as a b <-- classified as a b <-- classified as 0 1 | a = yes 0 1 | a = yes 0 1 | a = yes 0 1 | b = no 0 1 | b = no 0 1 | b = no Hasil Prediksi Klasifikasi berdasar Rule yang dihasilkan : Dengan memberikan data uji baru yaitu outlook =sunny, temperature=cool, humidity=high, windy=true dan play=yes/no, seluruh classifier memprediksi bahwa attribute play akan bernilai no atau dengan kondisi cuaca tersebut maka orang tidak akan pergi untuk bermain. Percobaan 2 : Classifier Average Precession Average Recall Time Taken Naive Bayes 0.6 0.45 0 s J48 0.6 0.45 0 s OneR 0.6 0.45 0 s Analisa : Percobaan 2 menggunakan 4 atribut (color,shape,size dan category) dan 5 jumlah data. Ketiga classifier memberikan hasil yang sama baik dari segi precission maupun waktu. Sehingga dapat dikatakan bahwa ketiga classifier sama-sama tepat untuk kasus ini. Hasil Testing NaiveBayes J48 OneR a b <-- classified as a b <-- classified as a b <-- classified as 10|a=+ 10|a=+ 10|a=+ 10|b=- 10|b=- 10|b=- 9
- 10. One-R, Decision Tree and Naive Bayes Hasil Prediksi Klasifikasi berdasar Rule yang dihasilkan : Dengan memberikan data uji yaitu color=red, shape=triangle, size=small dan category=+/-, seluruh classifier memprediksi bahwa attribute category akan bernilai + Percobaan 3 : Classifier Average Precession Average Recall Time Taken Naive Bayes 0.893 0.857 0 s J48 0.6 0.45 0 s OneR 0.6 0.45 0 s Analisa : Percobaan 3 menggunakan 5 atribut (cuaca,jarak relatif,pemakaian, pelanggan pasca bayar dan datang ke event) dan 14 jumlah data. Ketiga classifier memberikan hasil yang sama baik dari segi precission maupun waktu. Sehingga dapat dikatakan bahwa ketiga classifier sama- sama tepat untuk kasus ini. Hasil Testing NaiveBayes J48 OneR a b <-- classified as a b <-- classified as a b <-- classified as 0 1 | a = yes 0 1 | a = yes 0 1 | a = yes 0 1 | b = no 0 1 | b = no 0 1 | b = no Hasil Prediksi Klasifikasi berdasar Rule yang dihasilkan : Dengan memberikan data uji yaitu cuaca=cerah, jarak=dekat, pemakaian=tinggi, pelanggan pasca bayar=tidak dan datang_ke_event=yes/no, seluruh classifier memprediksi bahwa attribute datang_ke_event akan bernilai no atau dapat diartikan bahwa dengan kondisi seperti tersebut diprediksi bahwa orang tidak akan menghadiri event. 10
- 11. One-R, Decision Tree and Naive Bayes IV.KESIMPULAN Masing-masing klasifier mempunyai karakteristik masing-masing. Untuk membandingkan mana yang terbaik adalah dengan mencobakan sebuah kasus yang sama terhadap masing-masing classifier. Dengan jumlah data yang tidak banyak seperti pada data percobaan di atas, menggunakan cross validation, hampir seluruh classifier menghasilkan akurasi yang nyaris sama. Hal ini bisa disimpulkan bahwa untuk kasus percobaan-percobaan di atas, mesin klasifikasi manapun yang digunakan akan menghasilkan prediksi yang sama dengan kecepatan yang sama. Ketiga classifier ini bekerja dengan cara menghasilkan model berdasarkan kepada frequency table. Tabel ini dibentuk berdasarkan tingkat kemunculannya terhadap kelas / target. Masing-masing model memiliki algoritmanya sendiri sehingga didapatkan rule masing-masing. One-R adalah teknik yang paling sederhana dalam hal ini walaupun demikian pada percobaan ini tetap outcome prediksinya sama dengan Naive Bayes. One-R bersama Zero-R seringkali tidak diterapkan di dunia nyata tetapi lebih banyak sebagai pembanding classifer lainnya. V.REFERENSI 1. Real Time Data Mining, Saed Sayad 2. Daniel T. Larose. Discovering Knowledge In Data, an Introduction to Data Mining. Wiley Inter-science, New Jersey, 2005. 11