


































![STATE, ACTION
SUPERMARIO WITH R.L
env.observation_space.shape
(240, 256, 3) # [ height, weight, channel ]
env.action_space.n
256
SIMPLE_MOVEMENT = [
[ŌĆśnopŌĆÖ],
[ŌĆśrightŌĆÖ],
[ŌĆśrightŌĆÖ,ŌĆÖAŌĆÖ],
[ŌĆśrightŌĆÖ,ŌĆÖBŌĆÖ],
[ŌĆśrightŌĆÖ,ŌĆÖAŌĆÖ,ŌĆÖBŌĆÖ],
[ŌĆśAŌĆÖ],
[ŌĆśleftŌĆÖ],
]
ŌĆ©
ŌĆ©
from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
import gym_super_mario_brosŌĆ©
env = gym_super_mario_bros.make(ŌĆśSuperMarioBros-v0ŌĆÖ)
env =BinarySpaceToDiscreteSpaceEnv(env, SIMPLE_MOVEMENT)](https://image.slidesharecdn.com/allaboutaisupermario-180815072940/85/All-about-A-I-SuperMario-Reinforcement-Learning-38-320.jpg)

![REPLAY MEMORY BUFFER
SUPERMARIO WITH R.L
memory = deque([],maxlen=1000000)
memory.append(state,action,reward,next_state)
(St, At, Rt+1, St+1)
next_state, reward, done, info = env.step(action)
eps_min = 0.1
eps_max = 1
eps_decay_steps = 200000](https://image.slidesharecdn.com/allaboutaisupermario-180815072940/85/All-about-A-I-SuperMario-Reinforcement-Learning-40-320.jpg)







All about A.I SuperMario (Reinforcement Learning)
- 1. ņØĖĻ│Ąņ¦ĆļŖź ņŖłĒŹ╝ļ¦łļ”¼ņśżņØś Ļ▒░ņØś ļ¬©ļōĀ Ļ▓ā Reinforcement Learning Wonseok Jung
- 2. ņĀĢņøÉņäØŌĆ© Wonseok Jung City University of New York ŌĆ£- Baruch College (Data Science Major) ConnexionAI A.I Researcher DeepLearningCollege Reinforcement Learning Researcher ļ¬©ļæÉņØśņŚ░ĻĄ¼ņåī CTRL (Contest in RL) Leader Project what IŌĆÖve done : Reinforcement Learning, ŌĆ© Object Detection, Chatbot Github: https://github.com/wonseokjung Facebook: https://www.facebook.com/ws.jung.798 Blog: https://wonseokjung.github.io/
- 3. ļ¬®ņ░© 1. How Animals Learn 2. How Humans Learn 3. Reinforcement Learning 4. SuperMario with Reinforcement Learning REINFORCEMENT LEARNING
- 4. PREVIEW REINFORCEMENT LEARNING Animal Human SuperMario A A Env R AtRt SSt Rt+1 St+1 Reinforcement Learning Agent Environment
- 6. HABUTUATION - ļ¬©ļōĀ ļÅÖļ¼╝ņØĆ ĒĢÖņŖĄļŖźļĀźņØ┤ ņ׳ļŗż. - 300ņŚ¼Ļ░£ņØś ņŗĀĻ▓ĮņäĖĒżļ¦īņØä Ļ░¢Ļ│Ā ņ׳ļŖö ņśłņü£Ļ╝¼ļ¦łņäĀņČ® ļśÉĒĢ£ ĒĢÖņŖĄļŖźļĀźņØ┤ ņ׳ļŗż. - Head withdrawal reflex : ņ£äĒŚśĒĢ£ ļ¼╝ņ▓┤Ļ░Ć ņ׳ņØäĻ▓āņØ┤ļØ╝ ĒīÉļŗ©ņŚÉ ļö░ļźĖ ļ░śņé¼Ē¢ēļÅÖ - ņśłņü£Ļ╝¼ļ¦łņäĀņČ®ņØś ļ©Ėļ”¼ļź╝ Ļ▒┤ļō£ļ”¼ļ®┤ ņØ╝ņĀĢ Ļ▒░ļ”¼ļź╝ ļÆżļĪ£ Ļ░äļŗż. HOW ANIMALS LEARN
- 7. HABUTUATION HOW ANIMALS LEARN First try Second try Third try
- 8. LAW OF EFFECT - Edward Thorndike(1898) - Law of effect : ņ¢┤ļ¢ż Ē¢ēļÅÖņØś Ļ▓░Ļ│╝Ļ░Ć ļ¦īņĪ▒ņŖżļ¤¼ņÜ░ļ®┤ ļŗżņØīņŚÉļÅä ĻĘĖ Ē¢ēļÅÖņØä ļ░śļ│ĄĒĢ£ļŗż. ļ░śļīĆļĪ£ ļ¦īņĪ▒ĒĢśņ¦Ć ņĢŖņ£╝ļ®┤ ĻĘĖ Ē¢ēļÅÖņØä ĒĢśņ¦Ć ņĢŖļŖöļŗż. - Reinforcement(Ļ░ĢĒÖö) : ņØ┤ņĀäņŚÉ ņØ╝ņ¢┤ļé£ Ē¢ēļÅÖņØä ļ░śļ│ĄĒĢśĻ▓ī ļ¦īļō£ļŖö ņ×ÉĻĘ╣ - Punishment(ņ▓śļ▓ī) : ņØ┤ņĀäņŚÉ ņØ╝ņ¢┤ļé£ Ē¢ēļÅÖņØä Ēö╝ĒĢśĻ▓ī ļ¦īļō£ļŖö ņ×ÉĻĘ╣ HOW ANIMALS LEARN
- 9. EXAMPLE OF LAW OF EFFECT HOW ANIMALS LEARN
- 10. HOW HUMANS LEARN
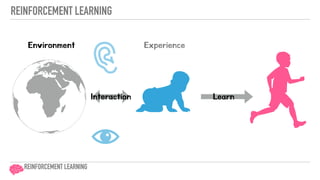
- 11. INTERACTION WITH ENVIRONMENT REINFORCEMENT LEARNING Environment Experience LearnInteraction
- 12. HOW HUMANS LEARN? - Reinforcement : ņØ┤ņĀäņŚÉ ņØ╝ņ¢┤ļé£ Ē¢ēļÅÖņØä ļ░śļ│ĄĒĢśĻ▓ī ļ¦īļō£ļŖö ņ×ÉĻĘ╣ - Punishment : ņØ┤ņĀäņŚÉ ņØ╝ņ¢┤ļé£ Ē¢ēļÅÖņØä Ēö╝ĒĢśĻ▓ī ļ¦īļō£ļŖö ņ×ÉĻĘ╣ HOW HUMANS LEARN
- 13. HOW HUMANS LEARN Experiment Using Tap ball HOW HUMANS LEARN https://www.youtube.com/watch?v=2sicukP34fk
- 14. HOW HUMANS LEARN -TAP BALL Day 1 Day 2 Day 3 Day 4 ņĄ£Ļ│ĀņĀÉņłś : 3ŌĆ© ļ¦×ņØĆĒܤņłś : 2 ņĄ£Ļ│ĀņĀÉņłś : 23ŌĆ© ļ¦×ņØĆĒܤņłś : 0 ņĄ£Ļ│ĀņĀÉņłś : 30ŌĆ© ļ¦×ņØĆĒܤņłś : 0 ņĄ£Ļ│ĀņĀÉņłś : 38 ļ¦×ņØĆĒܤņłś : 1 HOW HUMANS LEARN
- 15. HOW HUMAN LEARN Day 5 ņĄ£Ļ│ĀņĀÉņłś : 79 ļ¦×ņØĆĒܤņłś : 0 HOW HUMANS LEARN
- 16. SIMILARITY LEARNING METHOD B/W ANIMALS AND HUMAN HOW HUMANS LEARN Punishment Punishment Punishment
- 18. REINFORCEMENT LEARNING Environment Experience Learn REINFORCEMENT LEARNING Interaction
- 19. ņÜ®ņ¢┤ ņĀĢņØś Time step Action Transition Function Reward Set of states Set of actions Start state Discount factor t a P(sŌĆ▓, r ŌłŻ s, a) r A S S0 ╬│ Set of rewardŌĆ© ŌĆ© Policy Reward State R ŽĆ r REINFORCEMENT LEARNING s
- 20. TERMINATION Time step Action Transition Function Reward Set of states Set of actions Start state Discount factor t a P(sŌĆ▓, r ŌłŻ s, a) r A S S0 ╬│ Set of rewardŌĆ© ŌĆ© Policy Reward State R ŽĆ r REINFORCEMENT LEARNING s
- 21. LEARNING - Reinforcement learningņØĆ Reward(ļ│┤ņāü)ņØä ņĄ£ļīĆĒÖö ĒĢśļŖö action(Ē¢ēļÅÖ)ņØä ņäĀĒāØĒĢ£ļŗż. - Learner(ļ░░ņÜ░ļŖöņ×É)ļŖö ņŚ¼ļ¤¼ actionņØä ĒĢ┤ļ│┤ļ®░, rewardļź╝ Ļ░Ćņן ļåÆĻ▓ī ļ░øļŖö actionņØä ņ░ŠļŖöļŗż. -ņäĀĒāØļÉ£ actionņØ┤ ļŗ╣ņןņØś reward ļ┐Éļ¦ī ņĢäļŗī, ļŗżņØīņØś ņāüĒÖ® ļśÉļŖö ļŗżņØī ņØ╝ņ¢┤ļéśĻ▓ī ļÉĀ rewardņŚÉļÅä ņśüĒ¢źņØä ļü╝ņ╣ĀņłśļÅä ņ׳ļŗż. Action ļŗ╣ņןņØś ņāüĒÖ® ļ│ĆĒÖö ļ»ĖļלņØś ņāüĒÖ®Reward ļ»ĖļלņØś Reward REINFORCEMENT LEARNING
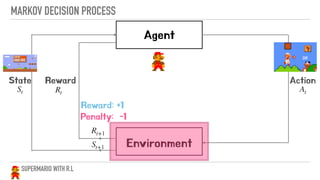
- 22. MARKOV DECISION PROCESS Action Agent Environment Reward AtRt State St Rt+1 St+1 REINFORCEMENT LEARNING
- 23. TOTAL REWARD REINFORCEMENT LEARNING Return of Episode Return of Episode with discount factor
- 25. STATE-ACTION VALUE FUNCTION State-Action value REINFORCEMENT LEARNING
- 26. OPTIMAL POLICY Optimal State-Value function REINFORCEMENT LEARNING Optimal State-Action value function
- 27. Agent Exploitation Exploration ? EXPLOITATION AND EXPLORATION REINFORCEMENT LEARNING
- 28. IMPORTANCE OF EXPLORATION ņģĆņØ┤ RussianBlue 2ņé┤ CuriosityŌĆ© ĒÆĆņØ┤ Munchkin 1ņé┤ Food REINFORCEMENT LEARNING
- 29. IMPORTANCE OF EXPLORATION REINFORCEMENT LEARNING ĒÆĆņØ┤ ņģĆņØ┤ ZeroŌĆ© exploration Exploration
- 30. IMPORTANCE OF EXPLORATION-2 REINFORCEMENT LEARNING ĒÆĆņØ┤ ņģĆņØ┤ Fail
- 31. SUPERMARIO WITH REINFORCEMENT LEARNING
- 32. MARKOV DECISION PROCESS Action Agent Environment Reward AtRt State St Rt+1 St+1 SUPERMARIO WITH R.L Reward: +1 Penalty: -1
- 33. MARKOV DECISION PROCESS Action Agent Environment Reward AtRt State St Rt+1 St+1 SUPERMARIO WITH R.L Reward: +1 Penalty: -1
- 34. SUPERMARIO WITH R.L https://github.com/wonseokjung/gym-super-mario-bros pip install gym-super-mario-brosŌĆ© ŌĆ© import gym_super_mario_brosŌĆ© env = gym_super_mario_bros.make(ŌĆśSuperMarioBros-v0') env.reset() env.render() INSTALL AND IMPORT ENVIRONMENT
- 35. WORLDS & LEVELS SUPERMARIO WITH R.L World 1 World 3 World 2 World 4 env = gym_super_mario_bros.make('SuperMarioBros-<world>-<level>-v<version>')
- 37. REWARD AND PENALTY SUPERMARIO WITH R.L Reward Penalty Ļ╣āļ░£ņŚÉ Ļ░ĆĻ╣īņøīņ¦Ćļ®┤ + ļ¬®Ēæ£ņŚÉ ļÅäņ░®ĒĢśļ®┤ + ļ¬®Ēæ£ļŗ¼ņä▒ĒĢśņ¦Ć ļ¬╗ĒĢśļ®┤ - ņŗ£Ļ░äņØ┤ ņ¦ĆļéĀļĢīļ¦łļŗż - Ļ╣āļ░£ņŚÉņä£ ļ®Ćņ¢┤ņ¦Ćļ®┤ -
- 38. STATE, ACTION SUPERMARIO WITH R.L env.observation_space.shape (240, 256, 3) # [ height, weight, channel ] env.action_space.n 256 SIMPLE_MOVEMENT = [ [ŌĆśnopŌĆÖ], [ŌĆśrightŌĆÖ], [ŌĆśrightŌĆÖ,ŌĆÖAŌĆÖ], [ŌĆśrightŌĆÖ,ŌĆÖBŌĆÖ], [ŌĆśrightŌĆÖ,ŌĆÖAŌĆÖ,ŌĆÖBŌĆÖ], [ŌĆśAŌĆÖ], [ŌĆśleftŌĆÖ], ] ŌĆ© ŌĆ© from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv import gym_super_mario_brosŌĆ© env = gym_super_mario_bros.make(ŌĆśSuperMarioBros-v0ŌĆÖ) env =BinarySpaceToDiscreteSpaceEnv(env, SIMPLE_MOVEMENT)
- 39. EXPLOITATION AND EXPLORATION SUPERMARIO WITH R.L next_state, reward, done, info = env.step(action) def epsilon_greedy(q_value,step): if np.random.rand() < epsilon : return np.random.randint(output) else : ŌĆ© action = np.argmax(output) Exploitation Exploration
- 40. REPLAY MEMORY BUFFER SUPERMARIO WITH R.L memory = deque([],maxlen=1000000) memory.append(state,action,reward,next_state) (St, At, Rt+1, St+1) next_state, reward, done, info = env.step(action) eps_min = 0.1 eps_max = 1 eps_decay_steps = 200000
- 41. MINIMIZE LOSS SUPERMARIO WITH R.L import tensorflow as tf loss = tf.reduce_mean(tf.squre( y - Q_action ) ) Optimizer =tf.train.AdamsOptimizer(learning_rate) training_op = optimizer.minize(loss) (Rt+1 + ╬│t+1maxaŌĆ▓q╬Ė(St+1, aŌĆ▓ ) ŌłÆ q╬Ė(St, At))2 (St, At, Rt+1, St+1)
- 42. MINIMIZE LOSS SUPERMARIO WITH R.L import tensorflow as tf loss = tf.reduce_mean(tf.squre( y - Q_action ) ) Optimizer =tf.train.AdamsOptimizer(learning_rate) training_op = optimizer.minize(loss) (Rt+1 + ╬│t+1maxaŌĆ▓q╬Ė(St+1, aŌĆ▓ ) ŌłÆ q╬Ė(St, At))2 (St, At, Rt+1, St+1)
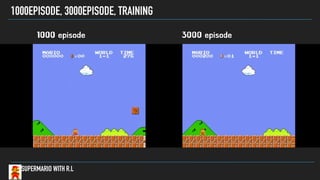
- 44. 1000EPISODE, 3000EPISODE, TRAINING SUPERMARIO WITH R.L 1000 episode 3000 episode
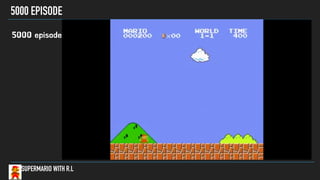
- 45. 5000 EPISODE SUPERMARIO WITH R.L 5000 episode
- 46. SUMMARY 1. How Animals Learn 2. How Humans Learn 3. Reinforcement Learning 4. SuperMario with Reinforcement Learning REINFORCEMENT LEARNING
- 47. REFERENCES 1. Habituation The Birth of Intelligence 2. Law of effect : The Birth of Intelligence ,p.171 3. Thorndike, E. L. (1905). The elements of psychology. New York: A. G. Seiler. 4. Thorndike, E. L. (1898). Animal intelligence: An experimental study of the associative processes in animals. Psychological Monographs: General and Applied, 2(4), i-109. 5. Supermario environment ŌĆ© https://github.com/Kautenja/gym-super-mario-bros 6. http://faculty.coe.uh.edu/smcneil/cuin6373/idhistory/thorndike_extra.html
- 48. Question?