AlphaGo, мғҲлЎңмҡҙ мӢңлҢҖмқҳ мӢңмһ‘
Download as pptx, pdf24 likes4,198 views

DeepMindмқҳ AlphaGo мҶҢк°ңмҷҖ к·ё мӢңмӮ¬м җ - AlphaGo мӮ¬кұҙ - л°”л‘‘ н”„лЎңк·ёлһЁ н•ңкі„ - AlphaGo кө¬м„ұ - мқҙм„ёлҸҢ 9лӢЁ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё - AlphaGo мқҳмқҳ



























AlphaGo, мғҲлЎңмҡҙ мӢңлҢҖмқҳ мӢңмһ‘
- 1. 1 AlphaGo, мғҲлЎңмҡҙ мӢңлҢҖмқҳ мӢңмһ‘ 2016.03.02 Youngsung Son
- 2. 2 Agenda пӮ§ AlphaGo мӮ¬кұҙ пӮ§ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ пӮ§ AlphaGo кө¬м„ұ пӮ§ мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кі„нҡҚ пӮ§ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё пӮ§ AlphaGo мқҳмқҳ пӮ§ м°ёкі
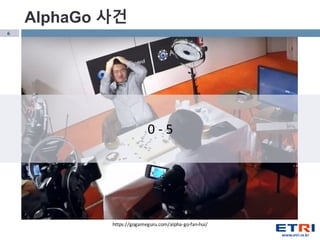
- 4. 4 https://gogameguru.com/alpha-go-fan-hui/ Fan Hui 2лӢЁ Europe Champion 4нҡҢ (2013,2014,2015,2016) AlphaGo мӮ¬кұҙ
- 5. 5 пӮ§ 5лІҲ лҢҖкөӯ вҖ“ мҳӨм „ кіөмӢқкІҪкё°: м ңн•ңмӢңк°„ 1мӢңк°„, 30мҙҲ 3нҡҢ мҙҲмқҪкё° вҖ“ мҳӨнӣ„ 비кіөмӢқкІҪкё°: м ңн•ңмӢңк°„ м—Ҷмқҙ 30мҙҲ 3нҡҢ мҙҲмқҪкё° пӮ§ кІ°кіј вҖ“ мҳӨм „ : Fan Hui 0-5 AlphaGo вҖ“ мҳӨнӣ„ : Fan Hui 2-3 AlphaGo AlphaGo мӮ¬кұҙ http://www.yonhapnews.co.kr/bulletin/2016/02/15/0200000000AKR20160215002700007.HTML
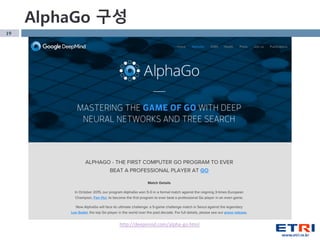
- 8. 8 Alpha Go мӮ¬кұҙ Mastering the game of Go with deep neural networks and tree search вҖ“ Nature, 2016
- 9. 9 Agenda пӮ§ Alpha Go мӮ¬кұҙ пӮ§ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ пӮ§ Alpha Go кө¬м„ұ пӮ§ мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кі„нҡҚ пӮ§ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё пӮ§ Alpha Go мӢңмӮ¬м җ пӮ§ м°ёкі
- 10. 10 http://time.com/3705316/deep-blue-kasparov/ мІҙмҠӨл§ҲмҠӨн„° Kasparov vs. IBM DeepBlue 1997.12 л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„
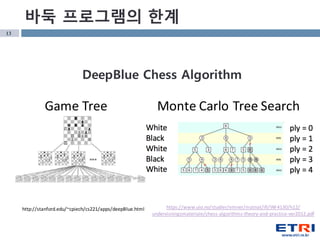
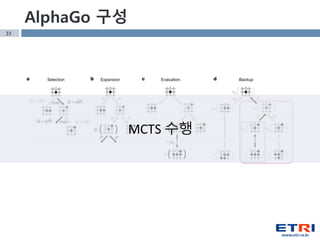
- 13. 13 http://stanford.edu/~cpiech/cs221/apps/deepBlue.html https://www.uio.no/studier/emner/matnat/ifi/INF4130/h12/ undervisningsmateriale/chess-algorithms-theory-and-practice-ver2012.pdf DeepBlue Chess Algorithm л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ Monte Carlo Tree SearchGame Tree
- 14. 14 л„Ҳл¬ҙлӮҳлҸ„ л§ҺмқҖ кІҪмҡ°мқҳ мҲҳ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„
- 15. 15 2081681993819799846 9947863334486277028 6522453884530548425 6394568209274196127 3801537852564845169 8519643907259916015 6281285460898883144 2712971531931755773 6620397247064840935 (19x19 board) 361! л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„
- 16. 16 Agenda пӮ§ AlphaGo мӮ¬кұҙ пӮ§ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ пӮ§ AlphaGo кө¬м„ұ пӮ§ мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кі„нҡҚ пӮ§ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё пӮ§ AlphaGo мӢңмӮ¬м җ пӮ§ м°ёкі
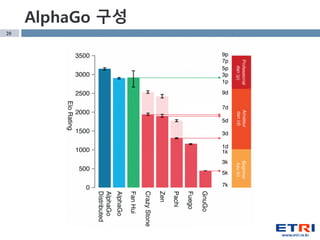
- 17. 17 48 CPU 494 : 1 1202 CPU 5 : 0 мҳЁлқјмқё KGS л°”л‘‘ кі мҲҳ(5~9лӢЁ) 16л§Ң кё°ліҙ 3000л§Ң м°©м җ н•ҷмҠө 100л§ҢлІҲ selfлҢҖкөӯ н•ҳлЈЁ 3л§Ң лҢҖкөӯ н•ҷмҠө AlphaGo кө¬м„ұ
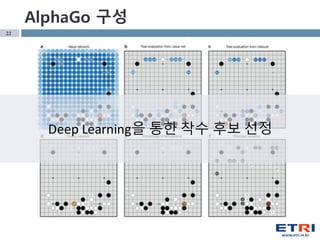
- 22. 22 AlphaGo кө¬м„ұ Deep Learningмқ„ нҶөн•ң м°©мҲҳ нӣ„ліҙ м„ м •
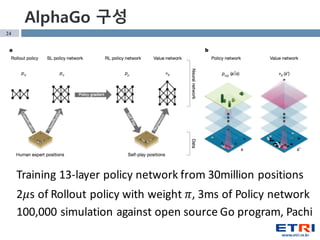
- 24. 24 100,000 simulation against open source Go program, Pachi AlphaGo кө¬м„ұ Training 13-layer policy network from 30million positions 2рқңҮs of Rollout policy with weight рқңӢ, 3ms of Policy network
- 25. 25 Agenda пӮ§ Alpha Go мӮ¬кұҙ пӮ§ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ пӮ§ Alpha Go кө¬м„ұ пӮ§ мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кі„нҡҚ пӮ§ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё пӮ§ Alpha Go мӢңмӮ¬м җ пӮ§ м°ёкі
- 26. 26 мқҙм„ёлҸҢ 9лӢЁ лҢҖкөӯ кі„нҡҚ
- 27. 27 пӮ§ мқјм • вҖ“ 1көӯ : 3мӣ” 9мқј (мҲҳ) мҳӨнӣ„ 1мӢң вҖ“ 2көӯ : 3мӣ” 10мқј (лӘ©) мҳӨнӣ„ 1мӢң вҖ“ 3көӯ : 3мӣ” 12мқј (нҶ ) мҳӨнӣ„ 1мӢң вҖ“ 4көӯ : 3мӣ” 13мқј (мқј) мҳӨнӣ„ 1мӢң вҖ“ 5көӯ : 3мӣ” 15мқј (нҷ”) мҳӨнӣ„ 1мӢң пӮ§ мғҒлҢҖ : Aja Huang м•„л§Ҳ 6лӢЁ (DeepMind м§Ғмӣҗ) пӮ§ мһҘмҶҢ : м„ңмҡё кҙ‘нҷ”л¬ё нҸ¬мӢңмҰҢмҠӨ нҳён…” нҠ№лі„ лҢҖкөӯмһҘ пӮ§ к·ңм№ҷ вҖ“ мӨ‘көӯк·ңм№ҷ, м ңн•ң мӢңк°„ 2мӢңк°„, 1분 мҙҲмқҪкё° 3нҡҢ (4~5мӢңк°„ мҳҲмғҒ) пӮ§ мғҒкёҲ 12м–өмӣҗ($1M) (мҠ№мһҗ? 5нҢҗ лӘЁл‘җ мҠ№лҰ¬?) мқҙм„ёлҸҢ 9лӢЁ лҢҖкөӯ кі„нҡҚ
- 28. 28 Agenda пӮ§ Alpha Go мӮ¬кұҙ пӮ§ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ пӮ§ Alpha Go кө¬м„ұ пӮ§ мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кі„нҡҚ пӮ§ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё пӮ§ Alpha Go мӢңмӮ¬м җ пӮ§ м°ёкі
- 29. 29 мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё (1/3) мқҙм„ёлҸҢмқҳ нқ”л“Өкё°? м•ҢнҢҢкі лҠ” мқҙм°Ҫнҳё мҠӨнғҖмқј?
- 30. 30 мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё (2/3) мӨ‘көӯ к·ңм№ҷ мқјкіұ집л°ҳ лҚӨ 2мӢңк°„ 60мҙҲ 3лІҲ мҙҲмқҪкё°
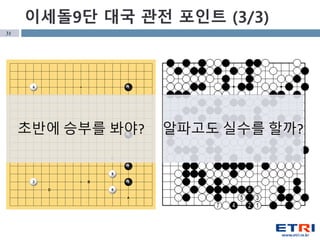
- 31. 31 мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё (3/3) м•ҢнҢҢкі лҸ„ мӢӨмҲҳлҘј н• к№Ң?мҙҲл°ҳм—җ мҠ№л¶ҖлҘј лҙҗм•ј?
- 32. 32 Agenda пӮ§ AlphaGo мӮ¬кұҙ пӮ§ л°”л‘‘ н”„лЎңк·ёлһЁмқҳ н•ңкі„ пӮ§ AlphaGo кө¬м„ұ пӮ§ мқҙм„ёлҸҢ9лӢЁ лҢҖкөӯ кі„нҡҚ пӮ§ лҢҖкөӯ кҙҖм „ нҸ¬мқёнҠё пӮ§ AlphaGo мӢңмӮ¬м җ пӮ§ м°ёкі
- 33. 33 AlphaGo мӢңмӮ¬м җ м„ұкіөн•ң кё°мҲ л§ҲмјҖнҢ…
- 34. 34 к°ңл°ңнҢҖ 20лӘ… David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel & Demis Hassabis AlphaGo мӢңмӮ¬м җ
- 36. 36 мЎҙ н—ЁлҰ¬ 1872л…„ лҜёкөӯ мӣЁмҠӨнҠёлІ„м§ҖлӢҲм•„ нғӨм»· н„°л„җ кіөмӮ¬ мҰқкё° л“ңлҰҙкіј н„°л„җ лҡ«кё° кІҪмҹҒнӣ„ нғҲ진 мӮ¬л§қ AlphaGo мӢңмӮ¬м җ
- 37. 37 References пӮ§ DeepMind, https://deepmind.com/alpha-go.html пӮ§ Why the Chess Computer Deep Blue Played Like a Human, http://nautil.us/issue/18/genius/why-the-chess- computer-deep-blue-played-like-a-human пӮ§ Monte Carlo Tree Search, http://mcts.ai/about/index.html пӮ§ David Silver, etc, вҖңMastering the game of Go with deep neural networks and tree searchвҖқ,вҖқ Nature, p.484-489, Jan. 2016 пӮ§ Volodymyr Mnih, etc,вҖқ Human-level control through deep reinforcementlearningвҖқ, Nature, p.529-43, Feb. 2015 пӮ§ к№Җм„қмӣҗ мҷё, вҖңAlphaGoмқҳ мқёкіөм§ҖлҠҘвҖқ, SPRi Issue Report, 2016.02
Editor's Notes
- #30: м•ҢнҢҢкі мқҳ кё°н’Қ вҖ“ мқҙм°Ҫнҳё мҠӨнғҖмқј? нҸүлІ”н•ң мҲҳлЎң мӢӨмҲҳлҘј н•ҳм§Җ м•ҠмқҢ мқҙм„ёлҸҢ 9лӢЁмқҳ кё°н’Қ л¶ҲлҰ¬н•ң кІҪмҡ° кіөкІ©м Ғмқё (нқ”л“ңлҠ”) мҲҳ мӨ‘көӯ к·ңм№ҷ вҖ“ мқјкіұ집 л°ҳ мҙҲмқҪкё° - 60мҙҲ мҙҲл°ҳм—җ мҠ№л¶ҖлҘј ліҙм§Җ лӘ»н•ҳл©ҙ мҠ№мӮ°мқҙ мһҲмқ„к№Ң? м•ҢнҢҢкі м—җкІҢ мӢӨмҲҳлһҖ?
- #31: м•ҢнҢҢкі мқҳ кё°н’Қ вҖ“ мқҙм°Ҫнҳё мҠӨнғҖмқј? нҸүлІ”н•ң мҲҳлЎң мӢӨмҲҳлҘј н•ҳм§Җ м•ҠмқҢ мқҙм„ёлҸҢ 9лӢЁмқҳ кё°н’Қ л¶ҲлҰ¬н•ң кІҪмҡ° кіөкІ©м Ғмқё (нқ”л“ңлҠ”) мҲҳ мӨ‘көӯ к·ңм№ҷ вҖ“ мқјкіұ집 л°ҳ мҙҲмқҪкё° - 60мҙҲ мҙҲл°ҳм—җ мҠ№л¶ҖлҘј ліҙм§Җ лӘ»н•ҳл©ҙ мҠ№мӮ°мқҙ мһҲмқ„к№Ң? м•ҢнҢҢкі м—җкІҢ мӢӨмҲҳлһҖ?
- #32: м•ҢнҢҢкі мқҳ кё°н’Қ вҖ“ мқҙм°Ҫнҳё мҠӨнғҖмқј? нҸүлІ”н•ң мҲҳлЎң мӢӨмҲҳлҘј н•ҳм§Җ м•ҠмқҢ мқҙм„ёлҸҢ 9лӢЁмқҳ кё°н’Қ л¶ҲлҰ¬н•ң кІҪмҡ° кіөкІ©м Ғмқё (нқ”л“ңлҠ”) мҲҳ мӨ‘көӯ к·ңм№ҷ вҖ“ мқјкіұ집 л°ҳ мҙҲмқҪкё° - 60мҙҲ мҙҲл°ҳм—җ мҠ№л¶ҖлҘј ліҙм§Җ лӘ»н•ҳл©ҙ мҠ№мӮ°мқҙ мһҲмқ„к№Ң? м•ҢнҢҢкі м—җкІҢ мӢӨмҲҳлһҖ?