


![? SIOS Technology, Inc. All rights Reserved.
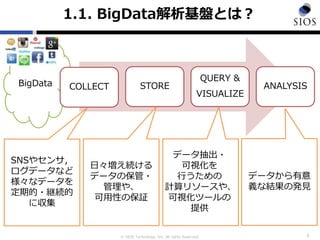
2.2. MapReduce?Pig?Hiveż╬ėø╩÷▒╚▌^
└²Ż║ģgšZż╬╝»ėŗ
Java For
MapReduce
Ż©ź│®`ź╔ż╬1/6│╠Č╚Æi╗鯮
Job job = new Job(conf,
'wordcount');
job.setJarByClass(WordCou
nt.class);
job.setOutputKeyClass(Text
.class);
job.setOutputValueClass(In
tWritable.class);
job.setMapperClass(Map.cla
ss);
job.setCombinerClass(Redu
ce.class);
job.setReducerClass(Reduc
e.class);
HiveQL
select s.word, count(*) from
(select explode(split(text, '[ ?t]+')) word from
hello) s group by s.word;
5
b = foreach a generate flatten(TOKENIZE(text))
as word;
c = group b by word;
d = foreach c generate group as word, COUNT(b)
as count;
store d into Ī«/output';
PigLatin
ź╣ź»źĻźūź╚ę²ė├Ż║http://www.ne.jp/asahi/hishidama/home/tech/index.html](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-5-320.jpg)
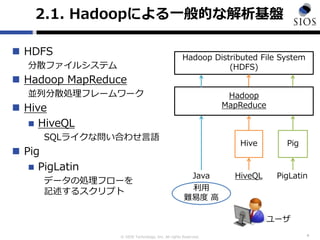
![? SIOS Technology, Inc. All rights Reserved.
2.5. Treasure Dataż╦ż¬ż▒żļźŪ®`ź┐ą╬╩Į
? Č■ż─ż╬ź½źķźÓż╦Ė±╝{Ż©Ī»vĪ»ż╚Ī»timeĪ»Ż®
? Ī«vĪ»ź½źķźÓż╦żŽĪóMAPą╬╩ĮżŪĖ±╝{
? KeyŻ║v[Ī«hostĪ»], v[Ī«userĪ»]
? ValueŻ║Ī»1.1.0.1Ī», Ī«ichiĪ»
? ź½źķźÓż╬▓╬šš
v[Ī«hostĪ»], v[Ī«userĪ»], time
? äe├¹ż“ź½źķźÓ├¹ż╚żĘżŲ└¹ė├
v[Ī«hostĪ»] AS host
8
v time
{'host':'1.1.0.1','user':'ichi'} 1370420001
{'host':'1.1.0.2','user':'jiro'} 1370420010
{'host':'1.1.0.3','user':'sabu'} 1370420100
_c0
1.1.0.1
1.1.0.2
1.1.0.3
host
1.1.0.1
1.1.0.2
1.1.0.3
AS└¹ė├
AS╬┤╩╣ė├](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-8-320.jpg)
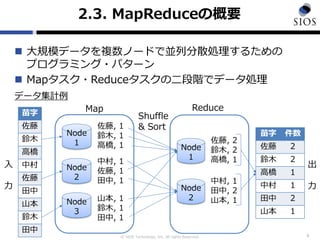
![? SIOS Technology, Inc. All rights Reserved.
2.7. MapReduceż╬╗ž╩²Ž„£pż╦żĶżļä┐┬╩╗»
ųžč}ź½źķźÓż╬│²╚źżŪż╬LEFT SEMI JOIN
SELECT host AS host
FROM
(SELECT v[Ī«hostĪ»] AS host
FROM tbl1) JOIN
(SELECT v[Ī«hostĪ»] AS host
FROM tbl2 GROUP BY host
) ON tbl1.host = tbl2.host
SELECT host AS host
FROM
(SELECT v[Ī«hostĪ»] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[Ī«hostĪ»] AS host
FROM tbl2)
ON tbl1.host = tbl2.host
10
GROUP BYż╬└¹ė├ LEFT SEMI JOINż╬└¹ė├
v
{'host':'1.1.0.3Ī«, Ī«userĪ»:Ī»taroĪ»}
{'host':'1.1.0.1Ī«, Ī«userĪ»:Ī»ichiĪ»}
v time
{'host':'1.1.0.1Ī«} 1370420001
{'host':'1.1.0.1'} 1370420010
tbl1 tbl2
host
1.1.0.1
stage-1 : GROUP BYėŗ╦Ń
stage-2 : JOINėŗ╦Ń
stage-1 : JOINėŗ╦Ń
äI└Ē╩²ż╬Ž„£p
* ėęźŲ®`źųźļż╬źŪ®`ź┐ż¼ū¾źŲ®`źųźļ
ż╦┤µį┌ż╣żļł÷║Žż╬ż▀└¹ė├┐╔─▄](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-10-320.jpg)
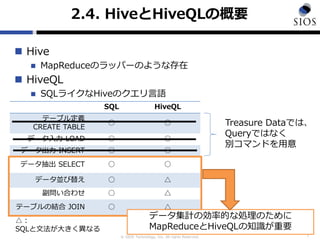
![? SIOS Technology, Inc. All rights Reserved.
2.8.źŲ®`źųźļż“źßźŌźĻżžš╣ķ_ż╣żļ
MAPJOINż╬└¹ė├
11
SELECT /*+MAPJOIN(tbl2)*/
host AS host FROM
(SELECT v[Ī«hostĪ»] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[Ī«hostĪ»] AS host
FROM tbl2) ON tbl1.host = tbl2.host
SELECT host AS host
FROM
(SELECT v[Ī«hostĪ»] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[Ī«hostĪ»] AS host
FROM tbl2) ON tbl1.host =
tbl2.host
MAPJOINż╬ĘŪ└¹ė├ MAPJOINż╬└¹ė├
v
{'host':'1.1.0.3Ī«, Ī«userĪ»:Ī»taroĪ»}
{'host':'1.1.0.1Ī«, Ī«userĪ»:Ī»ichiĪ»}
v time
{'host':'1.1.0.1Ī«} 1370420001
{'host':'1.1.0.1'} 1370420010
tbl1 tbl2
host
1.1.0.1
stage-1 : JOINėŗ╦Ń
ėŗ╦ŃĢrķg ąĪ
Ī·ėęźŲ®`źųźļż“źßźŌźĻ╔Žż╦š╣ķ_
stage-1 : JOINėŗ╦Ń
ėŗ╦ŃĢrķg ┤¾
* ėęźŲ®`źųźļż╬źŪ®`ź┐ż¼źßźŌźĻż╦
ģ¦ż▐żĻżŁżļźĄźżź║żŪżóżļż│ż╚](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-11-320.jpg)
![? SIOS Technology, Inc. All rights Reserved.
2.9. ╚½╠Õ╝»ėŗż╚éĆäe╝»ėŗ
12
V
{Ī«user':Ī«taroĪ«, Ī«cntĪ»:20Ī»}
{Ī«user':Ī«ichiĪ«, Ī«cntĪ»:Ī»5Ī»}
{Ī«user':Ī«ichiĪ«, Ī«cntĪ»:Ī»15Ī»}
tbl
user count
NULL 40
taro 20
ichi 20
SELECT v[Ī«userĪ»] AS user,
SUM(v[Ī«cntĪ»]) AS count
FROM tbl
GROUP BY v[Ī«hostĪ»]
WITH ROLLUP
SELECT u AS user, SUM(z) AS count
FROM tbl LATERAL VIEW
EXPLODE(ARRAY(v[Ī«userĪ»], null)) e
AS u
group by u
ROLLUPż╬└¹ė├Ż©Hive0.10╬┤£║Ż® ROLLUPż╬└¹ė├ (Hive0.10ęį╔Ž)
*¼Fį┌ż╬TDżŪżŽ└¹ė├▓╗┐╔*v[Ī«userĪ»]żŽ NOT NULL](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-12-320.jpg)

![? SIOS Technology, Inc. All rights Reserved.
2.11. żĮż╬╦¹ż╬ź▌źżź¾ź╚Ż©1/2Ż®
? źŲ®`źųźļĮY║Žż╦ż─żżżŲ
? UNION ALLż╬ż▀└¹ė├┐╔─▄
? ųžč}ż“║¼żÓ╚½źņź│®`ź╔ż╬ĮY║Ž
? ĮY║Žż╣żļźŲ®`źųźļ╚½╠Õż“Ė▒å¢żż║Žż’ż╗ż╦ż╣żļż│ż╚
? JOIN ONż╬ONż“ėø╩÷┬®żņżŽĪóCROSS JOINż╦ż╩żļ
? ONŠõżŪżŽęįŽ┬ż╬Č■ż─żŽ└¹ė├▓╗┐╔
? ▓╗Ą╚║┼żŪż╬ĮY║Ž
? ORż╦żĶżļČ■ż─ż╬╠§╝■ż“ė├żżż┐ĮY║Ž
? š²ęÄ▒Ē¼Fż╦ż─żżżŲ
? LIKE = SQLż╬LIKE
? ź’źżźļź╔ź½®`ź╔Ż║*,%,?,_,#,[╬─ūųźĻź╣ź╚],...
? RLIKEż“ė├żżżļż╚ĪóJavaż╬š²ęÄ▒Ē¼Fż“└¹ė├┐╔─▄
? ź’źżźļź╔ź½®`ź╔Ż║LIKE + ”┴
14](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-14-320.jpg)


For blog hive_ql_on_treasuredata
- 1. ? SIOS Technology, Inc. All rights Reserved. 1. BigDataĮŌ╬÷╗∙▒Pż╚żĘżŲż╬ Treasure Data 2. HiveQLż╬ų▄▐x╝╝ągż╚Tips źĄźżź¬ź╣źŲź»ź╬źĒźĖ®`ųĻ╩Į╗ß╔ń ź»źķź”ź╔źĮźĻźÕ®`źĘźńź¾▓┐ 2013─Ļ6į┬11╚š ¾{ś“ ▀_ źĄźżź¬ź╣źŲź»ź╬źĒźĖ®`ųĻ╩Į╗ß╔ń
- 2. ? SIOS Technology, Inc. All rights Reserved. ─┐Ą─ż╚─┐┤╬ ─┐ ┤╬ 1. BigDataĮŌ╬÷╗∙▒Pż╚żĘżŲż╬Treasure Data 1. BigDataĮŌ╬÷╗∙▒Pż╚żŽŻ┐ 2. HiveQLż╬ų▄▐x╝╝ągż╚Tips 1.~4. HiveQLż╬ų▄▐x╝╝ąg 5.~11. HiveQLż╬Tips 3. ░k▒Ēż╬ż▐ż╚żß 2 Treasure Dataż╚HiveQLż╦ķvż╣żļų¬ūR╣▓ėąż╦żĶżĻŻ¼ źņź▌®`źŲźŻź¾ź░ū„śIż╬ä┐┬╩źóź├źū ─┐ Ą─
- 3. ? SIOS Technology, Inc. All rights Reserved. 1.1. BigDataĮŌ╬÷╗∙▒Pż╚żŽŻ┐ 3 BigData COLLECT STORE QUERY & VISUALIZE ANALYSIS SNSżõź╗ź¾źĄŻ¼ źĒź░źŪ®`ź┐ż╩ż╔ śöĪ®ż╩źŪ®`ź┐ż“ Č©Ų┌Ą─?Š@ŠAĄ─ ż╦ģ¦╝» ╚šĪ®ēłż©ŠAż▒żļ źŪ®`ź┐ż╬▒Ż╣▄? ╣▄└ĒżõĪó ┐╔ė├ąįż╬▒Żį^ źŪ®`ź┐│ķ│÷? ┐╔ęĢ╗»ż“ ąąż”ż┐żßż╬ ėŗ╦ŃźĻźĮ®`ź╣żõĪó ┐╔ęĢ╗»ź─®`źļż╬ ╠ß╣® źŪ®`ź┐ż½żķėąęŌ ┴xż╩ĮY╣¹ż╬░kęŖ
- 4. ? SIOS Technology, Inc. All rights Reserved. 2.1. Hadoopż╦żĶżļę╗░ŃĄ─ż╩ĮŌ╬÷╗∙▒P ? HDFS Ęų╔óźšźĪźżźļźĘź╣źŲźÓ ? Hadoop MapReduce üK┴ąĘų╔óäI└Ēźšźņ®`źÓź’®`ź» ? Hive ? HiveQL SQLźķźżź»ż╩å¢żż║Žż’ż╗čįšZ ? Pig ? PigLatin źŪ®`ź┐ż╬äI└ĒźšźĒ®`ż“ ėø╩÷ż╣żļź╣ź»źĻźūź╚ 4 Hadoop Distributed File System (HDFS) Hadoop MapReduce Hive Pig HiveQL PigLatinJava └¹ė├ ļyęūČ╚ Ė▀ źµ®`źČ
- 5. ? SIOS Technology, Inc. All rights Reserved. 2.2. MapReduce?Pig?Hiveż╬ėø╩÷▒╚▌^ └²Ż║ģgšZż╬╝»ėŗ Java For MapReduce Ż©ź│®`ź╔ż╬1/6│╠Č╚Æi╗鯮 Job job = new Job(conf, 'wordcount'); job.setJarByClass(WordCou nt.class); job.setOutputKeyClass(Text .class); job.setOutputValueClass(In tWritable.class); job.setMapperClass(Map.cla ss); job.setCombinerClass(Redu ce.class); job.setReducerClass(Reduc e.class); HiveQL select s.word, count(*) from (select explode(split(text, '[ ?t]+')) word from hello) s group by s.word; 5 b = foreach a generate flatten(TOKENIZE(text)) as word; c = group b by word; d = foreach c generate group as word, COUNT(b) as count; store d into Ī«/output'; PigLatin ź╣ź»źĻźūź╚ę²ė├Ż║http://www.ne.jp/asahi/hishidama/home/tech/index.html
- 6. ? SIOS Technology, Inc. All rights Reserved. 2.3. MapReduceż╬Ė┼ę¬ ? ┤¾ęÄ─ŻźŪ®`ź┐ż“č}╩²ź╬®`ź╔żŪüK┴ąĘų╔óäI└Ēż╣żļż┐żßż╬ źūźĒź░źķź▀ź¾ź░?źčź┐®`ź¾ ? Mapź┐ź╣ź»?Reduceź┐ź╣ź»ż╬Č■Č╬ļAżŪźŪ®`ź┐äI└Ē 6 Map Reduce Node 1 Node 2 Node 3 ū¶╠┘, 1 ŌÅ─Š, 1 Ė▀ś“, 1 ųą┤Õ, 1 ū¶╠┘, 1 ╠’ųą, 1 ╔Į▒Š, 1 ŌÅ─Š, 1 ╠’ųą, 1 Node 1 Node 2 ū¶╠┘, 2 ŌÅ─Š, 2 Ė▀ś“, 1 ųą┤Õ, 1 ╠’ųą, 2 ╔Į▒Š, 1 Shuffle & Sort źŪ®`ź┐╝»ėŗ└² ╚ļ ┴” │÷ ┴” ├ńūų ū¶╠┘ ŌÅ─Š Ė▀ś“ ųą┤Õ ū¶╠┘ ╠’ųą ╔Į▒Š ŌÅ─Š ╠’ųą ├ńūų ╝■╩² ū¶╠┘ 2 ŌÅ─Š 2 Ė▀ś“ 1 ųą┤Õ 1 ╠’ųą 2 ╔Į▒Š 1
- 7. ? SIOS Technology, Inc. All rights Reserved. 2.4. Hiveż╚HiveQLż╬Ė┼ę¬ ? Hive ? MapReduceż╬źķź├źč®`ż╬żĶż”ż╩┤µį┌ ? HiveQL ? SQLźķźżź»ż╩Hiveż╬ź»ź©źĻčįšZ 7 SQL HiveQL źŲ®`źųźļČ©┴x CREATE TABLE Ī Ī źŪ®`ź┐╚ļ┴” LOAD Ī Ī źŪ®`ź┐│÷┴” INSERT Ī Ī źŪ®`ź┐│ķ│÷ SELECT Ī Ī źŪ®`ź┐üKżė╠µż© Ī Ī„ Ė▒å¢żż║Žż’ż╗ Ī Ī„ źŲ®`źųźļż╬ĮY║Ž JOIN Ī Ī„ Ī„Ż║ SQLż╚╬─Ę©ż¼┤¾żŁż»«Éż╩żļ Treasure DatażŪżŽĪó QueryżŪżŽż╩ż» äeź│ź▐ź¾ź╔ż“ė├ęŌ źŪ®`ź┐╝»ėŗż╬ä┐┬╩Ą─ż╩äI└Ēż╬ż┐żßż╦ MapReduceż╚HiveQLż╬ų¬ūRż¼ųžę¬
- 8. ? SIOS Technology, Inc. All rights Reserved. 2.5. Treasure Dataż╦ż¬ż▒żļźŪ®`ź┐ą╬╩Į ? Č■ż─ż╬ź½źķźÓż╦Ė±╝{Ż©Ī»vĪ»ż╚Ī»timeĪ»Ż® ? Ī«vĪ»ź½źķźÓż╦żŽĪóMAPą╬╩ĮżŪĖ±╝{ ? KeyŻ║v[Ī«hostĪ»], v[Ī«userĪ»] ? ValueŻ║Ī»1.1.0.1Ī», Ī«ichiĪ» ? ź½źķźÓż╬▓╬šš v[Ī«hostĪ»], v[Ī«userĪ»], time ? äe├¹ż“ź½źķźÓ├¹ż╚żĘżŲ└¹ė├ v[Ī«hostĪ»] AS host 8 v time {'host':'1.1.0.1','user':'ichi'} 1370420001 {'host':'1.1.0.2','user':'jiro'} 1370420010 {'host':'1.1.0.3','user':'sabu'} 1370420100 _c0 1.1.0.1 1.1.0.2 1.1.0.3 host 1.1.0.1 1.1.0.2 1.1.0.3 AS└¹ė├ AS╬┤╩╣ė├
- 9. ? SIOS Technology, Inc. All rights Reserved. 2.6. SELECT * ż╚ SELECT ĒŚ─┐ųĖČ© SELECT * FROM tbl ? MapReduceäI└Ēż“ īgąążĘż╩żżżŪĮY╣¹│÷┴” ? Hiveż¼ź╣źŁ®`ź▐ż“╗∙ż╦ ĮY╣¹ż“│÷┴” SELECT ź½źķźÓųĖČ© FROM tbl ? MapReduceäI└Ēż“ īgąążĘżŲĮY╣¹│÷┴” 9 Æżäėż╦▓Ņ«É ? ź½źķźÓųĖČ©żĶżĻäI└Ēż¼╦┘żż ? MapReduceż╬ŲäėĄ╚ż╦ ĢrķgŽ¹┘M ? źŪ®`ź┐ż╬┤_šJė├ż╦└¹ė├ Ż╝ż¬ż▐ż▒ŻŠ LIMITżŪĮY╣¹ż╬╚ĪĄ├╝■╩²ż“ųŲŽ▐ ┐╔─▄ SELECT * FROM tbl LIMIT 1 ĮY╣¹Ż® tblż½żķ1╝■ż╬ż▀╚ĪĄ├
- 10. ? SIOS Technology, Inc. All rights Reserved. 2.7. MapReduceż╬╗ž╩²Ž„£pż╦żĶżļä┐┬╩╗» ųžč}ź½źķźÓż╬│²╚źżŪż╬LEFT SEMI JOIN SELECT host AS host FROM (SELECT v[Ī«hostĪ»] AS host FROM tbl1) JOIN (SELECT v[Ī«hostĪ»] AS host FROM tbl2 GROUP BY host ) ON tbl1.host = tbl2.host SELECT host AS host FROM (SELECT v[Ī«hostĪ»] AS host FROM tbl1) LEFT SEMI JOIN (SELECT v[Ī«hostĪ»] AS host FROM tbl2) ON tbl1.host = tbl2.host 10 GROUP BYż╬└¹ė├ LEFT SEMI JOINż╬└¹ė├ v {'host':'1.1.0.3Ī«, Ī«userĪ»:Ī»taroĪ»} {'host':'1.1.0.1Ī«, Ī«userĪ»:Ī»ichiĪ»} v time {'host':'1.1.0.1Ī«} 1370420001 {'host':'1.1.0.1'} 1370420010 tbl1 tbl2 host 1.1.0.1 stage-1 : GROUP BYėŗ╦Ń stage-2 : JOINėŗ╦Ń stage-1 : JOINėŗ╦Ń äI└Ē╩²ż╬Ž„£p * ėęźŲ®`źųźļż╬źŪ®`ź┐ż¼ū¾źŲ®`źųźļ ż╦┤µį┌ż╣żļł÷║Žż╬ż▀└¹ė├┐╔─▄
- 11. ? SIOS Technology, Inc. All rights Reserved. 2.8.źŲ®`źųźļż“źßźŌźĻżžš╣ķ_ż╣żļ MAPJOINż╬└¹ė├ 11 SELECT /*+MAPJOIN(tbl2)*/ host AS host FROM (SELECT v[Ī«hostĪ»] AS host FROM tbl1) LEFT SEMI JOIN (SELECT v[Ī«hostĪ»] AS host FROM tbl2) ON tbl1.host = tbl2.host SELECT host AS host FROM (SELECT v[Ī«hostĪ»] AS host FROM tbl1) LEFT SEMI JOIN (SELECT v[Ī«hostĪ»] AS host FROM tbl2) ON tbl1.host = tbl2.host MAPJOINż╬ĘŪ└¹ė├ MAPJOINż╬└¹ė├ v {'host':'1.1.0.3Ī«, Ī«userĪ»:Ī»taroĪ»} {'host':'1.1.0.1Ī«, Ī«userĪ»:Ī»ichiĪ»} v time {'host':'1.1.0.1Ī«} 1370420001 {'host':'1.1.0.1'} 1370420010 tbl1 tbl2 host 1.1.0.1 stage-1 : JOINėŗ╦Ń ėŗ╦ŃĢrķg ąĪ Ī·ėęźŲ®`źųźļż“źßźŌźĻ╔Žż╦š╣ķ_ stage-1 : JOINėŗ╦Ń ėŗ╦ŃĢrķg ┤¾ * ėęźŲ®`źųźļż╬źŪ®`ź┐ż¼źßźŌźĻż╦ ģ¦ż▐żĻżŁżļźĄźżź║żŪżóżļż│ż╚
- 12. ? SIOS Technology, Inc. All rights Reserved. 2.9. ╚½╠Õ╝»ėŗż╚éĆäe╝»ėŗ 12 V {Ī«user':Ī«taroĪ«, Ī«cntĪ»:20Ī»} {Ī«user':Ī«ichiĪ«, Ī«cntĪ»:Ī»5Ī»} {Ī«user':Ī«ichiĪ«, Ī«cntĪ»:Ī»15Ī»} tbl user count NULL 40 taro 20 ichi 20 SELECT v[Ī«userĪ»] AS user, SUM(v[Ī«cntĪ»]) AS count FROM tbl GROUP BY v[Ī«hostĪ»] WITH ROLLUP SELECT u AS user, SUM(z) AS count FROM tbl LATERAL VIEW EXPLODE(ARRAY(v[Ī«userĪ»], null)) e AS u group by u ROLLUPż╬└¹ė├Ż©Hive0.10╬┤£║Ż® ROLLUPż╬└¹ė├ (Hive0.10ęį╔Ž) *¼Fį┌ż╬TDżŪżŽ└¹ė├▓╗┐╔*v[Ī«userĪ»]żŽ NOT NULL
- 13. ? SIOS Technology, Inc. All rights Reserved. 2.10. Treasure Dataż¼╠ß╣®ż╣żļUDF (User Defined Functoins) ? TD_X_RANK(keys) ? źµ®`źČÜ░ż╦Ę¼║┼ĖČ ? ĢrŽĄ┴ąż╦üKżė╠µż©żļż│ż╚żŪźčź╣ż╬ū„│╔ż¼┐╔─▄ ? TD_TIME_RANGE(time, start_time, end_time) ? WHEREŠõżŪż╬Ģrķgż╦żĶżļ╣ĀćņųĖČ© ? TD_TIME_ADD(time, Ī«Ų┌ķgĪ») ? Ģrķgż╬śöĪ®ż╩ųĖČ©ż¼┐╔─▄ ? N╚šß߯║Ī»1dĪ», Ī«2dĪ», Ī«3dĪ»,... 13 V {Ī«user':Ī«taroĪ«, Ī«refĪ»:Ī»1.1.1.1Ī»} {Ī«user':Ī«ichiĪ«, Ī«refĪ»:Ī»1.1.1.2Ī»} {Ī«user':Ī«ichiĪ«, Ī«refĪ»:Ī»1.1.1.3Ī»} Rank User Ref 1 Taro 1.1.1.1 1 Ichi 1.1.1.2 2 Ichi 1.1.1.3 SELECT ... WHERE TD_TIME_RANGE( Time, Ī«2013-04-01Ī», TD_TIME_ADD(Ī«2013-04-01Ī», Ī«1dĪ»)
- 14. ? SIOS Technology, Inc. All rights Reserved. 2.11. żĮż╬╦¹ż╬ź▌źżź¾ź╚Ż©1/2Ż® ? źŲ®`źųźļĮY║Žż╦ż─żżżŲ ? UNION ALLż╬ż▀└¹ė├┐╔─▄ ? ųžč}ż“║¼żÓ╚½źņź│®`ź╔ż╬ĮY║Ž ? ĮY║Žż╣żļźŲ®`źųźļ╚½╠Õż“Ė▒å¢żż║Žż’ż╗ż╦ż╣żļż│ż╚ ? JOIN ONż╬ONż“ėø╩÷┬®żņżŽĪóCROSS JOINż╦ż╩żļ ? ONŠõżŪżŽęįŽ┬ż╬Č■ż─żŽ└¹ė├▓╗┐╔ ? ▓╗Ą╚║┼żŪż╬ĮY║Ž ? ORż╦żĶżļČ■ż─ż╬╠§╝■ż“ė├żżż┐ĮY║Ž ? š²ęÄ▒Ē¼Fż╦ż─żżżŲ ? LIKE = SQLż╬LIKE ? ź’źżźļź╔ź½®`ź╔Ż║*,%,?,_,#,[╬─ūųźĻź╣ź╚],... ? RLIKEż“ė├żżżļż╚ĪóJavaż╬š²ęÄ▒Ē¼Fż“└¹ė├┐╔─▄ ? ź’źżźļź╔ź½®`ź╔Ż║LIKE + ”┴ 14
- 15. ? SIOS Technology, Inc. All rights Reserved. 2.11. żĮż╬╦¹ż╬ź▌źżź¾ź╚Ż©2/2Ż® ? ķv╩²Ūķł¾ ? SHOW FUNCTIONS ?ķv╩²ż╬ę╗ėEż“▒Ē╩ŠŻ©UDFżŌ║¼żÓŻ® ? DESC FUNCTION ķv╩²├¹ DESC FUNCTION EXTENDED ķv╩²├¹ ?ķv╩²ż╬Ūķł¾ż“▒Ē╩ŠĪóEXTENDEDżŪ╩╣ė├└²żŌ▒Ē╩Š 15
- 16. ? SIOS Technology, Inc. All rights Reserved. 3. ░k▒Ēż╬ż▐ż╚żß ? źėź├ź░źŪ®`ź┐ĮŌ╬÷╗∙▒Pż╦Ū¾żßżķżņżļÖC─▄Ż║ ? Ė„čuŲĘż╦ż¬ż▒żļĖ„ÖC─▄ż╬įö╝Üż╩▒╚▌^ż¼▒žę¬ ? HiveQLż╬Tips ? SQLż╚▀`żżżŽżóż▐żĻż╩żż ? MapReduceż“ęŌūRż╣żļż│ż╚żŪź»ź©źĻż╬ä┐┬╩╗» ? LEFT SEMI JOINż╬└¹ė├ ? /*+ MAPJOIN(tbl) */ż╬└¹ė├ ? ╚½╠Õ╝»ėŗż╚éĆäe╝»ėŗ ? UDFż╦ż─żżżŲ 16 COLLECT STORE QUERY & VISUALIZE ANALYSIS