


































![•¢•◊•Í•±©`•∑•Á•ÛÈ_∞k•—©`•»
º»¥Ê•∑•π•∆•ý§»§Œøé§Æ§≥§þ
∏þÀŸ§«•π•∆©`•÷•Î
ågþ\”√§«•—•Ô©`§Ú∞kì]§π§Î•¢•◊•Í•±©`•∑•Á•Û§À](https://image.slidesharecdn.com/20190212-supporterz-190213044954/85/20190212-supporterz-48-320.jpg)










20190212 supporterz
- 2. ΩÒ»’§Œ¡˜§Ï °Ò ∫Œπ ΩÒôC–µ—ß¡ï§ §Œ§´ °Ò ôC–µ—ß¡ï§Ú»°§ÍéܧØ≠hæ≥§»•”•∏•Õ•πôCª·§ŒÈvÇS °Ò ôC–µ—ß¡ï@•”•∏•Õ•π °Ò §Ë§ØÐW§Ø•ð•§•Û•»§»§Ω§ŒΩ‚õQ∑Ω∑® °Ò ôC–µ—ß¡ï@»À≤ƒ °Ò •«©`•ø•µ•§•®•Û•∆•£•π•»§Œ”˝§∆∑Ω
- 3. √„è䪷§¨ΩK§Ô§√§ø§»§≠§À§¢§ §ø§œ °Ò ΩÒ»’§Œ√„è䪷§«°≠ °Ò ôC–µ—ߡ匿•”•∏•Õ•π’nÓ}§ÚΩ‚õQ§π§Î¨Fàˆ§Ú÷™§Ï§Î °Ò åg¡¶§¨§¢§Ï§–√˜»’§´§ÈªÓÐS§«§≠§Î °Ò ΩÒ»’§Œƒ⁄»ð§œ °Ò ôC–µ—ß¡ï§Ú§¢§Î≥Ã∂»÷™§√§∆§§§Î»ÀœÚ§±§«§π ª˘µA§¨§¢§Î≥Ã∂»§¢§√§∆°¢§…§¶ 𧶧´§Ú÷™§Í§ø§§»À °Ò ª˘µA§´§È§‰§Í§ø§§»À§œ§≥§¡§È§‚Å„§ª§∆§…§¶§æ ΩÒ∏¸¬Ñ§±§ §§ôC–µ—ߡ琉ª˘µA§»èÍ”√ https://supporterz.jp/spevents/detail/20180803_kyoto »´≤ø“䧪§Þ§π°¢•«©`•ø•µ•§•®•Û•∆•£•π•»§Œ À ¬ https://supporterzcolab.com/event/485/
- 4. ◊‘º∫ΩBΩÈ °Ò —ß…˙ïr¥˙ °Ò ¥Û—ߧ«•¢•·•’•»≤ø§«œý ÷•¡©`•ý§Œ•«©`•ø∑÷Œˆ °Ò ¥Û—ß°¢¥Û—ß‘∫§«ôC–µ—ß¡ï§Úåüπ• °Ò —–æø•∆©`•Þ :ôC–µ—ß¡ï§À§Ë§Î•¢•·•Í•´•Û•’•√•»•Ð©`•Î§ŒëȬ‘Õ∆∂® °Ò •§•Û•ø©`•Û -> òIÑ’ŒØ”ö∆ıºs ° •Þ•Ø•Ì•þ•Î§«1•ˆ‘¬§Œ•§•Û•ø©`•Û•∑•√•◊§Œ··°¢∞΃ÍòIÑ’ŒØ”ö∆ıºs •«©`•ø•µ•§•®•Û•∆•£•π•»§»§∑§∆ÉP§Ø§≥§»§Ú÷™§Î ◊¢“‚ °Ò •µ•√•´©`þx ÷§«§œ§¢§Í§Þ§ª§Û •«©`•ø£°•¢•·•’•»£° ÷–¥Âø°ðo @shun_naka
- 5. ◊‘º∫ΩBΩÈ °Ò …Áª·»À °Ò òSÃϧ«•≠•„•Í•¢•π•ø©`•» °Ò Hadoop§Ú π§√§ø•”•√•∞•«©`•øÑI¿Ì°¢Web•¢•◊•Í•±©`•∑•Á•ÛÈ_∞k °Ò ôC–µ—ß¡ï§Ú π§¶ôCª·§À§œê{§Þ§Ï§∫ °Ò cherry-pick»Î…Á °Ò ◊‘…Á•µ©`•”•π§ŒôC–µ—ß¡ï≤ø∑÷§ŒÈ_∞k °Ò »Àπ§÷™ƒÐ ДöÈ_∞kª·…Á CTO °Ò ДöÈ_∞k§ŒôC–µ—ß¡ï≤ø∑÷°¢ °Ò 30•◊•Ì•∏•ß•Ø•» 50»À“‘…œ§Œ•«©`•ø•µ•§•®•Û•∆•£•π•»§Œ”˝≥…°¢•Þ•Õ©`•∏•„ °Ò •Þ•Õ©`•’•©•Ô©`•…•∞•Î©`•◊ •Ø•È•”•π »Àπ§÷™ƒÐ—–æøÀ˘ À˘ÈL °Ò ï¯Óê•«©`•øªØ•¢•◊•Í•±©`•∑•Á•Û§ŒôC–µ—ß¡ï≤ø∑÷§ŒÈ_∞k°¢•Þ•Õ©`•∏•„ °Ò •®•√•∏•≥•Û•µ•Î•∆•£•Û•∞ AI•∏•Á•÷•´•Ï ÷véü °Ò ôC–µ—ß¡ï°¢…Óå”—ß¡ï÷v◊˘§Œ÷véü °˘»’±æ•«•£©`•◊•È©`•À•Û•∞Öfª·’J∂®÷v◊˘ °Ò ÷–¥Âƒ¡àˆ∫œÕ¨ª·…Á ‘O¡¢ °Ò ôC–µ—ߡ琉•≥•Û•µ•Î°¢ ДöÈ_∞k°¢»À≤ƒ”˝≥… °Ò ÷Í Ωª·…ÁSplink AI•®•–•Û•∏•ß•Í•π•» °Ò »À≤ƒ”˝≥…°¢•◊•Ì•∏•ß•Ø•»•Þ•Õ©`•∏•„©` °Ò ƒŒ¡º•Ø•È•÷ CTO °Ò •µ•√•´©`•¡©`•ý§Œ•∆•Ø•Œ•Ì•∏©`»´∞„°¢IoT, AI, •π•ð©`•ƒ•«©`•øΩ‚Œˆ •«©`•ø£°•«©`•ø£° ÷–¥Âø°ðo @shun_naka
- 6. ◊‘º∫ΩBΩÈ °Ò ÉP§≠∑Ω °Ò •’•Î•Í•‚©`•»°¢•Õ•™…Áª·»À °Ò ÇÄ»À§ŒªÓÑ” °Ò NFL§«•«©`•ø∑÷ŒˆŒð§µ§Û§À§ §Î§Ÿ§Ø •¢•·•’•»§Œ•¢•◊•Í§Œ—–æøÈ_∞k§Ú§‰§√§∆§Þ§π @æ©∂º °Ò “ª∞„…Áá‚∑®»ÀJapan American football Dream §Œ“ªÜT§»§∑§∆ªÓÑ”§‚§∑§∆§Þ§π ÷–¥Âø°ðo @shun_naka •«©`•ø£°§»•π•ð©`•ƒ(Ãÿ§À•¢•·•’•»)§« √Ê∞◊§§§≥§»§Ú§‰§Í§ø§§£°
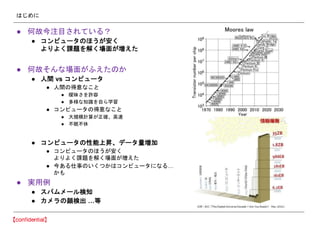
- 9. §œ§∏§·§À °Ò ôC–µ—ß¡ï£ø °Ò »ÀÈg§¨◊‘»ª§À––§√§∆§§§Î—ß¡ïƒÐ¡¶§»Õ¨òôCƒÐ§Ú •≥•Û•‘•Â©`•ø§«åg¨F§∑§Ë§¶§»§π§Îºº–g? ÷∑® (Wikipedia) °Ò 1959ƒÍ§´§È¥Ê‘⁄ °Ò ÃÿÑe–¬§∑§§ºº–g§«§œ§ §§
- 10. §œ§∏§·§À °Ò ∫Œπ ΩÒ◊¢ƒø§µ§Ï§∆§§§Î£ø °Ò •≥•Û•‘•Â©`•ø§Œ§€§¶§¨∞≤§Ø §Ë§Í§Ë§Ø’nÓ}§ÚΩ‚§Øàˆ√ʧ¨â৮§ø °Ò ∫Œπ §Ω§Û§ àˆ√ʧ¨§’§®§ø§Œ§´ °Ò »ÀÈg vs •≥•Û•‘•Â©`•ø °Ò »ÀÈg§Œµ√“‚§ §≥§» °Ò ï·√¡§µ§Ú‘S»ð °Ò ∂ýòî§ ÷™◊R§Ú◊‘§È—ß¡ï °Ò •≥•Û•‘•Â©`•ø§Œµ√“‚§ §≥§» °Ò ¥Û“郣”ãÀ„§¨’˝¥_°¢∏þÀŸ °Ò ≤ª√þ≤ª–ð °Ò •≥•Û•‘•Â©`•ø§Œ–‘ƒÐ…œïN°¢•«©`•ø¡øâດ °Ò •≥•Û•‘•Â©`•ø§Œ§€§¶§¨∞≤§Ø §Ë§Í§Ë§Ø’nÓ}§ÚΩ‚§Øàˆ√ʧ¨â৮§ø °Ò ΩÒ§¢§Î À ¬§Œ§§§Ø§ƒ§´§œ•≥•Û•‘•Â©`•ø§À§ §Î°≠ §´§‚ °Ò åg”√¿˝ °Ò •π•—•ý•·©`•Îó ÷™ °Ò •´•·•È§ŒÓÜó ≥ˆ °≠µ»
- 11. ôC–µ—ߡ裡§‚§ø§È§π”∞Ìë °Ò ¨F‘⁄þM–––Œ§«ÆbòI∏Ô√¸§¨2§ƒ∆§≥§√§∆§§§Î °Ò ICT∏Ô√¸ °Ò »Àπ§÷™ƒÐ∏Ô√¸ °Ò ôC–µ—ߡ匿•”•∏•Õ•π’nÓ}§ÚΩ‚õQ§«§≠§Î§»∏Ç’˘¡¶§¨§¢§¨§Î °Ò ôC–µ—ß¡ï§Ú π§√§ø∑Ω§¨µÕ•≥•π•»§«§Ë§Í§Ë§ØΩ‚õQ§«§≠§Î’nÓ}§¨∂ý§Ø§ §Î °Ò §Ω§Œ’nÓ}§ÚôC–µ—ß¡ï§Ú π§√§∆Ω‚õQ§π§Î§≥§»§«∏Ç’˘¡¶§¨§¢§¨§Î
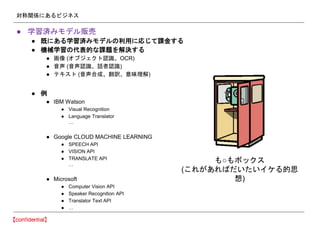
- 16. åù≥∆ÈvÇS§À§¢§Î•”•∏•Õ•π °Ò —ß¡ïúg§þ•‚•«•Îÿúâ” °Ò º»§À§¢§Î—ß¡ïúg§þ•‚•«•Î§Œ¿˚”√§Àèͧ∏§∆’nΩ§π§Î °Ò ôC–µ—ߡ琉¥˙±Ìµƒ§ ’nÓ}§ÚΩ‚õQ§π§Î °Ò ª≠œÒ (•™•÷•∏•ß•Ø•»’J◊R°¢OCR) °Ò “Ù…˘ (“Ù…˘’J◊R°¢‘í’þ’J◊R) °Ò •∆•≠•π•» (“Ù…˘∫œ≥…°¢∑≠‘U°¢“‚Œ∂¿ÌΩ‚) °Ò ¿˝ °Ò IBM Watson °Ò Visual Recognition °Ò Language Translator °≠ °Ò Google CLOUD MACHINE LEARNING °Ò SPEECH API °Ò VISION API °Ò TRANSLATE API °≠ °Ò Microsoft °Ò Computer Vision API °Ò Speaker Recognition API °Ò Translator Text API °Ò °≠ §‚°§‚•Ð•√•Ø•π (§≥§Ï§¨§¢§Ï§–§¿§§§ø§§•§•±§ÎµƒÀº œÎ)
- 17. ±»ð^ ДöÈ_∞k •Ø•È•¶•… §€§∑§§§‚§Œ§¨ π§®§Î ° °˜ ÿîÆb§¨≤–§Î§´ ° °¡ ¿˚”√È_ º§Þ§«§ŒïrÈg °¡ °Ú ±æ√„è䪷§«§œ÷˜§À ДöÈ_∞kŒð§µ§Û§´§È“䧮§Î ¿ΩÁ§Ú‘í§∑§Þ§π
- 18. æþõƒ§ ––Ñ”°¢≥…π˚ŒÔ °Ò ågÎH§Œ•”•∏•Õ•π’nÓ}§ÚΩ‚§Ø ÷Ìò °Ò ÜñÓ}‘O∂® °Ò •«©`•øþx∂® °Ò «∞ÑI¿Ì °Ò ôC–µ—ߡ匿∑÷Œˆ °Ò ΩYπ˚¥_’J°¢‘ŸÑI¿Ì °Ò º»¥Ê•∑•π•∆•ý§»§Œøé§Æ§≥§þ °˘‘î§∑§Ø§œÑe•ª•þ• ©`(≥ı–ƒ’þœÚ§±)§À§∆ »´≤ø“䧪§Þ§π°¢•«©`•ø•µ•§•®•Û•∆•£•π•»§Œ À ¬ https://supporterzcolab.com/event/485/
- 19. æþõƒ§ ––Ñ”°¢≥…π˚ŒÔ (‘îºö) °Ò ågÎH§Œ•”•∏•Õ•π’nÓ}§ÚΩ‚§Ø ÷Ìò °Ò ÜñÓ}‘O∂® °Ò ª·◊h°¢Ü”òI °Ò •«©`•øþx∂® °Ò ª·◊h°¢•«©`•ø•Ÿ©`•π≤Ÿ◊˜ °Ò «∞ÑI¿Ì °Ò ETL(Extract/Transform/Load)ÑI¿Ì•π•Ø•Í•◊•»È_∞k •«©`•ø•Ÿ©`•π≤Ÿ◊˜°¢Ωy”ãÑI¿Ì °Ò ôC–µ—ߡ匿∑÷Œˆ °Ò È_∞k (Python•·•§•Û) °Ò ΩYπ˚¥_’J°¢‘ŸÑI¿Ì °Ò ø…“ïªØ°¢‘uÅ˝÷∏òÀ¥_’J °Ò º»¥Ê•∑•π•∆•ý§»§Œøé§Æ§≥§þ °Ò APIªØÈ_∞k°¢•§•Û•’•Èòã∫B
- 20. Îy§∑§§•ð•§•Û•» °Ò ågÎH§Œ•”•∏•Õ•π’nÓ}§ÚΩ‚§Ø ÷Ìò °Ò ÜñÓ}‘O∂® °Ò ª·◊h°¢Ü”òI °Ò •«©`•øþx∂® °Ò ª·◊h°¢•«©`•ø•Ÿ©`•π≤Ÿ◊˜ °Ò «∞ÑI¿Ì °Ò ETL(Extract/Transform/Load)ÑI¿Ì•π•Ø•Í•◊•»È_∞k •«©`•ø•Ÿ©`•π≤Ÿ◊˜°¢Ωy”ãÑI¿Ì °Ò ôC–µ—ߡ匿∑÷Œˆ °Ò È_∞k (Python•·•§•Û) °Ò ΩYπ˚¥_’J°¢‘ŸÑI¿Ì °Ò ø…“ïªØ°¢‘uÅ˝÷∏òÀ¥_’J °Ò º»¥Ê•∑•π•∆•ý§»§Œøé§Æ§≥§þ °Ò APIªØÈ_∞k°¢•§•Û•’•Èòã∫B Îy§∑§§•ð•§•Û•»§Ú•·•§•Û§«’h√˜§∑§Þ§π
- 25. ¨Fàˆ§«§‰§Î§≥§» Ü”òI§»§§§¶§Ë§Í°≠ °Ò ∆ıºs§Ú§…§¶§π§Î§´°¢§«§œ§ §Ø §…§Û§ §‚§Œ§Ú◊˜§Î§´°¢§Ú‘í§π °Ò §‚§¶…Ÿ§∑§§§¶§»°¢≥ı§·§À◊˜§Î•◊•Ì•»•ø•§•◊§Œ–Œ§Ú§…§¶§π§Î§´§Ú‘í§π °Ò ¿˝ •Ø•È•§•¢•Û•»°∏EC§Œ•«©`•ø§Ú§Þ§»§·§∆“ä§Ï§Î§Ë§¶§ •µ©`•”•π§Ú◊˜§Í§ø§§°π §≥§¡§È°∏≥÷§√§∆§§§Î•«©`•ø§À§ƒ§§§∆Ω箧∆§‚§È§®§Þ§π§´£ø°π •Ø•È•§•¢•Û•»°∏∏˜•◊•È•√•»•’•©©`•ý§«…Ã∆∑§Œ•≥©`•…(JAN•≥©`•…)§Œô⁄§¨§¢§Î§¨ »Î¡¶§œ•Ê©`•∂©`»Œ§ª§ §Œ§«§ƒ§§§∆§§§Î§‚§Œ§»§ƒ§§§∆§§§ §§§‚§Œ§¨§¢§Î°π §≥§¡§È°∏§∏§„§°JAN•≥©`•…§Àåù§∑§∆…Ã∆∑§Ú√˚ºƒ§ª§π§Î•∑•π•∆•ý§À§∑§Þ§∑§Á§¶°£°π °∏“ª≤ø•«©`•ø§ÚΩÃéü•«©`•ø§À π§®§Î§Œ§«°¢ §§§√§ø§ÛΩÒ§¢§Î•«©`•ø§«1-2•´‘¬§‰§√§∆§þ§Þ§π°£°π
- 26. •¢•Û•¡•—•ø©`•Û °Ò °∞ôC–µ—ß¡ï§«Ω‚§Ø§Ÿ§≠§«§œ§ §§ÜñÓ}°±§ÀÃÙëȧπ§Î§Œ§œ±Ð§±§Î§Ÿ§≠ °Ò ôC–µ—ß¡ï§«Ω‚§Ø§Ÿ§≠§‚§Œ °Ò ðX∂»§ ÷™µƒ◊˜òI°¢•«©`•ø§ÚºØ§·§Ï§–§ §Û§»§´§ §Î§‚§Œ °Ò œ»––—–æø§ §…§¨§¢§Î§‚§Œ °Ò Ω‚§Ø§Ÿ§≠§«§œ§ §§§‚§Œ °Ò ∏þ∂»§ ÷™µƒ◊˜òI°¢§¢§§§Þ§§§µ°¢•Œ•§•∫§¨¥Û§≠§§•«©`•ø °Ò ΩÃéü•«©`•ø§Œ»Î ÷§¨¿ßÎy °Ò ¿˝ (Web•Þ©`•±•∆•£•Û•∞◊‘Ñ”ªØ•ƒ©`•Î) •Ø•È•§•¢•Û•» °∏“‘œ¬§Œ§…§Ï§´§‰§Í§ø§§§Û§¿§±§…°≠°π ¢Ÿé⁄∏ÊŸè»Î ó À˜•Ø•®•Í•Ï•≥•·•Û•… ¢⁄ó À˜•Ø•®•Í§¥§»§Œ•È•Û•≠•Û•∞…œŒªªØ ©≤þ•Ï•≥•·•Û•… ¢€Web•⁄©`•∏◊‘Ñ”∏¸–¬ §≥§¡§È °∏1§¨“ª∑¨∫ÜÖg§«3§¨“ª∑¨Îy§∑§§°π °Ò Îy§∑§µ§Ú∑÷§´§√§ø§¶§®§«•¡•„•Ï•Û•∏§π§Î§ §ÈOK °Ò Îy§∑§µ§¨∑÷§´§√§∆§§§ §§§» •Ø•È•§•¢•Û•» °∏§≥§Û§ §≥§»§‚§«§≠§ §§§Œ§´°π
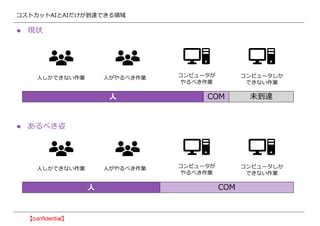
- 29. •≥•π•»•´•√•»AI§»AI§¿§±§¨µΩþ_§«§≠§ÎÓI”Ú °Ò ¨F◊¥ °Ò §¢§Î§Ÿ§≠◊À »À§∑§´§«§≠§ §§◊˜òI »À§¨§‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§¨ §‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§∑§´ §«§≠§ §§◊˜òI »À COM Œ¥µΩþ_ »À§∑§´§«§≠§ §§◊˜òI »À§¨§‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§¨ §‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§∑§´ §«§≠§ §§◊˜òI »À COM
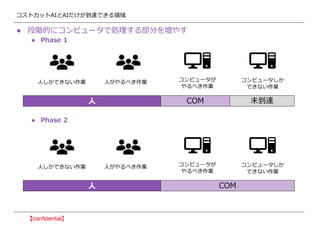
- 30. •≥•π•»•´•√•»AI§»AI§¿§±§¨µΩþ_§«§≠§ÎÓI”Ú °Ò ∂ŒÎAµƒ§À•≥•Û•‘•Â©`•ø§«ÑI¿Ì§π§Î≤ø∑÷§Úâ৉§π °Ò Phase 1 °Ò Phase 2 »À§∑§´§«§≠§ §§◊˜òI »À§¨§‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§¨ §‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§∑§´ §«§≠§ §§◊˜òI »À COM »À§∑§´§«§≠§ §§◊˜òI »À§¨§‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§¨ §‰§Î§Ÿ§≠◊˜òI •≥•Û•‘•Â©`•ø§∑§´ §«§≠§ §§◊˜òI »À COM Œ¥µΩþ_
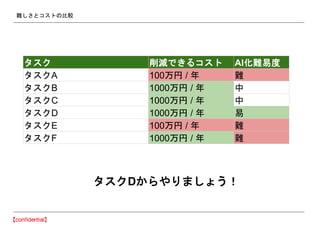
- 31. •≥•π•»•´•√•»AI§ŒÃ·∞∏ °Ò ågÎH§Œ◊˜òI °Ò •ø•π•ØA °Ò •ø•π•ØB °Ò •ø•π•ØC °Ò •ø•π•ØD °Ò •ø•π•ØE °Ò •ø•π•ØF °Ò Œ“°©§¨§«§≠§Î§≥§» °Ò §Ω§Ï§æ§Ï§Œ’nÓ}§ÚAI§«¥˙Ãʧπ§Îàˆ∫œ§ŒÎy§∑§µ°¢“ä∑e§‚§Í °Ò ¬òI÷˜§À§‰§√§∆§‚§È§¶§≥§» °Ò §Ω§Ï§æ§Ï§Œ’nÓ}§ÚAIªØ§«§≠§ø§»§≠§Œœ˜úp§µ§Ï§Î•≥•π•»§Œ‘áÀ„ °Ò ±æµ±§œ§‰§Í§ø§§§≥§»§Œ•Í•π•»
- 32. Îy§∑§µ§»•≥•π•»§Œ±»ð^ •ø•π•ØD§´§È§‰§Í§Þ§∑§Á§¶£° •ø•π•Ø œ˜úp§«§≠§Î•≥•π•» AIªØÎy“◊∂» •ø•π•ØA 100ÕÚÉ“ / ƒÍ Îy •ø•π•ØB 1000ÕÚÉ“ / ƒÍ ÷– •ø•π•ØC 1000ÕÚÉ“ / ƒÍ ÷– •ø•π•ØD 1000ÕÚÉ“ / ƒÍ “◊ •ø•π•ØE 100ÕÚÉ“ / ƒÍ Îy •ø•π•ØF 1000ÕÚÉ“ / ƒÍ Îy
- 33. •µ•÷•»•‘•√•Ø §Þ§∫§™øÕ§µ§Û§Ú§…§¶§‰§√§∆“䧃§±§Î§Œ£ø °Ò §Ω§≥§È÷–§À§§§Î §≥§Œ√„è䪷§À§‚¿¥§∆§§§Î§´§‚ °Ò §‰§√§∆§§§Þ§π∏–§Ú≥ˆ§π§Œ§œ¥Û ¬ (•ª•Î•’•÷•È•Û•«•£•Û•∞) °Ò æþõƒ§ ––Ñ” °Ò √„è䪷÷˜¥þ °Ò √„è䪷≤Œº” °Ò LinkedIn, FaceBookµ»§«§Œ∏Ê÷™µ» °Ò “ª∑¨∫ÜÖg °Ò ÷–¥Âƒ¡àˆ§À¿¥§Î
- 34. Ū§®§Î§Ÿ§≠§≥§» È_∞k’þ§¨“‚◊R§π§Ÿ§≠§≥§» °Ò •Ø•È•§•¢•Û•»§À∑÷§´§√§∆§‚§È§¶±ÿ“™§¨§¢§Î§≥§» °Ò ôC–µ§œ°∞Ó^§Œ¡º§§°±»ÀÈg§«§œ§ §§ »ÀÈg§Œ§€§¶§¨°±Ó^§œ¡º§§°± °Ò »ÀÈg§¨ôC–µ§ÀÑŸ§∆§ §§àˆ√ʧ¨¥Ê‘⁄§π§Î§¿§± ðX∂»§ ÷™µƒ◊˜òI§‰•≥•π•»√Ê °Ò È_∞k’þ§¨“‚◊R§π§Î±ÿ“™§¨§¢§Î§≥§» °Ò º»§ÀΩ‚§´§Ï§∆§§§ÎÀ∆§ø’nÓ}§Œ èÍ”√§¿§±§«ÓôøÕ§œ•œ•√•‘©`§À§ §Î§≥§»§¨∂ý§§ °Ò Œ“°©§œ—–æø’þ§«§œ§ §§
- 35. vs æÞ»À °Ò æÞ»À§ø§¡§»§Œ≤ÓÑeªØ°¢ π§§∑Ω °Ò §Ë§Ø—‘§Ô§Ï§Î—‘»~°∏∫Œ§¨þ`§¶§Œ£ø°π °Ò ∏Ç∫œ§π§Î§´£ø °Ò Yes °Ò Öf’{§«§≠§Î§´£ø °Ò Yes API§Ú§ƒ§ §Æ§≥§ýÈ_∞k§¿§±§« ɶ§±§∆§§§Î•”•∏•Õ•π§‚§¢§Î
- 36. vs æÞ»À 2 °Ò æÞ»À§ø§¡§»§Œ≤ÓÑeªØ°¢ π§§∑Ω °Ò æÞ»À§Œ¡¶§Ú π§®§Î§»§≥§Ì§œ π§√§∆°¢ 𧮧 §§≤ø∑÷§¿§±◊˜§Î ±æµ±§À§Þ§∏§·§À§‰§Î§ §È∂¿◊‘È_∞k§Œ§€§¶§¨¡º§§§¨°¢ §Þ§∏§·§À§‰§È§ §Ø§∆§‚¡º§§£®ïr¥˙§ÀþW§Ï§ §±§Ï§–OK£©§»Àº§√§∆§§§Î»À§‚§§§Î ◊ÓΩKµƒ§ÀAI§Ú•”•∏•Õ•π§Œ•≥•¢•–•Í•Â©`§»§π§Î§´°¢§¨≈–∂œª˘ú °Ò •”•∏•Õ•π§¿§±§«§§§®§–°¢ §ƒ§ §Æ§≥§ý§¿§±§«È_∞k§¨ΩK§Ô§Î§ §È§Ω§Ï§œ§Ω§Ï§«§Ë§§ Ðáðܧ¿§±§«úg§ý§ §È§–°¢ÐáðܧŒ‘Ÿ∞k√˜§Ú§π§Î±ÿ“™§œ§ §§ °˘òS§∑§Ø§œ°≠§ §§§´§‚ ДöÈ_∞k •Ø•È•¶•… §€§∑§§§‚§Œ§¨ π§®§Î ° °˜ ÿîÆb§¨≤–§Î§´ ° °¡ ¿˚”√È_ º§Þ§«§ŒïrÈg °¡ °Ú
- 38. §Ω§Œ∑÷“∞§Œ•◊•Ì§Œ÷™◊R§Ú§§§´§À∑¥”≥§µ§ª§È§Ï§Î§´ °Ò •–•Í•Â©`§Ú≥ˆ§ª§Î•ð•§•Û•» °Ò ôC–µ—ߡ琉åüÈTº“ x •”•∏•Õ•π§ŒåüÈTº“§¨ΩM§ý§´§È§Ë§§ °Ò §π§Ÿ§∆•«©`•ø•…•Í•÷•Û§«§œ¡º§§•¢•◊•Í•±©`•∑•Á•Û§œ◊˜§Ï§ §§ •”•∏•Õ•π§Ú§‰§√§∆§§§Î»À§Œ•…•·•§•Û÷™◊R§¨±ÿ“™ °Ò ôC–µ—ߡ琉åüÈTº“ °Ò •«©`•ø§Ú π§√§∆§…§¶Å˝Çé§Ú≥ˆ§π§´§Ú÷™§√§∆§§§Î§¨ §Ω§Œ•”•∏•Õ•π§Ú÷™§√§∆§§§Î§Ô§±§«§œ§ §§ °Ò §Ω§Œ•”•∏•Õ•π§«µ√§È§Ï§ø•«©`•ø§ŒÃÿè’§‰°¢Ω‚§≠§ø§§’nÓ}§œ •”•∏•Õ•πÇ»§´§ÈΩ箧∆§‚§È§¶±ÿ“™§¨§¢§Î ôC–µ—ߡ琉åüÈTº“ •”•∏•Õ•π§ŒåüÈTº“ •«©`•ø¿˚”√ ° °¡ •”•∏•Õ•π÷™◊R °¡ °
- 40. §Ω§Œ∑÷“∞§Œ•◊•Ì§Œ÷™◊R§Ú§§§´§À∑¥”≥§µ§ª§È§Ï§Î§´ ®C •¢•Û•¡•—•ø©`•Û °Ò •¢•Û•¡•—•ø©`•Û °Ò ôC–µ—ß¡ï§Ú∑÷§´§√§∆§§§ §§»À§¨•Í©`•…§Ú§∑§∆ Œ“°©§¨•”•∏•Õ•π“™«Û§ÚœÎœÒ§π§Î °˘ΩYòã§Ë§Ø“ä§Þ§π °Ò •Ø•È•§•¢•Û•»°∏§≥§Û§ ÷∑®§¨§§§§§√§∆¬Ñ§§§ø§Û§¿§±§…°¢ π§√§∆§þ§∆°π §≥§¡§È°∏§®§√°≠ (µƒÕ‚§Ï§π§Æ •Ô•Ì•π£˜)°π §≥§¡§È°∏•«©`•øµƒ§À§œ§≥§≥§œ§≥§¶§ §œ§∫°π •Ø•È•§•¢•Û•»°∏§Ω§Û§ §Ô§±§¢§Î§´ (ågÎH§À À ¬§∑§∆§ §§§´§È À∑Ω§Õ§ß§ °≠§ƒ§√§´§®)°π ôC–µ—ߡ琉åüÈTº“ •”•∏•Õ•π§ŒåüÈTº“ •«©`•ø¿˚”√ ° °¡ •”•∏•Õ•π÷™◊R °¡ ° °˘°∏‘≠“Ú§»ΩYπ˚§ŒΩUúg—ß°π (÷– “ƒ¡◊”°¢ΩÚ¥®”—ΩÈ÷¯°¢•¿•§•‰•‚•Û•……Á)
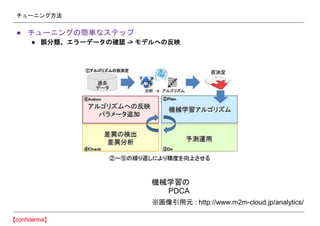
- 43. ‘uÅ˝∑Ω∑® °Ò ∑÷§´§Í§‰§π§§ƒøòÀ§»‘uÅ˝÷∏òÀ§«’h√˜§∑§∆§¢§≤§Î °Ò ΩK§Ô§Í§œ§≥§√§¡§«õQ§·§Î (•Ø•È•§•¢•Û•»§œ§…§¶§‰§√§ø§ÈΩK§Ô§Î§´§‚§Ô§´§√§∆§ §§) °Ò ¿˝) •◊•Ì•»•ø•§•◊§Ú2§´‘¬§«◊˜§Í§Þ§π°£ƒøòÀ’˝¥¬ §œ80% §Ω§Œ··°¢•¡•Â©`•À•Û•∞§Ú3•´‘¬§´§±§∆§‰§Í§Þ§π°£ƒøòÀ’˝¥¬ §œ95% °Ò ‘uÅ˝÷∏òÀ§œòî°©§ §‚§Œ§¨§¢§Î§¨°¢ø…ƒÐ§ œÞ§Í∑÷§´§Í§‰§π§§§‚§Œ§Ú ’˝¥¬ §‰∆Ωæ˘’`≤Óµ»§¨“ª∑¨¡º§§ °˘•Ï•ð©`•»”√§»•‚•«•Î‘uÅ˝”√§À‘uÅ˝÷∏òÀ§ÚÑe°©§Àúy§Î§≥§»§‚§∑§–§∑§– °Ò •∞•È•’§Ú≥ˆ§π§»§´§ §Íœ≤§–§Ï§Î °Ò ‘uÅ˝÷∏òÀ§Ë§Í•¡•Â©`•À•Û•∞§π§Î
- 44. •¡•Â©`•À•Û•∞∑Ω∑® °Ò •¡•Â©`•À•Û•∞§Œ∫ÜÖg§ •π•∆•√•◊ °Ò ’`∑÷Óê°¢•®•È©`•«©`•ø§Œ¥_’J -> •‚•«•Î§ÿ§Œ∑¥”≥ ôC–µ—ߡ琉 PDCA °˘ª≠œÒ“˝”√‘™ : http://www.m2m-cloud.jp/analytics/
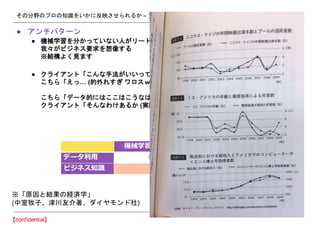
- 45. §‚§√§»¡º§§§‚§Œ§Ú◊˜§Í§ø§§§»Àº§√§ø§»§≠§À °Ò ◊RÑe–‘ƒÐ§ §…§Œ•‚•«•Î§Œ–‘ƒÐ§Ú…œïN§µ§ª§ø§§§ §È ¿Ì’짨œ»§«§œ§‚§¶◊∑§§§ƒ§±§ §§ °Ò Ãÿ§À•À•Â©`•È•Î•Õ•√•»•Ô©`•Ø °Ò •µ•ð©`•»•Ÿ•Ø•ø©`•Þ•∑•Û§Ø§È§§§Þ§«§œ¿Ì’윻––§¿§√§ø °Ò ¿Ì’ì(ª˘µA) —–æø -> èÍ”√—–æø§Ú÷ߧ®§ÎáÌ Ω °Ò Deep Learning§Ú÷ߧ®§ÎDrop Out, òã‘ϧ«§¢§ÎCNN, RNN§œèÍ”√(ågº˘) §´§È’Q…˙§∑°¢ –‘ƒÐ§«‘uÅ˝§µ§Ï§∆§§§Î °˘¿Ì’짌 ˝—ßµƒ§ ‘^√˜§œ§ §Ø°¢§™§Ω§È§Ø§Ω§¶§¿§Ì§¶°¢§»§§§¶§‚§Œ§¨∂ý§§ £®—YÇ»§Œ•—•È•·©`•ø◊ÓþmªØ§œ∑«≥£§À∫ÜÖg§ §‚§Œ§«§¢§Í°¢ •Õ•√•»•Ô©`•Ø§Œòã‘ϵ»§Ú‘á§∑°¢ó ‘^§∑§∆–‘ƒÐ§ÚœÚ…œ§µ§ª§Î§Œ§¨•·•§•Û£©
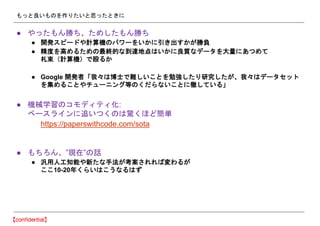
- 46. §‚§√§»¡º§§§‚§Œ§Ú◊˜§Í§ø§§§»Àº§√§ø§»§≠§À °Ò §‰§√§ø§‚§ÛÑŸ§¡°¢§ø§·§∑§ø§‚§ÛÑŸ§¡ °Ò È_∞k•π•‘©`•…§‰”ãÀ„ôC§Œ•—•Ô©`§Ú§§§´§À“˝§≠≥ˆ§π§´§¨ÑŸÿì °Ò æ´∂»§Ú∏þ§·§Î§ø§·§Œ◊ÓΩKµƒ§ µΩþ_µÿµ„§œ§§§´§À¡ºŸ|§ •«©`•ø§Ú¥Û¡ø§À§¢§ƒ§·§∆ ‘˝ ¯£®”ãÀ„ôC£©§«≈π§Î§´ °Ò Google È_∞k’þ°∏Œ“°©§œ≤© ø§«Îy§∑§§§≥§»§Ú√„èä§∑§ø§Í—–æø§∑§ø§¨°¢Œ“°©§œ•«©`•ø•ª•√•» §ÚºØ§·§Î§≥§»§‰•¡•Â©`•À•Û•∞µ»§Œ§Ø§¿§È§ §§§≥§»§Àèÿ§∑§∆§§§Î°π °Ò ôC–µ—ߡ琉•≥•‚•«•£•∆•£ªØ: •Ÿ©`•π•È•§•Û§À◊∑§§§ƒ§Ø§Œ§œÛ@§Ø§€§…∫ÜÖg https://paperswithcode.com/sota °Ò §‚§¡§Ì§Û°¢°±¨F‘⁄°±§Œ‘í °Ò ö¯”√»Àπ§÷™ƒÐ§‰–¬§ø§ ÷∑®§¨øº∞∏§µ§Ï§Ï§–≧ԧΧ¨ §≥§≥10-20ƒÍ§Ø§È§§§œ§≥§¶§ §Î§œ§∫
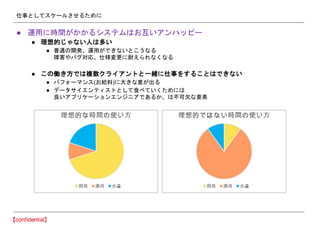
- 49. •Þ•§•Ø•Ì•µ©`•”•π§À§π§Î °Ò Ög∂¿§«Ñ”◊˜§∑°¢•∑•Û•◊•Î °Ò RESTful API§¨∑÷§´§Í§‰§π§§ °Ò API•Ø•È•§•¢•Û•»§‚È_∞k§∑§∆∂…§π§»° °Ò •«©`•ø§Œ Ч±∂…§∑§‚œý ÷§À§∑§∆§‚§È§¶§Œ§¨¿ÌœÎ °Ò §≥§¡§È§¨÷±Ω”•«©`•ø•Ÿ©`•π§À•¢•Ø•ª•π§π§Î§Œ§Ú±Ð§±§Î (•µ©`•”•π§Œ’œ∫¶§À§∑§∆§œ§ §È§ §§) °Ò æÞ»À§ŒAPI§Œ◊˜§Í§œ§´§ §Í≤Œøº§À§ §Î °Ò ¿˝) Google Cloud Vision API§«§œ ª≠œÒ§Úbase64•®•Û•≥©`•…§∑§∆Œƒ◊÷¡–§À§∑§∆•Í•Ø•®•π•»§π§Î°£ •–•§• •Í§Ë§Í»ð¡ø§¨â৮§Î°¢•®•Û•≥©`•…§»•«•≥©`•…ÑI¿Ì§¨±ÿ“™§À§ §Î§¨ Œƒ◊÷¡–§ §Œ§«•∑•Û•◊•Î°¢»°íQ§¨òS °Ò ∫ÜÖg§ •¡•Â©`•À•Û•∞§œÓôøÕ§À§«§≠§Î§Ë§¶§À °Ò •«©`•ø§Œºö§´§§•’•©©`•Þ•√•»§Œâ‰∏¸§‰◊∑º”µ»
- 50. À ¬§»§∑§∆•π•±©`•Î§µ§ª§Î§ø§·§À °Ò þ\”√§ÀïrÈg§¨§´§´§Î•∑•π•∆•ý§œ§™ª•§§•¢•Û•œ•√•‘©` °Ò ¿ÌœÎµƒ§∏§„§ §§»À§œ∂ý§§ °Ò ∆’Õ®§ŒÈ_∞k°¢þ\”√§¨§«§≠§ §§§»§≥§¶§ §Î ’œ∫¶§‰•–•∞åùèÍ°¢ Àòîâ‰∏¸§ÀƒÕ§®§È§Ï§ §Ø§ §Î °Ò §≥§ŒÉP§≠∑Ω§«§œ—} ˝•Ø•È•§•¢•Û•»§»“ªæw§À À ¬§Ú§π§Î§≥§»§œ§«§≠§ §§ °Ò •—•’•©©`•Þ•Û•π(§™Ωo¡œ)§À¥Û§≠§ ≤Ó§¨≥ˆ§Î °Ò •«©`•ø•µ•§•®•Û•∆•£•π•»§»§∑§∆ ≥§Ÿ§∆§§§Ø§ø§·§À§œ ¡º§§•¢•◊•Í•±©`•∑•Á•Û•®•Û•∏•À•¢§«§¢§Î§´°¢§œ≤ªø…«∑§ “™Àÿ
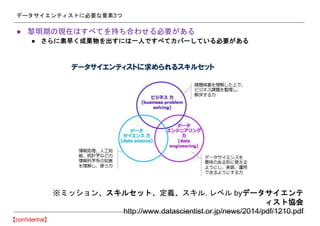
- 53. •«©`•ø•µ•§•®•Û•∆•£•π•»§À±ÿ“™§ “™Àÿ3§ƒ °˘•þ•√•∑•Á•Û°¢•π•≠•Î•ª•√•»°¢∂®¡x°¢•π•≠•Î. •Ï•Ÿ•Î by•«©`•ø•µ•§•®•Û•∆ •£•π•»Öfª· http://www.datascientist.or.jp/news/2014/pdf/1210.pdf °Ò ¿Ë√˜∆⁄§Œ¨F‘⁄§œ§π§Ÿ§∆§Ú≥÷§¡∫œ§Ô§ª§Î±ÿ“™§¨§¢§Î °Ò §µ§È§ÀÀÿ‘Á§Ø≥…π˚ŒÔ§Ú≥ˆ§π§À§œ“ª»À§«§π§Ÿ§∆•´•–©`§∑§∆§§§Î±ÿ“™§¨§¢§Î
- 55. ågŒÒ§¨“ª∑¨
- 56. §ƒ§Þ§Í°≠ “™Àÿ in •«©`•ø•µ•§•®•Û•π À ¬ •”•∏•Õ•π¡¶ •µ©`•”•π‘O”ã°¢“™º˛∂®¡x°¢•‚•«•Îþx∂® •«©`•ø•µ•§•®•Û•π¡¶ ôC–µ—ß¡ï•‚•«•Î§Œåg◊∞°¢’쌃’i§ý •«©`•ø•®•Û•∏•À•¢•Í•Û•∞¡¶ •¢•◊•Í•±©`•∑•Á•Û°¢APIÈ_∞k°¢þ\”√
- 57. •«©`•ø•µ•§•®•Û•∆•£•π•»§À±ÿ“™§ “™Àÿ3§ƒ§¨…̧À◊≈§Ø¨Fàˆ °Ò ¥Û—ß°¢¥Û—ß‘∫ °Ò ˝—ß°¢ôC–µ—ß¡ï§Ú…̧À◊≈§±§Î °Ò ’쌃§Ú’i§Û§¿§Èåg◊∞§«§≠§Î °Ò ¥Û∆ÛòI°¢÷–∆ÛòI °Ò È_∞k°¢þ\”√§Œª˘µA§Ú…̧À◊≈§±§Î °Ò ∏þÀŸ§ È_∞k§»»ð“◊§ þ\”√°¢§§§Ô§Ê§Î§≠§Ï§§§ •≥©`•…§Ú ﯧ±§Î§Ë§¶§À§ §Î °Ò •Ÿ•Û•¡•„©`∆ÛòI °Ò ◊‘§ÈÜñÓ}Ω‚õQ§Ú§π§Î °Ò ◊‘…Á°¢•Ø•È•§•¢•Û•»§ŒÜñÓ}§Ú•«©`•ø•µ•§•®•Û•π§«§…§¶ Ω‚õQ§π§Î§´§Ú÷∞∏§«§≠§Î °Ò ÷–¥Âƒ¡àˆ°¢Splink °Ò ∂ý∑N∂ýòî§ •Ø•È•§•¢•Û•»§»§π§Ÿ§∆§Œ§≥§»§¨§«§≠§Î£° °Ò •«©`•ø•µ•§•®•Û•∆•£•π•»§Œ•—•§•™•À•¢§À§ §Î °˘ÇÄ»À§Œ∏–œÎ§«§π
- 59. §µ§§§¥§À 2 ≈dŒ∂§Ú≥÷§√§∆§Ø§Ï§ø»À§ÿ §‰§√§∆§þ§ø§§»À§«—ß…˙§Œ»À : •§•Û•ø©`•Û§√§ð§§§Œ§¨§¢§Î§Œ§«§‰§√§∆§þ§Þ§ª§Û§´ §‰§√§∆§þ§ø§§»À§«ÉP§§§∆§Î»À : ∏±òI§∑§∆§þ§Þ§ª§Û§´ §‰§√§∆§þ§ø§§»À§«Ω箧∆”˚§∑§§»À: €” ¬òI º§·§Þ§∑§ø°£ Ч±§∆§Ø§¿§µ§§ ∫Œ§´•«©`•ø§«¿ß§√§∆§§§Î»À : ¡¶§À§ §Í§Þ§π°£§™‘í§Ú¬Ñ§´§ª§∆§Ø§¿§µ§§ …Áƒ⁄§Œ»À≤ƒ§Ú”˝≥…§∑§ø§§∑Ω : …ÁÕ‚œÚ§±§Œ√„è䪷, π≤Õ¨È_∞kµ»§¢§Í§Þ§π§Œ§« «∑«§¥¿˚”√§Ø§¿§µ§§
- 60. ¬÷’iª·§Œòî◊”
- 61. €”§Œòî◊”