














Advanced sampling part 1 presentation notes
- 1. Lunchtime Webinar Series: Advanced Sampling Part 1 1
- 2. Agenda ŌĆó Why do we work with samples? ŌĆó When is a sample representative? ŌĆó A review of the main sampling methods ŌĆó Understanding alpha and beta risks whilst making decisions based on sample data ŌĆó The importance of ŌĆ£critical differenceŌĆØ (delta) when sampling 2 ┬® BMGI. Except as may be expressly authorized by a written license agreement signed by BMGI, no portion may be altered, rewritten, edited, modified or used to create any derivative works.
- 3. Why do we work with samples? We often want to understand the nature of process we work with ŌĆō ŌĆ£population characteristicsŌĆØ. We also often need to find out if something has changed in the process or if the process differs depending on a certain factor. In many cases it is impossible or extremely difficult to measure the whole population (i.e. population is dynamic ŌĆō grows over time). Working with samples taken from population is always cheaper and faster. If we sample properly we are able to properly estimate population parameters. 3
- 4. When is a sample representative? A sample is representative when it can be reliably used to estimate population characteristics In order to obtain a representative sample we need to: ŌĆó Apply the appropriate sampling method ŌĆó Have a big enough sample 4
- 5. Main sampling methods Simple random sampling Simple random sampling is the sampling technique where every single item in the population has the same probability to be selected. This method can be used when population is homogenous. If the population is not homogenous, a simple random sample may result in inadequate representation. We need to understand what the population is. 5
- 6. Main sampling methods Stratified sampling Divide population into homogenous groups and randomly select from within each group. The groups themselves should differ from each other. The proportion of items in the sample from each group should be the same as the proportion of items in the population. This method can we used when the population can be divided into a reasonably small number of homogenous groups. 6
- 7. Main sampling methods Clustered sampling Divide population into many groups (sometimes these groups are ŌĆ£naturalŌĆØ and evident). Randomly select a few groups. Randomly sample from each of the selected groups. This method can be applied if most of the variation in the population is within the groups, not between them. 7
- 8. Main sampling methods Systematic sampling Start sampling with the randomly selected unit and sample every nth unit thereafter. Systematic samples are common in manufacturing and transactional environments. If people learn that every nth unit is sampled then sampling could become open to manipulation. 8
- 9. Risks related to samples Whenever we work with samples we try to make generalized conclusions about the population we draw the samples from. Whenever we work with sample data we try to find something we are purposefully looking for, e.g. the difference between different groups, change over time etc. Whenever we make conclusions about the population based on a sample we might be wrong. The only way to make sure that we are not wrong is to work with populations. 9
- 10. Risks related to samples There are two different types of errors we can make whilst working with sample data and making general conclusions about the population. 1. We believe we have discovered what we were looking for although this truly does not exist. This is called type I error, and probability of this event is denoted as alpha (╬▒) 2. Failing to discover what we were looking for although this truly exists. This is called type II error and probability of this event is denoted as beta (╬▓) 10
- 11. Risks related to samples Type I error is often called ŌĆ£false detectionŌĆØ: We detected something that does not truly exist, and this belief usually triggers a wrong action/decision. Type II error is often called ŌĆ£missed opportunityŌĆØ: We failed to detect something that truly exists. Making this conclusion that we did not detect what we were looking for, usually triggers no action. Determining acceptable levels of both risks is a business decision - usually it is set to ╬▒=5% and ╬▓=10% (Taking unnecessary actions is usually more painful than not taking necessary actions) 11
- 12. Risks related to samples For any conclusions made based on sample data, it is usually possible to calculate the risk of the conclusion being wrong. It is impossible to make both errors at the same time. It is an either/or situation depending on the conclusion we are making. The level of risk depends on a few factors ŌĆō one of them is sample size. Alpha risk is always calculated after sample data has been collected and analyzed (so called ŌĆ£p-valueŌĆØ). Beta risk can be usually calculated for a given sample size BEFORE data is collected and analyzed. 12
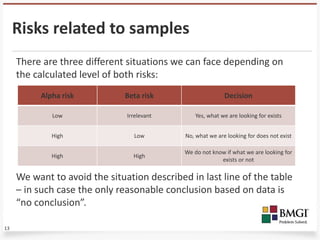
- 13. Risks related to samples There are three different situations we can face depending on the calculated level of both risks: Alpha risk Beta risk Decision Low Irrelevant Yes, what we are looking for exists High Low No, what we are looking for does not exist We do not know if what we are looking for High High exists or not We want to avoid the situation described in last line of the table ŌĆō in such case the only reasonable conclusion based on data is ŌĆ£no conclusionŌĆØ. 13
- 14. Importance of delta As you hopefully observed on the previous slides I mentioned a few times statement ŌĆ£what we are looking forŌĆØ. This is what we call ŌĆ£critical differenceŌĆØ ŌĆō the minimum difference we want to reliably detect. By ŌĆ£reliably detectŌĆØ we mean an acceptable low risk of failing to detect it, if the difference exists. Critical difference is denoted as delta (╬┤). Determination of the critical difference has massive impact on sample size. 14
- 15. Learn more! Free Tools, Templates & Courses & Workshops eLearning Learn more statistical analysis Visit our Open Access Website tools in the following courses: for more materials and free ŌĆó Six Sigma Green Belt learning on Lean Six Sigma, ŌĆó Six Sigma Black Belt Strategy execution, Change & ŌĆó Tool Master (advanced Innovation. statistical analysis tools) Open Access: Full Training Schedule: http://www.bmgi.org http://www.bmgi.com/training 15