08 mapreduce
Download as odp, pdf1 like831 views

Il documento descrive il modello di programmazione MapReduce, utilizzato per l'elaborazione parallela di grandi volumi di dati, particolarmente in contesti distribuiti come i cluster di computer. Sono illustrate le primitive funzionali 'map' e 'reduce', con esempi di implementazione in Python, e vengono discussi i processi di suddivisione dei dati, assegnazione dei task e aggregazione dei risultati. Viene inoltre accennato a diverse implementazioni del modello, come Hadoop.







![Esempio di map in Python >>> def f(x): ... return 2*x ... >>> i=[1,2,3,4] >>> o=map(f,i) >>> o [2, 4, 6, 8] >>>](https://image.slidesharecdn.com/08-mapreduce-110307074304-phpapp01/85/08-mapreduce-8-320.jpg)
![Esempio reduce in Python >>> def f(x,y): ... return x+y ... >>> f(3,4) 7 >>> i=[1,2,3,4] >>> o=reduce(f,i) >>> o 10 >>>](https://image.slidesharecdn.com/08-mapreduce-110307074304-phpapp01/85/08-mapreduce-9-320.jpg)
![Esempio reduce e lambda in Python >>> reduce (lambda x,y:x+y,[1,2,3,4]) 10 in questa espressione si usano espressioni literal al posto di f, i ed o: notare che il literal di una funzione si costruisce tramite l'operatore lambda (funzioni anonime)](https://image.slidesharecdn.com/08-mapreduce-110307074304-phpapp01/85/08-mapreduce-10-320.jpg)








08 mapreduce
- 1. MapReduce Davide Carboni Corso di Computazione su Rete Laurea specialistica in Tecnologie Informatiche Facoltà Scienze MM.FF.NN Università di Cagliari AA 2007/2008
- 2. MapReduce MapReduce ÃĻ un nuovo approccio alla programmazione parallela sviluppato ed utilizzato da Google E' basato sulle primitive funzionali map e reduce che vengono dal mondo dei linguaggi funzionali Ci sono varie implementazioni del concetto, ad esempio Hadoop (in Java e usata da Yahoo!)
- 3. Motivazione E' utilizzato in elaborazioni di grandi quantità di dati grandi volumi di input grandi volumi di output gran numero di processori (es. cluster) utilizzati parallelamente
- 4. Fornisce MapReduce fornisce parallelizzazione distribuzione tolleranza ai guasti scheduling I/O monitoraggio del calcolo e delle prestazioni
- 5. Cluster Un cluster ÃĻ un insieme di computer collegati attraverso una rete e coordinati in modo da distribuire e parallelizzare un calcolo complesso Occorre dunque: Hardware di rete ad alte prestazioni Un sistema operativo adattato al clustering Un algoritmo parallelizzabile
- 6. Primitive funzionali Nei linguaggi funzionali la primitiva map serve a mappare una sequenza di dati in ingresso i su una sequenza di dati in uscita o con una funzione f in modo che o = map (f, i) es. se i = {1,2,3,4,5,6,7,8} e f(x) := 2*x allora o = {2,4,6,8,10,12,14,16}
- 7. Primitive funzionali La reduce, data una sequenza di input i ed una funzione a due parametri (operatore binario) f produce un unico dato (atomo) o a partire dalla sequenza i Per esempio: o = reduce (f,i) con f(x,y) := x + y i := {1,2,3,4} produce o = ((1+2)+3)+4
- 8. Esempio di map in Python >>> def f(x): ... return 2*x ... >>> i=[1,2,3,4] >>> o=map(f,i) >>> o [2, 4, 6, 8] >>>
- 9. Esempio reduce in Python >>> def f(x,y): ... return x+y ... >>> f(3,4) 7 >>> i=[1,2,3,4] >>> o=reduce(f,i) >>> o 10 >>>
- 10. Esempio reduce e lambda in Python >>> reduce (lambda x,y:x+y,[1,2,3,4]) 10 in questa espressione si usano espressioni literal al posto di f, i ed o: notare che il literal di una funzione si costruisce tramite l'operatore lambda (funzioni anonime)
- 11. MapReduce Le primitive map, reduce che abbiamo visto sono parte dei linguaggi funzionali. E' possibile riprendere questi concetti in un ambiente distribuito (e implementarle con qualsiasi linguaggio anche non funzionale) Il comportamento ÃĻ mediato da una libreria (middleware)
- 12. Modello di programmazione map ( in_key, in_value ) -> list(out_key,intermediate_value) elabora una coppia chiave/valore produce una lista di coppie chiave/valore (diverse)
- 13. Modello di programmazione reduce ( out_key , list ( intermediate_value )) -> list(out_value) combina tutte le coppie chiave/valore per una certa chiave produce un set di valori (o un solo valore)
- 14. Ėý
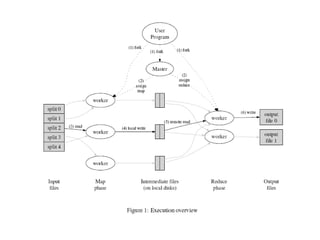
- 15. Esecuzione L'input viene diviso in blocchi (es. di 16MB) Vengono attivate varie istanze del programma su un cluster di macchine Una delle istanze detta master assegna i task alle altre dette worker Un worker che svolge un task map legge il blocco di input, estrae le coppie key,value e le passa alla funzione map ( user-defined)
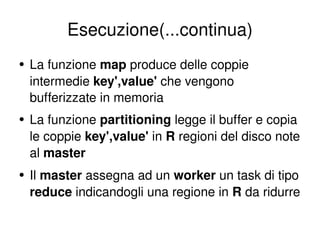
- 16. Esecuzione(...continua) La funzione map produce delle coppie intermedie key',value' che vengono bufferizzate in memoria La funzione partitioning legge il buffer e copia le coppie key',value' in R regioni del disco note al master Il master assegna ad un worker un task di tipo reduce indicandogli una regione in R da ridurre
- 17. Esecuzione(...continua) Il reduce task consiste nel prendere tutte le coppie key',value' e raggrupparle in modo che le chiavi siano uniche (k' 1 ,v' 1 ,v' 2 ,...,v' n ) (k' 2 ,w' 1 ,w' 2 ,...,w' m ) Dove le k' i sono chiavi intermedie e v' j e w' k sono valori intermedi emessi da map () Ogni gruppo (k' i ,v' 1 ,v' 2 ,...,v' n ) viene passato alla funzione reduce () definita dall'utente e i risultati scritti in R file di uscita
- 18. Esempio (conta le parole) map (input_key, input_value): // input_key: document name // input_value: document contents for each word w in input_value: EmitIntermediate(w, 1) reduce (output_key, list_of_intermediate_values): // output_key: a word // list_of_intermediate_values: all '1's emitted for a given word result = 0 for each v in list_of_intermediate_values: result += v Emit(result)
- 19. Esempio (distributed grep) map (input_key, input_value): pattern = input_key text = input_value for each line l in text: if match(l,pattern): EmitIntermediate(pattern, l); reduce (output_key, list_of_intermediate_values): lines = list_of_intermediate_values Emit(lines)
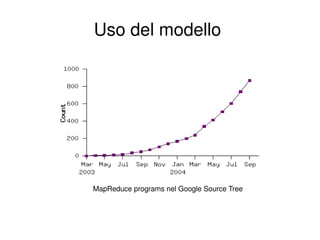
- 20. Uso del modello MapReduce programs nel Google Source Tree
- 21. Referenze "MapReduce: Simplified Data Processing on Large Clusters" paper by Jeffrey Dean and Sanjay Ghemawat; from Google Labs Free Java Framework for MapReduce http://hadoop.apache.org/