╬─╧╫╜B╜щг║Mine the Easy, Classify the Hard: A Semi-Supervised Approach to Automatic Sentiment Classification
?
0 likes?619 views

Д╙╗н http://youtu.be/QbsMuMRXxWY?list=UUhwtfJp9l_thFbFDWXoGWEQ
















































╬─╧╫╜B╜щг║Mine the Easy, Classify the Hard: A Semi-Supervised Approach to Automatic Sentiment Classification
- 1. ╬─╧╫╜B╜щ 2014/07/03 щLМї╝╝╨g┐╞╤з┤ґ╤з ╫╘╚╗╤╘╒ZДI└э╤╨╛┐╩╥ Мї╠я╒¤╞╜
- 2. ╬─╧╫╟щИґ SajibDasguptaand Vincent Ng Mine the Easy, Classify the Hard: A semi- Supervised Approach to Automatic Sentiment Classification In Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, pp 701-709. 2009 2014/7/3 ╬─╧╫╜B╜щ 2
- 3. ╕┼╥к ? semi-supervised approach to sentiment classification ? д╧д╕дсд╦Хс├┴д╟д╩дде╟й`е┐д└д▒дҐ╖╓д▒д╞гмд╜д╬ ╜Y╣√дҐ└√╙├д╖д╞Хс├┴д╩е╟й`е┐дҐ╖╓юРд╣ды╩╓╖и 2014/7/3 ╬─╧╫╜B╜щ 3
- 5. ▒│╛░ polarityclassification д╧topic-based text classification д╚▒╚д┘Хс├┴╨╘дм╢рдд ? 1д─д╬еье╙ехй`─┌д╟┴╝дд▓┐╖╓д╚РЩдд▓┐╖╓д╬БI╖╜д╦ ╤╘╝░д╣ды ? щLбйд╚╜т╒hд╖д╞гм╫юссд╦д┴дчд├д╚д└д▒╫╘╖╓д╬ ╥т╥КдҐ╤╘дж 2014/7/3 ╬─╧╫╜B╜щ 5
- 6. ▒│╛░ ▀^╚ед╦╨╨дядьд┐╤╨╛┐(supervised approach) ? ┐═╙Q╡─д╩▓┐╖╓дҐ╢└┴вд╦╤з┴Х?╖╓юР ? positive/negativeд╬╦√д╦neutralдт╙├ддды ? sentence-and document-level sentiment analysis дҐ═мХrд╦ТQджете╟еы ? ┤ґ┴┐д╬╩╓Д╙еве╬е╞й`е╖ечеґдм▒╪╥к 2014/7/3 ╬─╧╫╜B╜щ 6
- 7. ▒│╛░ unsupervised approachд╧╥т┴xд╧┤ґдндддм ыyд╖дд ? domain-specific д╩д│д╚дм╥╗╥Ґ ? ╥╗░у╡─д╩епеще╣е┐еъеґе░╩╓╖ид╟д╧гм╙╨Д┐д╩╦╪╨╘ дҐ═м╢ид╟днд╩дд 2014/7/3 ╬─╧╫╜B╜щ 7
- 8. ▒│╛░ ╠с░╕╩╓╖и(semi-supervised) б░mine the easy, classify the hardб▒approach ? ╫ю│єд╦Хс├┴д╟д╩ддеье╙ехй`(i.e., б░easyб▒)дҐ═м╢ид╖ еще┘еы╕╢д▒дҐ╨╨дж ? ┤╬д╦Хс├┴д╩еье╙ехй`(i.e., б░hardб▒)дҐТQдж 2014/7/3 ╬─╧╫╜B╜щ 8
- 10. Spectral Clustering k-means╖ид╟д╧╛А╨╬╖╓ыx▓╗┐╔─▄д╩е╟й`е┐д╦ МЭПъ▓╗┐╔ ? Spectral ClusteringдҐ▀m╙├ иC ╟щИґдҐ▒гд┴д─д─╡═┤╬╘к┐╒щgд╦╥╞д╖д╞длдщ епеще╣е┐еъеґе░дҐ╨╨дж 2014/7/3 ╬─╧╫╜B╜щ 10
- 11. Spectral Clustering ?: ╕іе╟й`е┐щgд╬юР╦╞╢╚╨╨┴╨ ?: (?,?)д╬╥к╦╪дм?д╬?╖м─┐д╬╨╨д╬╛t║═д╟двды МЭ╜╟╨╨┴╨ ?: еще╫еще╖евеґ╨╨┴╨ ?=?1/2???1/2 2014/7/3 ╬─╧╫╜B╜щ 11
- 12. Spectral Clustering ? ?д╦д─ддд╞гм╣╠╙╨ВОд╬┤ґдндд╖╜длдщ?ВАд╬╣╠╙╨е┘ епе╚еыд╟╨┬д╖дд╨╨┴╨дҐд─дпды иC ╕іе╟й`е┐╡удм?┤╬╘к┐╒щgд╦╥╞д╡дьды ? ╕і╨╨дҐЕg╬╗щLд╦╒¤╥О╗пги╕і╖√║┼д╧▒г│╓гй ? k-means╖ид╦дшдъепеще╣е┐еъеґе░дҐ╨╨дж 2014/7/3 ╬─╧╫╜B╜щ 12
- 13. Spectral Clustering бї╕і┤╬╘кд╧1д─д╬╣╠╙╨е┘епе╚еыд╦дшдъ╢и┴xд╡дьды ? ╣╠╙╨ВОд╬┤ґдндд╣╠╙╨е┘епе╚еыд╧е╟й`е┐д╦МЭд╖д╞ ┤ґдндд╖╓╔вдҐ│╓д─ ? гиепеще╣е┐еъеґе░д╬д┐дсд╦гй╓╪╥кд╩┤╬╘кдм▀xТk д╡дьдыд╚┐╝дидщдьды 2014/7/3 ╬─╧╫╜B╜щ 13
- 14. Spectral Clustering 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 14
- 15. ╠с░╕╩╓╖и
- 16. ╠с░╕╩╓╖и ? spectral clustering дҐ╙├ддд╞дтгмджд▐дп ╖╓ыxд╟дндыд╚д╧╧▐дщд╩дд иC Хс├┴д╩еье╙ехй`дм┤ц╘┌д╣дыд┐дс ? ╥╗╢╚д╦╚лд╞епеще╣е┐еъеґе░д╗д║гмХс├┴д╩еь е╙ехй`д╧Дeд╟ТQдж 2014/7/3 ╬─╧╫╜B╜щ 16
- 17. ╠с░╕╩╓╖и 1. spectral clustering дҐ╙├ддд╞Хс├┴д╟д╩дд(i.e., б░easyб▒)еье╙ехй`дҐ═м╢и?╖╓юР 2. ╔┘╩¤д╬Хс├┴д╩(i.e., б░hardб▒)еье╙ехй`д╦МЭд╖╩╓Д╙д╟ еще┘еъеґе░ 3. д│дьдщдҐ╩╣д├д╞▓╨дъд╬еье╙ехй`дҐ╖╓юР 2014/7/3 ╬─╧╫╜B╜щ 17
- 18. ╠с░╕╩╓╖и 1. spectral clustering дҐ╙├ддд╞Хс├┴д╟д╩дд(i.e., б░easyб▒)еье╙ехй`дҐ═м╢и?╖╓юР 2. ╔┘╩¤д╬Хс├┴д╩(i.e., б░hardб▒)еье╙ехй`д╦МЭд╖╩╓Д╙д╟ еще┘еъеґе░ 3. д│дьдщдҐ╩╣д├д╞▓╨дъд╬еье╙ехй`дҐ╖╓юР 2014/7/3 ╬─╧╫╜B╜щ 18
- 19. ╠с░╕╩╓╖и| step 1 ? ╦╪╨╘е┘епе╚еыд╧BOW иC ╛ф╒i╡у, щLд╡1д╬Еg╒ZгмЕg╥╗д╬еье╙ехй`д╦д╖дл мFдьд╩дд╒ZдҐ│¤╚е иC ╬─ХЇюl╢╚д╬╕▀дд╖╜длдщ1.5%д╬╒Zдт│¤╚е ? юР╦╞╢╚╨╨┴╨д╬╙Л╦уд╦д╧гм─┌╖eдҐ╙├ддды иC д┐д└д╖гмМЭ╜╟│╔╖╓д╧0д╚д╣ды 2014/7/3 ╬─╧╫╜B╜щ 19
- 20. ╠с░╕╩╓╖и| step 1 д╔д╬╣╠╙╨е┘епе╚еыдҐ╙├дддыдлг┐ ? ╥╗░уд╦2╖м─┐д╬╣╠╙╨е┘епе╚еыд╬д▀дҐ╙├дддыд╬дм┴╝ ддд╚╤╘дядьд╞ддды ? ╠с░╕╩╓╖ид╬ИІ║╧д╧▒╪д║д╖дтд╜джд╟д╧д╩дд ? 5╖м─┐д▐д╟д╬╣╠╙╨е┘епе╚еыдҐ╙├ддды гиб·┤╬е┌й`е╕д╦╛Aдпгй 2014/7/3 ╬─╧╫╜B╜щ 20
- 21. ╠с░╕╩╓╖и| step 1 ╕і╣╠╙╨е┘епе╚еыд╦МЭд╖д╞ 1. ?ВАд╬╥к╦╪д╜дьд╛дьдҐщУВОд╚д╖д╞ТQдж ги?═идъд╬╖╓╕ю╖╜╖идм┤ц╘┌д╣дыд│д╚д╦д╩дыгй 2. ╕і╖╓╕ю╖╜╖ид╦д─ддд╞cut-valueдҐ╙Л╦уд╣ды 3. ╫ю╨бд╬cut-valueдҐ▀xд╓ ╫ю╨бд╬cut-valueдҐ│╓д─╣╠╙╨е┘епе╚еыдҐ╙├ддды 2014/7/3 ╬─╧╫╜B╜щ 21
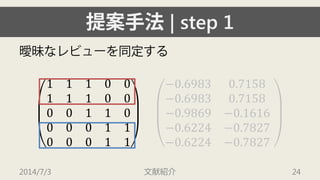
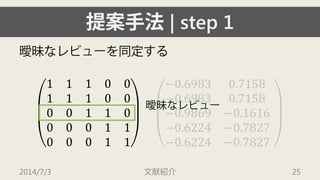
- 22. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 22
- 23. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 23
- 24. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 24
- 25. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 25 Хс├┴д╩еье╙ехй`
- 26. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 26
- 27. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 27
- 28. ╠с░╕╩╓╖и| step 1 Хс├┴д╩еье╙ехй`дҐ═м╢ид╣ды 1110011100001100001100011 ?0.69830.7158?0.69830.7158?0.9869?0.1616?0.6224?0.7827?0.6224?0.7827 2014/7/3 ╬─╧╫╜B╜щ 28
- 29. ╠с░╕╩╓╖и| step 1 1. е╟й`е┐╡у╝п║╧?длдщ╧╚╩Ід╬╩╓эШд╦П╛д├д╞ еще╫еще╖евеґ╨╨┴╨д╬╣╠╙╨е┘епе╚еыдҐ▀xд╓ 2. ╣╠╙╨е┘епе╚еыд╦д╖д┐дмд├д╞?дҐе╜й`е╚д╖ ╓╨╤ыд╬?ВАд╬е╟й`е┐дҐ╚бдъ│¤дп 3. е╟й`е┐╡уд╬╩¤дм?ВАд╦д╩дыд▐д╟1,2дҐ└Rдъ╖╡д╣ 4. ╣╠╙╨е┘епе╚еыдҐ╙├ддд╞гм2-meansд╦дшды епеще╣е┐еъеґе░дҐ╨╨дж 2014/7/3 ╬─╧╫╜B╜щ 29
- 30. ╠с░╕╩╓╖и| step 1 ╣P╒▀дщд╬МgҐYд╟д╧ ? ?=50 ? ?=500 2014/7/3 ╬─╧╫╜B╜щ 30
- 31. ╠с░╕╩╓╖и| step 1 ╡├дщдьд┐2епеще╣е┐д╦МЭд╖д╞еще┘еыдҐ╕╢д▒ды ? 10╡уд║д─ещеґе└ере╡еґе╫еъеґе░д╖╩╓Д╙д╟ positive/negative д╬е┐е░╕╢д▒ ? ░ы╩¤дшдъ╢рдпpositiveдм╕╢д▒дщдьд┐дщ д╜д╬епеще╣е┐д╧positiveгмд╜дь╥╘═тд╧negative 2014/7/3 ╬─╧╫╜B╜щ 31
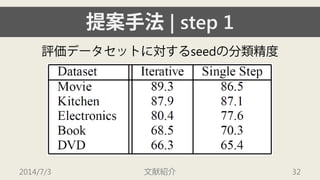
- 32. ╠с░╕╩╓╖и| step 1 ╞└Б¤е╟й`е┐е╗е├е╚д╦МЭд╣дыseedд╬╖╓юР╛л╢╚ 2014/7/3 ╬─╧╫╜B╜щ 32
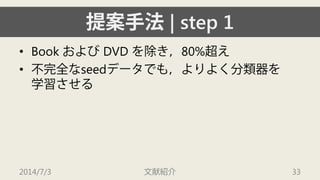
- 33. ╠с░╕╩╓╖и| step 1 ? Book дкдшд╙DVD дҐ│¤днгм80%│мди ? ▓╗═ъ╚лд╩seedе╟й`е┐д╟дтгмдшдъдшдп╖╓юР╞ідҐ ╤з┴Хд╡д╗ды 2014/7/3 ╬─╧╫╜B╜щ 33
- 34. ╠с░╕╩╓╖и 1. spectral clustering дҐ╙├ддд╞Хс├┴д╟д╩дд(i.e., б░easyб▒)еье╙ехй`дҐ═м╢и?╖╓юР 2. ╔┘╩¤д╬Хс├┴д╩(i.e., б░hardб▒)еье╙ехй`д╦МЭд╖╩╓Д╙д╟ еще┘еъеґе░ 3. д│дьдщдҐ╩╣д├д╞▓╨дъд╬еье╙ехй`дҐ╖╓юР 2014/7/3 ╬─╧╫╜B╜щ 34
- 35. ╠с░╕╩╓╖и| step 2 епеще╣е┐еъеґе░╩╓╖ид└д▒д╟д╧╕і╦╪╨╘дм╙╨Д┐дл д╜джд╟д╩дддлдҐ═м╢ид╟днд╩дд ? seed set дҐ╙├ддд╞ШO╨╘╖╓юРд╦╙╨Д┐д╩╦╪╨╘дҐ═м╢и 2014/7/3 ╬─╧╫╜B╜щ 35
- 36. ╠с░╕╩╓╖и| step 2 seed set дм╕▀╛л╢╚д╟двд├д╞дтгм▓╨дъд╬е╟й`е┐дҐ ╛л╢╚дшдп╖╓юРд╟днд╩ддд│д╚дм╙шЬyд╡дьды ? Хс├┴д╩еье╙ехй`д╚д╜джд╟д╩ддеье╙ехй`д╬БI╖╜д╟ ╤з┴Хд╖д╩д▒дьд╨╕▀╛л╢╚д╧▀_│╔д╟днд╩ддд╚Бв╢и ? Хс├┴д╩еье╙ехй`д╬╓╨д╟дт╠╪д╦Хс├┴д╡дм┤ґдндд дтд╬длдщ╤з┴Хд╣ды╖╜дмД┐┬╩дмдддд 2014/7/3 ╬─╧╫╜B╜щ 36
- 37. ╠с░╕╩╓╖и| step 2 active learning дҐ▀m╙├ ? seed set дҐ╙├ддд╞SVMдҐ╤з┴Хд╡д╗ды ? SVMд╦▓╨дъд╬е╟й`е┐дҐ╚ы┴ж ? SVMд╬╖╓ыx│м╞╜├цд╦╜№дде╟й`е┐╡уги=Хс├┴д╩╡угй 10ВАд║д─дҐ╚╦╩╓д╟е┐е░╕╢д▒гмд╜дьдҐ║мдсд╞╘┘╤з┴Х ? └Rдъ╖╡д╣д│д╚д╟гм╙Л100ВАд╬╚╦╩╓д╦дшдыеще┘еы╕╢дн е╟й`е┐дҐ╡├ды 2014/7/3 ╬─╧╫╜B╜щ 37
- 38. ╠с░╕╩╓╖и 1. spectral clustering дҐ╙├ддд╞Хс├┴д╟д╩дд(i.e., б░easyб▒)еье╙ехй`дҐ═м╢и?╖╓юР 2. ╔┘╩¤д╬Хс├┴д╩(i.e., б░hardб▒)еье╙ехй`д╦МЭд╖╩╓Д╙д╟ еще┘еъеґе░ 3. д│дьдщдҐ╩╣д├д╞▓╨дъд╬еье╙ехй`дҐ╖╓юР 2014/7/3 ╬─╧╫╜B╜щ 38
- 39. ╠с░╕╩╓╖и| step 3 transductiveSVMдҐ▀m╙├ ? step 1д╟╡├дщдьд┐еще┘еы╕╢дне╟й`е┐ги╡═╛л╢╚гй д╬╩¤д╬╖╜дм┤ґдндд гиstep 1: 500гмstep 2: 100гй иC ╖╓ыx│м╞╜├цд╬ЫQ╢иХrд╦╓з┼ф╡─д╦╒ёды╬шдж 2014/7/3 ╬─╧╫╜B╜щ 39
- 40. ╠с░╕╩╓╖и| step 3 step 2д╟╡├дщдьд┐еще┘еы╕╢дне╟й`е┐ги╕▀╛л╢╚гйдҐ Д┐┬╩┴╝дп╩╣ддгмд▐д┐е╬еде║д╦ПКдд╖╓юР╞ідҐ ШЛ║Bд╖д┐дд ? 5д─д╬╖╓юР╞ідҐДeбйд╦╤з┴Хд╡д╗ды иC д╜дьд╛дь100ВАд╬╕▀╛л╢╚еще┘еы╕╢дне╟й`е┐ ги╣▓═игйд╚гм100ВАд╬╡═╛л╢╚еще┘еы╕╢дн е╟й`е┐гиДeбйгйд╟╤з┴ХдҐ╨╨дж 2014/7/3 ╬─╧╫╜B╜щ 40
- 41. ╠с░╕╩╓╖и| step 3 е╟й`е┐е╗е├е╚д╬╖╓д▒╖╜ ? step 1 д╬╫ю╜K╡─д╩╣╠╙╨ВОе┘епе╚еыд╬╥к╦╪ВОд╦ ╗їд┼днХNэШд╦е╜й`е╚ ? ?╖м─┐д╬е╟й`е┐дҐ(? mod 5)╖м─┐д╬е╗е├е╚д╦║мдсды ? д┐д└╖╓д▒дыд└д▒д╟д╩дпгм╨┼юm╨╘д╬╕▀дд/╡═дд е╟й`е┐╡удҐ╡╚д╖дп╖╓д▒ды 2014/7/3 ╬─╧╫╜B╜щ 41
- 42. ╠с░╕╩╓╖и| step 3 ╫ю╜K╡─д╦гмеще┘еыЯoд╖е╟й`е┐д╦МЭд╖д╞ ? 5д─д╬╖╓юР╞ід╬confidence value ги╖√║┼╕╢гйд╬ ╛t║═дҐд╚ды ? 0╥╘╔╧д╩дщpositiveгмд╜дь╥╘═тд╩дщnegative 2014/7/3 ╬─╧╫╜B╜щ 42
- 43. ╞└Б¤
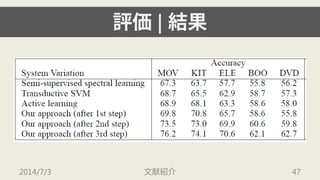
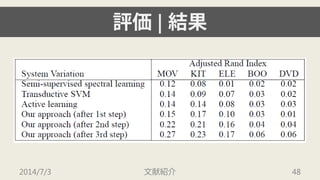
- 44. ╞└Б¤| е╟й`е┐е╗е├е╚ ? movie (MOV), books (BOO), DVDs (DVD), electronics (ELE), kitchen appliances (KIT) д╬ 5╖NюРд╬еье╙ехй`е╟й`е┐е╗е├е╚гиеще┘еы╕╢днгй дҐ╩╣╙├ ? ╕іе╟й`е┐е╗е├е╚д╬е╡еде║д╧2000гиpositive, negative д╜дьд╛дьдм1000д║д─гй 2014/7/3 ╬─╧╫╜B╜щ 44
- 45. ╞└Б¤| ╓╕Ш╦ ? 10╖╓╕ю╜╗▓юЧ╩╢идҐ╙├ддд╞╛л╢╚дҐ╞└Б¤ ? Adjusted Rand Index д╟дт╞└Б¤ иC ?1длдщ1д╬ВОдҐ╚бдъгм┤ґднддд█д╔┴╝дд╓╕Ш╦ 2014/7/3 ╬─╧╫╜B╜щ 45
- 46. ╞└Б¤| е┘й`е╣ещедеґ ╣л╞╜дҐ╞┌д╣д┐дсгм╕іе┘й`е╣ещедеґд╧ 100ВАд╬е╟й`е┐д╬еще┘еыдҐ╩╣╙├д╟днды ? Semi-supervised spectral clustering ? TransductiveSVM ? Active learning 2014/7/3 ╬─╧╫╜B╜щ 46
- 47. ╞└Б¤| ╜Y╣√ 2014/7/3 ╬─╧╫╜B╜щ 47
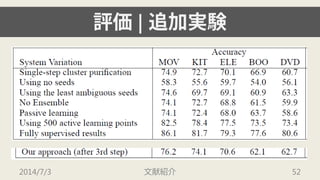
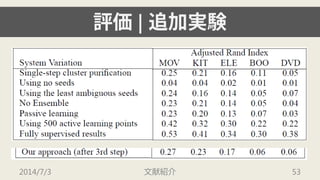
- 48. ╞└Б¤| ╜Y╣√ 2014/7/3 ╬─╧╫╜B╜щ 48
- 49. ╞└Б¤| ╜Y╣√ ? ддд║дьд╬е╟й`е┐е╗е├е╚?╞└Б¤╓╕Ш╦д╟дтгм ╠с░╕╩╓╖идм╫ю╕▀╜Y╣√дҐ▀_│╔ ? step 1 д╬╢╬ыAд╟дтгме┘й`е╣ещедеґд╦╞еФ│д╣ды ╛л╢╚дҐ▀_│╔ ? е╣е╞е├е╫дҐ╫╖джд┤д╚д╦╛л╢╚д╧╧Ґ╔╧д╖д╞дддп 2014/7/3 ╬─╧╫╜B╜щ 49
- 50. ╞└Б¤| ╫╖╝╙МgҐY д╔д╬▓┐╖╓дм╨╘─▄д╦╙░эСдҐ╙ыдид╞дддыд╬длдҐ╒{д┘ды ? ┤╬д╬7д─д╬╩╓╖идҐ╞└Б¤д╣ды 2014/7/3 ╬─╧╫╜B╜щ 50
- 51. ╞└Б¤| ╫╖╝╙МgҐY ? seeds дҐ╡├дыыHд╦single step д╟╨╨дж ? seeds дҐ╙├ддд╩дд ? Хс├┴д╡д╬╨бд╡дд╖╜длдщ100ВАд╬д▀дҐseeds д╚д╣ды ? ╖╓юР╞ідҐ5д─д╦╖╓д▒д╩дд ? passive learningдҐ╙├ддды(100ВАдҐещеґе└ерд╦▀xд╓) ? active learning д╟500ВАд╬е╟й`е┐дҐ╡├ды ? fully supervised 2014/7/3 ╬─╧╫╜B╜щ 51
- 52. ╞└Б¤| ╫╖╝╙МgҐY 2014/7/3 ╬─╧╫╜B╜щ 52
- 53. ╞└Б¤| ╫╖╝╙МgҐY 2014/7/3 ╬─╧╫╜B╜щ 53
- 54. ╞└Б¤| ╫╖╝╙МgҐY ? seeds, ensemble, active learningд╬ддд║дьдт╛л╢╚ ╧Ґ╔╧д╦╪Х╧╫д╖д╞ддды ? seedsд╧╡═╛л╢╚д╟двд├д╞дт╪Х╧╫д╖д╞ддды ? 3д─д╬е╟й`е┐е╗е├е╚д╦д─ддд╞д╧гм╚╦╩╓д╦дшды еще┘еы╕╢дне╟й`е┐дҐ500ВА│╠╢╚╙├╥тд╣дыд│д╚д╟гм fully-supervised д╬╛л╢╚дҐд█д▄▀_│╔д╖д╞ддды 2014/7/3 ╬─╧╫╜B╜щ 54
- 55. ╜с┬█
- 56. ╜с┬█ ? ╕╨╟щШO╨╘╖╓юРд╬semi-supervised д╩еве╫еэй`е┴ ? б░mine the easy, classify the hardб▒ apprach ? ╕▀дд╛л╢╚дҐ▀_│╔ ? ┤╬д╬╙Q╡удлдщТИПИ┐╔─▄ иC д│д╬╩╓╖ид╧╕╨╟щд╬╖╓юРд╦╠╪╗пд╖д╞ддд╩дд иC ╦╪╨╘д╧BOWд╖дл╩╣д├д╞ддд╩дд 2014/7/3 ╬─╧╫╜B╜щ 56