

![導入 II
Vapnik の思想 [Vapnik, 98]
Nothing is more practical than a good theory.
理論に基づいたアルゴリズム
? カーネル法 (サポートベクターマシン)
? ブースティング (アダブースト)...
このセミナーでは [4] を読んで機械学習の理論的側面に親しみ
たい.
本スライドは [4] の第 1 章のまとめである.
2](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-3-320.jpg)


![問題設定 II 判別問題 (§1.1.1)
? |Y| < ∞ のとき, input data から label を予測する.
? |Y| = 2 : 2 値判別 (e.g. 迷惑メール分類
Y = {“spam”, “nonspam”})
? |Y| ≥ 3 : 多値判別
? 判別問題における loss function (0-1 loss)
?(?y, y) = 1[?y ?= y] =
?
?
?
1 if y ?= ?y
0 otherwise
?
?=
?
?
?
?y if y ?= ?y
0 otherwise
?
?
損失が真ラベルに依存する場合
7](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-8-320.jpg)



![予測損失と経験損失 I
Definition 1 (予測 (期待) 損失)
test data (X, Y) の従う分布 D の下での仮説 h の予測損失を以
下で定義
R(h) := E(X,Y)~D[?(h(X), Y)]
Example 1 (0-1 loss)
0-1 loss の予測損失 (期待判別誤差) は
Rerr(h) = Pr[h(X) ?= Y] = E[1[h(X) ?= Y]]
学習の目標
data の真の分布が未知なため直接計算不可能な期待損失を観
測 data のみを用いて小さくする 11](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-12-320.jpg)
![予測損失と経験損失 II
Definition 2 (経験損失)
{(Xi, Yi)}n
i=1 : observed data
仮説 h の経験損失を以下で定義
?R(h) :=
1
n
n∑
i=1
?(h(Xi), Yi)
経験分布による表現
?D : 経験分布 i.e. (X, Y) ~ D ?? Pr[(X, Y) = (Xi, Yi)] = 1
n
とするとき,
?R(h) = E(X,Y)~ ?D[?(h(X), Y)]
予測損失 R(h) と経験損失 ?R(h) の違いは期待値を真の分布 D
で取るか, 経験分布 ?D で取るかの違い
12](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-13-320.jpg)
![予測損失と経験損失 III
Fact 1
(Xi, Yi) ~ D (identically distributed)
=? E[?R(h)] = R(h)
i.e. ?R は R の不偏推定量.
(∵) Dn : (Xi, Yi), i = 1, ..., n の joint distribution とするとき,
EDn [?R(h)] = EDn
[
1
n
n∑
i=1
?(h(Xi), Yi)
]
=
1
n
n∑
i=1
ED[?(h(Xi), Yi)]
R(h)
= R(h) 2
13](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-14-320.jpg)
![予測損失と経験損失 IV
経験損失は予測損失の不偏推定量: E[?R(h)] = R(h)
? 上の事実は data の独立性を仮定していない. 独立性がある
と, さらに一致性が示せる(大数の弱法則) :
Proposition 1
(Xi, Yi) ~i.i.d. D のとき, ?ε > 0,
lim
n→∞
PrDn [|?R(h) ? R(h)| > ε] = 0
? 様々な学習問題は, 予測損失 R の最小化が目標 (分布 D が
未知なので R も未知)
?→ 代理として経験損失 ?R の最小化を通して R を小さ
くする
14](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-15-320.jpg)

![ベイズ規則とベイズ誤差 II
Bayes rule を具体的に求めてみる.
? ?(?y, y) : loss 関数
? P : test distribution
とするとき,
R(h) = E(X,Y)~P[?(?y, y)] = EX [EY [?(?y, y)|X]]
(∵)
EX[EY [?(h(x), y)|X]
(?)
] =
∫
X
{∫
Y
?(h(x), y)dP(y|x)
}
dP(x)
=
∫
X×Y
?(h(x), y)dP(x, y)
= R(h) 2
積分の単調性から (?) を小さくする h を選べば予測損失も小さ
くなる 17](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-18-320.jpg)
![Example 1.1 判別問題
? 0-1loss を用いると,
(?) =
∑
y∈Y
?(h(X), Y)P(Y = y|X) = 1 ? P(Y = h(X)|X)
より,
h0(X) = arg max
y∈Y
P(Y = y|X)
が予測誤差を最小にする仮説 (input に対して最も出現確
率の大きなラベルを出力)
? このときの Bayes error は
R?
= 1 ? EX
[
max
y∈Y
P(Y = y|X)
]
18](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-19-320.jpg)
![Example 1.2 回帰問題
? 2 乗 loss を用い, Y の分散を V[Y] とおくと,
EY[?(h, Y)] = E[h2
? 2hY + Y2
]
= E[h2
] ? 2E[hY] + E[Y2
] + E[Y2
] ? E[Y]2
= h2
? 2hE[Y] + E[Y]2
+ E[Y2
] ? E[Y]2
V[Y]
= (h ? E[Y])2
+ V[Y]
第 1 項を最小にする h が Bayes rule
? このとき, Bayes error は
R?
= R(h0) = EX[EY[?(h0(X), Y)|X]
V[Y|X]
]
= E[V[Y|X]]
条件付き分散が一定値 σ2 ならば, Bayes error も σ2
19](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-20-320.jpg)

![Example 1.3 ランキング問題 II
Definition 4 (true positive rate / false positive rate)
しきい値 a ∈ R に対して,
TPh(a) := Ex+~D+ [1[h(x+) > a]]
FPh(a) := Ex?~D? [1[h(x?) > a]]
? TPh(a) : しきい値 a において positive sample を正しく
positive と判定出来ている割合.
? FPh(a) : しきい値 a において negative sample を誤って
positive と判定している割合.
a ∈ R に対して, (FPh(a), TPh(a)) ∈ [0, 1]2
21](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-22-320.jpg)
![Example 1.3 ランキング問題 IV
期待損失と AUC との関係
0-1 loss の下で,
R(h) = 1 ? Ex±~D± [1[h(x+) ? h(x?) > 0]]
= 1 ? Ex?~D? [Ex+~D+ [1[h(x+) > h(x?)]]
TPh(h(x?))
]
= 1 ? Ex?~D? [TPh(h(x?))]
AUC(h)
= 1 ? AUC(h)
よって x+x? のとき,
? h0 = arg max AUC(h)
? Bayes error = 1 ? AUC(h0)
23](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-24-320.jpg)


![学習アルゴリズムの性能評価 II
A の性能の評価指標
1. 予測損失の学習データに関する期待値をとる:
ES~Dn [R(hS)]
?→ A の平均的な性能を評価
2. 汎化誤差の分布を評価:
Bayes error を R? = inf R(h) とおく. ε > 0 と δ ∈ (0, 1) に
対して
Pr[R(hS) ? R?
< ε] > 1 ? δ
が成り立つとする.
→ 十分大きい確率 1 ? δ に対して ε を十分小さく取れれば
Bayes error に近い予測損失を達成する仮説が求まる
26](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-27-320.jpg)
![学習アルゴリズムの性能評価 III
Fact 2 (評価指標 1 と 2 の関係)
PS~Dn [R(hS) ? R?
≥ ε] ≤
ES~Dn [R(hS)] ? R?
ε
? 予測損失と Bayes error の差が ε 以上である確率は, 予測損
失の期待値と Bayes error の差で上から抑えられる
(∵) Markov’s inequality :
P(|X| ≥ a) ≤
E[|X|]
a
, a > 0
より, |X| = R(hS) ? R?, a = ε とおくと直ちに従う 2
27](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-28-320.jpg)
![学習アルゴリズムの性能評価 IV
Definition 7 (統計的一致性)
?D : distribution, ?ε > 0 に対して, 学習アルゴリズム
A : S → hS が統計的一致性をもつ
:?? lim
n→∞
PS~Dn [R(hS) ? R?
≤ ε] = 1
“data が多ければ最適な仮説を達成する” という良い学習アル
ゴリズムの性質
28](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-29-320.jpg)



![予測判別誤差 (0-1 loss の汎化誤差) の評価 III
Rerr(hS) ? Rerr(h0)
= Rerr(hS) ? ?Rerr(hS) + ?Rerr(hS) ? Rerr(hH) + Rerr(hH) ? Rerr(h0)
≤ Rerr(hS) ? ?Rerr(hS) + ?Rerr(hH) ? Rerr(hH) + Rerr(hH) ? Rerr(h0)
≤ max
h
|?Rerr(h) ? Rerr(h)| + max
h
|?Rerr(h) ? Rerr(h)| + Rerr(hH) ? Rerr(h0)
= 2 max
h
|?Rerr(h) ? Rerr(h)| + Rerr(hH) ? Rerr(h0) ? (?)
ここで (?) の第 1 項に Hoeffding’s inequality を使う
Lemma 1 (Hoeffding’s inequality)
Z : [0,1]-valued r.v. で Z1, ..., Zn ~i.i.d. PZ のとき, ε > 0,
P
[
1
n
n∑
i=1
Zi ? E[Z] ≥ ε
]
≤ 2e?2nε2
32](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-33-320.jpg)
![予測判別誤差 (0-1 loss の汎化誤差) の評価 IV
Hoeffding’s inequality の Z として 1[h(X) ?= Y] を取ると,
P
[
2 max
h∈H
|?Rerr(h) ? Rerr(h)| ≥ ε
]
≤
∑
h∈H
P
[
|?Rerr(h) ? Rerr(h)| ≥
ε
2
]
≤2e?2nε2/4
≤ 2|H|e?nε2/2
ここで, δ = 2|H|e?nε2/2 とおくと, 学習データ S が given の下で
P
[
Rerr(hS) ? Rerr(h0) ≤ Rerr(hH) ? Rerr(h0) +
√
2
n
log
2|H|
δ
]
≥ 1 ? δ
が成立.
33](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-34-320.jpg)
![予測判別誤差 (0-1 loss の汎化誤差) の評価 V
P
[
Rerr(hS) ? Rerr(h0) ≤ Rerr(hH) ? Rerr(h0) +
√
2
n
log
2|H|
δ
]
≥ 1 ? δ
(∵)
δ = 2|H|e?nε2/2
??
δ
2|H|
= e?nε2/2
?? log
δ
2|H|
=
?nε2
2
?? ε2
=
2
n
log
2|H|
δ
より,
P
[
2 max
h∈H
|?Rerr(h) ? Rerr(h)| ≥ ε
]
≤ 2|H|e?nε2/2
?? P
[
2 max
h∈H
|?Rerr(h) ? Rerr(h)| ≤
√
2
n
log
2|H|
δ
]
≥ 1 ? δ
34](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-35-320.jpg)
![予測判別誤差 (0-1 loss の汎化誤差) の評価 VI
(?) の第 1 項を上の評価で置き換えると,
Rerr(hS) ? Rerr(h0) ≤
√
2
n
log
2|H|
δ
+ Rerr(hH) ? Rerr(h0) w.p. 1 ? δ
が言える 2
? 仮説集合 H が Bayes rule を含むとき (hH = h0 のとき) :
Rerr(hH) ? Rerr(h0) = 0
=? Rerr(hS) ?→ Rerr(h0) as n → ∞
? 確率オーダー表記 (cf 例 2.1):
Rerr(hS) = Rerr(h0) + Op
(√
log |H|
n
)
i.e. lim
z→∞
lim sup
n→∞
P[|Rerr(hS)|/
√
log |H|/n > z] = 0
35](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-36-320.jpg)

![近似誤差と推定誤差 III
予測誤差を小さくする仮説集合 H?m として, 以下を満たすもの
が良さそう
?m = arg min
1≤m≤M
[biasHm + varHm ]
? bias が data 分布に依存するため上手い基準ではない
→ 正則化
38](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-39-320.jpg)
![正則化 I
アイデア: 大きな仮説集合から仮説を選ぶことに対してペナル
ティを課す
Definition 9 (ペナルティ関数)
仮説集合の増大列 H1 ? · · · ? HM. Φ : Hm → R≥0 が仮説 h に
対するペナルティ関数
:?? m1 < m2 に対して, h ∈ Hm1 , h′ ∈ Hm2 Hm1 ?
Φ(h) ≤ Φ(h′)
Example 2 (大きい仮説集合ほどペナルティも大きい)
H0 = ? として, 0 < w1 < · · · < wM に対して
Φ(h) =
M∑
m=1
wm1[h ∈ HmHm?1]
39](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-40-320.jpg)

![References
[1] Olivier Bousquet, Stéphane Boucheron, and Gábor Lugosi.
Introduction to statistical learning theory. In Advanced
lectures on machine learning, pages 169–207. Springer, 2004.
[2] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar.
Foundations of machine learning. MIT press, 2012.
[3] Shai Shalev-Shwartz and Shai Ben-David. Understanding
machine learning: From theory to algorithms. Cambridge
university press, 2014.
[4] 金森敬文. 統計的学習理論 (機械学習プロフェッショナルシ
リーズ), 2015.
41](https://image.slidesharecdn.com/sltsec1-181004081130/85/1-42-320.jpg)
「统计的学习理论」第1章
- 1. 統計的学習理論読み Kota Matsui October 4, 2018 理研 AIP データ駆動型生物医科学チーム
- 2. 導入 I ? 機械学習の文脈でよく見る ? モデルが汎化する ? モデルの汎化性能が高い ? 予測損失 (期待損失) が小さいことと定義される ? practical にはテスト誤差 (学習データとは独立に取得した テストデータで評価した誤差) で汎化性能を評価している 素朴な疑問 (学習理論が答えようとしていること) ? 上記の方法はどのように正当化されているのか? ? 経験損失最小化でなぜ予測損失を小さくできるのか? ? 経験損失と予測損失にどんなギャップがあるのか? 1
- 3. 導入 II Vapnik の思想 [Vapnik, 98] Nothing is more practical than a good theory. 理論に基づいたアルゴリズム ? カーネル法 (サポートベクターマシン) ? ブースティング (アダブースト)... このセミナーでは [4] を読んで機械学習の理論的側面に親しみ たい. 本スライドは [4] の第 1 章のまとめである. 2
- 4. Table of contents 1. 統計的学習理論の枠組み 3
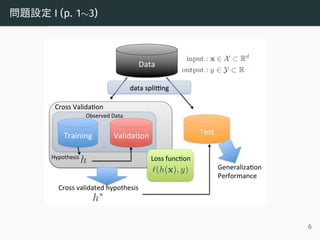
- 7. 問題設定 I (p. 1~3) Data Training Valida,on Test Cross Valida,on Cross validated hypothesis Generaliza,on Performance data spli<ng input : x X Rd output : y Y R Observed Data h h Hypothesis (h(x), y) Loss func,on 6
- 8. 問題設定 II 判別問題 (§1.1.1) ? |Y| < ∞ のとき, input data から label を予測する. ? |Y| = 2 : 2 値判別 (e.g. 迷惑メール分類 Y = {“spam”, “nonspam”}) ? |Y| ≥ 3 : 多値判別 ? 判別問題における loss function (0-1 loss) ?(?y, y) = 1[?y ?= y] = ? ? ? 1 if y ?= ?y 0 otherwise ? ?= ? ? ? ?y if y ?= ?y 0 otherwise ? ? 損失が真ラベルに依存する場合 7
- 9. 問題設定 III 回帰問題 (§1.1.2) ? Y = R のとき input から output を予測 (e.g. 株価や電力需 要の予測) ? 回帰問題の loss function (squared loss) ?(?y, y) = |?y ? y|2 8
- 10. 問題設定 IV ランキング問題 (§1.1.3) ? 3 つ組 data (x, x′, y) ∈ X2 × Y を観測 y = ? ? ? +1 if x ? x′ ?1 if x ? x′ ? 以下のような仮説 h : X → R を学習 x ? x′ ? h(x) > h(x′ ) x ? x′ ? h(x) ≤ h(x′ ) ? ランキング問題の loss function (0-1 loss) ?(?h, y) = ? ? ? 1 if y(h1 ? h2) ≤ 0 0 otherwise ここで h1 = h(x), h2 = h(x′), ?h = (h1, h2) ∈ R2. 0 ? 1 損失の下でランキング問題は判別として扱える. 9
- 12. 予測損失と経験損失 I Definition 1 (予測 (期待) 損失) test data (X, Y) の従う分布 D の下での仮説 h の予測損失を以 下で定義 R(h) := E(X,Y)~D[?(h(X), Y)] Example 1 (0-1 loss) 0-1 loss の予測損失 (期待判別誤差) は Rerr(h) = Pr[h(X) ?= Y] = E[1[h(X) ?= Y]] 学習の目標 data の真の分布が未知なため直接計算不可能な期待損失を観 測 data のみを用いて小さくする 11
- 13. 予測損失と経験損失 II Definition 2 (経験損失) {(Xi, Yi)}n i=1 : observed data 仮説 h の経験損失を以下で定義 ?R(h) := 1 n n∑ i=1 ?(h(Xi), Yi) 経験分布による表現 ?D : 経験分布 i.e. (X, Y) ~ D ?? Pr[(X, Y) = (Xi, Yi)] = 1 n とするとき, ?R(h) = E(X,Y)~ ?D[?(h(X), Y)] 予測損失 R(h) と経験損失 ?R(h) の違いは期待値を真の分布 D で取るか, 経験分布 ?D で取るかの違い 12
- 14. 予測損失と経験損失 III Fact 1 (Xi, Yi) ~ D (identically distributed) =? E[?R(h)] = R(h) i.e. ?R は R の不偏推定量. (∵) Dn : (Xi, Yi), i = 1, ..., n の joint distribution とするとき, EDn [?R(h)] = EDn [ 1 n n∑ i=1 ?(h(Xi), Yi) ] = 1 n n∑ i=1 ED[?(h(Xi), Yi)] R(h) = R(h) 2 13
- 15. 予測損失と経験損失 IV 経験損失は予測損失の不偏推定量: E[?R(h)] = R(h) ? 上の事実は data の独立性を仮定していない. 独立性がある と, さらに一致性が示せる(大数の弱法則) : Proposition 1 (Xi, Yi) ~i.i.d. D のとき, ?ε > 0, lim n→∞ PrDn [|?R(h) ? R(h)| > ε] = 0 ? 様々な学習問題は, 予測損失 R の最小化が目標 (分布 D が 未知なので R も未知) ?→ 代理として経験損失 ?R の最小化を通して R を小さ くする 14
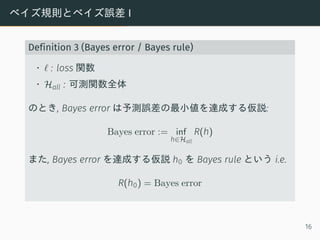
- 17. ベイズ規則とベイズ誤差 I Definition 3 (Bayes error / Bayes rule) ? ? : loss 関数 ? Hall : 可測関数全体 のとき, Bayes error は予測誤差の最小値を達成する仮説: Bayes error := inf h∈Hall R(h) また, Bayes error を達成する仮説 h0 を Bayes rule という i.e. R(h0) = Bayes error 16
- 18. ベイズ規則とベイズ誤差 II Bayes rule を具体的に求めてみる. ? ?(?y, y) : loss 関数 ? P : test distribution とするとき, R(h) = E(X,Y)~P[?(?y, y)] = EX [EY [?(?y, y)|X]] (∵) EX[EY [?(h(x), y)|X] (?) ] = ∫ X {∫ Y ?(h(x), y)dP(y|x) } dP(x) = ∫ X×Y ?(h(x), y)dP(x, y) = R(h) 2 積分の単調性から (?) を小さくする h を選べば予測損失も小さ くなる 17
- 19. Example 1.1 判別問題 ? 0-1loss を用いると, (?) = ∑ y∈Y ?(h(X), Y)P(Y = y|X) = 1 ? P(Y = h(X)|X) より, h0(X) = arg max y∈Y P(Y = y|X) が予測誤差を最小にする仮説 (input に対して最も出現確 率の大きなラベルを出力) ? このときの Bayes error は R? = 1 ? EX [ max y∈Y P(Y = y|X) ] 18
- 20. Example 1.2 回帰問題 ? 2 乗 loss を用い, Y の分散を V[Y] とおくと, EY[?(h, Y)] = E[h2 ? 2hY + Y2 ] = E[h2 ] ? 2E[hY] + E[Y2 ] + E[Y2 ] ? E[Y]2 = h2 ? 2hE[Y] + E[Y]2 + E[Y2 ] ? E[Y]2 V[Y] = (h ? E[Y])2 + V[Y] 第 1 項を最小にする h が Bayes rule ? このとき, Bayes error は R? = R(h0) = EX[EY[?(h0(X), Y)|X] V[Y|X] ] = E[V[Y|X]] 条件付き分散が一定値 σ2 ならば, Bayes error も σ2 19
- 21. Example 1.3 ランキング問題 I ランキングを 2 値判別として定式化すると, 仮説空間が H = {sign(h(x) ? h(x′ ))} なる形の関数空間に制限される. → 2 値判別の Bayes rule からランキングの Bayes rule は構成 できない → data 分布に仮定をおき, Bayes rule を特徴づける 設定 ? input を (x+, x?) ∈ X2 とおき, 常に x+ ? x?, y = +1 とする ? もし (x, x′, ?1) なる data があれば (x′, x, +1) と変換 ? x+ ~i.i.d. D+, x? ~i.i.d. D? とし, ランキング関数 h : X → R を学習 20
- 22. Example 1.3 ランキング問題 II Definition 4 (true positive rate / false positive rate) しきい値 a ∈ R に対して, TPh(a) := Ex+~D+ [1[h(x+) > a]] FPh(a) := Ex?~D? [1[h(x?) > a]] ? TPh(a) : しきい値 a において positive sample を正しく positive と判定出来ている割合. ? FPh(a) : しきい値 a において negative sample を誤って positive と判定している割合. a ∈ R に対して, (FPh(a), TPh(a)) ∈ [0, 1]2 21
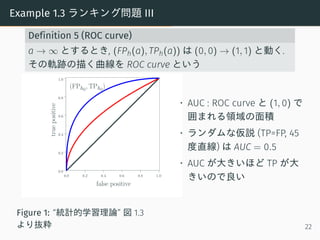
- 23. Example 1.3 ランキング問題 III Definition 5 (ROC curve) a → ∞ とするとき, (FPh(a), TPh(a)) は (0, 0) → (1, 1) と動く. その軌跡の描く曲線を ROC curve という 2015/1/24(21:30) 14 統計的学習理論の枠組 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 false positive truepositive (FPh0 , TPh0 ) 図 1.3 ROC 曲線のプロット.適切に仮説を選ぶと ROC 曲線は 45? の線 (TP = FP) より大 きくなり,AUC は 0.5 を越えます. Figure 1: “統計的学習理論” 図 1.3 より抜粋 ? AUC : ROC curve と (1, 0) で 囲まれる領域の面積 ? ランダムな仮説 (TP=FP, 45 度直線) は AUC = 0.5 ? AUC が大きいほど TP が大 きいので良い 22
- 24. Example 1.3 ランキング問題 IV 期待損失と AUC との関係 0-1 loss の下で, R(h) = 1 ? Ex±~D± [1[h(x+) ? h(x?) > 0]] = 1 ? Ex?~D? [Ex+~D+ [1[h(x+) > h(x?)]] TPh(h(x?)) ] = 1 ? Ex?~D? [TPh(h(x?))] AUC(h) = 1 ? AUC(h) よって x+x? のとき, ? h0 = arg max AUC(h) ? Bayes error = 1 ? AUC(h0) 23
- 26. 学習アルゴリズムの性能評価 I Definition 6 (学習アルゴリズム) 学習アルゴリズムは観測データ集合から仮説集合への map : A :2X×Y ?→ H S → A(S) = hS ここで, S = {(Xi, Yi)}n i=1 25
- 27. 学習アルゴリズムの性能評価 II A の性能の評価指標 1. 予測損失の学習データに関する期待値をとる: ES~Dn [R(hS)] ?→ A の平均的な性能を評価 2. 汎化誤差の分布を評価: Bayes error を R? = inf R(h) とおく. ε > 0 と δ ∈ (0, 1) に 対して Pr[R(hS) ? R? < ε] > 1 ? δ が成り立つとする. → 十分大きい確率 1 ? δ に対して ε を十分小さく取れれば Bayes error に近い予測損失を達成する仮説が求まる 26
- 28. 学習アルゴリズムの性能評価 III Fact 2 (評価指標 1 と 2 の関係) PS~Dn [R(hS) ? R? ≥ ε] ≤ ES~Dn [R(hS)] ? R? ε ? 予測損失と Bayes error の差が ε 以上である確率は, 予測損 失の期待値と Bayes error の差で上から抑えられる (∵) Markov’s inequality : P(|X| ≥ a) ≤ E[|X|] a , a > 0 より, |X| = R(hS) ? R?, a = ε とおくと直ちに従う 2 27
- 29. 学習アルゴリズムの性能評価 IV Definition 7 (統計的一致性) ?D : distribution, ?ε > 0 に対して, 学習アルゴリズム A : S → hS が統計的一致性をもつ :?? lim n→∞ PS~Dn [R(hS) ? R? ≤ ε] = 1 “data が多ければ最適な仮説を達成する” という良い学習アル ゴリズムの性質 28
- 31. 予測判別誤差 (0-1 loss の汎化誤差) の評価 I 問題設定 ? 2 値判別問題 (? : 0-1 loss) ? 有限仮説集合: H := {h1, ..., hT}, ht : X → {+1, ?1} ? 学習データ: S = {(Xi, Yi)}n i=1, (Xi, Yi) ~i.i.d. P このとき, 学習アルゴリズムとして経験判別誤差を最小にする 仮説を出力するものを考える: A :2X×Y → H S → A(S) = hS = arg min h∈H ?Rerr(h) 1 n ∑n i=1 ?(h(Xi),Yi) 分布 P の下での 0-1 loss に関する Bayes rule を h0 とする (一 般に h0 ?∈ H) 30
- 32. 予測判別誤差 (0-1 loss の汎化誤差) の評価 II 予測判別誤差と Bayes error の gap Rerr(hS) ? Rerr(h0) を評価. いま, hH := arg min h∈H Rerr(h) とおくと以下が成立: ? Rerr(h0) 全可測関数で min ≤ Rerr(hH) H 内で min ≤ Rerr(hS) ? ?Rerr(hS) ≤ ?Rerr(hH) 31
- 33. 予測判別誤差 (0-1 loss の汎化誤差) の評価 III Rerr(hS) ? Rerr(h0) = Rerr(hS) ? ?Rerr(hS) + ?Rerr(hS) ? Rerr(hH) + Rerr(hH) ? Rerr(h0) ≤ Rerr(hS) ? ?Rerr(hS) + ?Rerr(hH) ? Rerr(hH) + Rerr(hH) ? Rerr(h0) ≤ max h |?Rerr(h) ? Rerr(h)| + max h |?Rerr(h) ? Rerr(h)| + Rerr(hH) ? Rerr(h0) = 2 max h |?Rerr(h) ? Rerr(h)| + Rerr(hH) ? Rerr(h0) ? (?) ここで (?) の第 1 項に Hoeffding’s inequality を使う Lemma 1 (Hoeffding’s inequality) Z : [0,1]-valued r.v. で Z1, ..., Zn ~i.i.d. PZ のとき, ε > 0, P [ 1 n n∑ i=1 Zi ? E[Z] ≥ ε ] ≤ 2e?2nε2 32
- 34. 予測判別誤差 (0-1 loss の汎化誤差) の評価 IV Hoeffding’s inequality の Z として 1[h(X) ?= Y] を取ると, P [ 2 max h∈H |?Rerr(h) ? Rerr(h)| ≥ ε ] ≤ ∑ h∈H P [ |?Rerr(h) ? Rerr(h)| ≥ ε 2 ] ≤2e?2nε2/4 ≤ 2|H|e?nε2/2 ここで, δ = 2|H|e?nε2/2 とおくと, 学習データ S が given の下で P [ Rerr(hS) ? Rerr(h0) ≤ Rerr(hH) ? Rerr(h0) + √ 2 n log 2|H| δ ] ≥ 1 ? δ が成立. 33
- 35. 予測判別誤差 (0-1 loss の汎化誤差) の評価 V P [ Rerr(hS) ? Rerr(h0) ≤ Rerr(hH) ? Rerr(h0) + √ 2 n log 2|H| δ ] ≥ 1 ? δ (∵) δ = 2|H|e?nε2/2 ?? δ 2|H| = e?nε2/2 ?? log δ 2|H| = ?nε2 2 ?? ε2 = 2 n log 2|H| δ より, P [ 2 max h∈H |?Rerr(h) ? Rerr(h)| ≥ ε ] ≤ 2|H|e?nε2/2 ?? P [ 2 max h∈H |?Rerr(h) ? Rerr(h)| ≤ √ 2 n log 2|H| δ ] ≥ 1 ? δ 34
- 36. 予測判別誤差 (0-1 loss の汎化誤差) の評価 VI (?) の第 1 項を上の評価で置き換えると, Rerr(hS) ? Rerr(h0) ≤ √ 2 n log 2|H| δ + Rerr(hH) ? Rerr(h0) w.p. 1 ? δ が言える 2 ? 仮説集合 H が Bayes rule を含むとき (hH = h0 のとき) : Rerr(hH) ? Rerr(h0) = 0 =? Rerr(hS) ?→ Rerr(h0) as n → ∞ ? 確率オーダー表記 (cf 例 2.1): Rerr(hS) = Rerr(h0) + Op (√ log |H| n ) i.e. lim z→∞ lim sup n→∞ P[|Rerr(hS)|/ √ log |H|/n > z] = 0 35
- 37. 近似誤差と推定誤差 I Definition 8 (近似誤差 (bias) / 推定誤差 (variance) 分解) 評価式 Rerr(hS) ? Rerr(h0) ≤ √ 2 n log 2|H| δ + Rerr(hH) ? Rerr(h0) において, 近似誤差 (bias) と推定誤差 (var) を以下で定義. biasH := Rerr(hH) ? Rerr(h0) varH := √ 2 n log 2|H| δ ? bias はモデルが外れている (Bayes rule を含まない) こと で生じる誤差 (一般に h0 ?∈ H より biasH ≥ 0) ? var は学習データ (サンプルサイズ) に由来するばらつき 36
- 38. 近似誤差と推定誤差 II bias-variance trade-off 仮説空間の増大列 H1 ? · · · ? HM, |HM| < ∞ に対して biasH1 ≥ · · · ≥ biasHM , varH1 ≤ · · · ≤ varHM ? 仮説空間が広いほど Bayes rule に近い仮説が手に入りやす い ? サンプルサイズを止めて H を広げるとばらつきが増大 ? サンプルサイズが十分大 ? 大きな H でも var は bias に対して大きくない ? サンプルサイズが小さい ? var は H の大きさの影響を受けやすい 37
- 39. 近似誤差と推定誤差 III 予測誤差を小さくする仮説集合 H?m として, 以下を満たすもの が良さそう ?m = arg min 1≤m≤M [biasHm + varHm ] ? bias が data 分布に依存するため上手い基準ではない → 正則化 38
- 40. 正則化 I アイデア: 大きな仮説集合から仮説を選ぶことに対してペナル ティを課す Definition 9 (ペナルティ関数) 仮説集合の増大列 H1 ? · · · ? HM. Φ : Hm → R≥0 が仮説 h に 対するペナルティ関数 :?? m1 < m2 に対して, h ∈ Hm1 , h′ ∈ Hm2 Hm1 ? Φ(h) ≤ Φ(h′) Example 2 (大きい仮説集合ほどペナルティも大きい) H0 = ? として, 0 < w1 < · · · < wM に対して Φ(h) = M∑ m=1 wm1[h ∈ HmHm?1] 39
- 41. 正則化 II 正則化付き経験誤差最小化 min h∈HM ?Rerr(h) + λΦ(h) ? 想定する最大の仮説空間で最適化を実行 ? λ の決め方: ? data 数に依存させ, 適切なオーダーで λn → 0 as n → ∞ と する ? クロスバリデーション 40
- 42. References [1] Olivier Bousquet, Stéphane Boucheron, and Gábor Lugosi. Introduction to statistical learning theory. In Advanced lectures on machine learning, pages 169–207. Springer, 2004. [2] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT press, 2012. [3] Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014. [4] 金森敬文. 統計的学習理論 (機械学習プロフェッショナルシ リーズ), 2015. 41