20120303 _JAWS-UG_SUMMIT2012_•®•≠•π•—©`•»•ª•√•∑•Á•ÛEMRæé
?
4 likes?952 views

2012ƒÍ3‘¬3»’§ŒJAWS-UG SUMMIT 2012§Œ•®•≠•π•—©`•»•ª•√•∑•Á•ÛElastic MapReduceæ駫§π°£ •«•‚•Ÿ©`•π§Œ•ª•√•∑•Á•Û§Œ§ø§·ŸY¡œ§¿§±§«§œÅª§Ô§Í§À§Ø§§≤ø∑÷§¨§¢§Í§Þ§π°£ §¥¡À≥–§Ø§¿§µ§§°£
































20120303 _JAWS-UG_SUMMIT2012_•®•≠•π•—©`•»•ª•√•∑•Á•ÛEMRæé
- 1. 2012/03/03 @JAWS SUMMIT 2012 ∞k±ÌŸY¡œ •®•≠•π•—©`•»•ª•√•∑•Á•Û Elastic MapReduce •Ù•ß•Î•Ø÷Í Ωª·…Á ΩÚæ√æÆ∫∆ô¿…(@quarterkota) http://www.velc.co.jp 1
- 2. ◊‘º∫…ÐΩÈ ΩÚæ√æÆ∫∆ô¿… @quarterkota °ˆÀ˘ Ù ? •Ù•ß•Î•Ø÷Í Ωª·…Á »°æÜ“€/•¢©`•≠•∆•Ø•» ? JAWS-UGñ|æ©?≤ø •≥•¢•·•Û•–©` ? ?∞„…Áá‚∑®?•Ø•È•¶•…¿˚?¥ŸþMôCòã ºº–g•¢•…•–•§•∂©` °ˆ∫√§≠§ AWS•µ©`•”•π EMR£∫∫Œ§Ë§Í§‚?ðX§µ§¨•π•¥•§ RDS£∫•§•±§∆§Î•–•√•Ø•¢•√•◊§À√¸§Ú滧ԧϧø§≥§»§¨§¢§Î °ˆΩUös IT•≥•Û•µ•Î(•’•Â©`•¡•„©`•¢©`•≠•∆•Ø•») °˙ •§•Û•ø©`•Õ•√•»é⁄∏ÊœµIT•Ÿ•Û•¡•„©`(•µ•§•∆•√•Ø) °˙ ∂¿?§∑§∆¨F‘⁄2∆⁄ƒø 2
- 7. ±æ»’§ŒAgenda 1.∑°≤—∏ȧ»§œ£ø 2.EMR§Œ•·•Í•√•» 3.∑°≤—∏ȧڥ•§√§∆§þ§Î 4.∑°≤—∏È π”√…œ§Œ§¥◊¢“‚ 5.◊Ó∫Û§À 7
- 8. 1.∑°≤—∏ȧ»§œ£ø 8
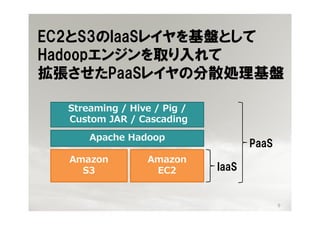
- 9. EC2§»S3§ŒIaaS•Ï•§•‰§Úª˘±P§»§∑§∆ Hadoop•®•Û•∏•Û§Ú»°§Í»Î§Ï§∆ íàè৵§ª§øPaaS•Ï•§•‰§Œ∑÷…¢ÑI¿Ìª˘±P Streaming / Hive / Pig / Custom JAR / Cascading Apache Hadoop PaaS Amazon Amazon S3 EC2 IaaS 9
- 10. —‘§§ìQ§®§Î§»??? ∫√§≠§ ïr§À∫√§≠§ §¿§± π§®§Î •Ø•È•¶•…–ÕHadoopª˘±P £´ 10
- 11. ±æ»’§ŒAgenda 2.EMR§Œ•·•Í•√•» 11
- 13. §∑§´§∑°¢±·≤πªÂ¥«¥«±Ë§¨”–Ñø§Àº⁄ÉP§π§Î •™•Û•◊•Ï≠hæ≥§Ú◊˜§Î§À§œ??? …Ÿ§ §Ø§»§‚ ˝ Æî“郣§Œ•µ©`•–§¨±ÿ“™ •§•À•∑•„•Î•≥•π•»?•·•Û•∆• •Û•π•≥•π•»¥Û •–•√•¡”√Õ槨÷––ƒ§À§ §Î§ø§·°¢ °∏•Í•Ω©`•π§Œø’§≠ïrÈg°π§¨∞k…˙§∑§¨§¡ 13
- 16. ¿˝§®§–??? m1.large§Ú20•Œ©`•…§«3ïrÈg§ŒÑI¿Ì $0.46 x 20 x 3 = $27.6 ®P 2346É“(85É“/$)
- 17. 3.∑°≤—∏ȧڥ•§√§∆§þ§Î 17
- 18. EMR§œ•Ê©`•∂§´§È§Œ÷∏ æ§Àª˘§≈§§§∆ •∏•Á•÷•’•Ì©`§Ú…˙≥… Hadoop•Ø•È•π•ø (EC2•§•Û•π•ø•Û•π»∫) •∏•Á•÷•’•Ì©` ÑI¿Ìƒ⁄»ð Hadoop•Ø•È•π•ø§Œ•µ•§•∫ § §… 18
- 21. •∏•Á•÷•’•Ì©`§Œ◊˜§Í∑Ω§œ 2•—•ø©`•Û 1.≥“±´±ı(•Þ•Õ•∏•·•Û•»•≥•Û•Ω©`•Î)§´§È§Œ◊˜≥… 2.∞‰≥¢±ı§´§È§Œ◊˜≥… 21
- 23. 2.∞‰≥¢±ı§´§È§Œ◊˜≥… 23
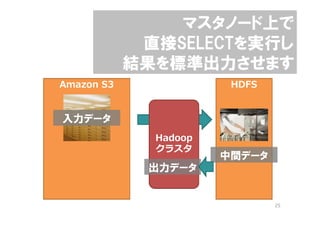
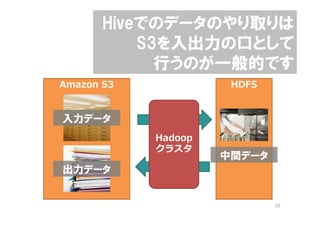
- 25. •Þ•π•ø•Œ©`•……œ§« ÷±Ω”SELECT§Úåg––§∑ ΩYπ˚§ÚòÀú ≥ˆ¡¶§µ§ª§Þ§π Amazon S3 HDFS »Î¡¶•«©`•ø Hadoop •Ø•È•π•ø ÷–Èg•«©`•ø ≥ˆ¡¶•«©`•ø 25
- 26. ±·æ±±π±§«§Œ•«©`•ø§Œ§‰§Í»°§Í§œ S3§Ú»Î≥ˆ¡¶§Œø⁄§»§∑§∆ ––§¶§Œ§¨“ª∞„µƒ§«§π Amazon S3 HDFS »Î¡¶•«©`•ø Hadoop •Ø•È•π•ø ÷–Èg•«©`•ø ≥ˆ¡¶•«©`•ø 26
- 30. ≥ß± ∞øπÛ§Úøº¬«§π§Ÿ§∑£° ÕÚ§¨“ª•Þ•π•ø•Œ©`•…§À ’œ∫¶§¨∞k…˙§∑§øàˆ∫œ »´§∆§ŒÑI¿ÌΩYπ˚§¨ ߧԧϧÎ
- 33. 5.◊Ó∫Û§À
- 34. EMR§œ¥Û¡ø∑÷…¢ÑI¿Ì§Ú “ªöð§À…ÌΩ¸§ §‚§Œ§À§π§Î ª≠∆⁄µƒ§ •µ©`•”•π§«§π §»§À§´§Ø•¨•Û•¨•Û π§√§∆ «ÈàÛπ≤”–§ÚþM§·§Þ§∑§Á§¶
- 37. enjoy life and creation http://www.velc.co.jp 37