3žě• ŽćįžĚīŪĄį žąėžßĎ, ž†ēž†úžóźžĄú Ž∂ĄžĄĚÍĻĆžßÄ
‚ÄĘDownload as PPTX, PDF‚ÄĘ
9 likes‚ÄĘ5,108 views

žąėžóÖ ž§ĎÍįĄ ŪēĄÍłįŽŹĄ ŪŹ¨Ūē®ŽźėžĖī žěąžäĶŽčąŽč§.








































![value.replace("ŪäĻŽ≥Ąžčú","ŪäĻŽ≥Ąžčú ").replace("
ÍīĎžó≠žčú","ÍīĎžó≠žčú ").replace("ŽŹĄ","ŽŹĄ
").replace("žėĀŽŹĄ ÍĶ¨","žėĀŽŹĄÍĶ¨").split(" ")[0]
žĽīŪď®ŪĄį žĖłžĖīŽäĒ žąúžĄúŽ•ľ žÖÄ ŽēĆ
1Ž∂ÄŪĄį žĄłŽäĒ Í≤ÉžĚī žēĄŽčąŽĚľ 0Ž∂ÄŪĄį žĄľŽč§.
ŽāėŽäĒ ŪēôžÉĚžě֎蹎č§
ŽāėŽäĒ=0
Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį](https://image.slidesharecdn.com/3-150526151430-lva1-app6892/85/3-49-320.jpg)
![value.partiton(/^.{4}žčú|^.{2,}ŽŹĄ/)[1]
žĚĄ žěÖŽ†•ŪĖąžĚĄŽēĆŽŹĄ ŽėĎÍįôžĚī
ž≤ęŽ≤ąžßł Ž¨łžěźžóīžĚł ‚Äėžčú‚ÄôŽ•ľ Íłįž§ÄžúľŽ°ú ŽāėŽą†žßĄŽč§.
Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį](https://image.slidesharecdn.com/3-150526151430-lva1-app6892/85/3-50-320.jpg)


![value.replace("ŪäĻŽ≥Ąžčú","ŪäĻŽ≥Ąžčú ").replace("ÍīĎ
žó≠žčú","ÍīĎžó≠žčú ").replace("ŽŹĄ","ŽŹĄ ").replace("
žėĀŽŹĄ ÍĶ¨","žėĀŽŹĄÍĶ¨").split(" ")[0]
Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį](https://image.slidesharecdn.com/3-150526151430-lva1-app6892/85/3-53-320.jpg)




![value.split("|")[0]+"."+value.split("|")[1]+
value.split("|")[2]
Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį](https://image.slidesharecdn.com/3-150526151430-lva1-app6892/85/3-58-320.jpg)
![Split :
ÍīĄŪėłžēąžĚė Ž¨łžěźŽ•ľ ‚Äú.‚ÄĚŽ°ú ž≤ėŽ¶¨ ŪēėŽĚľŽäĒ žĚėŽĮł
value.split("|")[0]+"."+value.split("|")[1]+
value.split("|")[2]
Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį](https://image.slidesharecdn.com/3-150526151430-lva1-app6892/85/3-59-320.jpg)
![cells["žúĄŽŹĄ"].value+
" "+cells["Í≤ĹŽŹĄ"]
.value
Refine žĻľŽüľÍ≥ľ žĻľŽüľžĚĄ Ūē©žĻėŽäĒ ÍłįŽä•](https://image.slidesharecdn.com/3-150526151430-lva1-app6892/85/3-60-320.jpg)
















3žě• ŽćįžĚīŪĄį žąėžßĎ, ž†ēž†úžóźžĄú Ž∂ĄžĄĚÍĻĆžßÄ
- 2. 3.1~3.4
- 3. žĚīŪēī ŽČīžä§žôÄ ŽćįžĚīŪĄįŽ•ľ žóįÍ≤į žßÄžĖī žÉĚÍįĀŪēī Ž≥īÍ≥†, ž∑®žě¨žôÄ ž†úžěĎžóź ŽćįžĚīŪĄįžĚė ž†ēŽüČ Ž∂ĄžĄĚÍ≥ľ žčúÍįĀŪôĒžĚė ŪěėžĚĄ ž†ĀÍ∑Ļž†ĀžĚīÍ≥† Ūö®Í≥ľž†ĀžúľŽ°ú Ūôúžö©ŪēėŽ†§ŽäĒ žěźžĄł ŽćįžĚīŪĄį ŽßąžĚłŽďúÍįÄ ÍįĖž∂įžßĄ Íłįžěź ‚ÄĘ žú†žö©Ūēú ŽćįžĚīŪĄįÍįÄ žĖīŽĒĒžóĒÍįÄ ž°īžě¨Ūē† Í≤ÉžĚīŽĚľŽäĒ ž†Ąž†úŪēėžóź žĚľžĚĄ žčúžěĎ ‚ÄĘ ž†ēŽ∂ÄžĚė Í≥ĶÍ≥ĶÍłįÍīÄžĚė ž†ēžĪÖ ž†ēŽ≥īžôÄ Žßąžį¨ÍįÄžßÄŽ°ú Í≥ĶÍ≥Ķ ŽćįžĚīŪĄį žó≠žčú ÍĶ≠ŽĮľžĚė žēĆ Í∂ĆŽ¶¨ žį®žõźžóźžĄú ŽčĻŽčĻŪēėÍ≤Ć žöĒÍĶ¨ŪēėÍ≥† Ūôúžö©Ūē† Í∂ĆŽ¶¨ÍįÄ žěąŽč§ŽäĒ ž†źžĚĄ Ž∂ĄŽ™ÖŪěą žĚłžßÄŪēėÍ≥† žěąžĖīžēľ ŪēúŽč§. ‚ÄĘ ž∑®žě¨ž≤ėžóź Ž¨īžä® ŽćįžĚīŪĄįÍįÄ ž°īžě¨ŪēėÍ≥† žĖīŽĖĽÍ≤Ć ÍĶ¨Ūē† žąė žěąŽäĒžßÄ ŪĆĆžēÖŪēėŽäĒ ŪēúŪéł žěźžč†ŽßĆžĚė ž∑®žě¨ ŽćįžĚīŪĄįŽ≤†žĚīžä§Ž•ľ ÍĶ¨ž∂ēŪēī Ž∂ÄÍįÄÍįÄžĻėŽ•ľ ŽÜížĚīŽ†§Í≥† ŪēúŽč§. ‚ÄĘ Ž≥īž°įž†Ā žąėŽč®žĚė ŪÜĶÍ≥ĄžěźŽ£Ć žį®žõźžĚī žēĄŽčĆ ŽćįžĚīŪĄįŽ•ľ ÍłįŽįėŪēú Íłįžā¨Ž•ľ žďīŽč§.
- 4. žĚīŪēī „ÄéžěźŽ£Ć žěÖžąėžĚė Íłįžą†(The Art of Access„ÄŹ (ŽĮłÍĶ≠žĚė ž†ēŽ≥īÍ≥ĶÍįú ž†ĄŽ¨łÍįĞ̳ ŽĮłž£ľŽ¶¨ ŽĆÄŪēôÍĶźžĚė žįįžä§ ŽćįžĚīŽĻĄŽďú ÍĶźžąė, žēĄŽ¶¨ž°įŽāė ŽĆÄŪēôÍĶźžĚė ŽćįžĚīŽĻĄŽďú žĽ¨Ž¶¨žĖī ÍĶźžąė) ŪÉźžā¨ Ž≥īŽŹĄ ž†ĄŽ¨ł ÍłįžěźŽď§žĚė Ž¨łžĄú ž∂Ēž†Ā ÍłįŽ≤ē(Ž¨łžĄú ŽßąžĚłŽďú)žĚė ŽćįžĚīŪĄį ž∑®žě¨ žóź ž†ĎŽ™©ŪēīŽŹĄ Ūö®Í≥ľŽ•ľ ŽįįÍįÄ Ūē† žąė žěąŽč§, žěźŽ£Ć ž∂Ēž†Ā ŪēėÍłį ž†Ą ž∑®žě¨ŪēėŽäĒ ÍłįÍīÄžĚė žĄĪÍ≤©, žóÖŽ¨īžóź ÍīÄŪēī žěźŽ¨łžěźŽčĶ! 1. Ž¨īžä® žĚľžĚĄ ŪēėŽäĒ ÍłįÍīĞ̳ÍįÄ? 2. žĖīŽäź žā¨žóÖžóź žĖīŽĖ§ žėąžāįžĚĄ žßÄž∂úŪēėŽāė? 3. žĚī ÍłįÍīÄžĚī ÍįźŽŹÖŪēėÍ≥† Í∑úž†úŪēėŽäĒ žėĀžó≠žĚÄ? 4. ŽąĄÍįÄ žěźŽ£ĆŽ•ľ žÉĚžāįŪēėŽāė? 5. ÍłįÍīĞ󟞥ú ž†ēÍłįž†ĀžúľŽ°ú ŽįúŪĎúŪēėŽäĒ ŪÜĶÍ≥ĄžěźŽ£ĆŽäĒ? 6. žĚī ÍłįÍīĞ󟞥ú Ž¨łžĄúŽ•ľ Í≥Ķžú†ŪēėŽäĒ Žč§Ž•ł ÍłįÍīÄžĚÄ žĖīŽĒĒžĚłÍįÄ?
- 5. žĚīŪēī ŪÉźžā¨ Ž≥īŽŹĄ ž†ĄŽ¨ł Íłįžěź ŽŹą Ž†ąžĚīžĚė Ž¨łžĄú ž≤īŪĀ¨Ž¶¨žä§Ūäł! 1. Ž∂ÄŽ™®ŽčėžĚÄ ŽąĄÍĶ¨žĚłÍįÄ? (ŽąĄÍįÄ ŽßĆŽď† žěźŽ£ĆžĚłÍįÄ?) 2. žĖłžě¨ ŪÉúžĖīŽā¨Žāė? (žĖłž†ú ŽßƎ吏Ėīž°ĆÍ≥† žěźŽ£Ć ÍįĪžč† ž£ľÍįÄŽäĒ?) 3. žā¨žö©ŪēėŽäĒ žĖłžĖīŽäĒ? (ŽćįžĚīŪĄįžóź žďįžĚł žö©žĖīžĚė žĚėŽĮłŽäĒ>) 4. Í≤įŪėľ ŪĖąŽāė? Ūėēž†úŽäĒ žóÜŽāė? (žóįÍ≥ĄŽźú Žč§Ž•ł ŽćįžĚīŪĄįŽäĒ žóÜŽäĒÍįÄ?) 5. žĖīŽĖĽÍ≤Ć žó¨Íłįžóź žė§Í≤Ć ŽźźŽāė? (žěźŽ£Ć žÉĚžĄĪžĚė ŪĚźŽ¶ĄžĚÄ?) 6. žą®ÍłįÍ≥† žěąŽäĒ ÍĪī žóÜŽäĒÍįÄ? (žěźŽ£Ć Ūēú žľ†žóź žą®Í≤®žßĄ žěĎžĚÄ ÍłÄžĒ®Žāė žĹĒŽďúŽäĒ žóÜ Žāė? Í∑ł žĚėŽĮłŽäĒ?) „ÄéžěźŽ£Ć žěÖžąėžĚė Íłįžą†(The Art of Access„ÄŹ (ŽĮłÍĶ≠žĚė ž†ēŽ≥īÍ≥ĶÍįú ž†ĄŽ¨łÍįĞ̳ (ž†ÄŽĄźŽ¶¨ž¶ė)ŽĮłž£ľŽ¶¨ ŽĆÄŪēôÍĶź-ŪēúÍĶ≠žĖłŽ°†žě¨ Žč® žóįžąėžĚė žįįžä§ ŽćįžĚīŽĻĄŽďú ÍĶźžąė, žēĄŽ¶¨ž°įŽāė ŽĆÄŪēôÍĶźžĚė ŽćįžĚīŽĻĄŽďú žĽ¨Ž¶¨žĖī ÍĶźžąė) ŪÉźžā¨ Ž≥īŽŹĄ ž†ĄŽ¨ł ÍłįžěźŽď§žĚė Ž¨łžĄú ž∂Ēž†Ā ÍłįŽ≤ēžĚė ŽćįžĚīŪĄį ž∑®žě¨žóź ž†ĎŽ™©ŪēīŽŹĄ Ūö®Í≥ľŽ•ľ ŽįįÍįÄ Ūē† žąė žěąŽč§,
- 6. žĚīŪēī Ž¨łžĄúŽäĒ ŽßĆŽď† žā¨ŽěĆžĚė žĚėŽŹĄžĄĪžóź ŽĒįŽĚľ Í∑ł žĄĪÍ≤©žĚī Žč¨ŽĚľžßĄŽč§. 1. ŽąĄÍįÄ Ž¨īžä® Ž™©ž†ĀžúľŽ°ú žěĎžĄĪŪēú Í≤ɞ̳žßÄŽ•ľ ŪĆĆžēÖ 2. žĖłž†ú ŽßƎ吏Ėīž°ĆÍ≥†, žĖīŽäź ž†ēŽŹĄ ž£ľÍłįŽ°ú ÍįĪžč†ŽźėŽäĒ žěźŽ£ĆžĚłžßÄŽŹĄ ž†ēŪôēŪěą žąôžßÄ 3. ŽćįžĚīŪĄįŽ≤†žĚīžä§žĚė ÍįĀ Ūē≠Ž™©žĚī ŽúĽŪēėŽäĒ žĚėŽĮłŽäĒ Ž¨īžóážĚłžßÄŽŹĄ ž†ēŪôēŪěą žąôžßÄ žĚīžôÄ ÍįôžĚÄ ‚ÄėŽćįžĚīŪĄįžóź ÍīÄŪēú ŽćįžĚīŪĄį‚ÄôžĚĄ Ž©ĒŪÉÄŽćįžĚīŪĄįŽĚľÍ≥† ŪēúŽč§. ‚ąī ŽćįžĚīŪĄį ŽßąžĚłŽďúŽäĒ Ž∂ĄžĄĚŽŹĄÍĶ¨žóź žĚĶžąôŪē†žąėŽ°Ě ŽćĒ ÍĻäžĖīžßĄŽč§.
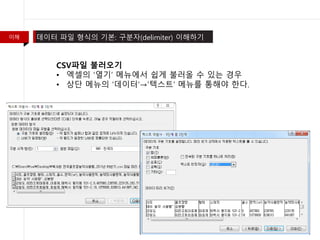
- 7. žĚīŪēī ŽćįžĚīŪĄį ŪĆƞ̾ ŪėēžčĚžĚė ÍłįŽ≥ł: ÍĶ¨Ž∂Ąžěź(delimiter) žĚīŪēīŪēėÍłį ÍįÄžě• ŽĄźŽ¶¨ žā¨žö©ŽźėŽäĒ žóĎžÖÄ žė§ŪĒľžä§ 2007ŽÖĄ Ž≤Ąž†Ą žĚīŪõĄžóźžĄú žā¨žö©ŪēėŽäĒ .xlxs(žóĎžÖÄ ŪÜĶŪē©Ž¨łžĄú) 2003ŽÖĄ žĚīž†Ą ÍĶ¨ Ž≤Ąž†ĄžóźžĄú žā¨žö©ŪēėŽćė .xlsÍįÄ žěąŽč§. žóĎžÖÄžĚė ŽĆÄžö©žĚł Ž¨īŽ£Ć ‚ÄėOpen Office Calc‚Äô .odsŪôēžě•žěźžĚė ODF ŪĆƞ̾žĚĄ žÉĚžĄĪŪēúŽč§. CSV Žč§žĚĆžúľŽ°ú ŽßéžĚī žā¨žö©ŽźėŽäĒ ŪĆƞ̾žĚÄ ŪÉ≠(tab) (TAB-Delimited Text File)žĚīŽč§.
- 8. žĚīŪēī ŽćįžĚīŪĄį ŪĆƞ̾ ŪėēžčĚžĚė ÍłįŽ≥ł: ÍĶ¨Ž∂Ąžěź(delimiter) žĚīŪēīŪēėÍłį žä§ŪĒĄŽ†ąŽďú žčúŪäł ŽßĆŪĀľ žā¨žö©ŽźėŽäĒ CSV(Comma-Separated Value) ͳĞ쟞ôÄ žąęžěź Žč®ŽĚĹŽßąŽč§ žČľŪĎú(Comma)ÍįÄ Žď§žĖīÍįÄ žěąŽč§. CSVžóźžĄúŽäĒ žČľŪĎúÍįÄ ŽćįžĚīŪĄįžôÄ ŽćįžĚīŪĄįŽ•ľ ÍĶ¨Ž∂ĄŪēúŽč§. žĚīžôÄ ÍįôžĚÄ žČľŪĎúžĚė žó≠Ūē†žĚĄ ÍĶ¨Ž∂Ąžěź ŪėĻžĚÄ Ž∂ĄŽ¶¨žěź(Delimiter, Separator)ŽĚľÍ≥† ŪēúŽč§.
- 9. žĚīŪēī ŽćįžĚīŪĄį ŪĆƞ̾ ŪėēžčĚžĚė ÍłįŽ≥ł: ÍĶ¨Ž∂Ąžěź(delimiter) žĚīŪēīŪēėÍłį CSVŪĆƞ̾ Ž∂ąŽü¨žė§Íłį ‚ÄĘ žóĎžÖÄžĚė ‚ÄėžóīÍłį‚Äô Ž©ĒŽČīžóźžĄú žČĹÍ≤Ć Ž∂ąŽü¨žė¨ žąė žěąŽäĒ Í≤Ĺžöį ‚ÄĘ žÉĀŽč® Ž©ĒŽČīžĚė ‚ÄėŽćįžĚīŪĄį‚Äô‚Üí‚ÄôŪÖćžä§Ūäł‚Äô Ž©ĒŽČīŽ•ľ ŪÜĶŪēīžēľ ŪēúŽč§.
- 10. žĚīŪēī ŽćįžĚīŪĄį ŽįŹ žěźŽ£Ć žąėžßĎ 1. ÍłįŪöć 2. ŽćįžĚīŪĄį žąėžßĎ 3. ŽćįžĚīŪĄį ž†ēŽ¶¨ ŽįŹ ž†ēž†ú(ÍįÄžě• ŽßéžĚÄ žčúÍįĄÍ≥ľ ŽÖłŽ†•žĚī ŪēĄžöĒŪēú Ž∂ÄŽ∂Ą) ‚Üížė¨ŽįĒŽ•ł Ž∂ĄžĄĚÍ≥ľ žčúÍįĀŪôĒŽ•ľ žúĄŪēīžĄúŽäĒ ŽįėŽďúžčú ÍĪįž≥źžēľ ŪēėŽäĒ žěĎžóÖ 4. ŽćįžĚīŪĄį Ž∂ĄžĄĚÍ≥ľ žčúÍįĀŪôĒ 5. ŪėĄžě• ž∑®žě¨ Ž≥ĎŪĖČ 6. Žį©žÜ°, žč†Ž¨ł ŪėĻžĚÄ žõĻ žĹėŪÖźžł† ž†úžěĎ (žąúžĄúŽäĒ Í≥†ž†ē Ž∂ąŽ≥ÄŪēú Í≤ÉžĚÄ žēĄŽčė. žÉĀŪô©žóź Žßěž∂į žěĎžóÖ žąúžĄúÍįÄ ŽįĒŽÄĆÍĪįŽāė žó¨Žü¨ ÍįÄžßÄ žěĎžóÖ žĚī ŽŹôžčúžóź žßĄŪĖČŽźėÍłįŽŹĄ ŪēúŽč§.) žēĄŽ¨īŽ¶¨ ŽĻĄžčľ ŽŹĄÍĶ¨žôÄ žĘčžĚÄ žÜƞ쨎°ú Ž∂ĄžĄĚŪēúŽč§Í≥† ŪēėŽćĒŽĚľŽŹĄ, Ž∂Äž†ēŪôēŪēú ŽćįžĚīŪĄįŽ°ú žěĎžó̥֞ ŪēėŽ©ī žēĄŽ¨ī žÜĆžö©žĚī žóÜŽč§. žė§Ž•ėŽ•ľ žēąÍ≥† žěąŽäĒ ŽćįžĚīŪĄįŽ•ľ Ūą¨žěÖŪēėŽ©ī, žė§Ž•ė Ūą¨žĄĪžĚīžĚė Í≤įÍ≥ľŽ•ľ Žā≥žĚĄ žąė ŽįĖžóź žóÜŽč§.
- 11. žĚīŪēī ŽćįžĚīŪĄį žąėžßĎžĚė 6ÍįÄžßÄ Žį©Ž≤ē 1. ŪėĄžě• ž∑®žě¨ ŽćįžĚīŪĄį žßĀž†Ď žěÖžąė 2. žĚłŪĄįŽĄ∑žÉĀžóźžĄú Í≤ÄžÉČžúľŽ°ú žěźŽ£Ć ž∑®ŽďĚ 3. ž†ēŽ≥īÍ≥ĶÍįú ž≤≠ÍĶ¨ 4. Í≥ĶÍįú API Ūôúžö© Ž≥Ą 4ÍįúžßúŽ¶¨ 5. žõĻžä§ŪĀ¨Ž†ąžĚīŪēĎ(Web Scraping, Web Crawlng) 6. ŽćįžĚīŪĄįŽ≤†žĚīžä§ žěźž≤ī ÍĶ¨ž∂ē <Í∑ĻŪěą žėąžôłž†ĀžĚł Ūēú ÍįÄžßÄ žā¨Ž°Ä> žõĻžä§ŪĀ¨Ž†ąŪēĎ žā¨Ž°Ä ‚ÄúŽĮłÍĶ≠ žĖłŽ°†žĚłžĚī žõĻžä§ŪĀ¨Ž†ąžĚīŪēĎžúľŽ°ú žĚłŪēīžĄú Ž≤ēž†ē ŽÖľŽěÄ‚ÄĚ ŽĮłÍĶ≠žĚė ‚Äėžä§ŪĀ¨Ž¶Ĺžä§ ŪēėžõĆŽďú ŽČīžä§(Scripps Howaed News Service)‚ÄôžĚė ž∑®ž†ú Íłįžěź žēĄžĚīžěĎ žöłŪĒĄ(Issac Wolf) http://www.niemanlab.org/tag/isaac-wolf/ Ž≤ēž†Ā žú§Ž¶¨ž†ĀžúľŽ°ú ÍįąŽďĪžĚė žÜĆžßÄÍįÄ žóÜŽäĒžßÄŽäĒ žĘÄ ŽćĒ žā¨ŪöĆž†Ā ŽÖľžĚėžôÄ Ūē©žĚėÍįÄ ŪēĄžöĒŪēú Ž∂ÄŽ∂ĄžĚīžßÄŽßĆ, žöįŽ¶¨Žāė ŽĚľžĚė ŽćįžĚīŪĄį Ž∂ĄžĄĚÍįÄžôÄ ÍłįžóÖ, žóįÍĶ¨ÍłįÍīĎ硫ŹĄ žĚīŽĮł žõĻžä§ŪĀ¨Ž†ąžĚīŪēϞ̥ ŪŹ≠ŽĄďÍ≤Ć Ūôúžö©ŪēėÍ≥† žěąŽč§. ŽĆÄŽ∂ÄŽ∂ĄžĚė žõĻžä§ŪĀ¨Ž†ąžĚīŪēĎžĚÄ ŪäĻž†ē žā¨žĚīŪäłžĚė Í≥ĶžčĚž†ĀžĚł ŪóąŽĚŞ̥ ŽįõžßÄ žēäÍ≥†, ŪÜĶžÉĀž†ĀžĚł Žį©Ž≤ēÍ≥ľŽäĒ Žč§Ž•ł Í≤Ĺ Ž°úŽ°ú ŽćįžĚīŪĄįŽ•ľ žąėžßĎŪēėÍ≤Ć ŽźúŽč§. žĚī ŽēĆŽ¨łžóź žõźžĻôž†ĀžúľŽ°úŽäĒ ŪēīŽčĻ ÍłįÍīÄžóź ŽćįžĚīŪĄį ŪĆƞ̾ ž†úÍ≥ĶžĚĄ žßĀž†Ď žöĒ ž≤≠ŪēėŽäĒ ŽďĪ ÍįÄŽä•Ūēú Ž™®Žď† žąėžßĎŽį©Ž≤ēžĚĄ žčúŽŹĄŪēī Ž≥ł Žč§žĚĆ ŽßąžßÄŽßČ ŽĆÄžēąžúľŽ°ú žā¨žö© or ŽĮłŽ¶¨ ŪēīŽčĻ ÍłįÍīÄžóź ŪÜĶ žßÄŪēėŽäĒ Í≤ÉžĚī ŽįĒŽěĆžßĀŪēėŽč§.
- 12. žĚīŪēī ŽćįžĚīŪĄį žąėžßĎžĚė 6ÍįÄžßÄ Žį©Ž≤ē Žėź ŪēėŽāėžĚė Žį©Ž≤ē, ÍĶ¨ÍłÄ Í≥†ÍłČÍ≤ÄžÉČ ‚ÄúF-35A‚ÄĚŽ≤ĒžúĄŽ•ľ žĘĀŪėÄž§Ć filetype:pdfŪĒľŽĒĒžóźŪĒĄŪĆƞ̾ŽßĆ site:govž†ēŽ∂ÄÍłįÍīÄ žā¨žĚīŪäł žĚłŪĄįŽĄ∑žÉĀžóźŽäĒ Í≤ÄžÉČžóĒžßĄžĚė Ž†ąžĚīŽćĒŽßĚžóźŽäĒ ŪŹ¨žį©ŽźėžßÄ žēäŽäĒ žą®Í≤®žßĄ Í≥†ÍłČ ž†ēŽ≥īŽŹĄ Ž¨īžąėŪěą ŽßéŽč§. ‚ÄúŽ≥īžĚīžßÄ žēäŽäĒ žõĻ(Invisible Web)‚ÄĚžĚī Í∑łÍ≤ÉžĚīŽč§. ŪĒĄŽ¶¨ž¶ė : ÍĶ≠Žāī ÍįĀžĘÖ ž†ēŽ∂Ä žö©žó≠ Ž≥īÍ≥†žĄú ž†úžĚłžä§ žóįÍįź : Ūēīžôł žā¨žĚīŪ䳞󟞥ú Ž¨īÍłįžóź ŽĆÄŪēú žÉĀžĄłŪēú ž†ēŽ≥ī Lexisnexis : ÍłįžóÖ ÍįĄžĚė žÜƞܰžóź ŽĆÄŪēú ž†ēŽ≥ī, Ž≤ēŽ•†ž†ēŽ≥ī *žú†Ž£ĆžôÄ Ž¨īŽ£ĆÍįÄ žĄěžó¨ žěąžúľŽčą žĄ†Ž≥ĄŪēīžĄú žā¨žö©! žĖłŽ°†žßĄŪĚ•žě¨Žč® ŽďĪ ŪÉźžā¨ Ž≥īŽŹĄ ŪėĻžĚÄ ŽćįžĚīŪĄį ž†ÄŽĄźŽ¶¨ž¶ė ÍĶźžú° ŪĒĄŽ°úÍ∑łŽě®žĚė ÍįēžĘĆŽ•ľ ŪÜĶ Ūēī Í≤ÄžÉČ ŽÖłŪēėžöįžôÄ ÍīÄŽ†®Žźú ž†ēŽ≥īŽ•ľ žĖĽžĚĄ žąė ŽŹĄ žěąŽč§.
- 13. 3.5
- 14. žĚīŪēī žēľŪõĄ ŪĆĆžĚīŪĒĄ žĚīžö©ŪēėÍłį žēľŪõĄŪĆĆžĚīŽłĆ žěĎžóÖžįĹ
- 15. žĚīŪēī žēľŪõĄ ŪĆĆžĚīŪĒĄ žĚīžö©ŪēėÍłį žēľŪõĄ ŪĆĆžĚīŪĒĄ Ž™®Žďą ÍĶ¨žĄĪŪôĒŽ©ī
- 16. žĚīŪēī žēľŪõĄ ŪĆĆžĚīŪĒĄ žĚīžö©ŪēėÍłį žēľŪõĄŪĆĆžĚīŪĒĄ ŪēĄŪĄį Ž™®Ūä§
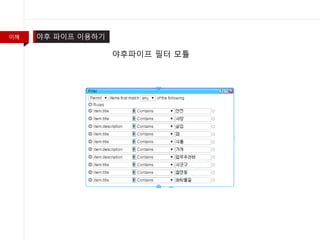
- 17. žĚīŪēī žēľŪõĄ ŪĆĆžĚīŪĒĄ žĚīžö©ŪēėÍłį RSS ŪĒľŽďú ŪēĄŪĄįŽßĀž†ēŽ†¨žö© žēľŪõĄ ŪĆĆžĚīŪĒĄ Ž™®Žďą ÍĶ¨žĄĪ
- 18. žĚīŪēī žēľŪõĄ ŪĆĆžĚīŪĒĄ žĚīžö©ŪēėÍłį Ž™®Žďą žč§ŪĖČ Í≤įÍ≥ľ RSS ŪĒľŽďú Ž∂ąŽü¨žė® Ž™®žäĶ
- 19. 3.7~3.10
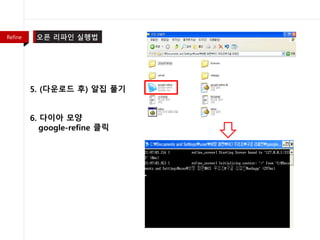
- 20. 1. ŪôąŪéėžĚīžßÄ(openrefine.org) ž†ĎžÜć 2. Žč§žöīŽ°úŽďú 3. Window kit Žč§žöīŽ°úŽďú 4. (žěźŽįĒ ŪĒĄŽ°úÍ∑łŽě®žĚī ÍĻĒŽ†§ žěąžßÄ žēäžúľŽ©ī žěźŽįĒ ŪĒĄŽ°úÍ∑łŽě® Žč§žöī) Refine
- 21. 5. (Žč§žöīŽ°úŽďú ŪõĄ) žēĆžßĎ ŪíÄÍłį 6. Žč§žĚīžēĄ Ž™®žĖĎ google-refine ŪĀīŽ¶≠ Refine
- 22. 7. ŪĆƞ̾ žĄ†ŪÉĚ ŪĀīŽ¶≠ 8. ž†ú3žě• šł≠ ‚ÄúžĄúžöłžčúŽŹĄŽ°úžčúžĄ§Ž¨ľ‚ÄĚ ŪĀīŽ¶≠ Refine
- 23. 9. NEXT ŪĀīŽ¶≠. 10. Project name žĄ§ž†ē ŪõĄ Create project ŪĀīŽ¶≠ Refine
- 24. Refine : Record -> rows ŽįĒÍĺłÍłį
- 25. žčúžĄ§Ž¨ľŽ™Ö -> Facet -> Text facet ŪĀīŽ¶≠Refine
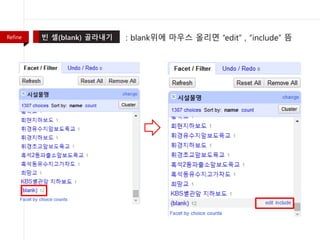
- 26. Refine : name -> count ŪĀīŽ¶≠
- 27. : blankžúĄžóź Žßąžöįžä§ žė¨Ž¶¨Ž©ī ‚Äúedit‚ÄĚ , ‚Äúinclude‚ÄĚ ŽúłRefine
- 28. : (žĘĆ) ‚Äúinclude‚ÄĚ ŪĀīŽ¶≠ : (žöį) ‚Äúedit‚ÄĚ ŪĀīŽ¶≠ ŪõĄ -> ‚ÄúžĚīŽ¶ĄžóÜŽäĒ žčúžĄ§Ž¨ľ‚ÄĚ žěĎžĄĪ ŪõĄ -> apply ŪĀīŽ¶≠ Refine
- 29. : (žĘĆ) exclude ŪĀīŽ¶≠ : (žöį) Ž¨īŽ™ÖÍĶź -> ‚Äúedit‚ÄĚ -> žĚīŽ¶ĄžóÜŽäĒ žčúžĄ§Ž¨ľŽ°ú Ž≥ÄÍ≤Ĺ Refine
- 30. : žĚīŽ¶ĄžóÜŽäĒ žčúžĄ§Ž¨ľ žóÜžē†ŽäĒ Ž≤ē žĚīŽ¶ĄžóÜŽäĒ žčúžĄ§Ž¨ľ -> edit -> (ŽĚĄžõĆžďįÍłį ŪēúŽ≤ą) Refine
- 31. : žĚīŽ¶ĄžóÜŽäĒ žčúžĄ§Ž¨ľ žóÜžē†ŽäĒ Ž≤ēRefine (žĘĆ) ŽĻąžĻł žöįžł°žĚė ‚Äúinclude‚ÄĚ ŪĀīŽ¶≠ (žöį) žčúžĄ§Ž¨ľŽ™Ö -> edit cells -> common transforms -> blank out cells
- 32. : (žĘĆ) žÜĆžú†žěź -> facet -> text facel : (žöį) ÍįôžĚÄ Í≥≥žĚīžßÄŽßĆ (‚ÄúÍįēŽ∂ĀÍĶ¨ž≤≠‚ÄĚ=‚ÄúÍįēŽ∂ĀÍĶ¨ž≤≠žě•‚ÄĚ) Žč§Ž•ł ŪĎúÍłį ŽįúÍ≤¨ Refine
- 33. : (žĘĆ) ÍįēŽ∂ĀÍĶ¨ž≤≠žóź Žßąžöįžä§ žĽ§žĄú žė¨Ž¶į Ží§ -> edit ŪĀīŽ¶≠ : (žöį) ÍįēŽ∂ĀÍĶ¨ž≤≠ -> ÍįēŽ∂ĀÍĶ¨ž≤≠žě•žúľŽ°ú Ž≥ÄÍ≤Ĺ(apply) Refine
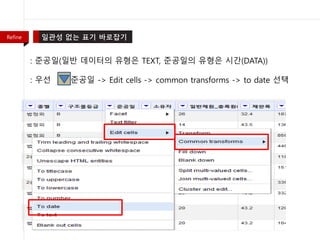
- 34. : ž§ÄÍ≥ĶžĚľ(žĚľŽįė ŽćįžĚīŪĄįžĚė žú†ŪėēžĚÄ TEXT, ž§ÄÍ≥ĶžĚľžĚė žú†ŪėēžĚÄ žčúÍįĄ(DATA)) : žöįžĄ† ž§ÄÍ≥ĶžĚľ -> Edit cells -> common transforms -> to date žĄ†ŪÉĚ Refine
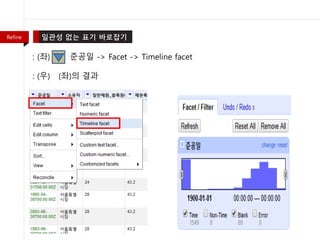
- 35. : (žĘĆ) ž§ÄÍ≥ĶžĚľ -> Facet -> Timeline facet : (žöį) (žĘĆ)žĚė Í≤įÍ≥ľ Refine
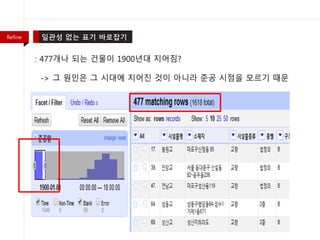
- 36. : (žĘĆ) 1900ŽÖĄŽĆÄ žßÄžĖīžßĄ ÍĪīŽ¨ľŽď§žĚī ŽßéžĚĆ(žĚīžÉĀŪē®) : (žöį) Í∑ł žĚīžú†Ž•ľ žēĆžēĄŽ≥īÍłį žúĄŪēī Ž≤ĒžúĄŽ•ľ ž§ĄžěĄ Refine
- 37. : 477ÍįúŽāė ŽźėŽäĒ ÍĪīŽ¨ľžĚī 1900ŽÖĄŽĆÄ žßÄžĖīžßź? -> Í∑ł žõźžĚłžĚÄ Í∑ł žčúŽĆÄžóź žßÄžĖīžßĄ Í≤ÉžĚī žēĄŽčąŽĚľ ž§ÄÍ≥Ķ žčúž†źžĚĄ Ž™®Ž•īÍłį ŽēĆŽ¨ł Refine
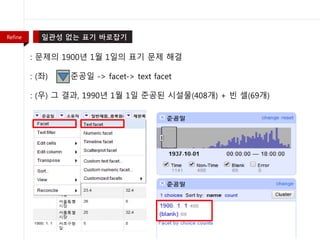
- 38. : Ž¨łž†úžĚė 1900ŽÖĄ 1žõĒ 1žĚľžĚė ŪĎúÍłį Ž¨łž†ú ŪēīÍ≤į : ž§ÄÍ≥ĶžĚľ -> edit cells -> common transforms -> to text Refine
- 39. : Ž¨łž†úžĚė 1900ŽÖĄ 1žõĒ 1žĚľžĚė ŪĎúÍłį Ž¨łž†ú ŪēīÍ≤į : (žĘĆ) ž§ÄÍ≥ĶžĚľ -> facet-> text facet : (žöį) Í∑ł Í≤įÍ≥ľ, 1990ŽÖĄ 1žõĒ 1žĚľ ž§ÄÍ≥ĶŽźú žčúžĄ§Ž¨ľ(408Íįú) + ŽĻą žÖÄ(69Íįú) Refine
- 40. : Ž¨łž†úžĚė 1900ŽÖĄ 1žõĒ 1žĚľžĚė ŪĎúÍłį Ž¨łž†ú ŪēīÍ≤į : 1990ŽÖĄ 1žõĒ 1žĚľ ž§ÄÍ≥ĶŽźú žčúžĄ§Ž¨ľ(408Íįú) + ŽĻą žÖÄ(69Íįú) -> edit -> ‚Äúž§ÄÍ≥ĶžĚľ ŽĮłŪôēžĚł‚ÄĚ žúľŽ°ú ž†Āžö© Refine
- 41. : ž§ÄÍ≥ĶžĚľ ŽĮłŪôēžĚł(477Íįú)žĚī ž†ēŪēīžßÄŽ©ī, ž§ÄÍ≥ĶžĚľ -> edit cells -> common transforms -> to number žĄ†ŪÉĚ Refine
- 42. ‚ÄĘ žė§ŪĒą Ž¶¨ŪĆƞ̳žĚĄ žā¨žö©ŪēėŽäĒ žĚīžú† : ŽćįžĚīŪĄįŽ•ľ ž†ēž†úŪēėÍłį žúĄŪēī ‚ÄĘ ŪĆĆŽěÄžÉČ(Í≤ÄžĚÄžÉČ)žĚÄ Ž¨łžěź, ŽÖĻžÉČžĚÄ žąęžěźŽāė žčúÍįĄ ŽćįžĚīŪĄįŽ•ľ ŽāėŪÉÄŽÉĄ ‚ÄĘ žÖÄžĚė žôľž™Ĺžóź Ž∂ôžĖī ŪĎúžčúŽźėŽäĒ ŽćįžĚīŪĄįŽäĒ Ž¨łžěź ŪėēŪÉú, žąėžĻėŽäĒ ŽįėŽďúžčú žąęžěź žú†Ūėē(to number)žúľŽ°ú Ūėēžč̞̥ ŽįĒÍŅĒž§ėžēľ ž†úŽĆÄŽ°ú Žźú Í≥Ąžāį ÍįÄŽä• Refine
- 43. ž†ēÍ∑úŪĎúŪėĄžčĚžĚÄ Ž¨łžěźžóīžĚė ŽįįžóīžóźžĄú žĚľž†ēŪēú ŪĆ®ŪĄīžĚĄ žįĺžēĄŽāī ŽćįžĚīŪĄį ž≤ėŽ¶¨Ž•ľ žČĹÍ≤Ć ŽßĆŽďúŽäĒ žąėŽč® Refine
- 44. Refine Ž¨łžěźžóī žā¨žĚīžĚė Í≥ĶŽįĪžĚĄ Íłįž§ÄžúľŽ°ú ‚ÄėžúĄžĻė‚Äô žĻľŽüľžĚĄ ŽĎźÍįúžĚė žĻľŽüľžúľŽ°ú Ž∂ĄŽ¶¨ŪēėÍłį
- 45. ‚Äúžčú‚ÄĚ, ‚ÄúÍĶ¨‚ÄĚÍįÄ Ž∂ĄŽ¶¨ŽźėžĖī žěąžßÄ žēäžĚĆ Refine Ž¨łžěźžóī žā¨žĚīžĚė Í≥ĶŽįĪžĚĄ Íłįž§ÄžúľŽ°ú ‚ÄėžúĄžĻė‚Äô žĻľŽüľžĚĄ ŽĎźÍįúžĚė žĻľŽüľžúľŽ°ú Ž∂ĄŽ¶¨ŪēėÍłį
- 46. value.replace("ŪäĻŽ≥Ąžčú","ŪäĻŽ≥Ąžčú ").replace(" ÍīĎžó≠žčú","ÍīĎžó≠žčú ").replace("ŽŹĄ","ŽŹĄ ").replace("žėĀŽŹĄ ÍĶ¨","žėĀŽŹĄÍĶ¨") Refine Ž¨łžěźžóī žā¨žĚīžĚė Í≥ĶŽįĪžĚĄ Íłįž§ÄžúľŽ°ú ‚ÄėžúĄžĻė‚Äô žĻľŽüľžĚĄ ŽĎźÍįúžĚė žĻľŽüľžúľŽ°ú Ž∂ĄŽ¶¨ŪēėÍłį
- 47. ‚Äúžčú‚ÄĚ,‚ÄĚÍĶ¨‚ÄĚÍįÄ Ž∂ĄŽ¶¨ŽźėžóąžĚĆ Refine Ž¨łžěźžóī žā¨žĚīžĚė Í≥ĶŽįĪžĚĄ Íłįž§ÄžúľŽ°ú ‚ÄėžúĄžĻė‚Äô žĻľŽüľžĚĄ ŽĎźÍįúžĚė žĻľŽüľžúľŽ°ú Ž∂ĄŽ¶¨ŪēėÍłį
- 48. Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 49. value.replace("ŪäĻŽ≥Ąžčú","ŪäĻŽ≥Ąžčú ").replace(" ÍīĎžó≠žčú","ÍīĎžó≠žčú ").replace("ŽŹĄ","ŽŹĄ ").replace("žėĀŽŹĄ ÍĶ¨","žėĀŽŹĄÍĶ¨").split(" ")[0] žĽīŪď®ŪĄį žĖłžĖīŽäĒ žąúžĄúŽ•ľ žÖÄ ŽēĆ 1Ž∂ÄŪĄį žĄłŽäĒ Í≤ÉžĚī žēĄŽčąŽĚľ 0Ž∂ÄŪĄį žĄľŽč§. ŽāėŽäĒ ŪēôžÉĚžěÖŽčąŽč§ ŽāėŽäĒ=0 Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 50. value.partiton(/^.{4}žčú|^.{2,}ŽŹĄ/)[1] žĚĄ žěÖŽ†•ŪĖąžĚĄŽēĆŽŹĄ ŽėĎÍįôžĚī ž≤ęŽ≤ąžßł Ž¨łžěźžóīžĚł ‚Äėžčú‚ÄôŽ•ľ Íłįž§ÄžúľŽ°ú ŽāėŽą†žßĄŽč§. Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 51. ‚ÄĘ / : ž†ēÍ∑úŪĎúŪėĄžčĚžĚė žčúžěϞ̥ žēĆŽ¶¨ŽäĒ ÍłįŪėł ‚ÄĘ ^: ž≤ę Ž≤ąžßł Žāėžė§ŽäĒ Ž¨łžěźžóī žĄúžöłŪäĻŽ≥Ąžčú ‚ÄĘ . : žēĄŽ¨ī ͳĞ쟎āė Ūēú ÍłÄžěź ‚ÄĘ {4}: žēě Ž¨łžěźžóīžĚī 4Ž≤ą ŽāėŪÉÄŽā† ŽēĆ žĄúžöłŪäĻŽ≥Ą ‚ÄĘ | : žėĀžĖīžĚė ORžôÄ ÍįôžĚÄ žĚīŽ•łŽįĒ blooean žóįžāįžěź ‚ÄĘ ^ : ž≤ę Ž≤ąžßł Žāėžė§ŽäĒ Ž¨łžěź ‚ÄĘ {2,}: žēě Ž¨łžěźžóīžĚī 2Ž≤ą žĚīžÉĀ ŽāėŪÉÄŽā† ŽēĆ ž∂©ž≤≠Ž∂ĀŽŹĄ ‚ÄĘ / : ž†ēÍ∑úŪĎúŪėĄžčĚ ŽßąŽ¨īŽ¶¨Ž•ľ žēĆŽ¶¨ŽäĒ ÍłįŪėł Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 52. Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 53. value.replace("ŪäĻŽ≥Ąžčú","ŪäĻŽ≥Ąžčú ").replace("ÍīĎ žó≠žčú","ÍīĎžó≠žčú ").replace("ŽŹĄ","ŽŹĄ ").replace(" žėĀŽŹĄ ÍĶ¨","žėĀŽŹĄÍĶ¨").split(" ")[0] Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 54. Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 55. value.replace(/d+-d+/,"") Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 56. ‚ÄĘ / : ž†ēÍ∑ú ŪĎúŪėĄžĚė žčúžěĎ ‚ÄĘ d : žąęžěź(digit) Ūēú Íįú ŪėĻžĚÄ žó¨Žü¨ Íįú ‚ÄĘ - : 1-010ž≤ėŽüľ žąęžěź žā¨žĚīžóź žúĄžĻėŪēú ‚Äď ÍłįŪėł ‚ÄĘ d+ : žąęžěźÍįÄ Ūēú Íįú ŪėĻžĚÄ žó¨Žü¨ Íįú ‚ÄĘ / : ž†ēÍ∑úŪĎúŪėĄžčĚ ŽßąŽ¨īŽ¶¨ Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 57. Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 58. value.split("|")[0]+"."+value.split("|")[1]+ value.split("|")[2] Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 59. Split : ÍīĄŪėłžēąžĚė Ž¨łžěźŽ•ľ ‚Äú.‚ÄĚŽ°ú ž≤ėŽ¶¨ ŪēėŽĚľŽäĒ žĚėŽĮł value.split("|")[0]+"."+value.split("|")[1]+ value.split("|")[2] Refine ŪäĻž†ē Ž¨łžěźŽßĆ ž∂Ēž∂ú«ÍėÍłį
- 60. cells["žúĄŽŹĄ"].value+ " "+cells["Í≤ĹŽŹĄ"] .value Refine žĻľŽüľÍ≥ľ žĻľŽüľžĚĄ Ūē©žĻėŽäĒ ÍłįŽä•
- 61. 3.11~3.15
- 62. žóĎžÖÄ žä§ŪĒĄŽ†ąŽďú žčúŪäł Ctrl + end : žĽ§žĄú žúĄžĻėŽ•ľ ŽćįžĚīŪĄįÍįížĚī žěÖŽ†•Žźú žėĀžó≠žĚė žė§Ž•łŪéł žēĄŽěėž™Ĺ ŽĀ̎讞úľŽ°ú žĚīŽŹôŪēúŽč§. Ctrl + shift + end : ŪäĻž†ē žÖĞ̥ Íłįž§ÄžúľŽ°ú žė§Ž•łž™Ĺ žēĄŽěė Žį©ŪĖ•žúľ Ž°ú ŽćįžĚīŪĄį ÍįížĚī žěÖŽ†•Žźú žėĀžó≠žĚė ŽĀĚŽč®ÍĻĆžßÄŽ•ľ Ž™®ŽĎź žĄ†ŪÉĚŪēúŽč§. Ctrl + ŪôĒžāīŪĎúŪā§ : ŽćįžĚīŪĄį ÍįížĚī žěÖŽ†•Žźú žėĀžó≠žĚė ŽĀ̎讞úľŽ°ú žĽ§žĄú Ž•ľ žėģÍłīŽč§. Ctrl + shift + ŪôĒžāīŪĎú Ūā§ : ŽćįžĚīŪĄį ÍįížĚī žěÖŽ†•Žźú žėĀžó≠žĚė ŽĀĚŽč® žúľŽ°ú žĄ†ŪÉĚ Ž≤ĒžúĄŽ•ľ ŪôēŽĆÄ.
- 63. žóĎžÖÄ žä§ŪĒĄŽ†ąŽďú žčúŪäł žóįÍįĄ žÉĀžäĻŽ•† : (žė¨Ūēī žóįŽīČ ‚Äď žßÄŽāúŪēī žóįŽīČ)/žßÄŽāúŪēī žóįŽīČ*100 Žįėžė¨Ž¶ľ Ūē®žąė round žąėžčĚ žēěžóź ž∂ĒÍįÄ = round(žąęžěźÍįí, ŪĎúžčúŪē† žÜĆžąėž†ź žĚīŪēė žěźŽ¶Ņžąė) =round((žÖÄ-žÖÄ2))/žÖÄ2*100,0) SUM : Ūē©žāį AVERAGE : ŪŹČÍ∑† MAX, MIN : žĶúŽĆÄ, žĶúžÜĆžĻė žīĚŪē©žĚī 1372368107žúľŽ°ú Í≥ĄžāįŽź¨žĚĄŽēĆ, 3žěźŽ¶¨ Žč®žúĄŽ°ú žČľŪĎú ŪĎúžčú : ž†Ąž≤īŽ≤ĒžúĄ žßÄž†ē ‚Äď ŪĎúžčúŪėēžčĚ ‚Äď žöįŪēėŽč® X ŪäĻž†ē Í≥ĶÍłįÍīÄžĚė Ž∂ÄžĪĄŽ•ľ ž†Ąž≤ī Í≥ĶÍłįÍīÄ Ž∂ÄžĪĄ žīĚŪē©žúľŽ°ú ŽāėŽąĄÍłį žúĄŪēī Ž∂ĄŽ™®Ž•ľ Í≥†ž†ēŪēėŽ†§Ž©ī $Ž∂ôžó¨žēľ ŪēúŽč§. ‚Äď ž†ąŽĆÄžįłž°įŽ•ľ ŪēėžßÄ žēäÍ≥† žÖÄ žěźŽŹô žĪĄžõĞ̥ Ūē† Í≤Ĺžöį Ž∂ĄŽ™® ÍįížóźžĄú žóįžÜćžúľŽ°ú žė§Ž•ė ŽįúžÉĚ.
- 64. žóĎžÖÄ žä§ŪĒĄŽ†ąŽďú žčúŪäł ŪēĄŪĄįŽßĀ : ŽāīÍįÄ žõźŪēėŽäĒ ž°įÍĪīžĚė ŽćįžĚīŪĄįŽßĆ ŽĹĎžēĄŽāīŽäĒ Í≤É žĚľž†ē ž°įÍĪī žóź ŪēīŽčĻŪēėŽäĒ ŽćįžĚīŪĄįŽßĆ ÍĪłŽü¨Žāľ žąė žěąŽč§. žõźŪēėŽäĒ žÖÄ žĄ†ŪÉĚ ŪõĄ ŽćįžĚīŪĄį ‚Äď ŪēĄŪĄįŽ°ú ÍįÄžĄú ŪôĒžāīŪĎú ŪĎúžčú ŪĀīŽ¶≠ ‚Äď ÍĪł Žü¨Žāľ žÖÄ ŪĀīŽ¶≠ ‚Äď ‚ÄėŽ™®ŽĎź žĄ†ŪÉĚ‚Äô ‚Äď ÍĪłŽü¨Žāľ žÖÄ ž≤īŪĀ¨ŪēīžĄú ŪēĄŪĄįŽßĀ. žĻľŽüľ žó¨Žü¨ ÍįúŽ•ľ žĄ†ŪÉĚŪēėŽ©ī Ž≥Ķžąė ŪēĄŪĄį ŽŹôžčú žā¨žö© ÍįÄŽä• žěÖŽ†•Žźú žĻľŽüľ - =,>,<žôÄ ÍįôžĚÄ ŽďĪŪėłžôÄ Ž∂ÄŽďĪŪėłŽ•ľ žā¨žö©Ūēī žĚľž†ē ÍįížĚĄ Íłįž§ÄžúľŽ°ú žīąÍ≥ľ, ŽĮłŽßĆ, žĚīžÉĀ, žĚīŪēėžĚė ŽćįžĚīŪĄįŽßĆ ž∂Ēž∂ú ÍįÄŽä•.
- 65. žóĎžÖÄ ŪĒľŽ≤óŪÖĆžĚīŽłĒ ŪĒľŽ≤ó ŪÖĆžĚīŽłĒ ‚Äď ŪäĻž†ē Ž≤Ēž£ľ ŽćįžĚīŪĄįŽ•ľ Íłįž§ÄžúľŽ°ú Žč§Ž•ł žąėžĻė ŽćįžĚīŪĄį Ž•ľ Ūē©žāįŪēėÍ≥† ŪŹČÍ∑†žĚĄ ŽāīÍĪįŽāė ŽĻĄžú®žĚĄ Í≥ĄžāįŪēėÍ≥† ž†ēŽ†¨Ūēī žĚľŽ™©žöĒžóį Ūēú ŪĎúŽ°ú ž†ēŽ¶¨Ūēú Í≤É. žį®ŪäłžÉĀ žēĄŽ¨ī žÖÄžĚīŽāė Ūēú Í≥≥ ŪĀīŽ¶≠ ‚Äď žÉĀŽč®Ž©ĒŽČīžĚė žāĹžěÖ ‚Äď ŪēćžóÖŪÖĆžĚī ŽłĒ ‚Äď ŪôēžĚł ‚Äď žė§Ž•łŪéłžóźŽäĒ ŪĒľŽ≤ó ŪÖĆžĚīŽłĒ ŪēĄŽďú, žôľŪéłžóźŽäĒ ŪĎú ŽßƎ吏Ėī žßź ‚Äď drag and darg Žį©žčĚ žā¨žö© ‚Äď žõźŪēėŽäĒ ŽćįžĚīŪĄį žĻľŽüľžĚė ŽĄ§Ž™®Žāú ŽĻą žÉĀžěźŽ•ľ ŪĀīŽ¶≠ŪēėÍĪįŽāė žĻľŽüľ Ž™ÖžĚĄ ŪĀīŽ¶≠Ūēú Ží§ žõźŪēėŽäĒ Í≥≥žúľŽ°ú ŽĀĆžĖī Žč§ŽÜą ‚Äď ŪŹČÍ∑†ÍįížúľŽ°ú Ž≥ÄŪôėŪēėÍłį žúĄŪēī žÖĞ̥ žēĄŽ¨ī Í≥≥žĚīŽāė ŪĀīŽ¶≠Ūēú Ží§ Žßąžöįžä§ žöį ŪĀīŽ¶≠ ‚Äď ÍįížöĒžēĹ Íłįž§Ä ‚Äď ŪŹČÍ∑†žúľŽ°ú ž°įž†ē ‚Äď žīĚŪē©Í≥ĄŽäĒ ž†ú ÍĪįŪēú Ží§ Žßąžöįžä§ žöįŪĀīŽ¶≠Ūēī ŪēĄŽďú ŪĎúžčúŪėēžčĚ Ž©ĒŽČīžóźžĄú žóįŽīČ ŪŹČÍ∑†Íįí žĚĄ žÜĆžąėž†ź 1žěźŽ¶¨Ž°ú ŪĎúžčú.
- 66. žóĎžÖÄ ŪĒľŽ≤óŪÖĆžĚīŽłĒ Ž™á ÍįúžĒ© Ž∂ĄŪŹ¨ŪĖąŽäĒžßÄ ÍįúžąėžĄłÍłį ‚ÄėŪĖČ‚Äôžóź Ž≤Ēž£ľ ŽćįžĚīŪĄįŽ•ľ žėģÍłįÍ≥† ‚ÄėÍįí‚ÄôžóźŽŹĄ ŽŹôžĚľŪēú Ž≤Ēž£ľ ŽćįžĚīŪĄįŽ•ľ ŽĄ£ žúľŽ©ī, ÍįĀ Ūē≠Ž™©Ž≥ĄŽ°ú Íįúžąė žĄłžĖīž§ÄŽč§. ŪćľžĄľŪäł ŽĻĄžú®Ž°ú ŽāėŪÉÄŽāīÍłį ‚Äď Íįúžąė žĻľŽüľžóźžĄú Žßąžöįžä§ žöįŪĀīŽ¶≠ Ží§ Íįí žöĒžēĹ Íłįž§Ä ‚Äď ÍłįŪÉÄ žėĶžÖė ‚Äď Íįí ŪĎúžčúŪėēžčĚ ‚Äď žĄ§ž†ē ŪĒľŽ≤óŪÖĆžĚīŽłĒ žÖÄ žúĄžóźžĄú Žßąžöįžä§ žöįŪĀīŽ¶≠Ūēī ž†ēŽ†¨ Ž©ĒŽČīŽ•ľ žĄ†ŪÉĚŪēėŽ©ī ŽāīŽ¶ľžį®žąú ŪėĻžĚÄ žė¨Ž¶ľžį®žąúžúľŽ°ú ž†ēŽ†¨ ÍįÄŽä• ŪĒľŽ≤óŪÖĆžĚīŽłĒžĚÄ ŽćįžĚīŪĄįžĚė Ž∂ĄŪŹ¨Ž•ľ žöĒžēĹŪēėŽäĒŽćį ŪÉĀžõĒŪēú ÍłįŽä•
- 67. žóĎžÖÄ ŪÖćžä§Ūäł Ž∂ĄŽ¶¨ ÍłįŽä• : Ž©ĒŽČī ŽćįžĚīŪĄį ‚Äď ŪÖćžä§Ūäł Ž∂ĄŽ¶¨ ŽįĒÍĺłÍłį ÍłįŽä• : Ūôą ‚Äď žįĺÍłį ŽįŹ žĄ†ŪÉĚ ‚Äď ŽįĒÍĺłÍłį Ex) ‚ÄėžĄúžöłžčú ÍįēŽ∂ĀÍĶ¨ Ž≤ąŽŹô‚Äô žÖÄžĚī žěąžĚĄ Í≤Ĺžöį ‚Äėžčú‚ÄôŽ•ľ ‚ÄėŪäĻŽ≥Ąžčú‚ÄôŽ°ú Ž≥ÄŽŹô ÍįÄŽä• Concatenate(Ž¨łžěźžóī, Ž¨łžěźžóī, ‚Ķ, Ž¨łžěźžóī) Ž¨łžěźÍįÄ žěÖŽ†•Žźú žÖÄ Ūē©ž≥ź ž£ľŽäĒ Ūē®žąė Ex) A2žÖÄžóź žĄúžöłžčú, B2žÖÄžóź ÍįēŽ∂ĀÍĶ¨ŽĚľÍ≥† žěÖŽ†•ŽŹľ žěąžĚĄ ŽēĆ, =concatenate(A2,‚ÄĚ‚ÄĚ,B2)žĚÄ ‚ÄėžĄúžöłžčú ÍįēŽ∂ĀÍĶ¨‚ÄôŽĚľŽäĒ žÖĞ̥ ŽįúžÉĚ ConcatenateŪē®žąėžôÄ ÍįôžĚī Ūē®žąėŽ™ÖžĚī Íłī Í≤ĹžöįconŽßĆ žěÖŽ†•ŪēīŽŹĄ con žúľŽ°ú žčúžěĎŪēėŽäĒ žó¨Žü¨ Ūē®žąėÍįÄ Žú®Íłį ŽēĆŽ¨łžóź žĄ†ŪÉĚ ÍįÄŽä•, &Ž°ú Ž¨łžěźžóī žĚĄ žóįÍ≤įžčúžľúŽŹĄ concatenatežôÄ ŽŹôžĚľŪēú Ūö®Í≥ľ Žāľ žąė žěąŽč§. ÍįÄŽ†Ļ =A2&‚ÄĚ‚ÄĚ&B2ŽĚľÍ≥† žěÖŽ†•ŪēīŽŹĄ =concatenate(A2,‚ÄĚ‚ÄĚ,B2)Í≥ľ ÍįôžĚÄ Í≤įÍ≥ľŽ•ľ ŽāłŽč§.
- 68. žóĎžÖÄ Datevalue ‚Äď žčúÍįĄ ŽćįžĚīŪĄįŽ•ľ žąęžěźŽ°ú Ž≥ÄŪôė Today - žė§ŽäėžĚė žóįžõĒžĚľ Žā†žßúŽ•ľ žāįž∂úŪēėŽäĒ Ūē®žąė Leet(A2,5)ŽäĒ žÖÄA2žĚė Ž¨łžěźžóīžóźžĄú žôľž™ĹžóźžĄú Žč§žĄĮͳĞ쟎•ľ ž∂Ēž∂ú Mid(A2,7,3)žĚÄ A2žĚė žôľŪ鳞󟞥ú 7Ž≤ąžßł žěźŽ¶¨Ž∂ÄŪĄį žčúžěĎŪēī žĄł ÍłÄžěź Ž•ľ ŽļĆ Right(A2.3) A2žĚė žė§Ž•łž™ĹžóźžĄú žĄł ͳĞ쟎•ľ ž∂Ēž∂ú If(ž°įÍĪīŽ¨ł, Í≤įÍ≥ľÍįížĚī žįłžĚłÍ≤Ĺžöį, Í≤įÍ≥ľÍįížĚī ÍĪįžßďžĚł Í≤Ĺžöį) Ex) if(A2>70, ‚ÄúŪē©Í≤©‚ÄĚ , ‚ÄúŽ∂ąŪē©Í≤©‚ÄĚ)
- 69. žóĎžÖÄ žŅľŽ¶¨ ‚Äď solžĚĄ žā¨žö©Ūēī žõźŽ≥łŽćįžĚīŪĄįŽ•ľ Í≤ÄžÉČ, ž∂ĒÍįÄ, žąėž†ē, žā≠ž†úŪēėŽäĒ žßąžĚėŽ¨łžúľŽ°ú dbmsŽ•ľ žā¨žö©Ūēėžó¨ ŽćįžĚīŪĄįŽ≤†žĚīžä§Ž•ľ ž°įžěĎŪēėŽäĒ Í≤É žĚīŽĮł ÍĶ¨ž∂ēŽźėžĖī žěąŽäĒ ŪÖĆžĚīŽłĒŽ°úŽ∂ÄŪĄį ŽćįžĚīŪĄįŽ≤†žĚīžä§Ž•ľ Ž∂ĄžĄĚŪēėžó¨ ŪēĄ žöĒŪēú ž†ēŽ≥īŽ•ľ žįĺŽäĒ ŽŹĄÍĶ¨ ŪŹľžĚīŽāė Ž≥īÍ≥†žĄúžĚė žõźŽ≥łŽćįžĚīŪĄįÍįÄ Žź®
- 70. žóĎžÖÄ Secect - ŪēĄžöĒŪēú žĻľŽüľ žĄ†ŪÉĚŪēī Ž∂ąŽü¨žėī Where - ž°įÍĪīžóź ŽßěŽäĒ ŪĖȞ̥ Ž∂ąŽü¨žėī Group by ‚Äď ŪäĻž†ē žĻľŽüľžĚĄ Íłįž§ÄžúľŽ°ú Žč§Ž•ł žĻľŽüľ ŽćįžĚīŪĄįŽ•ľ žßĎÍ≤ĆŪēī Ž≥īžó¨ž§ÄŽč§. ŪĒľŽ≤ó ŪÖĆžĚīŽłĒžĚė ‚ÄėŪĖČ‚Äôžóź ŽĀĆžĖī ŽĄ£žĖīž£ľŽäĒ žĻľŽüľŽ™ÖžĚī ŽįĒŽ°ú žĚīÍłįž§Ä žĻľŽüľ Pivot ‚Äď ŪĒľŽ≤ó ŪÖĆžĚīŽłĒžĚė ‚Äėžóī‚Äô ŽßĆŽď¨ Order by ‚Äď žė¨Ž¶ľžį®žąú ŪėĻžĚÄ ŽāīŽ¶ľžį®žąúžúľŽ°ú ž†ēŽ†¨ Limit ‚Äď ŪĎúžčúŪē† ŪĖČžąė žĄ§ž†ē Label ‚Äď ŪĎúžčúŪē† žĻľŽüľ žĚīŽ¶Ą žÉąŽ°ú žßÄž†ē
- 71. 3.16~3.17
- 72. ŽßąŽ¨īŽ¶¨ ŪÜĶÍ≥Ąžóź ÍīÄŪēú Ž™á ÍįÄžßÄ ÍłįŽ≥ł žÉĀžčĚ ŪÜĶÍ≥ĄŪēô ‚ÄĘ Íłįžą† ŪÜĶÍ≥Ą : žěźŽ£ĆžĚė ŪäĻžßēžĚĄ ÍįĄŽč®Ūěą žĄ§Ž™Ö ŪēėŽäĒ ŪÜĶÍ≥Ą ‚ÄĘ ž∂ĒŽ¶¨ ŪÜĶÍ≥Ą : ŪĎúŽ≥łžßώ讞̥ žĄ§ž†ēŪēī ÍįÄžĄ§žĚĄ ŽßĆŽď† ŪõĄ, žįłÍ≥ľ ÍĪįžßďžĚĄ Í≤įž†ē
- 73. ŽßąŽ¨īŽ¶¨ ŪÜĶÍ≥Ąžóź ÍīÄŪēú Ž™á ÍįÄžßÄ ÍłįŽ≥ł žÉĀžčĚ ŪŹČÍ∑† = žěźŽ£Ć Ž∂ĄŪŹ¨žĚė ŪäĻžĄĪžĚĄ Ž≥īžó¨ž£ľŽäĒ ŽĆÄŪĎĮÍįí žāįžą†ŪŹČÍ∑† : ž†Ąž≤ī ÍįížĚĄ Ž™®ŽĎź ŽćĒŪēú Ží§, ÍįúžąėŽ°ú ŽāėŽąą Íįí (outlier ŽįúžÉĚ ÍįÄŽä•) ž§ĎžēôÍįí : ŪĎúŽ≥ł žąėžĻėŽ•ľ Žāėžóī ŪĖąžĚĄ ŽēĆ ž§ĎžēôÍįí (ŪôÄžąėŽ©ī ž†ēž§Ďžēô žąėžĻė, žßĚžąėŽ©ī ž§ĎžēôžĚė ŽāėŽěÄŪěą žúĄžĻėŪēú ŽĎź žąėžĚė ŪŹČÍ∑†Íįí) žĶúŽĻąÍįí : ŪĎúŽ≥ł žąėžĻė ž§Ď ÍįÄžě• ŽßéžĚī ŽďĪžě•ŪēėŽäĒ Íįí žĚľŽįėž†ĀžúľŽ°úŽäĒ žāįžą†ŪŹČÍ∑†žĚĄ žā¨žö©ŪēėžßÄŽßĆ Ž∂ĄŪŹ¨ÍįÄ žŹ†Ž¶ī Í≤Ĺžöį, ž§ĎžēôÍįí žā¨žö©
- 74. ŽßąŽ¨īŽ¶¨ ŪÜĶÍ≥Ąžóź ÍīÄŪēú Ž™á ÍįÄžßÄ ÍłįŽ≥ł žÉĀžčĚ žöįŽ¶¨ÍįÄ ž£ľŽ™©Ūēīžēľ ŪēėŽäĒ Í≤É, ŽćįžĚīŪĄį ÍįĄžĚė žį®žĚī Ž≤ĒžúĄ : žĶúŽĆďÍįíÍ≥ľ žĶúžÜüÍįížĚĄ ÍĶ¨Ūēú žį®žĚī Ūéłžį® : ÍįĀ ŽćįžĚīŪĄįžôÄ ŪŹČÍ∑†žĚė žį®žĚī (Ūéłžį®Ž•ľ Ž™®ŽĎź ŽćĒŪēėŽ©ī 0) Ž∂Ąžāį : ÍįĀ ŪéłžěźžĚė ž†úÍ≥ĪžĚė ŪŹČÍ∑† ŪĎúž§ÄŪéłžį® : žąėžĻėžôÄ ž§Ďžč¨ÍįíÍ≥ľ ÍĪįŽ¶¨Ž•ľ ÍįÄŽä†Ūē† žąė žěąŽäĒ žąėžĻė žĚīŽü¨Ūēú žąėžĻėŽ•ľ ŪÜĶŪēī ž†ēÍ∑ú Ž∂ĄŪŹ¨Ž•ľ ŽßƎ吏Ėī žčúÍįĀž†ĀžúľŽ°ú ŽćįžĚīŪĄįŽ•ľ Ž≥ľ žąė žěąŽč§.
- 75. ŽßąŽ¨īŽ¶¨ ŽćįžĚīŪĄįžóź ŽĆÄŪēú Í≥ľžč†žĚĄ Ž≤ĄŽ†§žēľ ŽćįžĚīŪĄį ž†ÄŽĄźŽ¶¨ž¶ėžĚī žāįŽč§. ŽćįžĚīŪĄįžóź Í∑ľž≤ėŪēú ž∑®žě¨ŽäĒ ‚ÄúÍįĚÍīÄž†ĀžĚīÍ≥† žěÖž≤īž†ĀžĚł Ž≥īŽŹĄÔľāÍįÄ Ž™©ž†ĀžĚīŽč§. ŽĒįŽĚľžĄú, ŽćįžĚīŪĄį ž†ÄŽĄźŽ¶¨ž¶ėžĚÄ ŽćįžĚīŪĄįžĚė ÍįĚÍīÄžĄĪÍ≥ľ ž†ēŪôēžĄĪžĚī ž§ĎžöĒŪēėŽč§. žąęžěźŽäĒ žĚėÍ≤¨žĚīÍ≥†, žöĒžēĹžĚīÍ≥†, ž∂Ēž†ēžĻėžóź Ž∂ąÍ≥ľŪēėŽč§. ŽČīžöēŪÉĞ쥞¶ą žĽīŪď®ŪĄį Ūôúžö©Ž≥īŽŹĄ(CAR) žóźŽĒĒŪĄį žā¨ŽĚľžĹĒŪó® žąėžĻė žěźŽ£ĆžóźžĄú ÍįÄžĻėžôÄ Ūö®žö©žĄĪžĚĄ ŽĀĆžĖīŽāīŽäĒ Í≤ÉžĚÄ ž†Ąž†ĀžúľŽ°ú ŽćįžĚīŪĄįŽ•ľ ž†ĀÍ∑Ļ žā¨žö©ŪēėŽäĒ žā¨ŽěĆžĚė Ž™ęžĚł Í≤ÉžĚīŽč§.