ВІГвХёвћЦвЪгвІЮ_18_GumBolt (VAE with Boltzmann Machine)
Download as pptx, pdf0 likes261 views
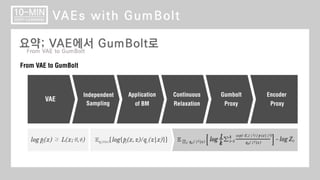
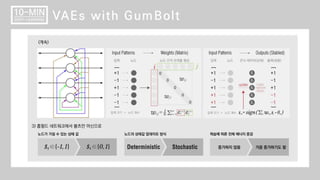
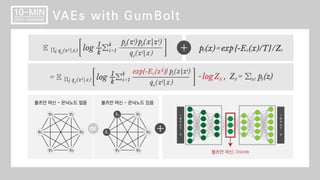
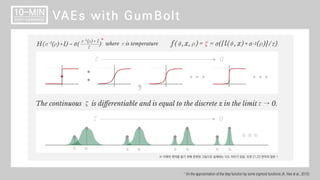
GumBolt (VAE with Boltzmann Machine) ВЌљ Ж┤ђьЋю ВёцвфЁВъЁвІѕвІц.
1 of 15
Downloaded 67 times











Ad
Recommended
[RAG Tutorial] 02. RAG рёЉрЁ│рёЁрЁЕрёїрЁдрєерёљрЁ│ ьїїВЮ┤ьћёвЮ╝ВЮИ.pdf
[RAG Tutorial] 02. RAG рёЉрЁ│рёЁрЁЕрёїрЁдрєерёљрЁ│ ьїїВЮ┤ьћёвЮ╝ВЮИ.pdfHyunKyu Jeon
╠§
[RAG Tutorial] RAG рёЉрЁ│рёЁрЁЕрёїрЁдрєерёљрЁ│ ьїїВЮ┤ьћёвЮ╝ВЮИ
[GITHUB] https://github.com/hkjeon13/rag-tutorial[RAG Tutorial] 01. RAG рёЉрЁ│рёЁрЁЕрёїрЁдрєерёљрЁ│ рёђрЁбрёІрЁГ.pdf
[RAG Tutorial] 01. RAG рёЉрЁ│рёЁрЁЕрёїрЁдрєерёљрЁ│ рёђрЁбрёІрЁГ.pdfHyunKyu Jeon
╠§
[RAG Tutorial] ьћёвАюВаЮьіИ Ж░юВџћ
[GITHUB] https://github.com/hkjeon13/rag-tutorial[PR-358] Training Differentially Private Generative Models with Sinkhorn Dive...
[PR-358] Training Differentially Private Generative Models with Sinkhorn Dive...HyunKyu Jeon
╠§
[PR-358] Paper Review - Training Differentially Private Generative Models with Sinkhorn Divergence
Super tickets in pre trained language models
Super tickets in pre trained language modelsHyunKyu Jeon
╠§
This document discusses finding "super tickets" in pre-trained language models through pruning attention heads and feedforward layers. It shows that lightly pruning BERT models can improve generalization without degrading accuracy (phase transition phenomenon). The authors propose a new pruning approach for multi-task fine-tuning of language models called "ticket sharing" where pruned weights are shared across tasks. Experiments on GLUE benchmarks show their proposed super ticket and ticket sharing methods consistently outperform unpruned baselines, with more significant gains on smaller tasks. Analysis indicates pruning reduces model variance and some tasks share more task-specific knowledge than others.Synthesizer rethinking self-attention for transformer models
Synthesizer rethinking self-attention for transformer models HyunKyu Jeon
╠§
Synthesizer: Rethinking Self-Attention for Transformer ModelsDomain Invariant Representation Learning with Domain Density Transformations
Domain Invariant Representation Learning with Domain Density TransformationsHyunKyu Jeon
╠§
The document discusses domain invariant representation learning aimed at creating models that generalize well to unseen domains, contrasting it with domain adaptation. It proposes a method that enforces invariance across transformations between domains and utilizes generative adversarial networks to implement these transformations. The effectiveness of the proposed approach is demonstrated on various datasets, achieving competitive results compared to state-of-the-art methods in domain generalization.Meta back translation
Meta back translationHyunKyu Jeon
╠§
This document summarizes Meta Back-Translation, a method for improving back-translation by training the backward model to directly optimize the performance of the forward model during training. The key points are:
1. Back-translation typically relies on a fixed backward model, which can lead the forward model to overfit to its outputs. Meta back-translation instead continually trains the backward model to generate pseudo-parallel data that improves the forward model.
2. Experiments show Meta back-translation generates translations with fewer pathological outputs like greatly differing in length from references. It also avoids both overfitting and underfitting of the forward model by flexibly controlling the diversity of pseudo-parallel data.
3. Related work leverages monMaxmin qlearning controlling the estimation bias of qlearning
Maxmin qlearning controlling the estimation bias of qlearningHyunKyu Jeon
╠§
This document summarizes the Maxmin Q-learning paper published at ICLR 2020. Maxmin Q-learning aims to address the overestimation bias of Q-learning and underestimation bias of Double Q-learning by maintaining multiple Q-functions and using the minimum value across them for the target in the Q-learning update. It defines the action selection and target construction for the update based on taking the maximum over the minimum Q-value for each action. The algorithm initializes multiple Q-functions, selects a random subset to update using the maxmin target constructed from the minimum Q-values. This approach reduces the biases seen in prior methods.Adversarial Attack in Neural Machine Translation
Adversarial Attack in Neural Machine TranslationHyunKyu Jeon
╠§
Adversarial Attack in Neural Machine TranslationВІГвХёвћЦвЪгвІЮ_19│т┤А│б│б│т┤Ах■░┐▒Ф░Н│т░С▒и▒и
ВІГвХёвћЦвЪгвІЮ_19│т┤А│б│б│т┤Ах■░┐▒Ф░Н│т░С▒и▒иHyunKyu Jeon
╠§
ВІГвХёвћЦвЪгвІЮ_19│т┤А│б│б│т┤Ах■░┐▒Ф░Н│т░С▒и▒и(edited) ВІГвХёвћЦвЪгвІЮ_17_DIM(DeepInfoMax)
(edited) ВІГвХёвћЦвЪгвІЮ_17_DIM(DeepInfoMax)HyunKyu Jeon
╠§
ВўцьЃѕВъљ ВѕўВаЋЖ│╝ ьЉюьўёВЮё вІцВєї ВѕўВаЋьЋўВўђВіхвІѕвІц.ВІГвХёвћЦвЪгвІЮ_16_WGAN (Wasserstein GANs)
ВІГвХёвћЦвЪгвІЮ_16_WGAN (Wasserstein GANs)HyunKyu Jeon
╠§
Wasserstein GANsВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.(ВўцьЃђвѓў ВўцвЦўЖ░ђ ВъѕВќ┤Вёю ВѕўВаЋв│И ВўгвдйвІѕвІцсЁасЁа)ВІГвХёвћЦвЪгвІЮ_15_SSD(Single Shot Multibox Detector)
ВІГвХёвћЦвЪгвІЮ_15_SSD(Single Shot Multibox Detector)HyunKyu Jeon
╠§
SSD(Single Shot Multibox Detector)ВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_14_YOLO(You Only Look Once)
ВІГвХёвћЦвЪгвІЮ_14_YOLO(You Only Look Once)HyunKyu Jeon
╠§
YOLO(You Only Look Once) вёцьіИВЏїьЂгВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_13_Transformer Networks (Self Attention)
ВІГвХёвћЦвЪгвІЮ_13_Transformer Networks (Self Attention)HyunKyu Jeon
╠§
ВЁђьћёВќ┤ьЁљВЁў(Self Attention)ЖИ░в▓ЋВЮё ВѓгВџЕьЋю Transformer NetworksВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_12_Вќ┤ьЁљВЁў(Attention Mechanism)
ВІГвХёвћЦвЪгвІЮ_12_Вќ┤ьЁљВЁў(Attention Mechanism)HyunKyu Jeon
╠§
Вќ┤ьЁљВЁў вЕћВ╗цвІѕВдў(Attention Mechanism)ВЌљ вїђьЋю вѓ┤ВџЕВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_9_VAE(Variational Autoencoder)
ВІГвХёвћЦвЪгвІЮ_9_VAE(Variational Autoencoder)HyunKyu Jeon
╠§
Variational AutoEncoderВЌљ вїђьЋ┤ ВёцвфЁьЋўвіћ ВігвЮ╝ВЮ┤вЊю ВъЁвІѕвІц.ВІГвХёВѕўьЋЎ│тВЃЂЖ┤ђЖ┤Х─Ж│ё(░С┤К░щ░щ▒▒З▓╣│┘Й▒┤К▓н)
ВІГвХёВѕўьЋЎ│тВЃЂЖ┤ђЖ┤Х─Ж│ё(░С┤К░щ░щ▒▒З▓╣│┘Й▒┤К▓н)HyunKyu Jeon
╠§
ВЃЂЖ┤ђЖ┤ђЖ│ё(Correlation), ьћ╝Вќ┤Віе ВЃЂЖ┤ђЖ│ёВѕў (Pearson Correlation Coefficient), Віцьћ╝Вќ┤вДї ВѕюВюё ВЃЂЖ┤ђЖ│ёВѕў(Spearman Rank Correlation Coefficient), В╝ёвІг ВѕюВюё ВЃЂЖ┤ђЖ│ёВѕў(Kendall Rank Correlation Coefficient)ВІГвХёВѕўьЋЎ│тЖ▒░вдг(Х┘Й▒▓ш│┘▓╣▓н│д▒)
ВІГвХёВѕўьЋЎ│тЖ▒░вдг(Х┘Й▒▓ш│┘▓╣▓н│д▒)HyunKyu Jeon
╠§
Distance in terms of Data Sciences/Math
about Euclidean Distance, Manhattan Distance, Minkowski Distance, and Mahalanobis distance.More Related Content
More from HyunKyu Jeon (20)
Adversarial Attack in Neural Machine Translation
Adversarial Attack in Neural Machine TranslationHyunKyu Jeon
╠§
Adversarial Attack in Neural Machine TranslationВІГвХёвћЦвЪгвІЮ_19│т┤А│б│б│т┤Ах■░┐▒Ф░Н│т░С▒и▒и
ВІГвХёвћЦвЪгвІЮ_19│т┤А│б│б│т┤Ах■░┐▒Ф░Н│т░С▒и▒иHyunKyu Jeon
╠§
ВІГвХёвћЦвЪгвІЮ_19│т┤А│б│б│т┤Ах■░┐▒Ф░Н│т░С▒и▒и(edited) ВІГвХёвћЦвЪгвІЮ_17_DIM(DeepInfoMax)
(edited) ВІГвХёвћЦвЪгвІЮ_17_DIM(DeepInfoMax)HyunKyu Jeon
╠§
ВўцьЃѕВъљ ВѕўВаЋЖ│╝ ьЉюьўёВЮё вІцВєї ВѕўВаЋьЋўВўђВіхвІѕвІц.ВІГвХёвћЦвЪгвІЮ_16_WGAN (Wasserstein GANs)
ВІГвХёвћЦвЪгвІЮ_16_WGAN (Wasserstein GANs)HyunKyu Jeon
╠§
Wasserstein GANsВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.(ВўцьЃђвѓў ВўцвЦўЖ░ђ ВъѕВќ┤Вёю ВѕўВаЋв│И ВўгвдйвІѕвІцсЁасЁа)ВІГвХёвћЦвЪгвІЮ_15_SSD(Single Shot Multibox Detector)
ВІГвХёвћЦвЪгвІЮ_15_SSD(Single Shot Multibox Detector)HyunKyu Jeon
╠§
SSD(Single Shot Multibox Detector)ВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_14_YOLO(You Only Look Once)
ВІГвХёвћЦвЪгвІЮ_14_YOLO(You Only Look Once)HyunKyu Jeon
╠§
YOLO(You Only Look Once) вёцьіИВЏїьЂгВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_13_Transformer Networks (Self Attention)
ВІГвХёвћЦвЪгвІЮ_13_Transformer Networks (Self Attention)HyunKyu Jeon
╠§
ВЁђьћёВќ┤ьЁљВЁў(Self Attention)ЖИ░в▓ЋВЮё ВѓгВџЕьЋю Transformer NetworksВЌљ вїђьЋю ВёцвфЁВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_12_Вќ┤ьЁљВЁў(Attention Mechanism)
ВІГвХёвћЦвЪгвІЮ_12_Вќ┤ьЁљВЁў(Attention Mechanism)HyunKyu Jeon
╠§
Вќ┤ьЁљВЁў вЕћВ╗цвІѕВдў(Attention Mechanism)ВЌљ вїђьЋю вѓ┤ВџЕВъЁвІѕвІц.ВІГвХёвћЦвЪгвІЮ_9_VAE(Variational Autoencoder)
ВІГвХёвћЦвЪгвІЮ_9_VAE(Variational Autoencoder)HyunKyu Jeon
╠§
Variational AutoEncoderВЌљ вїђьЋ┤ ВёцвфЁьЋўвіћ ВігвЮ╝ВЮ┤вЊю ВъЁвІѕвІц.ВІГвХёВѕўьЋЎ│тВЃЂЖ┤ђЖ┤Х─Ж│ё(░С┤К░щ░щ▒▒З▓╣│┘Й▒┤К▓н)
ВІГвХёВѕўьЋЎ│тВЃЂЖ┤ђЖ┤Х─Ж│ё(░С┤К░щ░щ▒▒З▓╣│┘Й▒┤К▓н)HyunKyu Jeon
╠§
ВЃЂЖ┤ђЖ┤ђЖ│ё(Correlation), ьћ╝Вќ┤Віе ВЃЂЖ┤ђЖ│ёВѕў (Pearson Correlation Coefficient), Віцьћ╝Вќ┤вДї ВѕюВюё ВЃЂЖ┤ђЖ│ёВѕў(Spearman Rank Correlation Coefficient), В╝ёвІг ВѕюВюё ВЃЂЖ┤ђЖ│ёВѕў(Kendall Rank Correlation Coefficient)ВІГвХёВѕўьЋЎ│тЖ▒░вдг(Х┘Й▒▓ш│┘▓╣▓н│д▒)
ВІГвХёВѕўьЋЎ│тЖ▒░вдг(Х┘Й▒▓ш│┘▓╣▓н│д▒)HyunKyu Jeon
╠§
Distance in terms of Data Sciences/Math
about Euclidean Distance, Manhattan Distance, Minkowski Distance, and Mahalanobis distance.