




























![相澤?山崎研究室勉強会
知識の流れ
Hubel and Wiesel [1962]
(単純細胞,複雑細胞,局所受容野)
!
!
Fukushima [1980]
(Neocognitron)
!
!
LeCun [1989, 1998]
(Convolutional Neural Network→手書き文字認識への応用)
40
1. Introduction to Convolutional Neural Network](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-40-320.jpg)

![相澤?山崎研究室勉強会
全体構造
? 基本的にはこの2層を繰り返すことで成り立つ.
? 最終層は出力層として,ソフトマックス関数を置くことが多い(分類
問題の場合)
? そこにいたるいくつかの層はフル接続とすることが多い.
44
1. Introduction to Convolutional Neural Network
LeNet-5 [LeCun, 1998]](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-44-320.jpg)


![相澤?山崎研究室勉強会
全体構造(再掲)
? 基本的にはこの2層を繰り返すことで成り立つ.
? 最終層は出力層として,ソフトマックス関数を置くことが多い(分類
問題の場合)
? そこにいたるいくつかの層はフル接続とすることが多い.
47
1. Introduction to Convolutional Neural Network
LeNet-5 [LeCun, 1998]](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-47-320.jpg)
![相澤?山崎研究室勉強会
Convolutionは先ほど説明したとおりだが…
!
☆いくつカーネル(フィルタ)を用意する?
☆カーネルのサイズは?
☆「端っこ」の扱いは?
☆活性化関数は?
☆重みやバイアスの決定は?
☆フィルタの動かし方は?
Convolution
48
2. The Detail of Conventional CNN Techniques
[conv]
type=conv
inputs=data
channels=3
filters=32
padding=4
stride=1
filterSize=9
neuron=logistic
initW=0.00001
initB=0.5](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-48-320.jpg)
![相澤?山崎研究室勉強会
? 直感的にはある程度の領域を「まとめる」ことで位置情報を捨て,
変化に対してロバストにする作業のこと.
? 広義では,抽出した生の特徴表現を,認識に必要な部分だけ残す
ような新たな表現に変換すること.
!
!
? 無意識に多く使われている
? 「最大値をとる」「平均をとる」「(語弊あるが)まとめる」
? 要素技術しかり,アルゴリズム全体然り
? ex) ??????????????????????
SIFT[Lowe 99], Bag of Features[], Spatial Pyramid[],
Object Bank[2010],
Pooling
49
2. The Detail of Conventional CNN Techniques](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-49-320.jpg)
![相澤?山崎研究室勉強会
Pooling
50
2. The Detail of Conventional CNN Techniques
? Max pooling
!
!
!
? Avg. pooling (平均プーリング)
!
!
!
? (一般の) Pooling
hi,k+1 = max
j2Pi,k
hj
hi,k+1 =
1
|Pi|
X
j2Pi
hj
hi,k+1 =
?
1
|Pi|
X
j2Pi
hp
j
◆1
p
p=1 avg
p= max
※実際にはavg~maxのつなぎ方は他にもあり,詳細は[Boureau, ICML 2010]を参照](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-50-320.jpg)
![相澤?山崎研究室勉強会
Pooling
51
2. The Detail of Conventional CNN Techniques
? 結局どれがいいのか
? [Boureau, CVPR 2010及びICML 2010]に詳しい議論
? Cardinality(プーリングサイズ)による
? 直感的には??
? 元画像に対し,広い部分を扱うときは平均プーリング,小さい部分
の時はmaxの方が良い?](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-51-320.jpg)
![相澤?山崎研究室勉強会
☆プーリング開始画素は?
☆プーリングサイズは?(Overlap)
☆動かす幅は?(Overlap)
☆活性化関数は?
☆プーリングの種類は?
Pooling
52
2. The Detail of Conventional CNN Techniques
[pool]
type=pool
pool=max
inputs=local32
start=0
sizeX=4
stride=2
outputsX=0
channels=32
neuron=relu](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-52-320.jpg)

![相澤?山崎研究室勉強会
局所コントラスト正規化
54
2. The Detail of Conventional CNN Techniques
? 減算正規化
!
!
!
!
? 除算正規化
?hi,j,k = hj,k
X
i,p,q
wp,qhi,j+p,k+q
h : 前層の出力
j, k : 画素
i : フィルタ番号
w : 平均を調整するための重み
c : 定数
h0
i,j,k =
?hi,j,k
q
c +
P
i,p,q wp,q
?h2
i,j+p,k+q
文献によっては,減算をしていないもの [Krizhevsky 2012]もある
また,いくつかのフィルタにまたがる場合(across map)とまたがらない場合がある](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-54-320.jpg)
![相澤?山崎研究室勉強会
局所コントラスト正規化
55
2. The Detail of Conventional CNN Techniques
? 具体的な効果は?:
? improves invariance
? improves optimization
? increase sparsity [以上,Ranzato, CVPR 2013 Tutorial]](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-55-320.jpg)

![相澤?山崎研究室勉強会
なぜ学習がうまくいくのか?
? Bengio「Although deep supervised neural networks were generally found
too di?cult to train before the use of unsupervised pre-training, there is one
notable exception: convolutional neural networks.」[Bengio, 2009]
!
? 一般に多層のNNは過学習を起こす
? なぜCNNはOK?
!
? One untested hypothesis by Bengio
? 入力数(fan-in)が少ないと誤差なく勾配伝搬する?
? 局所的に接続された階層構造は認識タスクに向いている?
? FULL < Random CNN < Supervised CNN
57
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-57-320.jpg)
![相澤?山崎研究室勉強会
DropOut
? DropOut [Hinton et al., 2012]
? 学習時に,中間層の出力の50%をrandomに0にする
? 一時的に依存関係を大幅に減らすことで,強い正則化の効果があ
る
? 一般化→DropConnect [Wan et al., 2013]
? 50% -> (1-p)%
? Sparseな接続の重み行列に
58
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-58-320.jpg)


![相澤?山崎研究室勉強会
Convolutionは先ほど説明したとおりだが…
!
☆いくつカーネル(フィルタ)を用意する?
☆カーネルのサイズは?
☆「端っこ」の扱いは?
☆活性化関数は?
☆重みやバイアスの決定は?
Convolution(再掲)
61
[conv]
type=conv
inputs=data
channels=3
filters=32
padding=4
stride=1
filterSize=9
neuron=logistic
initW=0.00001
initB=0.5
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-61-320.jpg)
![相澤?山崎研究室勉強会
☆プーリング開始画素は?
☆プーリングサイズは?(Overlap)
☆動かす幅は?(Overlap)
☆活性化関数は?
☆プーリングの種類は?
Pooling(再掲)
62
[pool]
type=pool
pool=max
inputs=local32
start=0
sizeX=4
stride=2
outputsX=0
channels=32
neuron=relu
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-62-320.jpg)
![相澤?山崎研究室勉強会
いわゆるハイパパラメータ
? いくつかの決定手法は提案されてはいる
? ランダムサーチのほうが性能がいい?[Bergstra, 2012]
? 基本的には層は多くあるべき? [Bengio, 2013]
? http://www.slideshare.net/koji_matsuda/practical-
recommendation-fordeeplearning
!
!
? しかし基本的に問題依存とされる
? 経験則しか頼りづらいBlack-box tool
63
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-63-320.jpg)



![相澤?山崎研究室勉強会
後半の参考資料(updated)
? 論文
? Krizhevsky et al., ImageNet Classi?cation with Deep Convolutional Neural Networks, NIPS, 2012
? LeCun et al., Gradient-Based Learning Applied to Document Recognition, Proc. of IEEE, 1998
? [20][21][22]
!
? 日本語スライド
? http://www.slideshare.net/koji_matsuda/practical-recommendation-fordeeplearning
? http://www.slideshare.net/kazoo04/deep-learning-15097274
? http://www.slideshare.net/yurieoka37/ss-28152060 (実装に詳しい)
? http://www.slideshare.net/mokemokechicken/pythondeep-learning (実際にアプリケーション
を作成した例)
!
? 海外チュートリアル
? CVPR 2013のTutorialはCNNに焦点があたっている(GoogleのRanzato氏)
? ICML 2013, CVPR 2012等も参考になる
68](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-68-320.jpg)

2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで
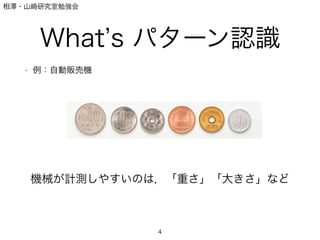
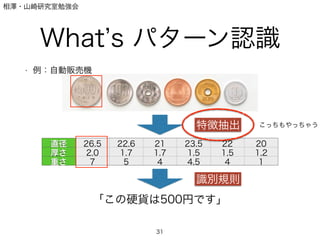
- 2. 相澤?山崎研究室勉強会 What s パターン認識 ? 例:自動販売機 2 Q. どうやって機械は硬貨を判別しているか
- 3. 相澤?山崎研究室勉強会 What s パターン認識 ? 例:自動販売機 3 人間はどうやって判別する? →色,大きさ,穴
- 4. 相澤?山崎研究室勉強会 What s パターン認識 ? 例:自動販売機 4 機械が計測しやすいのは,「重さ」「大きさ」など
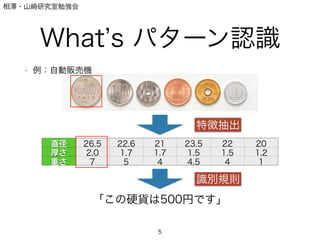
- 5. 相澤?山崎研究室勉強会 What s パターン認識 ? 例:自動販売機 5 直径 26.5 22.6 21 23.5 22 20 厚さ 2.0 1.7 1.7 1.5 1,5 1,2 重さ 7 5 4 4.5 4 1 「この硬貨は500円です」 特徴抽出 識別規則
- 6. 相澤?山崎研究室勉強会 パターン認識 ? 大きく分けて「特徴抽出」ステージと「識別」ステージがある ? 機械学習はふつう「識別」を対象にする ! ? 1.特徴抽出 ? SIFT+BoF, HoG, Haar-like, RGB hist, SPM, Attribute.. ? 2.識別規則 ? SVMだの決定木だのNNだのランダムフォレストだの ? ノーフリーランチ定理 ! ! ? よい識別を行うには,入力(学習用)データとクラスの対応付けを 「学習」させなければならない 6
- 7. 相澤?山崎研究室勉強会 識別規則の種類 ? 識別関数:入力を関数に入れてその関数値で分類する ? SVM,?ニューラルネットワークetc ! ! ! ! ? 識別モデル:入力データからクラス事後確率をモデル化して識別 →CRF系 ? 生成モデル:どのような分布で入力が生成されたかをモデル化して識 別→ベイズ系 7 ???
- 8. 相澤?山崎研究室勉強会 識別規則の種類 ? 識別関数:入力を関数に入れてその関数値で分類する ? SVM,?ニューラルネットワークetc ! ! ! ! ? 識別モデル:入力データからクラス事後確率をモデル化して識別 →CRF系 ? 生成モデル:どのような分布で入力が生成されたかをモデル化して識 別→ベイズ系 8 一番簡単
- 9. 相澤?山崎研究室勉強会 識別規則の種類 ? 識別関数:入力を関数に入れてその関数値で分類する ? SVM,?ニューラルネットワークetc ! ! ! ! ? 識別モデル:入力データからクラス事後確率をモデル化して識別 →CRF系 ? 生成モデル:どのような分布で入力が生成されたかをモデル化して識 別→ベイズ系 9
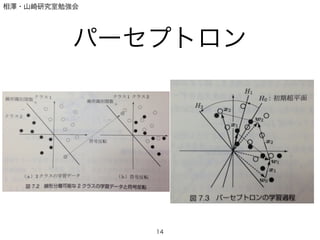
- 10. 相澤?山崎研究室勉強会 パーセプトロン ? 簡単な線形識別2クラス問題を考える ! ! ! ! ! ? xはd次元ベクトルとする 10 f(x) = wT x if f(x) > 0, x 2 C1 else x 2 C2
- 11. 相澤?山崎研究室勉強会 パーセプトロン ? これを図式化すると,図のようになる(3次元) 11 y = w1x1 + w2x2 + w3x3 = 3X i=1 wixi = wT x where w = {w1, w2, w3}, x = {x1, x2, x3}
- 13. 相澤?山崎研究室勉強会 パーセプトロン ? アルゴリズムは以下の通り ! ! ! ! ? μは学習率(0 < μ 1) ? どんくらい変えるのか ! ? あるデータ点x_iのクラスと出力に応じて重みベクトルを更新. ? 幾何的な説明が可能 13 wi+1 = wi + ?xi (f(x) > 0) wi+1 = wi (else)
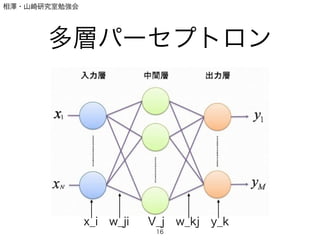
- 15. 相澤?山崎研究室勉強会 多層パーセプトロン ? パーセプトロンの限界 ? 線形分離不可能な場合(cf. XOR) ? X, Y, XとYの外積の3軸があれば平面分離可能 ! ? 線形分離関数の多層化→多層パーセプトロン 15
- 16. 相澤?山崎研究室勉強会 多層パーセプトロン 16 x_i w_ji V_j w_kj y_k
- 17. 相澤?山崎研究室勉強会 多層パーセプトロン ? V_jへの入力は.. ! ! ! ? V_jの出力は.. ! ! ! ! 17 V n j,in = dX i=0 wjixn i = wT j xn V n j,out = g(wT j xn ) g(u) = 1 1 + exp( u) (for example)
- 18. 相澤?山崎研究室勉強会 多層パーセプトロン ! ! ! ! ! ? g(u)をのぞいて単層の場合と一緒..なぜ非線形出力関数を使うの か? ? 1. 後述の誤差逆伝播法(勾配法)では微分できなければいけない から ? 2. 隠れ素子の出力関数が線形であれば,多層回路を構成しても等 価的に1層の回路で近似可能になってしまう 18 V n j,out = g(wT j xn ) g(u) = 1 1 + exp( u) (for example)
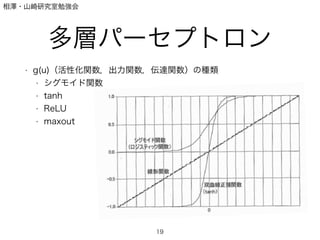
- 19. 相澤?山崎研究室勉強会 多層パーセプトロン ? g(u)(活性化関数,出力関数,伝達関数)の種類 ? シグモイド関数 ? tanh ? ReLU ? maxout ! 19
- 20. 相澤?山崎研究室勉強会 多層パーセプトロン ? y_iの入力は ! ! ! ? 出力(=結果)は ! ! ! ! ? g (u)は(非)線形関数,多クラス分類の時はソフトマックスを用い たりする ! 20 yn k,in = wT kjV n yn k,out = ?g(wT kjV n ) ?g(u) = act. func.
- 21. 相澤?山崎研究室勉強会 多層パーセプトロン ? んで,どうやってwを求めるのかという話. ? ここで出てくるのがかの有名な ! Back propagation(誤差逆伝播法,誤差逆伝搬法) 21
- 22. 相澤?山崎研究室勉強会 Back propagation ? Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが 多い) 22 E(w) = 1 2 N n=1 K k=1 (tn k yn k )2 tn k は教師信号,yn k は MLP の出力. それを出力ユニット分足しあわせたものを,全データ分足す wkj( + 1) = wkj( ) + wkj( ) 一般にこの修正を何度も繰り返すので, はイテレーション回数を示す.
- 23. 相澤?山崎研究室勉強会 Back propagation ? Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが 多い) 23 wkj( ) = N n=1 En(w) wkj = N n=1 En(w) yn k yn k wkj = N n=1 (tn k yn k )?g (yn k,in)V n j,out where En(w) = 1 2 K k=1 (tn k yn k )2
- 24. 相澤?山崎研究室勉強会 Back propagation ? Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが 多い) 24 ここで, n k = (tn k yn k )?g (yn k,in) とおくと N n=1 (tn k yn k )?g (yn k,in)V n j,out = N n=1 n k V n j,out ※これで出力層終わり
- 25. 相澤?山崎研究室勉強会 Back propagation ? Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが 多い) 25 出力層の誤差が出力層と隠れ層の間の重みを通じて隠れ層に伝搬
- 26. 相澤?山崎研究室勉強会 Back propagation ? 今までのがバッチ学習,最急降下法と呼ばれる方法 ! ? 1データごとに更新する場合(オンライン学習)や,小さいバッチで 行う場合(ミニバッチ学習)などもある. 26
- 27. 相澤?山崎研究室勉強会 Back propagation ? Case 2, 交差エントロピーを用いる場合(分類問題にはこちらが使わ れることが多い) ! ! ! ! ! ? 力尽きた. 27
- 28. 相澤?山崎研究室勉強会 MLP w/ BP+GDの問題 ? 1. 初期値依存性 ? 局所最適解が大量に含まれる誤差関数を最適化するので,初期値 によって り着く局所解が違う ! ? 2. 過学習 ? 隠れ素子の数が多くなったり,活性化関数がサチったりでノイズ に適合し始めると,過学習が起こる ? 対策として,early stoppingやL2正則化などが行われているが, 一番効くのはデータ数を増やすこと 28
- 29. 相澤?山崎研究室勉強会 NN冬の時代 ! ? ある時期,NIPS(機械学習系のトップカンファレンス)に投稿され る論文の採択率と,タイトルにニューラルネットワークが入っていた 場合と負の相関があった(SVMは正の相関) ! ? 過学習に対応できず,う~んといったかんじ 29 Deep Learning の登場
- 30. 相澤?山崎研究室勉強会 Deep Learning 30 CVPR2013 罢耻迟辞谤颈补濒より
- 31. 相澤?山崎研究室勉強会 What s パターン認識 ? 例:自動販売機 31 直径 26.5 22.6 21 23.5 22 20 厚さ 2.0 1.7 1.7 1.5 1,5 1,2 重さ 7 5 4 4.5 4 1 「この硬貨は500円です」 特徴抽出 識別規則 こっちもやっちゃう
- 32. 相澤?山崎研究室勉強会 Deep Learning ? Full-Connected + Pre-traning系 ? ネットで探してDeep Learningって言われがちなのはこっち ? フル接続の多層NNは誤差が分散してしまって性能が上がらなかっ たが,事前学習を取り入れることでそれを回避 ? Deep Belief NetsやStacked Denoising Autoencodersなどが 知られている ! ? CNN系 ? 事前学習なし,局所受容野の考え方を取り入れることで過学習の 回避 ? 画像に向いている(らしい) 32
- 33. Today I ll talk about CNN
- 34. 相澤?山崎研究室勉強会 アウトライン 1. Introduction to Convolutional Neural Network 2. The Detail of Conventional CNN Techniques 3. Other Topic 4. Implementation 34
- 35. 相澤?山崎研究室勉強会 アウトライン 1. Introduction to Convolutional Neural Network 2. The Detail of Conventional CNN Techniques 3. Other Topic 4. Implementation 35
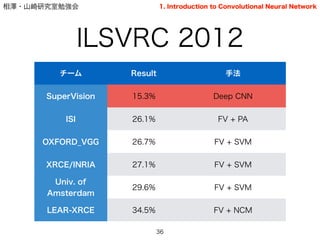
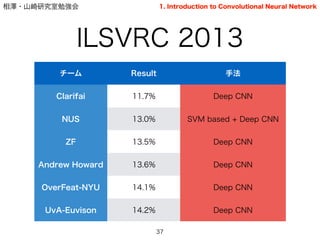
- 36. 相澤?山崎研究室勉強会 ILSVRC 2012 36 チーム Result 手法 SuperVision 15.3% Deep CNN ISI 26.1% FV + PA OXFORD_VGG 26.7% FV + SVM XRCE/INRIA 27.1% FV + SVM Univ. of Amsterdam 29.6% FV + SVM LEAR-XRCE 34.5% FV + NCM 1. Introduction to Convolutional Neural Network
- 37. 相澤?山崎研究室勉強会 ILSVRC 2013 37 チーム Result 手法 Clarifai 11.7% Deep CNN NUS 13.0% SVM based + Deep CNN ZF 13.5% Deep CNN Andrew Howard 13.6% Deep CNN OverFeat-NYU 14.1% Deep CNN UvA-Euvison 14.2% Deep CNN 1. Introduction to Convolutional Neural Network
- 38. 相澤?山崎研究室勉強会 Other dataset.. 38 1. Introduction to Convolutional Neural Network
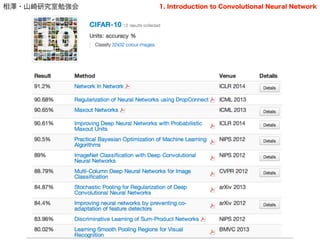
- 39. 相澤?山崎研究室勉強会 Other dataset.. ? CIFAR-10 ? CIFAR-100 ? Network in Network , ICLR 2014 ! ? MNIST ? Regularization of Neural Networks using DropConnect , ICML, 2013 39 全てCNN (が基にある) 1. Introduction to Convolutional Neural Network
- 40. 相澤?山崎研究室勉強会 知識の流れ Hubel and Wiesel [1962] (単純細胞,複雑細胞,局所受容野) ! ! Fukushima [1980] (Neocognitron) ! ! LeCun [1989, 1998] (Convolutional Neural Network→手書き文字認識への応用) 40 1. Introduction to Convolutional Neural Network
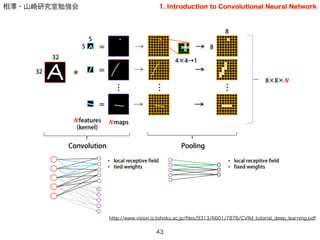
- 41. 相澤?山崎研究室勉強会 基本構造 41 2 3 5 6 7 4 1 7 3 Convolution(畳み込み) 2 3 5 6 7 4 1 7 3 2 3 5 6 7 4 1 7 3 Pooling(プーリング,適切な日本語訳なし?) ※画像はイメージです 2 3 5 6 7 4 1 7 3 1. Introduction to Convolutional Neural Network ※画像はイメージです いわゆる移動フィルタの形で,画像を移動しながら注目画素の周 辺の画素値を用いて計算.このフィルタをたくさん用意する (フィルタ=重み行列が局所的)
- 42. 相澤?山崎研究室勉強会 42 1. Introduction to Convolutional Neural Network
- 43. 相澤?山崎研究室勉強会 43 http://www.vision.is.tohoku.ac.jp/?les/9313/6601/7876/CVIM_tutorial_deep_learning.pdf 1. Introduction to Convolutional Neural Network
- 44. 相澤?山崎研究室勉強会 全体構造 ? 基本的にはこの2層を繰り返すことで成り立つ. ? 最終層は出力層として,ソフトマックス関数を置くことが多い(分類 問題の場合) ? そこにいたるいくつかの層はフル接続とすることが多い. 44 1. Introduction to Convolutional Neural Network LeNet-5 [LeCun, 1998]
- 45. 相澤?山崎研究室勉強会 学習 Stochastic Gradient Descend (SGD, Batch training) ! + ! Back Propagation (誤差逆伝搬法) 45 1. Introduction to Convolutional Neural Network
- 46. 相澤?山崎研究室勉強会 アウトライン 1. Introduction to Convolutional Neural Network 2. The Detail of Conventional CNN Techniques 3. Other Topic 4. Implementation 46
- 47. 相澤?山崎研究室勉強会 全体構造(再掲) ? 基本的にはこの2層を繰り返すことで成り立つ. ? 最終層は出力層として,ソフトマックス関数を置くことが多い(分類 問題の場合) ? そこにいたるいくつかの層はフル接続とすることが多い. 47 1. Introduction to Convolutional Neural Network LeNet-5 [LeCun, 1998]
- 48. 相澤?山崎研究室勉強会 Convolutionは先ほど説明したとおりだが… ! ☆いくつカーネル(フィルタ)を用意する? ☆カーネルのサイズは? ☆「端っこ」の扱いは? ☆活性化関数は? ☆重みやバイアスの決定は? ☆フィルタの動かし方は? Convolution 48 2. The Detail of Conventional CNN Techniques [conv] type=conv inputs=data channels=3 filters=32 padding=4 stride=1 filterSize=9 neuron=logistic initW=0.00001 initB=0.5
- 49. 相澤?山崎研究室勉強会 ? 直感的にはある程度の領域を「まとめる」ことで位置情報を捨て, 変化に対してロバストにする作業のこと. ? 広義では,抽出した生の特徴表現を,認識に必要な部分だけ残す ような新たな表現に変換すること. ! ! ? 無意識に多く使われている ? 「最大値をとる」「平均をとる」「(語弊あるが)まとめる」 ? 要素技術しかり,アルゴリズム全体然り ? ex) ?????????????????????? SIFT[Lowe 99], Bag of Features[], Spatial Pyramid[], Object Bank[2010], Pooling 49 2. The Detail of Conventional CNN Techniques
- 50. 相澤?山崎研究室勉強会 Pooling 50 2. The Detail of Conventional CNN Techniques ? Max pooling ! ! ! ? Avg. pooling (平均プーリング) ! ! ! ? (一般の) Pooling hi,k+1 = max j2Pi,k hj hi,k+1 = 1 |Pi| X j2Pi hj hi,k+1 = ? 1 |Pi| X j2Pi hp j ◆1 p p=1 avg p= max ※実際にはavg~maxのつなぎ方は他にもあり,詳細は[Boureau, ICML 2010]を参照
- 51. 相澤?山崎研究室勉強会 Pooling 51 2. The Detail of Conventional CNN Techniques ? 結局どれがいいのか ? [Boureau, CVPR 2010及びICML 2010]に詳しい議論 ? Cardinality(プーリングサイズ)による ? 直感的には?? ? 元画像に対し,広い部分を扱うときは平均プーリング,小さい部分 の時はmaxの方が良い?
- 52. 相澤?山崎研究室勉強会 ☆プーリング開始画素は? ☆プーリングサイズは?(Overlap) ☆動かす幅は?(Overlap) ☆活性化関数は? ☆プーリングの種類は? Pooling 52 2. The Detail of Conventional CNN Techniques [pool] type=pool pool=max inputs=local32 start=0 sizeX=4 stride=2 outputsX=0 channels=32 neuron=relu
- 53. 相澤?山崎研究室勉強会 局所コントラスト正規化 53 2. The Detail of Conventional CNN Techniques ? 発端は?:計算神経科学(哺乳類の初期視覚野のモデル) ? 脳のニュートンによる情報伝達はパルス数によって制限(有限) ? どうやってやる?:減算初期化と除算初期化 ? どちらかというと除算が重要か(?) ! ? 意味は?: ? ①上記の脳の初期視覚野のモデルを表現 ? ②複雑視覚野におけるニュ―ロンの選択性がコントラストに非 依存であることの説明
- 54. 相澤?山崎研究室勉強会 局所コントラスト正規化 54 2. The Detail of Conventional CNN Techniques ? 減算正規化 ! ! ! ! ? 除算正規化 ?hi,j,k = hj,k X i,p,q wp,qhi,j+p,k+q h : 前層の出力 j, k : 画素 i : フィルタ番号 w : 平均を調整するための重み c : 定数 h0 i,j,k = ?hi,j,k q c + P i,p,q wp,q ?h2 i,j+p,k+q 文献によっては,減算をしていないもの [Krizhevsky 2012]もある また,いくつかのフィルタにまたがる場合(across map)とまたがらない場合がある
- 55. 相澤?山崎研究室勉強会 局所コントラスト正規化 55 2. The Detail of Conventional CNN Techniques ? 具体的な効果は?: ? improves invariance ? improves optimization ? increase sparsity [以上,Ranzato, CVPR 2013 Tutorial]
- 56. 相澤?山崎研究室勉強会 アウトライン 1. Introduction to Convolutional Neural Network 2. The Detail of Conventional CNN Techniques 3. Other Topic 4. Implementation 56
- 57. 相澤?山崎研究室勉強会 なぜ学習がうまくいくのか? ? Bengio「Although deep supervised neural networks were generally found too di?cult to train before the use of unsupervised pre-training, there is one notable exception: convolutional neural networks.」[Bengio, 2009] ! ? 一般に多層のNNは過学習を起こす ? なぜCNNはOK? ! ? One untested hypothesis by Bengio ? 入力数(fan-in)が少ないと誤差なく勾配伝搬する? ? 局所的に接続された階層構造は認識タスクに向いている? ? FULL < Random CNN < Supervised CNN 57 3. Other Topic
- 58. 相澤?山崎研究室勉強会 DropOut ? DropOut [Hinton et al., 2012] ? 学習時に,中間層の出力の50%をrandomに0にする ? 一時的に依存関係を大幅に減らすことで,強い正則化の効果があ る ? 一般化→DropConnect [Wan et al., 2013] ? 50% -> (1-p)% ? Sparseな接続の重み行列に 58 3. Other Topic
- 60. 相澤?山崎研究室勉強会 CNNの問題点 60 http://www.slideshare.net/yurieoka37/ss-28152060 3. Other Topic ←最初に決めるが,一番難しい…
- 63. 相澤?山崎研究室勉強会 いわゆるハイパパラメータ ? いくつかの決定手法は提案されてはいる ? ランダムサーチのほうが性能がいい?[Bergstra, 2012] ? 基本的には層は多くあるべき? [Bengio, 2013] ? http://www.slideshare.net/koji_matsuda/practical- recommendation-fordeeplearning ! ! ? しかし基本的に問題依存とされる ? 経験則しか頼りづらいBlack-box tool 63 3. Other Topic
- 64. 相澤?山崎研究室勉強会 アウトライン 1. Introduction to Convolutional Neural Network 2. The Detail of Conventional CNN Techniques 3. Other Topic 4. Implementation 64
- 65. 相澤?山崎研究室勉強会 cuda-convnet ? LSVRC2012優勝のSupervisionのコード ? GPU利用が前提 ? 演算部分はC++ / CUDA, UI部分はPython ! ? @hokkun_cvの卒論にて利用 65 4. Implementation
- 66. 相澤?山崎研究室勉強会 cuda-convnet ? 基本的なCNNの機能を網羅 ? ただし自分たちで使ってるDropOutの実装はない ? (Forkして公開している人はいる) ! ? UI部分はPythonなのでいじりやすい ! ? 欠点: ? 画像を読み込ませるためにデータ加工するコードを自分で書かな ければならない ? 並列処理ライブラリCUDAを用いているので,重要な処理の部分 を変更するにはそれなりの知識が必要 66 4. Implementation
- 67. 相澤?山崎研究室勉強会 まとめ ? CNNはConvolutionとPoolingの繰り返しでできている ? アイデア自体はかなり古い ! ? 同じ層分だけあるフル接続NNよりも性能が良い ? なぜかはまだ理論的説明がない ! ? 局所的な正規化を行うことで性能向上 ! ? あらゆる場所でコンテストを行っても上位独占 ? 特にSupervisionの快挙は2013年にその改良を行う論文が多く執 筆されたことからもわかる 67
- 68. 相澤?山崎研究室勉強会 後半の参考資料(updated) ? 論文 ? Krizhevsky et al., ImageNet Classi?cation with Deep Convolutional Neural Networks, NIPS, 2012 ? LeCun et al., Gradient-Based Learning Applied to Document Recognition, Proc. of IEEE, 1998 ? [20][21][22] ! ? 日本語スライド ? http://www.slideshare.net/koji_matsuda/practical-recommendation-fordeeplearning ? http://www.slideshare.net/kazoo04/deep-learning-15097274 ? http://www.slideshare.net/yurieoka37/ss-28152060 (実装に詳しい) ? http://www.slideshare.net/mokemokechicken/pythondeep-learning (実際にアプリケーション を作成した例) ! ? 海外チュートリアル ? CVPR 2013のTutorialはCNNに焦点があたっている(GoogleのRanzato氏) ? ICML 2013, CVPR 2012等も参考になる 68
- 69. 相澤?山崎研究室勉強会 前半の参考資料(updated) ? 本 ? はじめてのパターン認識,平井著,森北出版 ? わかりやすいパターン認識,石井ら著,オーム社 ? PRML ! ? Web ? http://www.slideshare.net/Tyee/f5up ? http://www.slideshare.net/tonets/prml-chapter-5 ? http://www.cbrc.jp/ asai/LECTURE/H16SeitaiJouhouRon/NN_learning.pdf ! ! ! 69