












![DTW: Calcolo della distanza
Partendo dalla cella [1,1] viene calcolata la distanza euclidea tra ogni punto delle due serie, a
questa deve essere aggiunto il minimo tra:
ŌŚÅ il valore precedente sulle righe: cancellazione;
ŌŚÅ il valore precedente sulle colonne: inserimento;
ŌŚÅ il valore precedente in diagonale: corrispondenza.
DTW[i,j] := distance[i,j] + min(DTW[i-1, j],
DTW[i, j-1],
DTW[i-1, j-1])](https://image.slidesharecdn.com/dlimeetupunsupervisedlearningts-201020173735/85/Algoritmi-non-supervisionati-per-time-series-14-320.jpg)
![DTW: Warping Path
Partendo da DTW[0,0] costruire un percorso che tocchi il valore minimo muovendo da
sinistra verso destra, dallŌĆÖalto verso il basso.
ŌŚÅ spostamento orizzontale:
serie_2 ├© accelerata
durante questo intervallo.
ŌŚÅ spostamento verticale:
serie_2 ├© decelerata
durante questo intervallo.
ŌŚÅ spostamento diagonale:
durante questo periodo le
serie camminano di pari
passo.](https://image.slidesharecdn.com/dlimeetupunsupervisedlearningts-201020173735/85/Algoritmi-non-supervisionati-per-time-series-15-320.jpg)






![Piecewise Aggregate
Approximation
Idea
ŌĆ£riassumere la sequenza in una serie di segmenti che ne riducano la
lunghezza ma con la minima perdita di informazioneŌĆØ
Data una Time Series Y = [YŌéü, YŌéé, ŌĆ”,Yn] pu├▓ essere ridotta in una sequenza X = [XŌéü, XŌéé, ŌĆ”, Xm]
con mŌēżn utilizzando lŌĆÖequazione:
casi particolari:
ŌŚÅ m=n restituisce la serie originale
ŌŚÅ m=1 la nuova sequenza avr├Ā un solo valore pari alla media della time series originale](https://image.slidesharecdn.com/dlimeetupunsupervisedlearningts-201020173735/85/Algoritmi-non-supervisionati-per-time-series-22-320.jpg)



Algoritmi non supervisionati per time series
- 2. Chi sono Nicola ŌĆ£NicoŌĆØ Procopio Senior Data Scientist @ Dove ho lavorato Dove potremmo esserci gi├Ā incontrati Interessi ŌĆ£lavorativiŌĆØ Altro ŌŚÅ Lettore bulimico ŌŚÅ Ciclista/Hikers molto amatoriale ŌŚÅ Indie-Rock fan ŌŚÅ Innamorato della mia terra
- 3. Time Series: Definizione ŌĆ£una serie storica si definisce come un insieme di variabili casuali ordinate rispetto al tempoŌĆØ le cui osservazioni sono influenzate dal tempo stesso. Dato un fenomeno Y si indica con Yt lŌĆÖosservazione di tale fenomeno al tempo t={1, 2, ŌĆ”, T}
- 4. Time Series is Dynamic! ŌŚÅ Cross Sectional Data: una serie di variabili, rappresentative di un fenomeno, osservate in un particolare momento ŌŚŗ Esempio: abitudini di acquisto durante i saldi, prezzi degli immobili in base alle caratteristiche in un dato periodo ŌŚÅ Time Series Data: una singola variabile, rappresentativa di un fenomeno, osservata su pi├╣ periodi della stessa dimensione ŌŚŗ Esempio: il PIL negli ultimi 30 anni, la fornitura elettrica bimestrale E le serie storiche MULTIVARIATE?
- 5. Problemi pi├╣ comuni Forecasting Classification Anomaly Detection
- 6. In (MY) Real World Approccio Supervisionato: ŌŚÅ infinita letteratura e codice on-line da studiare e riciclare ŌŚÅ poche aziende hanno uno storico di dati etichettati da utilizzare nella fase di training
- 7. Possibili soluzioni Etichettare lo storico dati a mano ATTENZIONE: potrebbe nuocere alla salute ATTENZIONE: coinvolgere lŌĆÖesperto di dominio Etichettare lo storico dati con algoritmi non supervisionati
- 8. Basics Approccio NON Supervisionato: ŌŚÅ non cŌĆÖ├© bisogno di dati etichettati ŌŚÅ lavora sulla similarit├Ā, le distanze, la densit├Ā ŌŚÅ ha lŌĆÖobiettivo di creare gruppi pi├╣ omogenei possibile al loro interno ed eterogenei tra loro Tecniche pi├╣ comuni: ŌŚÅ Clustering ŌŚÅ Dimensionality Reduction
- 9. Problema: misurare distanza Calcolo della distanza tra osservazioni Ogni Time Series ├© una singola osservazione
- 10. Dynamic Time Warping "Il Dynamic Time Warping, o DTW, ├© un algoritmo che permette l'allineamento tra due sequenze, e che pu├▓ portare ad una misura di distanza tra le due sequenze allineate. Tale algoritmo ├© particolarmente utile per trattare sequenze in cui singole componenti hanno caratteristiche che variano nel tempo, e per le quali la semplice espansione o compressione lineare delle due sequenze non porta risultati soddisfacenti." Fonte Wikipedia
- 11. DTW: Prerequisiti Per calcolare la distanza tra due sequenze, indipendentemente dalla loro lunghezza, col DTW devono essere presenti i seguenti requisiti: ŌŚÅ ogni indice della prima sequenza deve poter essere confrontato con tutti gli indici delle altre e viceversa; ŌŚÅ il primo indice della prima sequenza deve essere associato al primo indice dell'altra sequenza (ma non deve essere la sua unica corrispondenza); ŌŚÅ l'ultimo indice della prima sequenza deve corrispondere all'ultimo indice dell'altra sequenza (ma non deve essere la sua unica corrispondenza); ŌŚÅ la mappatura degli indici dalla prima sequenza agli indici delle altre sequenze deve essere monotonicamente crescente. A grandi linee, indipendentemente dalla lunghezza delle serie l'indice iniziale e finale devono coincidere.
- 12. DTW: Algoritmo Date due sequenze di lunghezza diversa se volessimo calcolarne la similarit├Ā utilizzando il DTW per prima cosa bisogna creare una matrice m x n dove (m,n) sono le lunghezze delle serie + 1
- 13. DTW: Cold Start Il cold start ├© il confronto con i periodi precedenti quando si ├© al primo passo dell'algoritmo. Impostando una riga fittizia ad infinito non si incorre in situazioni anomale e si evita di implementare condizioni sullo start che appesantirebbero ulteriormente il calcolo.
- 14. DTW: Calcolo della distanza Partendo dalla cella [1,1] viene calcolata la distanza euclidea tra ogni punto delle due serie, a questa deve essere aggiunto il minimo tra: ŌŚÅ il valore precedente sulle righe: cancellazione; ŌŚÅ il valore precedente sulle colonne: inserimento; ŌŚÅ il valore precedente in diagonale: corrispondenza. DTW[i,j] := distance[i,j] + min(DTW[i-1, j], DTW[i, j-1], DTW[i-1, j-1])
- 15. DTW: Warping Path Partendo da DTW[0,0] costruire un percorso che tocchi il valore minimo muovendo da sinistra verso destra, dallŌĆÖalto verso il basso. ŌŚÅ spostamento orizzontale: serie_2 ├© accelerata durante questo intervallo. ŌŚÅ spostamento verticale: serie_2 ├© decelerata durante questo intervallo. ŌŚÅ spostamento diagonale: durante questo periodo le serie camminano di pari passo.
- 16. DTW: Miglioramenti Window Constraint Per rendere pi├╣ performante lŌĆÖalgoritmo viene impostata una finestra temporale w su cui calcolare la distanza. Utile per sequenze lunghe che produrrebbero confronti inutili tra periodi molto distanti tra loro. FastDTW EŌĆÖ forse la versione pi├╣ conosciuta dellŌĆÖalgoritmo. Si basa su alcune approssimazioni che velocizzano il calcolo. Molto studiato e discusso perch├© non sempre la performance porta a risultati di qualit├Ā accettabile.
- 17. DTW: Applicazioni Anomaly detection Trovare pattern anomali in ambito health, ad esempio una persona che deambula a velocit├Ā diversa, o parla pi├╣ lentamente/velocemente potrebbe aiutare nella diagnosi. Customer Segmentation Profilare le abitudini in ambito utilities per proporre nuove offerte o prevenire frodi. Forecasting Evaluation Misurare la distanza tra dato reale e stime.
- 18. DTW e K-Means
- 19. Dimensionality Reduction In termini estremamente semplicistici: ŌĆ£prendo un fenomeno molto complesso, condenso lŌĆÖinformazione (con una perdita accettabile) mediante un algoritmo, restituisco lo stesso fenomeno ma con una visione meno dettagliataŌĆØ Time Series? N.B. Non siate estremisti come Drake
- 20. SAX Encoding Symbolic Aggregate approXimation Encoding: ŌŚÅ inventato nel 2002 da Keogh e Lin ŌŚÅ trasforma le time series in sequenze di simboli ŌŚÅ robusta ai valori mancanti ŌŚÅ non supervisionata ŌŚÅ basata sia sui volumi che sugli andamenti Adolphe Sax inventore del sassofono. Correlazione(SAX, Sax) = 0.00
- 21. Preparazione del dataset Il SAX Encoding ha bisogno di serie storiche disposte come segue: ŌŚÅ per ogni riga una serie storica ŌŚÅ per ogni colonna uno step temporale ŌŚÅ i dati devono essere standardizzati dati della protezione civile sul Covid-19
- 22. Piecewise Aggregate Approximation Idea ŌĆ£riassumere la sequenza in una serie di segmenti che ne riducano la lunghezza ma con la minima perdita di informazioneŌĆØ Data una Time Series Y = [YŌéü, YŌéé, ŌĆ”,Yn] pu├▓ essere ridotta in una sequenza X = [XŌéü, XŌéé, ŌĆ”, Xm] con mŌēżn utilizzando lŌĆÖequazione: casi particolari: ŌŚÅ m=n restituisce la serie originale ŌŚÅ m=1 la nuova sequenza avr├Ā un solo valore pari alla media della time series originale
- 23. Piecewise Aggregate Approximation Molto importante scegliere la finestra temporale di approssimazione w con un esperto di dominio. Questo influisce sul numero di segmenti, se len(TS)/w non ├© un intero arrotondare per eccesso cos├¼ da non perdere informazioni.
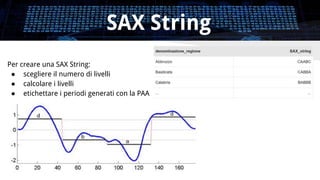
- 24. SAX String Per creare una SAX String: ŌŚÅ scegliere il numero di livelli ŌŚÅ calcolare i livelli ŌŚÅ etichettare i periodi generati con la PAA
- 25. Anomaly Detection ŌŚÅ LŌĆÖanomalia non ├© una sola osservazione ma unŌĆÖintera serie storica 1. Fissare un limite entro il quale etichettiamo il pattern come anomalo 2. Calcolare la frequenza per ogni SAX String
- 26. Grazie a tutti! Domande? Nicola Procopio Breve introduzione al DTW SAX Encoding @nickprock