





![B. Tᚥo Qlogs và lÆ°u cÃĒu truy vášĨn CÃĄc hà m cháŧĐc nÄng: - Hà m lášĨy tháŧi gian: <%=date.toGMTString()%> - Hà m lášĨy IP: request.getRemoteAddr() Hà m lášĨy Session: HttpSessionĖýsessionĖý=Ėýrequest.getSession(); StringĖýidĖý=Ėýsession.getId(); Hà m lášĨy Cookies: Cookie cookie = new Cookie ("tÊn",giÃĄ tráŧ); Cookie.setMaxAge(365 * 24 * 60 * 60); response.addCookie(cookie); Cookie cookies [] = request.getCookies () Cookies[i].getValue() - Hà m lášĨy URL clicked: ?](https://image.slidesharecdn.com/apache-qlogs-110228102607-phpapp01/85/Apache-q-logs-12-320.jpg)






























More Related Content
Viewers also liked (8)
Similar to Apache+ q logs (20)






Apache+ q logs
- 1. Demo: Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse. Tᚥo và lÆ°u cÃĒu truy vášĨn và o QLogs. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse 1, PhiÊn bášĢn Eclipse 2. Kášŋt háŧĢp Webserver, JRE và o Workspace. 3. Import Nutch. 4. Äáš·c tášĢ CrawlDB B. Tᚥo QLogs và lÆ°u cÃĒu truy vášĨn 1. CSDL 2. Import thÆ° viáŧn JDBC và o Eclipse 3. LÆ°u cÃĒu truy vášĨn
- 2. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse 1, PhiÊn bášĢn Eclipse tháŧąc nghiáŧm: Eclipse EUROPA download tᚥi: http://www.eclipse.org/downloads/moreinfo/jee.php
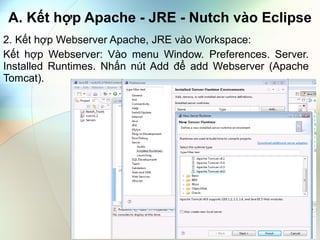
- 3. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse 2. Kášŋt háŧĢp Webserver Apache, JRE và o Workspace: Kášŋt háŧĢp Webserver: Và o menu Window. Preferences. Server. Installed Runtimes. NhášĨn nÚt Add Äáŧ add Webserver (Apache Tomcat).
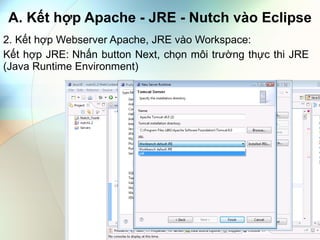
- 4. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse 2. Kášŋt háŧĢp Webserver Apache, JRE và o Workspace: Kášŋt háŧĢp JRE: NhášĨn button Next, cháŧn mÃīi trÆ°áŧng tháŧąc thi JRE (Java Runtime Environment)
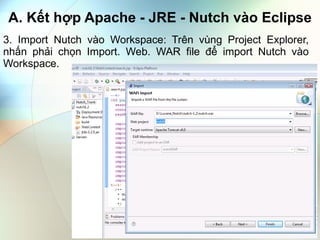
- 5. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse 3. Import Nutch và o Workspace: TrÊn vÃđng Project Explorer, nhášĨn phášĢi cháŧn Import. Web. WAR file Äáŧ import Nutch và o Workspace.
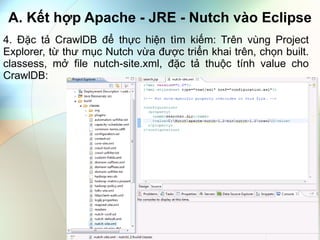
- 6. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse 4. Äáš·c tášĢ CrawlDB Äáŧ tháŧąc hiáŧn tÃŽm kiášŋm: TrÊn vÃđng Project Explorer, táŧŦ thÆ° máŧĨc Nutch váŧŦa ÄÆ°áŧĢc triáŧn khai trÊn, cháŧn built. classess, máŧ file nutch-site.xml, Äáš·c tášĢ thuáŧc tÃnh value cho CrawlDB:
- 7. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse trang search.jsp sáŧ dáŧĨng phÆ°ÆĄng tháŧĐc GET Äáŧ get data nášąm trong URL string, Webserver khÃīng nhášn biášŋt ÄÆ°áŧĢc encoding cáŧ§a cÃĒu láŧnh request.setCharacterEncoding("UTF-8") mà sáŧ dáŧĨng default encoding ISO-8859-1, ÄÃĒy là nguyÊn nhÃĒn khiášŋn JSP form khÃīng phÃĒn giášĢi ÄÆ°áŧĢc mÃĢ tiášŋng Viáŧt UTF-8. TrÊn vÃđng Project Explorer, táŧŦ thÆ° máŧĨc Webserver váŧŦa ÄÆ°áŧĢc kášŋt háŧĢp trÊn, máŧ file server.xml Äáŧ thÊm encoding nhášn dᚥng URI (Uniform Resource Identifier): <Connector URIEncoding="UTF-8" connectionTimeout="20000" port="8080" ... > - Running váŧi F11.
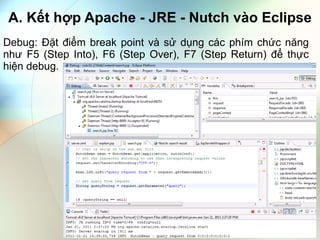
- 8. A. Kášŋt háŧĢp Apache - JRE - Nutch và o Eclipse Debug: Äáš·t Äiáŧm break point và sáŧ dáŧĨng cÃĄc phÃm cháŧĐc nÄng nhÆ° F5 (Step Into), F6 (Step Over), F7 (Step Return) Äáŧ tháŧąc hiáŧn debug.
- 9. B. Tᚥo Qlogs và lÆ°u cÃĒu truy vášĨn CSDL Äáŧ lÆ°u cÃĄc cÃĒu truy vášĨn: MS. SQL Server Import láŧp thÆ° viáŧn JDBC và o Eclipse BÆ°áŧc 1. Download tᚥi: http://www.sourceforge.net/projects/jtds/develop BÆ°áŧc 2. Copy file jtds - 1.2.5 . jar và o Workspace Äáŧ build và o thÆ° viáŧn cáŧ§a Eclipse. B3. TrÊn vÃđng Project Explorer, táŧŦ thÆ° máŧĨc Nutch váŧŦa ÄÆ°áŧĢc triáŧn khai trÊn, nhášĨn phášĢi cháŧn Properties. Java Build Path. Cháŧn tab Libraries. Click button Add External JARs Äáŧ add file *.jar váŧŦa copy trÊn. Sang tab Order and Export Äáŧ click cháŧn thÆ° viáŧn nà y.
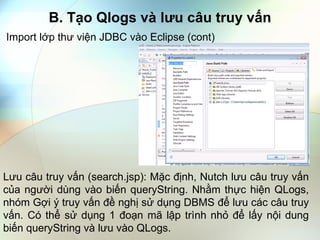
- 10. B. Tᚥo Qlogs và lÆ°u cÃĒu truy vášĨn Import láŧp thÆ° viáŧn JDBC và o Eclipse (cont) LÆ°u cÃĒu truy vášĨn (search.jsp): Máš·c Äáŧnh, Nutch lÆ°u cÃĒu truy vášĨn cáŧ§a ngÆ°áŧi dÃđng và o biášŋn queryString. Nhášąm tháŧąc hiáŧn QLogs, nhÃģm GáŧĢi Ã― truy vášĨn Äáŧ ngháŧ sáŧ dáŧĨng DBMS Äáŧ lÆ°u cÃĄc cÃĒu truy vášĨn. CÃģ tháŧ sáŧ dáŧĨng 1 Äoᚥn mÃĢ lášp trÃŽnh nháŧ Äáŧ lášĨy náŧi dung biášŋn queryString và lÆ°u và o QLogs.
- 11. B. Tᚥo Qlogs và lÆ°u cÃĒu truy vášĨn LÆ°u cÃĒu truy vášĨn (cont)
- 12. B. Tᚥo Qlogs và lÆ°u cÃĒu truy vášĨn CÃĄc hà m cháŧĐc nÄng: - Hà m lášĨy tháŧi gian: <%=date.toGMTString()%> - Hà m lášĨy IP: request.getRemoteAddr() Hà m lášĨy Session: HttpSessionĖýsessionĖý=Ėýrequest.getSession(); StringĖýidĖý=Ėýsession.getId(); Hà m lášĨy Cookies: Cookie cookie = new Cookie ("tÊn",giÃĄ tráŧ); Cookie.setMaxAge(365 * 24 * 60 * 60); response.addCookie(cookie); Cookie cookies [] = request.getCookies () Cookies[i].getValue() - Hà m lášĨy URL clicked: ?