A Corpus of Chinese Comic Books: Database, Metadata, and Visual Object Recognition
1 like298 views

The document summarizes a project to create a corpus of digitized Chinese comic books from the 1950s-1970s. It discusses the history and achievements of the project, including digitizing over 1,250 comic books, creating metadata records, and providing online access. It also describes experiments with automatic object detection in the comics using computer vision techniques. Finally, it outlines the new system being developed including a IIIF image server, use of the Mirador annotation tool, and linking to external authorities and standards to improve interoperability.
































A Corpus of Chinese Comic Books: Database, Metadata, and Visual Object Recognition
- 1. A Corpus of Chinese Comic Books: Database, Metadata, and Visual Object Recognition Matthias Arnold, HRA, Universit?t Heidelberg
- 2. Agenda ? Project history ? Approaching the material ? Achievements ? Automatic object detection ? New system and user annotation Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 3. ˇ°Leihbibliothek f¨ąr Kinder an der Stra?eˇ°, She Zeh Tschi, Der Holzschnitt im Neuen China, Katalog, Dresden 1951, p.101
- 5. Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 6. Project History 2009-11 Main digitisation project Funding: Cluster of Excellence ?Asia and Europeˇ° and Institute of Chinese Studies Scanning: MediaLab at Cluster First database: eXist-db, metadata in MODS XML Presentation at Cartoon Museum Basel ?Visual Words - Comics from Chinaˇ° (2010/11) Content expansion and separation of books and stories Image analysis project with Computer Vision (radiances) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
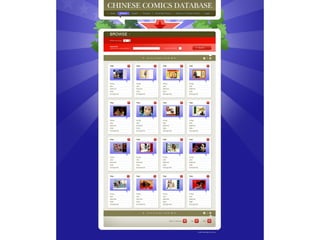
- 7. Enduser interface (2010) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 13. Project History 2009-11 Main digitisation project Funding: Cluster of Excellence ?Asia and Europeˇ° and Institute of Chinese Studies Scanning: MediaLab at Cluster First database: eXist-db, metadata in MODS XML Presentation at Cartoon Museum Basel ?Visual Words - Comics from Chinaˇ° (2010/11) Content expansion and separation of books and stories Image analysis project with Computer Vision (radiances) 2018: Data migration (ongoing): Mongo DB, ingest in XML, image service (IIIF), browse - search - filter, user annotation through Mirador viewer Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 14. Approaching the material Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 15. Úw°ŮČf Zhao Baiwan (1951) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 16. şěµĆĽÇ Hong deng ji (1970) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 17. ³ѸşÍÇŕÄęµÄąĘĘ Lu Xun he qingnian de gushi (1976) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
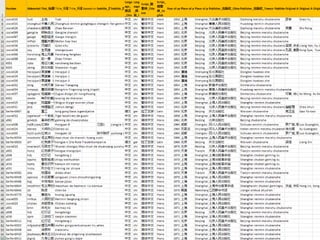
- 18. 1. Spreadsheets 2. XML Database (MODS records) and frontend 3. Refined metadata schema (books & stories, agents), SQL database 4. Mongo database, IIIF image service, user annotations in Mirador Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 19. Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 21. Special cases Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 22. ÉúËŔľ‰ Sheng si yuan (1953) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 23. ¸ß¸čĂÍ˝ř Gaoge mengjin (1952) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 24. Project Achievements 1. Scans from 5 collections (1250/1031 books) 2. Digitize material (greysacale .tif @600dpi, ca. 4 TB) 3. Record all metadata (as provided on books) 4. Provide online access to metadata 5. Provide online access to full books (read books) 6. Open data for research annotations (Mirador) 7. Explore automatic content analysis (computer vision) 8. *Link data to authorities (agents) 9. **Generate fulltext 10. **Explore generic content description (XML) Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 25. Automatic object detection Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 26. Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19 ? Chinese comics from the second half of the Cultural Revolution ? Over 1200 books (~120,000 pages) ? Grayscale .tif images @600 dpi ~ 4,5 Tb data ? Focus: comic book production of late 1960s and 1970s from China. ? Shows the diversity of Chinese comic production in general ? Special type of emphasis (heroes, symbolic objects or idols)
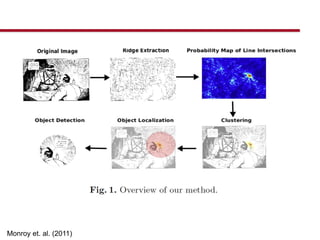
- 27. Specific type of emphasis: radiance
- 28. Monroy et. al. (2011)
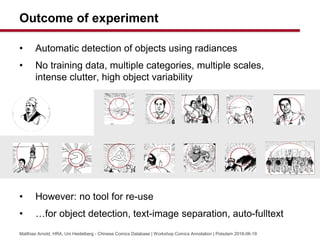
- 31. Outcome of experiment ? Automatic detection of objects using radiances ? No training data, multiple categories, multiple scales, intense clutter, high object variability ? However: no tool for re-use ? ˇfor object detection, text-image separation, auto-fulltext Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 32. New system and user annotation Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
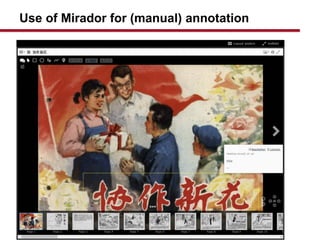
- 34. Use of Mirador for (manual) annotation
- 35. Arnold/Decker - Annotationssysteme f¨ąr Bild- und Videomedien, 2016-01-26 35
- 36. Standards - Interoperability 1. Image service: IIIF Image API using standardized IIIF image call, http://iiif.io 2. Image annotation: Web Annotation using Mirador IIIF viewer http://w3c.github.io/web-annotation/ 3. Bibliographic metadata: MODS XML for library catalogs 4. Agentˇ®s data: link to authorities (e.g. GND or VIAF) 5. Textual data (ideas): Publish metadata on research data platform (HeiDATA) Texts (stories, pre-/postface, paratext) in TEI XML Structure in CBML? 6. Re-use and enhancements: Include samples in Graphic Narrative or Vis. Lang Res. Corpus? Find partners for automatical (Chinese) comics analysis
- 37. References ? Seifert, Andreas. Bildgeschichten f¨ąr Chinas Massen: Comic und Comicproduktion im 20. Jahrhundert. K?ln: B?hlau, 2008. ? Monroy, Antonio, Tobias Kr?ger, Matthias Arnold, and Bj?rn Ommer. ˇ°Parametric Object Detection for Iconographic Analysis.ˇ± In SCCH11, 1-8. Heidelberg, 2011. ? ˇ°Reddition : Reddition 63.ˇ± Edition Alfons, Dec. 2015. https://www.reddition.de/index.php/shop/reddition/reddition-63- detail. ? Database: http://comics.freizo.org Matthias Arnold, HRA, Uni Heidelberg - Chinese Comics Database | Workshop Comics Annotation | Potsdam 2018-06-19
- 38. Contact Matthias Arnold Heidelberg Research Architecture Cluster of Excellence ˇ°Asia and Europe in a Global Contextˇ± Heidelberg Centre for Transcultural Studies | HCTS Karl Jaspers Centre Vo?str. 2 | Building 4400 | Room 005b 69115 Heidelberg, Germany arnold@asia-europe.uni-heidelberg.de http://www.asia-europe.uni-heidelberg.de