



![ī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į
?? •Ō©`•…•Į•ť•Ļ•Ņ•Í•ů•į
?
?? “Ľ§ń§ő•«©`•Ņ§Ō“Ľ§ń§ő•Į•ť•Ļ•Ņ§ň§ő§Ŗ∑÷Óź§Ķ§ž§Ž
?
?? •Į•ť•Ļ•Ņ•Í•ů•įĹYĻŻņż
?
?? •«©`•Ņ£Ī§Ō•Į•ť•Ļ•ŅA
?
?? •«©`•Ņ£≤§Ō•Į•ť•Ļ•ŅB
?
?? ī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į
?
?? ňý ۧĻ§Ž•Į•ť•Ļ•Ņ§Ōī_¬ Ķń§ň∂®§Š§ť§ž§Ž
?
?? •Į•ť•Ļ•Ņ•Í•ů•įĹYĻŻņż
?(•Į•ť•Ļ•Ņ ż
?=
?3)
?
?? •«©`•Ņ£Ī§Ō•Į•ť•Ļ•Ņ
[A,B,C]
?§ň
?[0.8,0.1,0.1]
?§őī_¬ §«
ňý ۧĻ§Ž
?
?? •«©`•Ņ£≤§Ō•Į•ť•Ļ•Ņ
[A,B,C]
?§ň
?[0.1,0.3,0.6]
?§őī_¬ §«
ňý ۧĻ§Ž
?
?? °łī_¬ •‚•«•Ž°Ļ§√§∆§ §ů§Ļ§ę£Ņ£Ņ£®īő•ŕ©`•ł£©
?](https://image.slidesharecdn.com/10-140304101559-phpapp01/85/10-4-320.jpg)
![•Į•ť•Ļ•Ņ•Í•ů•į§ň§™§Ī§Žī_¬ •‚•«•Ž
?? •‚•«•Ž§»§∑§∆ĀĘ∂®§Ļ§Ž§‚§ő
?
1.? •Į•ť•Ļ•Ņöį§ő•«©`•Ņ∑÷≤ľ•‚•«•Ž
?
2.? [1]
?§őĺÄ–őļÕ§ň§Ť§√§∆ĪŪ¨F§Ķ§ž§Ž»ęŐŚ§ő•«©`•Ņ∑÷≤ľ•‚•«•Ž
?
?? §Ť§Į Ļ§Ô§ž§Ž§ő§ŌĽžļŌ’ż“é∑÷≤ľ•‚•«•Ž
?
(%)
?
?
•‚•«•Ž§őņż
?
?“Ľīő‘™’ż“é∑÷≤ľ
?
?£≥•Į•ť•Ļ•Ņ
?
x
?:
?”Qúy•«©`•Ņ
?](https://image.slidesharecdn.com/10-140304101559-phpapp01/85/10-5-320.jpg)


![ī_¬ •‚•«•Ž£®ĽžļŌ’ż“é∑÷≤ľ•‚•«•Ž£©
?
§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į§»§Ō£Ņ
?? Ō¬”õ§ő£≤§ń§Ú––§¶§≥§»
?
1.? ”Qúy•«©`•Ņ§Ú◊Ó§‚§Ť§ĮĪŪ¨F§Ļ§Žī_¬ •‚•«•Ž§ÚÕ∆∂®
?
?? ī_¬ •‚•«•Ž§ő•—•ť•Š©`•ŅÕ∆∂®£®∆Ĺĺý?∑÷…Ę?ĽžļŌĪ»£©
?
2.? Õ∆∂®§∑§Ņ•‚•«•Ž§ň§Ť§√§∆łų•«©`•Ņ§ő•Į•ť•Ļ•Ņ§ÚÕ∆∂®
?
?? łų•«©`•Ņ§¨łų•Į•ť•Ļ•Ņ§ňňý ۧĻ§Žī_¬ §ő—›ň„
?
?? —›ň„§Ļ§Žī_¬ §ő ż§Ō
?[•«©`•Ņ ż]
?°Ń
?[•Į•ť•Ļ•Ņ ż]
?
?
?? [1][2]§őÕ∆∂®§ÚĹĽĽ•§ňĆg ©§∑°Ę◊ÓŖm§ •‚•«•ŽÕ∆∂®§Ú––
§¶§ő§¨
?EM
?•Ę•Ž•ī•Í•ļ•ŗ£®ŠŠ Ų£©
?
x1
?:
?[A,B,C]
?=
?[0.8,
?0.1,
?0.1]
?
x2
?:
?[A,B,C]
?=
?[0.1,
?0.6,
?0.3]
?
x3
?:
?[A,B,C]
?=
?[0.3,
?0.3,
?0.4]
[1]M•Ļ•∆•√•◊
[2]E•Ļ•∆•√•◊](https://image.slidesharecdn.com/10-140304101559-phpapp01/85/10-8-320.jpg)

















§Ō§∑?§Š§∆§ő•Ō?•Ņ©`•ů’J◊R›Ü’iĽŠ 10’¬ŠŠįŽ
- 1. §Ō§ł•—•Ņ›Ü’iĽŠ ? 10’¬ŠŠįŽ£®10.4£© ī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į ? 2014/3/4 ? @_kobacky
- 2. ◊Ó≥ű§ő§™§≥§»§Ô§Í m(_ ?_)m ?? ĪĺŔYŃŌ§ŌĹŐŅ∆ēݧڒi§ů§«◊Ó≥ű£Ņ£Ņ£Ņ£Ņ§ņ§√§Ņ ? @_kobacky ?§ő§Ť§¶§ »ň§¨√„Źä§Ļ§Ž§Ņ§Š§ő§»§√§ę§ę§Í §»§ §Ž§≥§»§ÚńŅėň§»§∑§ř§Ļ°£ ? ?? §Ĺ§ő§Ņ§Š°Ę§ §Ž§Ŕ§Į∑÷≤ľ§ÚáŪ ĺ§∑§∆Ņľ§®§Ņ§§§«§Ļ°£ §Ĺ§≥§«ĹŐŅ∆ēݧ«§Ō ?dīő‘™§ő•«©`•Ņ§ň§ń§§§∆’麟§ť§ž §∆§§§ř§Ļ§¨°ĘáŪ§šņż§Ō“Ľīő‘™•«©`•Ņ§«Ņľ§®§∆◊ų≥…§∑ §∆§§§ř§Ļ°£∆Ĺĺý•Ŕ•Į•»•Ž§»§ęĻ≤∑÷…Ę––Ń–§Ō“ĽĶ©÷√§§ §»§§§∆°Ę∆Ĺĺýāé?∑÷…Ęā駫Ņľ§®§Ķ§Ľ§∆Ō¬§Ķ§§°£ ? ?? ĪĺŔYŃŌ§Ō“Ľ≤Ņ°ĘĹŐŅ∆ēݧň”õ›d§ő§ §§°Ę◊ų≥…’Ŗ§őĹ‚Šč §ň§Ť§Žńŕ»›§Úļ¨§ů§«§§§ř§Ļ°£
- 3. °ĺSTEP1°Ņ10.4.1 ?Ļ̧»»ęŐŚŌŮ §Ĺ§‚§Ĺ§‚ī_¬ •‚•«•Ž§»§Ōļő§ę£Ņī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť •Ļ•Ņ•Í•ů•į§»§Ōļő§Ú§Ļ§Ž§≥§»§ §ő§ęņŪĹ‚§∑§ř§∑§Á§¶°£ ? ? °ĺńŅėň£°°Ņ ? ?? •Ō©`•…•Į•ť•Ļ•Ņ•Í•ů•į§»§őŖ`§§§ÚņŪĹ‚§Ļ§Ž ? ?? ī_¬ •‚•«•Ž§ň§ń§§§∆ņŪĹ‚§Ļ§Ž ? ?? ĽžļŌ’ż“é∑÷≤ľ§»§Ĺ§ő•—•ť•Š©`•Ņ§ň§ń§§§∆ņŪĹ‚§Ļ§Ž ? ?? ī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į§»§ŌĺŖŐŚĶń§ňļő§Ú «ů§Š§Ž§≥§»§ §ő§ę§ň§ń§§§∆ņŪĹ‚§Ļ§Ž ?
- 4. ī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į ?? •Ō©`•…•Į•ť•Ļ•Ņ•Í•ů•į ? ?? “Ľ§ń§ő•«©`•Ņ§Ō“Ľ§ń§ő•Į•ť•Ļ•Ņ§ň§ő§Ŗ∑÷Óź§Ķ§ž§Ž ? ?? •Į•ť•Ļ•Ņ•Í•ů•įĹYĻŻņż ? ?? •«©`•Ņ£Ī§Ō•Į•ť•Ļ•ŅA ? ?? •«©`•Ņ£≤§Ō•Į•ť•Ļ•ŅB ? ?? ī_¬ •‚•«•Ž§ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į ? ?? ňý ۧĻ§Ž•Į•ť•Ļ•Ņ§Ōī_¬ Ķń§ň∂®§Š§ť§ž§Ž ? ?? •Į•ť•Ļ•Ņ•Í•ů•įĹYĻŻņż ?(•Į•ť•Ļ•Ņ ż ?= ?3) ? ?? •«©`•Ņ£Ī§Ō•Į•ť•Ļ•Ņ [A,B,C] ?§ň ?[0.8,0.1,0.1] ?§őī_¬ §« ňý ۧĻ§Ž ? ?? •«©`•Ņ£≤§Ō•Į•ť•Ļ•Ņ [A,B,C] ?§ň ?[0.1,0.3,0.6] ?§őī_¬ §« ňý ۧĻ§Ž ? ?? °łī_¬ •‚•«•Ž°Ļ§√§∆§ §ů§Ļ§ę£Ņ£Ņ£®īő•ŕ©`•ł£© ?
- 5. •Į•ť•Ļ•Ņ•Í•ů•į§ň§™§Ī§Žī_¬ •‚•«•Ž ?? •‚•«•Ž§»§∑§∆ĀĘ∂®§Ļ§Ž§‚§ő ? 1.? •Į•ť•Ļ•Ņöį§ő•«©`•Ņ∑÷≤ľ•‚•«•Ž ? 2.? [1] ?§őĺÄ–őļÕ§ň§Ť§√§∆ĪŪ¨F§Ķ§ž§Ž»ęŐŚ§ő•«©`•Ņ∑÷≤ľ•‚•«•Ž ? ?? §Ť§Į Ļ§Ô§ž§Ž§ő§ŌĽžļŌ’ż“é∑÷≤ľ•‚•«•Ž ? (%) ? ? •‚•«•Ž§őņż ? ?“Ľīő‘™’ż“é∑÷≤ľ ? ?£≥•Į•ť•Ļ•Ņ ? x ?: ?”Qúy•«©`•Ņ ?
- 6. ĽžļŌ’ż“é∑÷≤ľ•‚•«•Ž§ő•—•ť•Š©`•Ņ ?? łų•Į•ť•Ļ•Ņ§ő’ż“é∑÷≤ľ•—•ť•Š©`•Ņ ? ?? ¶Ők ?: ?∆Ĺĺý ? ?? ¶≤k ?: ?∑÷…Ę£®ėňú ∆ę≤Ó§«§‚Ņ…£© ? ?? ĽžļŌ§Ļ§Ž§Ņ§Š§ňĪō“™§ •—•ť•Š©`•Ņ ? ?? ¶–k ?: ?•Į•ť•Ļ•Ņöį§ő’ż“é∑÷≤ľ§őĽžļŌĪ» ? ĽžļŌ’ż“é∑÷≤ľ •Į•ť•Ļ•Ņ£Ī ? = ?¶–1 ?°Ń ? ∑÷…Ę£ļ¶≤1 ? ? •Į•ť•Ļ•Ņ£≥ ? + ? ?¶–3 ?°Ń ? + ? ?¶–2 ?°Ń ? ∆Ĺĺý£ļ¶Ő1 ? ? §Ľ§ů?§Ī§§?§Ô£° ? •Į•ť•Ļ•Ņ£≤ ? ∆Ĺĺý£ļ¶Ő2 ? ? ∑÷…Ę£ļ¶≤2 ? ? ∆Ĺĺý£ļ¶Ő3 ? ? ∑÷…Ę£ļ¶≤3 ? ?
- 7. §Ń§ §Ŗ§ň?? ?? ĪĺŔYŃŌ§őī_¬ •‚•«•ŽáŪ§ŌExcel ?§«Ō¬”õ§őÕ®§Í◊ų≥… ? ?? 9•—•ť•Š©`•Ņ§«•‚•«•Ž§¨õQ∂®§∑§∆§§§Ž§ő§¨§Ô§ę§Ž ? ?? •—•ť•Š©`•Ņ§Ú…ę°©Čš§®§∆•‚•«•Ž§őČšĽĮ§Ú§Ŗ§Ž§»√śį◊§§ §ę§‚?? ? ?? §≥§Ń§ť§ę§ť ?DL ?Ņ…ń‹ ?-?©\> ?hNp://bit.ly/1eJCa4i ? ?
- 8. ī_¬ •‚•«•Ž£®ĽžļŌ’ż“é∑÷≤ľ•‚•«•Ž£© ? §ň§Ť§Ž•Į•ť•Ļ•Ņ•Í•ů•į§»§Ō£Ņ ?? Ō¬”õ§ő£≤§ń§Ú––§¶§≥§» ? 1.? ”Qúy•«©`•Ņ§Ú◊Ó§‚§Ť§ĮĪŪ¨F§Ļ§Žī_¬ •‚•«•Ž§ÚÕ∆∂® ? ?? ī_¬ •‚•«•Ž§ő•—•ť•Š©`•ŅÕ∆∂®£®∆Ĺĺý?∑÷…Ę?ĽžļŌĪ»£© ? 2.? Õ∆∂®§∑§Ņ•‚•«•Ž§ň§Ť§√§∆łų•«©`•Ņ§ő•Į•ť•Ļ•Ņ§ÚÕ∆∂® ? ?? łų•«©`•Ņ§¨łų•Į•ť•Ļ•Ņ§ňňý ۧĻ§Žī_¬ §ő—›ň„ ? ?? —›ň„§Ļ§Žī_¬ §ő ż§Ō ?[•«©`•Ņ ż] ?°Ń ?[•Į•ť•Ļ•Ņ ż] ? ? ?? [1][2]§őÕ∆∂®§ÚĹĽĽ•§ňĆg ©§∑°Ę◊ÓŖm§ •‚•«•ŽÕ∆∂®§Ú–– §¶§ő§¨ ?EM ?•Ę•Ž•ī•Í•ļ•ŗ£®ŠŠ Ų£© ? x1 ?: ?[A,B,C] ?= ?[0.8, ?0.1, ?0.1] ? x2 ?: ?[A,B,C] ?= ?[0.1, ?0.6, ?0.3] ? x3 ?: ?[A,B,C] ?= ?[0.3, ?0.3, ?0.4] [1]M•Ļ•∆•√•◊ [2]E•Ļ•∆•√•◊
- 9. °ĺSTEP2°Ņ10.4.2 ?ĻĚ?10.4.4 ?ĻĚ ī_¬ •‚•«•Ž§őÕ∆∂®°Ęī_¬ •‚•«•Ž§Ú”√§§§Ņ•Į•ť•Ļ•Ņ•Í•ů •į§ÚĆg ©§Ļ§Ž§Ņ§Š§őú āš°£ ? §Ĺ§ő§Ņ§Š§őłų∑N∂®Ńx§ň§ń§§§∆ņŪĹ‚§∑§ř§∑§Á§¶°£ ? ? °ĺńŅėň£°°Ņ ? ?? łų•«©`•Ņ§¨ňý ۧĻ§Ž•Į•ť•Ļ•Ņ§ő◊īĎB§ÚĪŪ¨F§Ļ§Ž§Ņ§Š §őŽL§žČš ż§ň§ń§§§∆ņŪĹ‚§Ļ§Ž ?? •‚•«•Ž•—•ť•Š©`•Ņ§ő◊Ó”»Õ∆∂®§ÚĆg ©§Ļ§Ž§Ņ§Š§ň?? ?? Õͻꕫ©`•Ņ§ő∂®Ńx§ň§ń§§§∆ņŪĹ‚§Ļ§Ž ? ?? ī_¬ •‚•«•Ž§ő”»∂»§ň§ń§§§∆ņŪĹ‚§Ļ§Ž ? ?? ī_¬ •‚•«•Ž§ő•—•ť•Š©`•Ņ§Ú◊Ó”»Õ∆∂®§Ļ§Ž§Ņ§Š§ő Q ?ťv ż§ň§ń §§§∆ņŪĹ‚§Ļ§Ž ?
- 10. ŽL§žČš ż ?? ĆgŽH§ň”Qúy§Ķ§ž§Ņ•«©`•Ņ§¨§…§ő•Į•ť•Ļ•Ņ§ň ۧĻ§Ž§ę ĪŪ¨F§Ļ§Ž§Ņ§Š§ő•Ŕ•Į•»•ŽČš ż ? ??z ?= ?(z1,z2,z3,???,zK) ? ?? K ?: ?•Į•ť•Ļ•Ņ ż ? ?? •«©`•Ņ§¨•Į•ť•Ļ•Ņk ?§ňňý ۧ∑§∆§§§Ž◊īĎB§őąŲļŌ ? ??z ?= ?(0,0,0,?,1,??,0) ? ?°ķ ?zk ?= ?1 ? k∑¨ńŅ ?? p(zk ?= ?1) ?= ?¶–k ? ?? •‚•«•ŽŐűľĢŌ¬§«°Ęk ?∑¨ńŅ§ő•Į•ť•Ļ•Ņ§ňňý ۧĻ§Žī_ ¬ §Ō§Ĺ§ő•Į•ť•Ļ•Ņ§őĽžļŌĪ»§ň“Ľ÷¬§Ļ§Ž§Ņ§Š°£(ĹŐŅ∆ ēݧň§Ō”õ›düo§∑°£@_kobacky ?§ň§Ť§ŽĹ‚Šč°£)
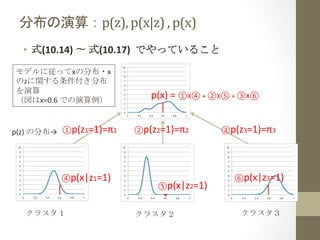
- 11. ∑÷≤ľ§ő—›ň„£ļp(z), ?p(x|z) ?, ?p(x) ?? Ĺ(10.14) ?? ? Ĺ(10.17) ? ?§«§š§√§∆§§§Ž§≥§» ? •‚•«•Ž§ňŹĺ§√§∆x§ő∑÷≤ľ?x §őz§ňťv§Ļ§ŽŐűľĢł∂§≠∑÷≤ľ §Ú—›ň„ ? £®áŪ§Ōx=0.6 ?§«§ő—›ň„ņż£© ? p(z) ?§ő∑÷≤ľ°ķ ? ĘŔp(z1=1)=¶–1 ? ? Ę‹p(x|z1=1) ? ? •Į•ť•Ļ•Ņ£Ī ? p(x) ?= ?ĘŔXĘ‹ ?+ ?ĘŕXĘ› ?+ ?ĘŘXĘř ? ? Ęŕp(z2=1)=¶–2 ? ? Ę›p(x|z2=1) ? ? •Į•ť•Ļ•Ņ£≤ ? ĘŘp(z3=1)=¶–3 ? ? Ęřp(x|z3=1) ? ? •Į•ť•Ļ•Ņ£≥ ?
- 12. ŽL§žČš ż§ő ¬ŠŠī_¬ £ļ¶√(zk) ?? Ĺ(10.18)§ő—›ň„£ļ¶√(z) ?= ?p(z) ?°Ń ?p(x ?| ?z) ?/ ?p(x) ? k=1 ?(•Į•ť•Ļ•Ņ1)§őąŲļŌ ? ¶√(z1) ?= ?ĘŔXĘ‹ ?/ ?ĘŖ ? ? p(z) ?§ő∑÷≤ľ°ķ ? ĘŔp(z1=1)=¶–1 ? ? Ę‹p(x|z1=1) ? ? •Į•ť•Ļ•Ņ£Ī ? ĘŖ ?p(x) ?= ?ĘŔXĘ‹ ?+ ?ĘŕXĘ› ?+ ?ĘŘXĘř ? ? Ęŕp(z2=1)=¶–2 ? ? Ę›p(x|z2=1) ? ? •Į•ť•Ļ•Ņ£≤ ? ĘŘp(z3=1)=¶–3 ? ? Ęřp(x|z3=1) ? ? •Į•ť•Ļ•Ņ£≥ ?
- 13. ŽL§žČš ż§ő ¬ŠŠī_¬ £ļ¶√(zk) ?? Ĺ(10.18)§ő—›ň„£ļ¶√(z) ?= ?p(z) ?°Ń ?p(x ?| ?z) ?/ ?p(x) ? k=2 ?(•Į•ť•Ļ•Ņ2)§őąŲļŌ ? ¶√(z2) ?= ?ĘŕXĘ› ?/ ?ĘŖ ? ? p(z) ?§ő∑÷≤ľ°ķ ? ĘŔp(z1=1)=¶–1 ? ? Ę‹p(x|z1=1) ? ? •Į•ť•Ļ•Ņ£Ī ? ĘŖ ?p(x) ?= ?ĘŔXĘ‹ ?+ ?ĘŕXĘ› ?+ ?ĘŘXĘř ? ? Ęŕp(z2=1)=¶–2 ? ? Ę›p(x|z2=1) ? ? •Į•ť•Ļ•Ņ£≤ ? ĘŘp(z3=1)=¶–3 ? ? Ęřp(x|z3=1) ? ? •Į•ť•Ļ•Ņ£≥ ?
- 14. ŽL§žČš ż§ő ¬ŠŠī_¬ £ļ¶√(zk) ?? Ĺ(10.18)§ő—›ň„£ļ¶√(z) ?= ?p(z) ?°Ń ?p(x ?| ?z) ?/ ?p(x) ? k=3 ?(•Į•ť•Ļ•Ņ3)§őąŲļŌ ? ¶√(z3) ?= ?ĘŘXĘř ?/ ?ĘŖ ? ? p(z) ?§ő∑÷≤ľ°ķ ? ĘŔp(z1=1)=¶–1 ? ? Ę‹p(x|z1=1) ? ? •Į•ť•Ļ•Ņ£Ī ? ĘŖ ?p(x) ?= ?ĘŔXĘ‹ ?+ ?ĘŕXĘ› ?+ ?ĘŘXĘř ? ? Ęŕp(z2=1)=¶–2 ? ? Ę›p(x|z2=1) ? ? •Į•ť•Ļ•Ņ£≤ ? ĘŘp(z3=1)=¶–3 ? ? Ęřp(x|z3=1) ? ? •Į•ť•Ļ•Ņ£≥ ?
- 15. ŽL§žČš ż§ňťvŖB§∑§∆Ņľ§®§Ņ§≥§» ?? •«©`•Ņx ?§őŽL§žČš żz ?(zk=1)§ňťv§Ļ§Ž ¬ŠŠī_¬ §Ō°Ę§≥ §ő•‚•«•Ž§ň§™§§§∆ ?x ?§¨ ?k∑¨ńŅ§ő•Į•ť•Ļ•Ņ§ňňý ۧĻ§Ž ī_¬ §Ú ĺ§∑§∆§§§Ž°£ ? ?? ?«įŪď§ř§«§őņż§ň§™§§§∆°Ę¶≤k=1,2,3(¶√(zk)) ?= ?1 ?§»§ §Ž§≥§» §¨§Ô§ę§Ž°£
- 16. Õͻꕫ©`•Ņ ?? •«©`•Ņ§őľĮļŌ£ļX ? ?? X ?= ?(x1,x2,???,xN) ? ? ?xi ?= ?(xi1,xi2,???,xid)§ő‹ě÷√•Ŕ•Į•»•Ž ? ?? ŽL§žČš ż§őľĮļŌ£ļZ ? ?? Z ?= ?(z1,z2,???,zN) ? ? ?zi ?= ?(zi1,zi2,???,ziK)§ő‹ě÷√•Ŕ•Į•»•Ž ? ?? Čš ż∂®Ńx ? ?? N ?: ?”Qúy•«©`•Ņ§őāÄ ż ? ?? d ?: ?”Qúy•«©`•Ņ§őīő‘™ ż ? ?? K ?: ?•Į•ť•Ļ•Ņ ż ? ?? Õͻꕫ©`•Ņ£ļY ? ?? Y ?= ?(X,Z) ? ?? •«©`•Ņ§»ŽL§žČš ż§ÚļŌ§Ô§Ľ§ŅľĮļŌ
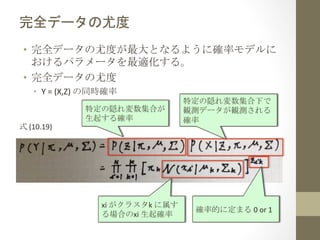
- 17. Õͻꕫ©`•Ņ§ő”»∂» ?? Õͻꕫ©`•Ņ§ő”»∂»§¨◊Óīů§»§ §Ž§Ť§¶§ňī_¬ •‚•«•Ž§ň §™§Ī§Ž•—•ť•Š©`•Ņ§Ú◊ÓŖmĽĮ§Ļ§Ž°£ ? ?? Õͻꕫ©`•Ņ§ő”»∂» ? ?? Y ?= ?(X,Z) ?§őÕ¨ērī_¬ ? Ĺ ?(10.19) ? Őō∂®§őŽL§žČš żľĮļŌ§¨ ? …ķ∆ū§Ļ§Žī_¬ xi ?§¨•Į•ť•Ļ•Ņk ?§ň ۧĻ §ŽąŲļŌ§őxi ?…ķ∆ūī_¬ Őō∂®§őŽL§žČš żľĮļŌŌ¬§« ”Qúy•«©`•Ņ§¨”Qúy§Ķ§ž§Ž ī_¬ ī_¬ Ķń§ň∂®§ř§Ž ?0 ?or ?1
- 18. Õͻꕫ©`•Ņ§őĆĚ ż”»∂» ?? ◊Ó”»Õ∆∂®āé§Ú«ů§Š§Ž§Ņ§Š§ňĆĚ ż”»∂»ťv ż§ňČšďQ ? ?? ī_¬ ∑÷≤ľťv ż§ŌĆĚ ż§Ú»°§√§Ņ∑ŧ¨őĘ∑÷§∑§š§Ļ§§£®◊Ó”»Õ∆∂® §ňťv§Ļ§Ž‘Ēľö§Ō ?4.3ĻĚ ≤ő’’£© ? z ?? §Ņ§ņ§∑ŽL§žČš ż ik ?§Ōī_¬ Ķń§ň∂®§ř§Ž§Ņ§Š°Ę§≥§őĆĚ ż”»∂» ťv ż§ę§ť÷ĪĹ”◊Ó”»Õ∆∂®āé§Ú«ů§Š§Ž§≥§»§Ō§«§≠§ §§°£ ? ?? ◊Ó”»Õ∆∂®£ļ”Qúy•«©`•Ņ§ę§ť°Ę◊Ó§‚”»§‚§ť§∑§§•‚•«•Ž§ő•—•ť •Š©`•Ņ§ÚÕ∆∂®§Ļ§Ž°£ ? Ĺ ?(10.20) ? £Ī§ę§‚§∑§ž§ §§§∑°Ę ? £į§ę§‚§∑§ž§ §§°£
- 19. Q ?ťv ż ?? Q ?ťv ż ? ?? ĆĚ ż”»∂»ťv ż§ő°ĘŽL§žČš ż§ňťv§Ļ§Ž∆ŕīżāé ? ?? ĆĚ ż”»∂»ťv ż§őīķ§Ô§Í§ň◊Ó”»Õ∆∂®§ň”√§§§Ž ? Ĺ ?(10.21) ? zik ?§ő zik ?§ňťv§Ļ§Ž ? ∆ŕīżāé Ĺ ?(10.22) ? Zik ?= ?0 ?§őŪó§Ō»ę§∆ ?0 ?§ň§ §Í°Ę zik= ?1 ?§őŪó§ő§Ŗ≤–§Ž ŽL§žČš ż zi ?§ő ¬ŠŠī_¬
- 20. Q ?ťv ż Ĺ ?(10.23) ? •‚•«•Ž§¨õQ∂®§Ļ§ž§– ā駨∂®§ř§Ž
- 21. °ĺSTEP3°Ņ10.4.5 ?ĻĚ?10.4.7 ?ĻĚ ī_¬ •‚•«•Ž§ő•—•ť•Š©`•ŅÕ∆∂®§ő∑Ĺ∑®§ň§ń§§§∆—ߧ”§ř§Ļ°£ ? ? °ĺńŅėň£°°Ņ ? ?? EM ?•Ę•Ž•ī•Í•ļ•ŗ§őŅľ§®∑ŧÚņŪĹ‚§Ļ§Ž ? ?? °łEM ?•Ę•Ž•ī•Í•ļ•ŗ§ő•—•ť•Š©`•ŅÕ∆∂®§¨ ?Q ?ťv ż§őőĘ ∑÷§Ú Ļ§√§∆§«§≠§Ž§ů§ņ§ §°??§ō§ß?°Ļ§»ňľ§¶ ? ?? •ę•Ž•–•√•Į?•ť•§•÷•ť©`«ťąůŃŅ§»§Ōļő§ę§Ú÷™§Ž ? ?? EM ?•Ę•Ž•ī•Í•ļ•ŗ§ň§Ť§Í°Ę•‚•«•Ž§ň§Ť§Ž∑÷≤ľ§»’ś§ő ∑÷≤ľ§¨ĹŁ§Ň§§§∆––§Į•§•Š©`•ł§Ú≥÷§ń ?
- 22. EM ?•Ę•Ž•ī•Í•ļ•ŗ ?? ī_¬ •‚•«•Ž§ő•—•ť•Š©`•Ņ§ő◊Ó”»Õ∆∂®āé§Ú«ů§Š§Ž ÷∑® ? ?? £≤∑NÓź§ő•Ļ•∆•√•◊§ÚĹĽĽ•§ňĆg © ? 1.? Expectafon ?•Ļ•∆•√•◊£®ĘŘ£© ? ?? ī_¬ •‚•«•Ž§ő•—•ť•Š©`•Ņ§ÚĻŐ∂® ? ?? ĻŐ∂®§Ķ§ž§Ņī_¬ •‚•«•ŽŌ¬§ň§™§Ī§ŽŽL§žČš ż§ő ¬ŠŠī_¬ §Ú—›ň„ ? 2.? Maximizafon ?•Ļ•∆•√•◊£®ĘŔĘŕ£© ? ?? E ?•Ļ•∆•√•◊§«Ķ√§ŅŽL§žČš ż§ő ¬ŠŠī_¬ §Ú ?Q ?ťv ż§ňīķ»Ž ? ?? Q ?ťv ż§Ú◊Óīů§ň§Ļ§Ž ?(ī_¬ •‚•«•Ž§ő)•—•ť•Š©`•Ņ§Ú«ů§Š§Ž ? ?? Q ?ťv ż§őĆĚ ż”»∂»§¨Öß Ý§Ļ§Ž§ř§«ņR§Í∑Ķ§Ļ ? ?? ĺ÷ňýĹ‚§ň§Ō◊Ę“‚°£≥ű∆ŕāé§ÚČš§®§∆ļő∂»§ęĆg ©§Ļ§Ž§»Ńľ§§°£ ¶√11 ?= ?0.3, ?¶√12 ?= ?0.4, ?¶√13 ?= ?0.3 ? ¶√21 ?= ?0.6, ?¶√22 ?= ?0.1, ?¶√23 ?= ?0.3 ? ¶√31 ?= ?0.2, ?¶√32 ?= ?0.7, ?¶√33 ?= ?0.1 ? ĘŔīķ»Ž ĘŘ—›ň„ Ęŕ•—•ť•Š©`•Ņ ◊Ó”»āéÕ∆∂® Qťv ż§¨ ? Öß Ý§∑§Ņ§ť ÕÍ
- 23. EM ?•Ę•Ž•ī•Í•ļ•ŗ§ő Ĺ ?? E ?•Ļ•∆•√•◊ ? ?? M ?•Ļ•∆•√•◊ ? k∑¨ńŅ§ő•Į•ť•Ļ•Ņ §ň ۧĻ§Ž•«©`•Ņ ż §őÕ∆∂®āé ∆Ĺĺý?∑÷…Ę?ĽžļŌĪ» §ő∂®Ńx§ňḈ∑§∆ľ{Ķ√ ł–§ő§Ę§Ž ŧň§ §√§∆ §§§Ž§»ňľ§¶°£
- 24. EM ?•Ę•Ž•ī•Í•ļ•ŗ§ő ŧőĆß≥Ų ???§Ō°ĘłÓźŘ§∑§ř§Ļ°£ ? ö›§ň§ §Ž∑ŧŌ ?10.4.6 ?Ļ̧ڧī≤ő’’Ō¬§Ķ§§°£ ?m(_ ?_)m ? ?? ¶Ők ?§š ¶≤k ?§őÕ∆∂®§Ō°Ę ?Q ?ťv ż§ő(Õ∆∂®ĆĚŌů•—•ť•Š©`•Ņ§ň §Ť§Ž)∆ęőĘ∑÷ ?= ?0 ?§»§ §Ž§Ť§¶§ •—•ť•Š©`•Ņ§Ú«ů§Š§Ž§≥ §»§«––§¶°£ ? ?? ¶–k ?§őÕ∆∂®§Ō•ť•į•ť•ů•ł•Śťv ż§»§ę Ļ§√§∆§ §ů§ę§š§√ §∆§ř§Ļ°£°£ ?
- 25. EM ?•Ę•Ž•ī•Í•ļ•ŗ§ő–‘Ŕ|(1) ?? p(X|¶») ?= ?p(X,Z) ?/ ?p(Z|X, ?¶») ? ? ?? ?? ?? ?? X ?£ļ ”Qúy•«©`•ŅľĮļŌ ? Z ?£ļ ”Qúy•«©`•ŅľĮļŌX ?§ňḈĻ§ŽŽL§žČš żľĮļŌ ? ¶» ?£ļ ī_¬ •‚•«•Ž§ő•—•ť•Š©`•ŅľĮļŌ ? p(X ?| ?¶»)£ļ•—•ť•Š©`•Ņ¶»§őī_¬ •‚•«•ŽŌ¬§ň§™§Ī§Ž”Qúy•«©`•ŅX §ő”»∂» ? ?? ĆĚ ż”»∂» ?= ?lnp(X|¶») ?= ???? ?= ?L(q|¶») ?+ ?KL(q||p) ? ?? q(Z) ?£ļ ?Z ?§ňťv§Ļ§Ž»ő“‚§ő∑÷≤ľ ? ?? L(q|¶») ?= ?¶≤Zq(Z)ln(p(X,Z|¶») ?/ ?q(Z)) ? ?? KL(q||p) ?= ?¶≤Zq(Z)ln(q(Z) ?/ ?p(Z|X,¶»)) ? ?? •ę•Ž•–•√•Į?•ť•§•÷•ť©`«ťąůŃŅ ? ?? ’ś§ő∑÷≤ľq(Z) ?§» ?(ī_¬ •‚•«•Ž?”Qúy•«©`•Ņ§Ú‘™§ňĶ√§ť§ž§Ž) ¬ŠŠ ∑÷≤ľp(Z|X,¶») ?§őī_¬ Čš żťg§őĺŗŽx£®’ż§őā飩§ÚĪŪ§Ļ ?
- 26. EM ?•Ę•Ž•ī•Í•ļ•ŗ§ő–‘Ŕ|(2) ?? L(q|¶») ?§Ú◊ÓīůĽĮ§Ļ§Ž§≥§»§«°ĘKL(q||p) ?§Ú–°§Ķ§Į§Ļ§Ž°Ę §ń§ř§Í°Ęp(•‚•«•Ž§ň§Ť§ŽŽL§žČš ż§ő∑÷≤ľ)§Úq(’ś§ő∑÷ ≤ľ)§ňĹŁ§Ň§Ī§Ž°£ ? ?? E ?•Ļ•∆•√•◊§«§Ō¶»§ÚĻŐ∂®§∑§∆ ?q ?§ňťv§∑§∆ L(q|¶») ?§Ú◊ÓīůĽĮ ? ?? M ?•Ļ•∆•√•◊§«§Ō◊ÓīůĽĮ§Ķ§ž§Ņq§Ú”√§§§∆¶»§ňťv§∑§∆L(q|¶»)§Ú◊Ó īůĽĮ°£ ? ?? •‚•«•Ž§ň§Ť§ŽŽL§žČš ż§ő∑÷≤ľ§¨’ś§ő∑÷≤ľ§ňĹŁ§Ň§Į°£ ? E•Ļ•∆•√•◊§«§ŌL ?§Ú◊ÓīůĽĮ§Ļ §Ž§≥§»§«§≥§ő•ť•§•ů§Ú…Ō§ň —ļ§∑…Ō§≤§Ņ§§£° ? ?? •Ļ•∆•√•◊öį§ňQťv ż§őā駨īů§≠§Į§ §Ž§≥§»§¨ ĺ§Ķ§ž§∆§§§Ž°£ ?