













Amazon SageMaker§«•º•Ì§´§È§œ§∏§·§ÎôC–µ—ß¡ï»ÎÈT
- 2. 2ÀΩ§À§ƒ§§§∆ §∏§Á§Û§π§þ§π ? •Ø•È•π•·•Ω•√•…÷Í Ωª·…Á •«©`•ø•§•Û•∆•∞•Ï©`•∑•Á•Û≤ø MLÕ∆þM•¡©`•ýTL ? Alteryx ACE ? ±±∫£µ¿§´§È¿¥§Þ§∑§ø£° »’≥£§«÷˜§ÀíQ§¶ºº–g ? Alteryx ? Hadoop, EMR ? ôC–µ—ß¡ï, Amazom SageMaker
- 3. 3±æ»’§Œƒ⁄»ð ? §œ§∏§·§À ? ôC–µ—ߡ炙§œ ? Amazon SageMaker§Ú π§√§øôC–µ—ß¡ï ? Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„
- 4. 4±æ»’§Œƒ⁄»ð ? §œ§∏§·§À ? ôC–µ—ߡ炙§œ ? Amazon SageMaker§Ú π§√§øôC–µ—ß¡ï ? Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„
- 5. 5§œ§∏§·§À ? ÷˜§À“‘œ¬§Œ§Ë§¶§ ƒ⁄»ð§À§ƒ§§§∆’Z§Í§Þ§π ? ôC–µ—ߡ炙§œ§…§Œ§Ë§¶§ §‚§Œ§ §Œ§´ ? ôC–µ—ß¡ï•∑•π•∆•ý§Úågþ\”√§π§Î…œ§«§Œ’nÓ} ? Amazon SageMaker§Ú π§√§øôC–µ—ß¡ï•∑•π•∆•ý§Œ◊˜§Í∑Ω ? “‘œ¬§Œ§≥§»§À§ƒ§§§∆§œ’Z§Í§Þ§ª§Û ? ÇÄ°©§ŒôC–µ—ß¡ï•¢•Î•¥•Í•∫•ý§Œ‘îºö ? ôC–µ—ß¡ïå߻ΧŒåg¿˝ ? ∞k±ÌŸY¡œ§œπ´È_”Ë∂®§«§π ? •·•‚§∑§ø§Í–¥’ʥȧ√§ø§Í§∑§ §Ø§∆§‚¥Û’…∑Ú§¿§Ë£°
- 6. 6±æ»’§Œƒ⁄»ð ? §œ§∏§·§À ? ôC–µ—ߡ炙§œ ? Amazon SageMaker§Ú π§√§øôC–µ—ß¡ï ? Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„
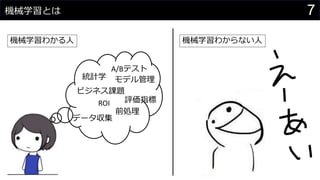
- 8. 8ôC–µ—ߡ炙§œ è䧧AI§»»ı§§AI »ı§§AI è䧧AI ? •ø•π•ØÃÿªØ–Õ ? Ãÿ∂®…Ã∆∑§Œâ”…œ”Ëúy ? •π•—•ý•·©`•Î•’•£•Î•ø ? …Ã∆∑•Ï•≥•·•Û•… ? •≥•Û•‘•Â©`•øΩ´∆ ? ôC–µ—ߡ隆§≥§¡§È ? •«©`•ø§´§ÈÉAœÚ§Úåߧ≠≥ˆ§π ? •«©`•ø§¨§ §§§»∫Œ§‚§«§≠§ §§ ? Deep Learning§‚ôC–µ—ߡ琉“ª≤ø ? ö¯”√µƒ§ ∫Œ§´ ? •…•È§®§‚§Û ? •ø©`•þ•Õ©`•ø©` ? HAL 9000 ? AI•÷©`•ý§«¡˜––§Í§Œºº–g§»§œÑeŒÔ ? ‘î§∑§Ø÷™§Í§ø§§∑Ω§œ °∏»´√󕢩`•≠•∆•Ø•¡•„°π§«’{§Ÿ§∆§þ§Ë§¶
- 9. 9ôC–µ—ߡ炙§œ •«©`•ø∑÷Œˆ§«§…§Œ§Ë§¶§ §≥§»§¨ø…ƒÐ§´ ? Descriptive(”õ ˆµƒ) ? •«©`•ø§´§È°±∫Œ§¨∆§≥§√§ø§´°±§Ú∞—Œ’§π§Î ? þLƒ©§Àºà§™§ý§ƒ§ÚŸI§¶»À§œ•”©`•Î§‚“ªæw§ÀŸI§√§∆§§§ø ? Predictive(”Ëúyµƒ) ? •«©`•ø§´§È°±Ω´¿¥∫Œ§¨∆§≥§Î§´°±§Ú”Ëúy§π§Î ? …Ã∆∑A§ÚŸI§√§ø»À§¨¥Œ§ÀŸI§¶§«§¢§Ì§¶…Ã∆∑§œ£ø ? Prescriptive(ÑI∑Ωµƒ) ? •«©`•ø§´§È°±∫Œ§Ú––§¶§´°±§ÚõQ∂®§π§Î ? œÞ§È§Ï§øµÍ≈n•π•⁄©`•πƒ⁄§À§…§Œ§Ë§¶§ …Ã∆∑§Ú≈‰÷√§π§Î§´
- 10. 10ôC–µ—ߡ炙§œ •«©`•ø∑÷Œˆ§«§…§Œ§Ë§¶§ §≥§»§¨ø…ƒÐ§´ ? Descriptive(”õ ˆµƒ) ? •«©`•ø§´§È°±∫Œ§¨∆§≥§√§ø§´°±§Ú∞—Œ’§π§Î ? þLƒ©§Àºà§™§ý§ƒ§ÚŸI§¶»À§œ•”©`•Î§‚“ªæw§ÀŸI§√§∆§§§ø ? Predictive(”Ëúyµƒ) ? •«©`•ø§´§È°±Ω´¿¥∫Œ§¨∆§≥§Î§´°±§Ú”Ëúy§π§Î ? …Ã∆∑A§ÚŸI§√§ø»À§¨¥Œ§ÀŸI§¶§«§¢§Ì§¶…Ã∆∑§œ£ø ? Prescriptive(ÑI∑Ωµƒ) ? •«©`•ø§´§È°±∫Œ§Ú––§¶§´°±§ÚõQ∂®§π§Î ? œÞ§È§Ï§øµÍ≈n•π•⁄©`•πƒ⁄§À§…§Œ§Ë§¶§ …Ã∆∑§Ú≈‰÷√§π§Î§´
- 11. 11±æ»’§Œƒ⁄»ð ? §œ§∏§·§À ? ôC–µ—ߡ炙§œ ? Amazon SageMaker§Ú π§√§øôC–µ—ß¡ï ? Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„
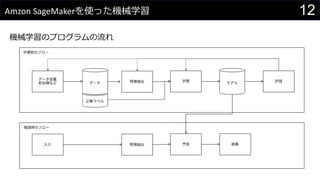
- 14. 14Amzon SageMaker§Ú π§√§øôC–µ—ß¡ï ôC–µ—ߡ琉•◊•Ì•∞•È•ý§Œ¡˜§Ï ? •Œ©`•»•÷•√•Ø•§•Û•π•ø•Û•π§Œ◊˜≥… ? ÑI¿Ìƒ⁄»ð§Œ”õ ˆ ? —ß¡ïÑI¿Ì§Œåg–– ? Õ∆’ì•®•Û•…•ð•§•Û•»§Œ◊˜≥… ? Õ∆’ì•®•Û•…•ð•§•Û•»§Ú π§√§ø”Ëúy ? —ß¡ïΩYπ˚§Œ‘uÅ˝
- 16. 16±æ»’§Œƒ⁄»ð ? §œ§∏§·§À ? ôC–µ—ߡ炙§œ ? Amazon SageMaker§Ú π§√§øôC–µ—ß¡ï ? Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„
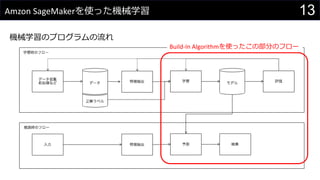
- 17. 17Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„ SageMaker§Œ π§§∑Ω ? Build-In•¢•Î•¥•Í•∫•ý§Ú¿˚”√§π§Î ? TensorFlow, MXNet, Chainer§Ú¿˚”√ ? ∂¿◊‘§À◊˜§Î(ex: scikit-learn§ÚΩM§þÞz§ý) ? Apache Spark§´§È¿˚”√
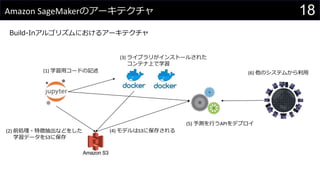
- 18. 18Amazon SageMaker§Œ•¢©`•≠•∆•Ø•¡•„ Build-In•¢•Î•¥•Í•∫•ý§À§™§±§Î•¢©`•≠•∆•Ø•¡•„ (1) —ß¡ï”√•≥©`•…§Œ”õ ˆ (2) «∞ÑI¿Ì?Ãÿè’≥È≥ˆ§ §…§Ú§∑§ø —ß¡ï•«©`•ø§ÚS3§À±£¥Ê (3) •È•§•÷•È•Í§¨•§•Û•π•»©`•Î§µ§Ï§ø •≥•Û•∆• …œ§«—ß¡ï (4) •‚•«•Î§œS3§À±£¥Ê§µ§Ï§Î (5) ”Ëúy§Ú––§¶API§Ú•«•◊•Ì•§ (6) À˚§Œ•∑•π•∆•ý§´§È¿˚”√
- 19. 19
Editor's Notes
- #8: ôC–µ—ß¡ï§Ú§‰§Î§À§œøº§®§ §±§Ï§–§ §È§ §§òî°©§ §≥§»§¨§¢§Î §Ω§¶§§§√§ø§≥§»§Ú∫Œ§‚÷™§È§ §§∂ŒÎA§«§œ”“§Œ§Ë§¶§À°±§ §Û§«§‚§«§≠§Îƒß∑®°±§»§»§È§®§¨§¡ ågÎH§À§œôC–µ—ߡ隆°±„y§ŒèéÕË°±§«§œ§ §§§Œ§¨°¢§Ω§Ï§Ú÷™§Î§ø§·§Œ◊„§¨•¨•Í§»§ §Î“™Àÿ§Ú§»§È§®§Î§Þ§«§¨¥Û≠¿˝§®§–°¢√„èä§∑§Ë§¶§»Àº§√§∆±æ§‰Web•µ•§•»§Ú“ä§∆§‚§§§≠§ §ÍÎy§∑§§ ˝ Ω§Ú“ä§ª§È§Ï§ø§Í§π§Î§Œ§«°¢ •∑•π•∆•ý§»§∑§∆§…§Œ§Ë§¶§Àåg◊∞§π§Ï§–§§§§§Œ§´§‰°¢§Ω§Ï§¨•”•∏•Õ•π§À§…§¶“€§À¡¢§ƒ§´§¨√˜¥_§«§ §§ Amazon SageMaker§Ú 𧶧≥§»§«IT§Œ§Ô§´§ÎCitizen data scientist§À§ §Ï§Î§ø§·§Œ°¢ ôC–µ—ߡ琉§»§√§´§´§Í§»§ §Î“™Àÿ§Œ¿ÌΩ‚§¨ΩÒ»’§Œƒøµƒ °˘ Citizen data scientist§»§œ ˝—ߧ‰Ωy”ã—ߧŒåüÈT÷™◊R§œ§ §§§¨°¢•”•∏•Õ•πÓI”Ú§«§ŒåüÈT÷™◊R§œ”–§∑§∆§§§∆°¢ •”•∏•Õ•πÅ˝Çé§Ú§‚§ø§È§π§ø§·§Œ•«©`•ø∑÷Œˆ§¨§«§≠§Î»À§Œ§≥§»
- #9: §Ë§Øø±þ`§§§µ§Ï§¨§¡§ §‰§ƒ •∑•Û•Æ•Â•È•Í•∆•£§‰AI§À»ÀÈg§Œ À ¬§ÚäZ§Ô§Ï§Î§þ§ø§§§ Œƒ√}§«µ«àˆ§π§Î§Œ§œ§§§Ô§Ê§Î°±è䧧AI°± ö¯”√»Àπ§÷™ƒÐ§»∫Ù§–§Ï§∆°¢»ÀÈg§»Õ¨µ»§Àòî°©§≥§»§Úåg¨F§«§≠§Î§‚§Œ ¨F‘⁄§ŒAI•÷©`•ý§Œ÷˜“™ºº–g§«§¢§ÎôC–µ—ߡ炙§œÆê§ §Î°∏»ÀÈg§Œ√ó§ŒôCƒÐ§Ú‘Ÿ¨F§∑§Ë§¶§»§π§Î—–æø°π§œÑe§À§¢§Î ôC–µ—ߡ隆Ωy”㵃§ ÷∑®§Àª˘§≈§Ø(SVM§ §…¿˝Õ‚§‚§¢§Î)•ø•π•ØÃÿªØ–Õ§Œ ÀΩM§þ »ÀÈg§œ •”•∏•Õ•π’nÓ}§ §…°¢åg¨F§∑§ø§§§≥§»§Œ√˜¥_ªØ Ωy”㵃§ ÷∑®§Úþm”√§π§Î§ø§·§Œ•«©`•ø’˚lj ΩYπ˚§Ú§‚§»§À§∑§∆§…§Œ§Ë§¶§ •¢•Ø•∑•Á•Û§Ú»°§Î§´§ŒõQ∂® § §…§Ú§π§Î±ÿ“™§¨§¢§Î°£
- #10: Descriptive(”õ ˆµƒ)§ •«©`•ø∑÷Œˆ§«§œ°¢º»§Àµ√§È§Ï§∆§§§Îþ^»••«©`•ø§Àåù§∑§∆°¢ §…§Œ§Ë§¶§ §≥§»§¨∆§≥§√§ø§Œ§´§Ú’˚¿Ì§∑°¢¿ÌΩ‚§π§Î§ø§·§Œ ÷∑® ÖgºÉ§À•«©`•ø§ÚºØ”ã§∑§∆’˚¿Ì§∑§∆§þ§ø§Í°¢•«©`•ø•Þ•§•À•Û•∞µƒ ÷∑®§Ú π§√§∆§…§Œ§Ë§¶§ ÉAœÚ§¨§¢§Î§Œ§´§Ú’{§Ÿ§ø§Í§π§Î •”©`•Î§»ºà§™§ý§ƒ§Œ¿˝§œ•«©`•ø•Þ•§•À•Û•∞§«”–√˚§ §‚§Œ §ø§¿§∑°¢§≥§Ï§œ§¢§Ø§Þ§«§‚∫Œ§¨∆§≥§√§ø§´§Ú°±÷™§Î°±§»§≥§¨§«§≠§Î§Œ§þ§«°¢ §≥§Ï§Ú Ч±§∆∫Œ§Ú§π§Î§Œ§´§œ§≥§ŒπÝÆݧÀ∫¨§Þ§Ï§∆§§§ §§ •«©`•ø•…•Í•÷•Û§ ŒƒªØ§Ú∫B§Ø§ø§·§Œ◊Ó≥ı§Œ“ªöi§«§‚§¢§Í°¢§≥§Ï“‘Ωµ§Œ2§ƒ§Ú––§¶§¶§®§«§‚◊Ó≥ı§À§‰§Î§Ÿ§≠÷ÿ“™§ “™Àÿ§»§ §Î Predictive(”Ëúyµƒ)§«§œþ^»•§ŒÉAœÚ§»Õ¨§∏◊¥õr§¨æA§≠àˆ∫œ°¢¥Œ§À∫Œ§¨∆§≥§Î§Œ§´§Ú”Ëúy§π§Î (œ¡¡x§«§Œ)ôC–µ—ߡ裡––§¶§Œ§¨÷˜§À§≥§Œ≤ø∑÷§»§ §Î ”Ëúy§Ú––§¶§ø§·§Œ§À°¢Ωy”㵃§ ÷∑®§»°¢Ãÿè’§»§ §Î•«©`•ø§Ú”√“‚§π§Î±ÿ“™§¨§¢§Î •«©`•ø§´§ÈÉAœÚ§Ú”Ëúy§π§Î§ø§·°¢µ√§È§Ï§∆§§§ §§«ÈàÛ§Àª˘§≈§Ø”Ëúy§œ§«§≠§ §§ í§§≤§∆§§§Î¿˝§œ°¢•Ï•≥•·•Û•…•∑•π•∆•ý§Œ§Ë§¶§ §‚§Œ þ^»•§Œ•Ê©`•∂§ŒÉAœÚ§´§È“ªæw§ÀŸè»Î§µ§Ï§Î¥_¬ §¨∏þ§§…Ã∆∑§‰≈dŒ∂§Œ§¢§ÎπÝáϧŒÉAœÚ§¨Õ¨§∏•Ê©`•∂§¨öð§À»Î§√§ø…Ã∆∑§ §…°¢ Ÿè»Î§µ§Ï§Î¥_¬ §¨∏þ§§§‚§Œ§Ú”Ëúy§π§Î§≥§»§«°¢œ»ªÿ§Í§∑§∆•™•π•π•·§«§≠§Î Prescriptive(ÑI∑Ωµƒ)§«§œ°¢•«©`•ø§ÚªÓ”√§∑§∆»ÀÈg§¨––§¶§Ÿ§≠•¢•Ø•∑•Á•Û§ŒõQ∂®§Ú––§¶°£ ¿˝§»§∑§∆í§§≤§∆§§§Î§‚§Œ§œ°¢°±ΩM§þ∫œ§Ô§ª◊ÓþmªØÜñÓ}°± Descriptive§‰Prescriptive§«––§√§øΩYπ˚§´§È§Œâ”…œ”Ëúy§ §…§Àª˘§≈§≠§…§Œ…Ã∆∑§ÚµÍ≈n§À≈‰÷√§π§Î§Œ§¨§Ë§µ§Ω§¶§´≈–∂œ§π§Î §Ω§ŒÎH°¢ µÍ≈n•π•⁄©`•π§œœÞ§È§Ï§Î§ø§·§ §Û§«§‚»°§Í§Ω§Ì§®§Î§≥§»§œ§«§≠§ §§ §Ë§Ø“ªæw§ÀŸè»Î§µ§Ï§Î…Ã∆∑Õ¨ ø§œΩ¸§Ø§À§¢§√§ø∑Ω§¨§§§§ …Ã∆∑§¥§»§À¥Û§≠§µ§ §…§‚þ`§¶§ø§·°¢§Ë§Ø┧ϧΧ´§È§»§§§√§∆»Î∫…§π§Î§»§€§´§Œ…Ã∆∑§Ú÷√§Ø•π•⁄©`•π§¨úp§Î(=§€§´§Œ…Ã∆∑§Œâ”§Í…œ§≤§¨úp§Î) ∏˜…Ã∆∑§Œ¿˚“ʬ §‚øºë]§π§Î±ÿ“™§¨§¢§Î § §…°¢§…§Û§ …Ã∆∑§Ú»Î∫…§∑§∆§…§Œ§Ë§¶§À≈‰÷√§π§Î§´§Ú ˝ Ω§Àâ‰ìQ§∑§∆◊Óþm§ ◊¥ëB§ÚôC–µµƒ§À«Û§·§Î§ §…§π§Î
- #11: ΩÒªÿ§œ≥ß≤π≤µ±≤—≤π∞ϱ∞˘§Ú π§√§øª˙–µ—ßœ∞§Œ π§§∑Ω§¨•·•§•Û§»§ §Î§Œ§«÷˜§ÀíQ§¶§Œ§œ§≥§Œ≤ø∑÷ ågÎH§À§œ°¢ôC–µ—ß¡ï§Ú§π§Î§ÀÎH§∑§∆§‚ Descriptive : •‚•«•Í•Û•∞§Œ«∞§ŒEDA(ÃΩÀ˜µƒ•«©`•øΩ‚Œˆ) Prescriptive : •«•◊•Ì•§··§ŒA/B•∆•π•»§‰∂ýÕÛ•–•Û•«•£•√•» § §…°¢»´Ã§¨ÈvÇS§∑§∆§Ø§Î »ÎÈT§ §Œ§«°±ôC–µ—ß¡ï§Ú§π§Î°±§»§§§¶≤ø∑÷§ÀΩg§√§∆‘í§π
- #13: ôC–µ—ß¡ï§Ú•∑•π•∆•ý§ÀΩM§þÞz§ý§À§œ§‰§È§ §§§»•¿•·§ §≥§»§¨§§§√§—§§§¢§Î òã≥…§»§∑§∆°¢—ß¡ï§Ú––§√§∆•‚•«•Î§Ú…˙≥…§π§Î≤ø∑÷§»§€§´§Œ•∑•π•∆•ý§´§È¿˚”√§µ§Ï§ÎÕ∆’ì≤ø∑÷§À¥Û§≠§Ø∑÷§±§È§Ï§Î —ß¡ï≤ø∑÷§»Õ∆’ì≤ø∑÷§œ§Ω§Ï§æ§ÏÑe§Œ•∑•π•∆•ý§»§ §√§∆§§§∆°¢—ߡ匿◊˜§È§Ï§ø•‚•«•Î§¨Õ∆’ì”√§Œ•∑•π•∆•ý§«¿˚”√§µ§Ï§Î ôC–µ—ß¡ï§Ú∫¨§Þ§ §§Õ®≥£§Œ•∑•π•∆•ý§»§Œåù±»§«øº§®§Î§» —ß¡ï≤ø∑÷§œ“πÈg•–•√•¡§Œ§Ë§¶§ §‚§Œ§«À˚§´§È¿˚”√§´§Œ§¶§ •«©`•ø§Ú…˙≥…§π§Î Õ∆’ì≤ø∑÷§œ•Ê©`•∂§¨“ª∞„§À¿˚”√§π§ÎUI§Ú≥÷§√§∆§§§Î•∑•π•∆•ý§«•–•√•¡§¨…˙≥…§∑§ø•«©`•ø§Ú¿˚”√§π§Î §»§§§¶§Ë§¶§ ∏–§∏§«øº§®§Î§»§§§§ §Ω§ŒÎH°±•«©`•ø°±§»§∑§∆π≤”–§µ§Ï§Î§Œ§¨°±•‚•«•Î°±§»§ §Î —ß¡ïïr§Œ•’•Ì©`§ÀÈv§∑§∆§œ§Þ§∫•«©`•ø§¨§ §§§»—ߡ匿§≠§ §§§Œ§«°¢•«©`•ø§Ú π§®◊¥ëB§À§∑§∆§™§Ø±ÿ“™§¨§¢§Î°£ §≥§Ï§œ°¢•«©`•ø•Ÿ©`•π§ÿ§Œ•¢•Ø•ª•π§‰•’•°•§•Î§¨¿˚”√ø…ƒÐ§ ◊¥ëB§À§ §√§∆§§§Î°¢§»§§§¶§Œ§œ§‚§»§Ë§Í º»¥Ê§Œ•«©`•ø§Ú 𧮧Î◊¥ëB§À§π§Î§ø§·§À«∞ÑI¿Ì§∑§ø§Í°¢àˆ∫œ§À§Ë§√§∆§œ∂®∆⁄µƒ§À•«©`•ø§ÚÖߺØ?ºØºs§π§Î•Ì•∏•√•Ø§‚±ÿ“™§À§ §Î°£§ƒ§È§§°£ ¿˚”√ø…ƒÐ§ ◊¥ëB§Œ•«©`•ø§Àåù§∑§∆°¢’˝Ω‚•È•Ÿ•Î§Ú◊˜≥…§π§Î±ÿ“™§¨§¢§Îàˆ∫œ§‚§¢§Î°£ ¿˝§®§–°¢é⁄∏ʧŒ•Ø•Í•√•Ø?…Ã∆∑Ÿè»Î§Œ”–üo?•Ï•”•Â©`§Œ–«§Œ ˝§ §…•Ê©`•∂§Œ––Ñ”§¨§Ω§Œ§Þ§Þ’˝Ω‚•È•Ÿ•Î§À§ §Î§≥§»§‚§¢§Ï§–°¢ •Ï•”•Â©`ƒ⁄»ð§¨•ð•∏•∆•£•÷§ ƒ⁄»ð§´•Õ•¨•∆•£•÷§ ƒ⁄»ð§´§ §…°¢»ÀÈg§¨“ä§∆•¢•Œ•∆©`•∑•Á•Û§Ú‘O∂®§π§Î±ÿ“™§¨§¢§Îàˆ∫œ§‚§¢§Î Ãÿè’≥È≥ˆ(Feature Engineering)§œàˆ∫œ§À§Ë§√§∆§œ«∞ÑI¿Ì§»Õ¨§∏íQ§§§Œ§≥§»§‚§¢§Î §≥§≥§«§œ°¢ •«©`•ø§Ú§Ω§‚§Ω§‚ 𧮧Î◊¥ëB§À§π§Î§Œ§¨«∞ÑI¿Ì §Ë§Í§Ë§§—ß¡ïΩYπ˚§Úµ√§Î§ø§·§À•«©`•ø§Àåù§∑§∆––§¶º”π§»´∞„§ÚÃÿè’≥È≥ˆ §»§π§Î —ߡ隆•«©`•ø§Àåù§∑§∆ågÎH§ÀôC–µ—ߡ琉 ÷∑®§Úþm”√§µ§ª§∆”Ëúy§¨ø…ƒÐ§ •‚•«•Î§Ú◊˜≥…§π§Î•◊•Ì•ª•π Îy§∑§§ ˝—ߧŒ¿Ì’짨Ωj§Û§¿§Í§π§Î§¨°¢SageMaker§«§œ”√“‚§µ§Ï§∆§§§Î•È•§•÷•È•Í§ŒÈv ˝§Ú∫Ù§”≥ˆ§π§Œ§þ §ø§¿§∑°¢§…§Œ ÷∑®§¨§…§Œƒøµƒ§« π§®§Î§´§ §…§ŒåùèÍÈvÇS§œ÷™§√§∆§™§Ø±ÿ“™§¨§¢§Î —ß¡ï§Ú––§√§ø··§œ°¢•‚•«•Î§¨§…§Ï§¿§±§¶§Þ§ØÕ∆’짫§≠§Î§Ë§¶§À§ §√§∆§§§Î§Œ§´§Ú‘uÅ˝§π§Î ôC–µ—ߡ琉ΩYπ˚§œ100%’˝Ω‚§π§Î§Ô§±§«§œ§ §§§Œ§«°¢§…§Œ§Ë§¶§ àˆ√ʧ«¿˚”√§π§Î§´§Àèͧ∏§∆òî°©§ ∑Ω∑®§«‘uÅ˝§Ú––§¶ ‘uÅ˝§ŒΩYπ˚§¶§Þ§ØÕ∆’짫§≠§Ω§¶§‚§ §§§»§ §√§øàˆ∫œ§œ•«©`•ø§Ú≧®§ø§Í°¢ ÷∑®§Ú≧®§ø§Í§∑§ §¨§ÈΩYπ˚§Ú∏ƒ…∆§∑§ø§Í°¢÷B§·§ø§Í§π§Î°£ Õ∆’ìïr§À§œ°¢Õ∆’ì≠hæ≥§À•‚•«•Î§Ú•«•◊•Ì•§§∑§∆°¢Èv ˝§‰API§ §…§«∫Ù§”≥ˆ§ª§Î§Ë§¶§À§∑§∆§™§Ø ”ËúyåùœÛ§¨œÞ∂®µƒ§ àˆ∫œ§œ°¢§¢§È§´§∏§·ΩYπ˚§ÚDB§À»Î§Ï§∆§™§Ø§ §…§∑§∆§‚§Ë§§ Õ∆’ì”√§Œ•∑•π•∆•ý§À»Î§Ï§Î•«©`•ø§»§∑§∆§œ°¢«∞ÑI¿Ì§ §…§¨úg§Û§«§§§Î◊¥ëB§Œ§‚§Œ§Ú»Î¡¶§»§π§Î§≥§»§¨ø…ƒÐ§¿§¨°¢ Ãÿè’≥È≥ˆ§«––§√§ø•Ì•∏•√•Ø§œ§Ω§Ï”√§Œ•—•È•·©`•ø§Ú≥÷§√§∆§ø§Í§‚§π§Î§Œ§«°¢§Ô§Í§´§∑•∑•π•∆•ýÇ»§«≥÷§√§∆§™§Ø±ÿ“™§¨§¢§Î°£ §≥§Œ≤ø∑÷§œÕ∆’ìΩYπ˚§Ú∑µ§π
- #14: ΩÒªÿ§œ≥ß≤π≤µ±≤—≤π∞ϱ∞˘§Ú π§√§øª˙–µ—ßœ∞§Œ π§§∑Ω§¨•·•§•Û§»§ §Î§Œ§«÷˜§ÀíQ§¶§Œ§œ§≥§Œ≤ø∑÷
- #15: §‰§√§∆§þ§Ë§¶£°
- #16: •Œ©`•»•÷•√•Ø•§•Û•π•ø•Û•π§Ú¡¢§¡…œ§≤§Ë§¶§»§π§Î ïrÈg§¨§´§´§Î§ø§·°¢¡¢§¡…œ§≤§Ë§¶§»§π§Î§¿§±§«ågÎH§À§œ§π§«§ÀÑ”§§§∆§Î•§•Û•π•ø•Û•π§Ú 𧶠•Œ©`•»•÷•√•Ø§ÚÈ_§Ø LinearLearner§Œ•µ•Û•◊•Î§Ú“ª≤øâ‰∏¸§∑§ø§‚§Œ •◊•Ì•ª•π§ÚÌò§À’h√˜§∑§∆§§§Ø fit, deploy§œïrÈg§¨§´§´§Î§Œ§«°±§≥§¡§È§À§«§≠§ø§‚§Œ§¨§¢§Í§Þ§π°± endpoint¬‰§»§π