Acl2020 taguchi
?
0 likes?1,270 views

ACL 2020 §Œ≤Œº”àÛ∏Ê°£BPE œµ§Œ tokenizer §À§ƒ§§§∆§Œ‘í ?Rico Sennrich, Barry Haddow, and Alexandra Birch. "Neural machine translation of rare words with subword units." In ACL, 2016. ?Taku Kudo. "Subword regularization: Improving neural network translation models with multiple subword candidates." In ACL, 2018. ?Ivan Provilkov, Dmitrii Emelianenko, and Elena Voita. "BPE-Dropout: Simple and Effective Subword Regularization." In ACL, 2020. ?Xuanli He, Gholamreza Haffari, and Mohammad Norouzi. "Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation." In ACL, 2020.


![5
? ôC–µ∑≠‘U§«§Ë§Ø π”√§µ§Ï§Î metric
? 0~1 §«∏fl§§§€§…§Ë§§∑≠‘UΩYπ˚
? brevity penalty: ”Ëúy‘U§¨’˝Ω‚‘U§Ë§Í∂ç§àˆ∫œ§À•⁄• •Î•∆•£§Ú’n§π
? n-gram overlap: 1~4-gram §Œ modi?ed precision (±ª§Í n-gram ˝ / »´ n-gram ˝)
BLEU [Papineni et al., 2002] https://cloud.google.com/translate/automl/docs/evaluate?hl=ja
(~0.1)
(0.1~0.19)
(0.2~0.29)
(0.3~0.4)
(0.4~0.5)
(0.5~0.6)
(0.6~)
bleu score §ŒΩ‚·ã (°˘á̧Œ•π•≥•¢§œ 0~100 §«ï¯§´§Ï§∆§§§Î§Œ§«—a’˝Çé§Ú«‡◊÷§«”õ›d)](https://image.slidesharecdn.com/acl2020taguchi-200814054704/85/Acl2020-taguchi-5-320.jpg)
![6
ACL
2016
Neural Machine Translation of
Rare Words with Subword Unit
[Sennrich et al., 2016]](https://image.slidesharecdn.com/acl2020taguchi-200814054704/85/Acl2020-taguchi-6-320.jpg)


![9
? «ÈàÛàRøs§À π§Ô§Ï§Îºº–g§Œ‘í
? Ól≥ˆ§π§Î 2 byte §Ú 1 byte Œƒ◊÷§À÷√§≠ìQ§®§Î§≥§»§Ú¿R§Í∑µ§π
Byte Pair Encoding (BPE) [Gage, 1994]
BPE §Œflm”√¿˝
(wikipedia §Ë§Í“˝”√£∫https://ja.wikipedia.org/wiki/%E3%83%90%E3%82%A4%E3%83%88%E5%AF%BE%E7%AC%A6%E5%8F%B7%E5%8C%96)](https://image.slidesharecdn.com/acl2020taguchi-200814054704/85/Acl2020-taguchi-9-320.jpg)







![17
ACL
2018
Subword Regularization: Improving
Neural Network Translation Models
with Multiple Subword Candidates
[Kudo, 2018]](https://image.slidesharecdn.com/acl2020taguchi-200814054704/85/Acl2020-taguchi-17-320.jpg)








![26
ACL
2020
BPE-Dropout: Simple and E?ective
Subword Regularization
[Provilkov et al., 2020]](https://image.slidesharecdn.com/acl2020taguchi-200814054704/85/Acl2020-taguchi-26-320.jpg)



![30
ACL
2020
Dynamic Programming Encoding for
Subword Segmentation in
Neural Machine Translation
[He et al., 2020]](https://image.slidesharecdn.com/acl2020taguchi-200814054704/85/Acl2020-taguchi-30-320.jpg)










Acl2020 taguchi
- 1. 2020.08.14 ÃÔø⁄ ÷±√÷ ACL 2020 ≤Œº”àÛ∏Ê ~ BPE œµ tokenization §Œ±≥æ∞§»◊Ó–¬Ñ”œÚ ~
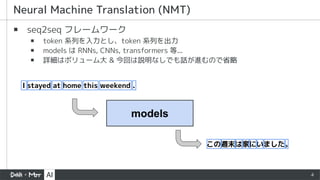
- 2. 2 ? text tokenization §À§ƒ§§§∆ ? NLP §Ú ML §«––§¶ÎH§Œ text ∑÷∏Ó ÷∑® ? Ãÿ§À BPE §ÀÈvflB§π§Î ACL2020 §Œ’쌃£≤±æ§ÚΩBΩÈ ΩÒªÿ‘í§πƒ⁄»› I stayed at home this weekend. I s t a y e d a t h o m e t h i s w e e k e n d . I stayed at home this weekend . I stay ed at home this week end .
- 3. 3 ? …Ÿ§ §Ø§»§‚ NLP w/ NN §Ú§π§Î§ §È tokenization §π§Î§œ§∫ ? ◊ÓΩ¸ kaggle §«§‚ BPE tokenizer §Ú π§√§ø ? •¢•◊•Ì©`•¡§¨ ö¯”√µƒ§¿§»Àº§√§ø ? NLP §Àœfi§È§∫§≥§≥§À◊≈œÎ§Úµ√§∆ΩYòãèÍ”√§¨Ñø§≠§Ω§¶ § §Û§«§≥§Œ•∆©`•fi£ø
- 4. 4 ? seq2seq •’•Ï©`•‡•Ô©`•Ø°° ? token œµ¡–§Ú»Î¡¶§»§∑°¢token œµ¡–§Ú≥ˆ¡¶ ? models §œ RNNs, CNNs, transformers µ»... ? ‘îºö§œ•‹•Í•Â©`•‡¥Û & ΩÒªÿ§œ’h√˜§ §∑§«§‚‘í§¨flM§‡§Œ§« °¬‘ Neural Machine Translation (NMT) models I stayed at home this weekend . §≥§ŒflLƒ©§œº“§À§§§fi§∑§ø°£
- 5. 5 ? ôC–µ∑≠‘U§«§Ë§Ø π”√§µ§Ï§Î metric ? 0~1 §«∏fl§§§€§…§Ë§§∑≠‘UΩYπ˚ ? brevity penalty: ”Ëúy‘U§¨’˝Ω‚‘U§Ë§Í∂ç§àˆ∫œ§À•⁄• •Î•∆•£§Ú’n§π ? n-gram overlap: 1~4-gram §Œ modi?ed precision (±ª§Í n-gram ˝ / »´ n-gram ˝) BLEU [Papineni et al., 2002] https://cloud.google.com/translate/automl/docs/evaluate?hl=ja (~0.1) (0.1~0.19) (0.2~0.29) (0.3~0.4) (0.4~0.5) (0.5~0.6) (0.6~) bleu score §ŒΩ‚·ã (°˘á̧Œ•π•≥•¢§œ 0~100 §«ï¯§´§Ï§∆§§§Î§Œ§«—a’˝Çé§Ú«‡◊÷§«”õ›d)
- 6. 6 ACL 2016 Neural Machine Translation of Rare Words with Subword Unit [Sennrich et al., 2016]
- 7. 7 ? Ñø¬ µƒ§ tokenization ÷∑®§«§¢§Î BPE §Ú÷∞∏ ? —ß¡ï•«©`•ø§À§ §§Ög’Z§À§‚åùèÍø…ƒ‹ (open-vocaburaly) ? ’Zè° ˝§Ú“÷§®§ƒ§ƒ°¢ π”√ïr§Œ–‘ƒ‹§‚¡º§§ ? (NLP “ª∞„§À π§®§Î§¨) ◊≈ƒø§π§ÎÜñÓ}‘O∂®§œ NMT (ôC–µ∑≠‘U) ∏≈“™
- 8. 8 ¡º§§ tokenization §Œ‘O”ã∑Ω·ò §«§≠§Î§¿§± tokenization §Œ¡£∂»§Úºö§´§Ø§∑§ø§§ ?vocabulary ÈvflB§Œïrø’Èg”ãÀ„¡ø§Œœ˜úp ?ΩM§fl∫œ§Ô§ª§À§Ë§Î±Ì¨F§« open-vocabulary ªØ§¨∆⁄¥˝§«§≠§Î ?etc... §«§≠§Î§¿§± tokenization §Œ¡£∂»§Úªƒ§Ø§∑§ø§§ ?∑÷∏Ó token ˝§Œœ˜úp§À§Ë§ÎÑI¿Ì§ŒÑø¬ ªØ ?∑÷∏Ó token ˝§Œœ˜úp§À§Ë§Î NN §Œ«ÈàÛŪ≤•ÿìµ£§Œœ˜úp ?etc... trade o? Ól≥ˆ’Z§œ§fi§»§·°¢’‰§∑§§Ög’Z§œ subword §ŒΩM§fl∫œ§Ô§ª§«±Ì¨F£°
- 9. 9 ? «ÈàÛàRøs§À π§Ô§Ï§Îºº–g§Œ‘í ? Ól≥ˆ§π§Î 2 byte §Ú 1 byte Œƒ◊÷§À÷√§≠ìQ§®§Î§≥§»§Ú¿R§Í∑µ§π Byte Pair Encoding (BPE) [Gage, 1994] BPE §Œflm”√¿˝ (wikipedia §Ë§Í“˝”√£∫https://ja.wikipedia.org/wiki/%E3%83%90%E3%82%A4%E3%83%88%E5%AF%BE%E7%AC%A6%E5%8F%B7%E5%8C%96)
- 10. ? BPE tokenization §Œ—ß¡ï (°˘’쌃”…¿¥§«§ §Ø°¢±æ∞k±Ì§À§™§§§∆§Œ∫Ù≥∆§«§π) 10 ÷∞∏ ÷∑® ¢Ÿ vocabulary §Ú a, b, °≠ µ»§Œ°∫Œƒ◊÷°ª§«≥ı∆⁄ªØ ¢⁄ —ß¡ï”√§Œ text •«©`•ø§Ú vocabulary §Ú§‚§»§À tokenize ¢€ ¢⁄§Œ token œµ¡–§À§™§§§∆∏˜ token §Œ°∫•⁄•¢°ª§Ú ˝§®§Î ¢‹ ¢€ §«◊Ó§‚ ˝§Œ∂‡§´§√§ø°∫•⁄•¢°ª§À§ƒ§§§∆ vocabulary?operation §À◊∑º” ¢› vocabulary §Œ¥Û§≠§µ§¨“é∂®§Œ ˝§Àfl_§∑§ø§ÈΩK¡À°£§Ω§¶§«§ §§àˆ∫œ ¢⁄ §ÿ a, b, c, ... ?T h e _ s c o r e _ b e c o m e s _ l o w e r _ a n d _ l o w e r . ?I _ h a v e _ a c h i e v e d _ b e t t e r _ r e s u l t . °˘∫ÜÖg§Œ§ø§·°¢£≤ sentences vocabulary text •«©`•ø operation
- 11. ? BPE tokenization §Œ—ß¡ï (°˘’쌃”…¿¥§«§ §Ø°¢±æ∞k±Ì§À§™§§§∆§Œ∫Ù≥∆§«§π) 11 ÷∞∏ ÷∑® ¢Ÿ vocabulary §Ú a, b, °≠ µ»§Œ°∫Œƒ◊÷°ª§«≥ı∆⁄ªØ ¢⁄ —ß¡ï”√§Œ text •«©`•ø§Ú vocabulary §Ú§‚§»§À tokenize ¢€ ¢⁄§Œ token œµ¡–§À§™§§§∆∏˜ token §Œ°∫•⁄•¢°ª§Ú ˝§®§Î ¢‹ ¢€ §«◊Ó§‚ ˝§Œ∂‡§´§√§ø°∫•⁄•¢°ª§À§ƒ§§§∆ vocabulary?operation §À◊∑º” ¢› vocabulary §Œ¥Û§≠§µ§¨“é∂®§Œ ˝§Àfl_§∑§ø§ÈΩK¡À°£§Ω§¶§«§ §§àˆ∫œ ¢⁄ §ÿ a, b, c, ... ?T h e _ s c o r e _ b e c o m e s _ l o w e r _ a n d _ l o w e r . ?I _ h a v e _ a c h i e v e d _ b e t t e r _ r e s u l t . °˘∫ÜÖg§Œ§ø§·°¢£≤ sentences vocabulary text •«©`•ø operation °∫er°ª§¨◊Ó∂‡£°
- 12. ? BPE tokenization §Œ—ß¡ï (°˘’쌃”…¿¥§«§ §Ø°¢±æ∞k±Ì§À§™§§§∆§Œ∫Ù≥∆§«§π) 12 ÷∞∏ ÷∑® ¢Ÿ vocabulary §Ú a, b, °≠ µ»§Œ°∫Œƒ◊÷°ª§«≥ı∆⁄ªØ ¢⁄ —ß¡ï”√§Œ text •«©`•ø§Ú vocabulary §Ú§‚§»§À tokenize ¢€ ¢⁄§Œ token œµ¡–§À§™§§§∆∏˜ token §Œ°∫•⁄•¢°ª§Ú ˝§®§Î ¢‹ ¢€ §«◊Ó§‚ ˝§Œ∂‡§´§√§ø°∫•⁄•¢°ª§À§ƒ§§§∆ vocabulary?operation §À◊∑º” ¢› vocabulary §Œ¥Û§≠§µ§¨“é∂®§Œ ˝§Àfl_§∑§ø§ÈΩK¡À°£§Ω§¶§«§ §§àˆ∫œ ¢⁄ §ÿ er, a, b, c, ... ?T h e _ s c o r e _ b e c o m e s _ l o w e r _ a n d _ l o w e r . ?I _ h a v e _ a c h i e v e d _ b e t t e r _ r e s u l t . °˘∫ÜÖg§Œ§ø§·°¢£≤ sentences vocabulary text •«©`•ø e-r °˙ er operation °∫er°ª§Ú◊∑º” §≥§¡§È§‚◊∑º”
- 13. ? BPE tokenization §Œ—ß¡ï (°˘’쌃”…¿¥§«§ §Ø°¢±æ∞k±Ì§À§™§§§∆§Œ∫Ù≥∆§«§π) 13 ÷∞∏ ÷∑® ¢Ÿ vocabulary §Ú a, b, °≠ µ»§Œ°∫Œƒ◊÷°ª§«≥ı∆⁄ªØ ¢⁄ —ß¡ï”√§Œ text •«©`•ø§Ú vocabulary §Ú§‚§»§À tokenize ¢€ ¢⁄§Œ token œµ¡–§À§™§§§∆∏˜ token §Œ°∫•⁄•¢°ª§Ú ˝§®§Î ¢‹ ¢€ §«◊Ó§‚ ˝§Œ∂‡§´§√§ø°∫•⁄•¢°ª§À§ƒ§§§∆ vocabulary?operation §À◊∑º” ¢› vocabulary §Œ¥Û§≠§µ§¨“é∂®§Œ ˝§Àfl_§∑§ø§ÈΩK¡À°£§Ω§¶§«§ §§àˆ∫œ ¢⁄ §ÿ er, a, b, c, ... ?T h e _ s c o r e _ b e c o m e s _ l o w er _ a n d _ l o w er . ?I _ h a v e _ a c h i e v e d _ b e t t er _ r e s u l t . °˘∫ÜÖg§Œ§ø§·°¢£≤ sentences vocabulary text •«©`•ø e-r °˙ er operation “‘Ωµ er §Ú•⁄•¢§»§∑§∆ tokenize
- 14. ? BPE tokenization §Œflm”√ ? Œƒ◊÷∑÷∏Ó§∑§ø·· operation §ÚÌò§Àflm”√ 14 ÷∞∏ ÷∑® e-r °˙ er t-h °˙ th th-e °˙ the operation T h e _ s c o r e _ b e c o m e s _ l o w e r _ a n d _ l o w e r . T h e _ s c o r e _ b e c o m e s _ l o w er _ a n d _ l o w er . ... Th e _ s c o r e _ b e c o m e s _ l o w er _ a n d _ l o w er . The _ s c o r e _ b e c o m e s _ l o w er _ a n d _ l o w er .... °˝ °˝ °˝
- 15. 15 ? BPE §œÑø¬ §Ë§Ø tokenize §«§≠§∆§§§Î ? # tokens: »´ token ˝ ? # types : vocabulary ˝ ? # UNK : test •«©`•ø§À§™§±§ÎŒ¥÷™’Z ˝ ? BPE (joint) : source & target §Œ—‘’Z§ÚÕ¨ïr§À tokenize BPE tokenization –‘ƒ‹ tokenize §ÀÈv§π§Î∏˜∑NΩy”ã¡ø
- 16. 16 ? òî°©§ metric §À§™§±§ÎÀ˚ ÷∑®§»§Œ±»›^ ? shortlist (char-bigram Õ‚§«ÑeÕæ”√“‚§µ§Ï§ø vocabulary) üo§∑§«§‚¡º§§–‘ƒ‹ ? rare §Àåù§π§Î–‘ƒ‹§¨¡º§§ BPE tokenization –‘ƒ‹
- 17. 17 ACL 2018 Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates [Kudo, 2018]
- 18. 18 ? BPE tokenization §¨õQ∂®µƒ§ tokenize §Ú––§¶§≥§»§ÚÜñÓ}“ï ? hello §œ±æ¿¥ hello, he-llo, h-e-l-l-o µ»òî°©§ ∑÷∏Ó§¨¥_¬ µƒ§À––§Ô§Ïµ√§Î ? ¥_¬ µƒ§À tokenize §Ú––§§’˝ÑtªØÑøπ˚§Ú∆⁄¥˝§π§Î ÷∑®§Ú÷∞∏ ? unigram language model •Ÿ©`•π§Œ ÷∑® ? Ñø¬ µƒ§À”ãÀ„§π§Î§ø§·°¢viterbi algorithm §» EM algorithm §ÚÅ„”√ ∏≈“™
- 19. 19 ? tokenize §œ±æ¿¥õQ∂®µƒ§«§œ§ §Ø¥_¬ µƒ§À±Ì¨F§µ§Ï§Î ? BPE tokenization §œõQ∂®µƒ ? ¥_¬ §œ•µ•Û•◊•Í•Û•∞§À§Ë§Í±Ì¨F •¢•§•«•¢ BPE ÷∞∏ •µ•Û•◊•Í•Û•∞§«±Ì¨F •«©`•ø•µ•§•∫ (Œƒ’¬ ˝) •‚•«•Î§Œ•—•È•·©`•ø tokenize §µ§Ï§ø s ∑¨ƒø§Œ ∑≠‘UåùœÛ tokenize §µ§Ï§ø s ∑¨ƒø§Œ ∑≠‘UΩYπ˚ s ∑¨ƒø§Œ»´ tokenize ∫Ú—a§À§ƒ§§§∆∆⁄¥˝Çé”ãÀ„
- 20. 20 ? ∏˜ token §¨∂¿¡¢§À…˙∆§π§Î§»§§§¶Å¢∂®§Ú÷√§Ø ? token ∫Ú—a§œ vocabulary (§≥§Ï§¨”Χ®§È§Ï§∆§§§Î«∞÷) §Œ“™Àÿ ? token œµ¡–§Œ…˙∆¥_¬ §¨§Ω§Ï§æ§Ï§Œ token §Œ§‚§Œ§Œ∑e§«±Ì¨Fø…ƒ‹ ? ··§œ token œµ¡–§Œ…˙∆¥_¬ §Àèͧ∏§∆—ß¡ïïr§À•µ•Û•◊•Í•Û•∞§π§Ï§–÷∞∏§¨åg¨Fø…ƒ‹ ? ◊Ó§‚¥_¬ §Œ∏fl§§ token œµ¡–§œ Viterbi algorithm §«Ñø¬ §Ë§Ø”ãÀ„ø…ƒ‹ (··§€§… π”√) Unigram Language Model I at a t s stay stayed ed t a y e d ... ... ... Œƒ§Œ token ˝ token œµ¡–§Œ…˙∆¥_¬
- 21. 21 ? ∏˜ token §¨∂¿¡¢§À…˙∆§π§Î§»§§§¶Å¢∂®§Ú÷√§Ø ? token ∫Ú—a§œ vocabulary (§≥§Ï§¨”Χ®§È§Ï§∆§§§Î«∞÷) §Œ“™Àÿ ? token œµ¡–§Œ…˙∆¥_¬ §¨§Ω§Ï§æ§Ï§Œ token §Œ§‚§Œ§Œ∑e§«±Ì¨Fø…ƒ‹ ? ··§œ token œµ¡–§Œ…˙∆¥_¬ §Àèͧ∏§∆—ß¡ïïr§À•µ•Û•◊•Í•Û•∞§π§Ï§–÷∞∏§¨åg¨Fø…ƒ‹ ? ◊Ó§‚¥_¬ §Œ∏fl§§ token œµ¡–§œ Viterbi algorithm §«Ñø¬ §Ë§Ø”ãÀ„ø…ƒ‹ (··§€§… π”√) Unigram Language Model I at a t s stay stayed ed t a y e d ... ... ... Œƒ§Œ token ˝ token œµ¡–§Œ…˙∆¥_¬ ¢Ÿ ∏˜ token §Œ…˙∆¥_¬ §œ§…§¶§‰§√§∆«Û§·§Î£ø ¢⁄ vocabulary §œ§…§¶§‰§√§∆¥_∂®§µ§ª§Î£ø
- 22. 22 ? L §Ú◊ӥ۪اπ§Î EM algorithm (appendix) §À§Ë§Í∏˜ token §Œ…˙∆¥_¬ §ÚÀ„≥ˆ ? ÎL§Ï≠˝ : ∏˜ token §Œ…˙∆¥_¬ ? E-step : M-step §Œ token œµ¡–§À§™§±§Î≥ˆ¨FÓl∂»§Àª˘§≈§≠°¢ÎL§Ï≠˝ §ÚÕ∆∂® ? M-step : ∏˜Œƒ§À§ƒ§§§∆°¢viterbi algorithm §«◊Ó§‚¥_§´§È§∑§§ token œµ¡–§Ú«Û§·§Î ∏˜ token §Œ…˙∆¥_¬ §Ú«Û§·§Î viterbi algorithm §«”ãÀ„ø…ƒ‹
- 23. 23 ? L §Ú◊ӥ۪اπ§Î EM algorithm (appendix) §À§Ë§Í∏˜ token §Œ…˙∆¥_¬ §ÚÀ„≥ˆ ? ÎL§Ï≠˝ : ∏˜ token §Œ…˙∆¥_¬ ? E-step : M-step §Œ token œµ¡–§À§™§±§Î≥ˆ¨FÓl∂»§Àª˘§≈§≠°¢ÎL§Ï≠˝ §ÚÕ∆∂® ? M-step : ∏˜Œƒ§À§ƒ§§§∆°¢viterbi algorithm §«◊Ó§‚¥_§´§È§∑§§ token œµ¡–§Ú«Û§·§Î ∏˜ token §Œ…˙∆¥_¬ §Ú«Û§·§Î viterbi algorithm §«”ãÀ„ø…ƒ‹ §≥§Œ≤Ÿ◊˜◊‘ç‚ vocabulary §¨§Ô§´§È§ §§§»flm”√§«§≠§ §§
- 24. 24 ? ∑¥èÕ‘á––§À§Ë§Í vocabulary §Ú∏¸–¬§∑§∆§§§Ø ? vocabulary §Œ¥_∂®§» token …˙∆¥_¬ §ŒÀ„≥ˆ§ÚÕ¨ïr§À––§¶§Œ§œÎy§∑§§ vocabulary §Ú«Û§·§Î ¢Ÿ heuristic §À¥Û§≠§·§Œ vocabulary §Œ≥ı∆⁄Çé§Ú‘O∂® ¢⁄ EM algorithm §À§Ë§Í token §Œ…˙∆¥_¬ §»¨F◊¥◊Ó¡º§Œ tokenization §ÚÀ„≥ˆ ¢€ ∏˜ token §Œ loss §Ú”ãÀ„ °˙ loss §œ∏˜ token §Ú vocabulary §´§Èíi§§§ø§»§≠§Œ L §Œúp…Ÿ∂»∫œ§§§´§ÈÀ„≥ˆ ¢‹ loss §À§Ë§Í token §Ú sort §∑°¢…œŒª ¶«% §Ú vocabulary §´§È≥˝Õ‚ ¢› vocabulary §Œ¥Û§≠§µ§¨÷∏∂®§∑§ø§‚§Œ§Ë§Í¥Û§≠§§àˆ∫œ°¢¢⁄ §À믧Î
- 25. 25 ? òî°©§ •≥©`•—•π…œ§« baseline (BPE) §»§§§Ø§ƒ§´§ŒÃ·∞∏ ÷∑®§Ú±»›^ ? l §œ∏˜Œƒ§À§ƒ§§§∆§Œ•µ•Û•◊•Í•Û•∞ ˝ (l=1 §œ unigram language model §«§Œ best § tokenization §Ú π”√) ? one-best vs n-best §œ∑≠‘U∫Ú—a§ŒÀ„≥ˆ ˝ (n-best §«§œ n ÇħŒƒ⁄ best § §‚§Œ§Ú π”√) ? ª˘±æµƒ§À÷∞∏ ÷∑®§œ”–Ñø°¢Ãÿ§À•«©`•ø§¨…Ÿ§ §§àˆ∫œ§œ§Ë§Í”–Ñø (augmentation Ñøπ˚) ÷∞∏ ÷∑®§Œ–‘ƒ‹
- 26. 26 ACL 2020 BPE-Dropout: Simple and E?ective Subword Regularization [Provilkov et al., 2020]
- 27. 27 ? tokenize §À§™§±§Î’˝ÑtªØ§Ú§Ë§Í•∑•Û•◊•Î§ BPE-dropout §«åg¨F ? ∫ÜÖg§Àflm”√§«§≠§Î…œ°¢–‘ƒ‹§‚¡º§§ ? kaggle §»§´§«§‚ 𧮧٧¶£ø ∏≈“™
- 28. 28 ? operation §Ú¥_¬ µƒ§Àflm”√ ? •‚•«•Î§Œ—ß¡ïïr§Œ§fl dropout §∑°¢Õ∆’ìïr§À§œÕ®≥£§Œ BPE §»Õ¨ò tokenization ÷∞∏ ÷∑® (BPE-dropout) e-r °˙ er t-h °˙ th th-e °˙ the operation ... T h e _ s c o r e _ b e c o m e s _ ... T h e _ s c o r e _ b e c o m e s _ ... Th e _ s c o r e _ b e c o m e s _ ... Th e _ s c o r e _ b e c o m e s _ ... ... °˝ °˝ °˝ ¿˝§®§–§≥§Ï§¨flm”√§µ§Ï § §´§√§øàˆ∫œ The §»§§§¶Ög’Z§œ token §À§ §È§ §§
- 30. 30 ACL 2020 Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation [He et al., 2020]
- 31. 31 ? °∫ôC–µ∑≠‘U§À§™§±§Î∑≠‘Uœ»§Œ§fl°ª§À tokenization ÷∑®§Ú÷∞∏ ? vocabulary §œ BPE §À§Ë§Í”Χ®§È§Ï§∆§§§Î«∞÷ ? Transformer §Ú π§√§ø context Ω‚·ã§À§Ë§ÎΩM∫œ§ª±¨∞k§Œªÿ±‹ ? Ñ”µƒ”ãª≠∑®§Ú π§√§∆Ñø¬ µƒ§À”ãÀ„ ∏≈“™
- 32. 32 ? ôC–µ∑≠‘U§À§™§±§Î°∫∑≠‘Uœ»Ç»§Œ—ß¡ï•«©`•ø°ª§Œ tokenization ÷∑® ? Dynamic Programming Encoding (DPE) •¢•§•«•¢
- 33. 33 ? tokenization §Œ À∑Ω§À§ƒ§§§∆§Œ÷‹fixªØ§Ú––§§§ø§§ ? tokenization §Ú«±‘⁄≠˝§À§Ë§Î§‚§Œ§»§fl§ §∑°¢§Ω§Œ÷‹fixªØ§À§Ë§Íµ√§È§Ï§Î Œƒ’¬◊‘猅˙∆¥_¬ §Œ◊ӥ۪اڃø÷∏§π ? “ª∑Ω°¢ΩM§fl∫œ§Ô§ª±¨∞k§«¨Fågµƒ§«§œ§ §§... °˙ °∫context°ª§ÚŒƒ◊÷•Ÿ©`•π§À§∑§∆ΩM§fl∫œ§Ô§ªœ˜úp£° •¢•§•«•¢ (∑≠‘UΩYπ˚§Œ) Œƒ’¬ (Œƒ◊÷§Œœµ¡–) ◊‘猅˙∆¥_¬ °∫context°ª= i ∑¨ƒø§fi§«§Œ tokenization §µ§Ï§ø∑≠‘UΩYπ˚§À“¿¥Ê (ﯧ´§Ï§∆§§§ §§§¨°¢∑≠‘U‘™ x §À§‚“¿¥Ê) tokenize §Œ À∑Ω (∑«≥£§À∂‡§§) i ∑¨ƒø§Œ token
- 34. 34 ? Transformer §Ú 𧧰¢k Œƒ◊÷ƒø§À§™§±§Îtoken …˙∆∑÷≤º§ÚÀ„≥ˆ ? »Î¡¶§¨°∫Œƒ◊÷°ª?≥ˆ¡¶§¨°∫token …˙∆∑÷≤º°ª ? §ø§¿§∑°¢(algirithm §À±Ì”õ§œ§ §§§¨) ∑≠‘U‘™ x §œ tokenize §µ§Ï§ø–Œ§«»Î¡¶ ? Ñ”µƒ”ãª≠∑®§À§Ë§ÍÑø¬ §Ë§Ø (mixed character-subword transformer §Ú) —ß¡ï ÷∞∏ ÷∑® ÷‹fixªØ§∑§∆µ√§È§Ï§ø y (∑≠‘U‘™§ŒŒƒ) §Œ…˙∆¥_¬ 1 §À§ §Î§Ë§¶§À—ß¡ï transformer §««Û§·§Î ÷‹fixªØ§µ§Ï§ø°∫context°ª§Œ…˙∆¥_¬ °£ §≥§Œ§‰§Í∑Ω÷ÿ—}”ãÀ„§Ú∑¿§∞ (Ñ”µƒ”ãª≠∑®) vocabulary §À§¢§Î token §Àœfi∂® k Œƒ◊÷ƒø°∫§fi§«°ª
- 35. 35 ? Õ∆’ì (tokenization) ïr§À§œ◊Ó§‚¥_¬ §Œ∏fl§§ token œµ¡–§Ú¿˚”√ ? §≥§Ï§À§Ë§Í°∫ôC–µ∑≠‘U§Œ∑≠‘Uœ»°ª§Œ tokenization §¨§«§≠°¢§≥§Œ token œµ¡–§Ú π§√§∆ôC–µ∑≠‘U§Ú—ß¡ï°£°∫∑≠‘U‘™°ª§À§œ BPE dropout §Ú π”√ ? —ß¡ï§À§™§±§Î log-sum-exp §¨ max §À§ §√§ø–Œ ÷∞∏ ÷∑®
- 36. 36 ? ∑≠‘U–‘ƒ‹§Ú BLEU §«‘uÅ˝ ? §€§‹»´§∆§Œ•±©`•π§«BPE dropout §Ë§Í§‚∏fl–‘ƒ‹ ? ∑≠‘U‘™§Œ tokenization §À“¿¥Ê§∑§∆∑≠‘Uœ»§Œ tokenize §Ú§«§≠§Î§Œ§¨–‘ƒ‹§Œ“ª“Ú Ã·∞∏ ÷∑®§Œ–‘ƒ‹
- 37. 37 ? BPE §‰§Ω§≥§´§È≈……˙§π§Î£¥§ƒ§Œ’쌃§Œ∏≈“™§ÚΩBΩÈ ? ¥_¬ §Œ±Ì¨F§‰§Ω§Œ∏flÀŸªØ§À§™§±§Îòî°©§ π§∑Ú ? ‘îºö§ ågÚYΩYπ˚µ»§œ’쌃§Ú≤Œ’’ ? “‘…œ£° §fi§»§·
- 38. 38 Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proc. of ACL. Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proc. of ACL. Philip Gage. 1994. A new algorithm for data compression. C Users J. 12(2):23®C38. Taku Kudo. 2018. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proc. of ACL. Ivan Provilkov, Dmitrii Emelianenko, and Elena Voita. 2020. Bpe-dropout: Simple and e?ective subword regularization. In Proc. of ACL. Xuanli He, Gholamreza Ha?ari, Mohammad Norouzi. 2020. Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation. In Proc. of ACL. ≤ŒøºŒƒœ◊
- 39. 39 APPENDIX
- 40. 40 ? ÎL§Ï≠˝§¨§¢§Îàˆ∫œ§À”»∂»§Œ◊ӥ۪اڧ∑§ø§§ÎH§À π”√§π§Î ? ”»∂»§¨ÎL§Ï≠˝§À“¿¥Ê§π§Î§¨°¢ÎL§Ï≠˝§œ”Qúy§«§≠§ §§ °˙ “‘œ¬§Œ ©––§«”»∂»§Œ∆⁄¥˝Ç駌◊ӥ۪اڿR§Í∑µ§π ¢Ÿ •«©`•ø§»¨F◊¥§Œ”Ëúy•—•È•·©`•ø§´§ÈÎL§Ï≠˝§Œ ¬··¥_¬ §Ú”ãÀ„§∑°¢ §≥§Ï§Ú”√§§§∆ (åù ˝) ”»∂»§Œ∆⁄¥˝Çé§Ú”ãÀ„ (E step) ¢⁄ (åù ˝) ”»∂»§Œ∆⁄¥˝Çé§Ú◊Ó¥ÛªØ§π•—•È•·©`•ø§ÚÕ∆∂® (M step) ¢€ Öß ¯§∑§ §§àˆ∫œ ¢Ÿ §À믧Π? ex) ªÏ∫œ’˝“é∑÷≤º§Œ•—•È•·©`•ø”Ëúy ? ÎL§Ï≠˝ : ∏˜•µ•Û•◊•Î§¨§…§Œ’˝“é∑÷≤º§À Ù§π§Î§´ (0 or 1) EM algorithm