–ü–Α–Ι–Ω–Μ–Α–Ι–Ϋ –Φ–Α―à–Η–Ϋ–Ϋ–Ψ–≥–Ψ –Ψ–±―É―΅–Β–Ϋ–Η―è –Ϋ–Α Apache Spark
βÄΔDownload as PPTX, PDFβÄΔ
0 likesβÄΔ237 views
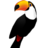
–ß―²–Ψ ―É –Ϋ–Α―¹ –±―΄–Μ–Ψ –¥–Ψ Spark, –Κ–Α–Κ –Φ―΄ –Κ –Ϋ–Β–Φ―É –Ω―Ä–Η―à–Μ–Η, –Η –Ω―Ä–Η ―΅–Β–Φ –Ζ–¥–Β―¹―¨ –Φ–Α―²–Β–Φ–Α―²–Η–Κ–Η-–Ω―Ä–Ψ–≥―Ä–Α–Φ–Φ–Η―¹―²―΄?





























![Pandas vs Spark Dataframe
import pandas as pd
!hive -e "select * from users" >
dt.csv
df = pd.read_csv("dt.csv")
counts = df[df.age > 30]
.groupby("sex")
.count()
from pyspark.sql import HiveContext
ctx = HiveContext(sc)
df = ctx.sql("select * from
users")
counts = df[df.age > 30]
.groupby("sex")
.count()](https://image.slidesharecdn.com/random-170428112607/85/Apache-Spark-30-320.jpg)









–ü–Α–Ι–Ω–Μ–Α–Ι–Ϋ –Φ–Α―à–Η–Ϋ–Ϋ–Ψ–≥–Ψ –Ψ–±―É―΅–Β–Ϋ–Η―è –Ϋ–Α Apache Spark
- 4. Moscow Spark
- 9. –£ Rambler&Co Spark –Η―¹–Ω–Ψ–Μ―¨–Ζ―É―é―² βÄΔ –û―²–¥–Β–Μ –Φ–Α―à–Η–Ϋ–Ϋ–Ψ–≥–Ψ –Ψ–±―É―΅–Β–Ϋ–Η―è (10 ―΅–Β–Μ–Ψ–≤–Β–Κ) βÄΔ DMP (8 ―΅–Β–Μ–Ψ–≤–Β–Κ) βÄΔ –Δ–Ψ–Ω-100 (3 ―΅–Β–Μ–Ψ–≤–Β–Κ–Α)
- 10. –ü–Ψ–Μ–Ϋ–Α―è –≤–Β―Ä―¹–Η―è –¥–Ψ–Κ–Μ–Α–¥–Α ¬Ϊ–ü–Α–Ι–Ω–Μ–Α–Ι–Ϋ –Φ–Α―à–Η–Ϋ–Ϋ–Ψ–≥–Ψ –Ψ–±―É―΅–Β–Ϋ–Η―è –Ϋ–Α Apache Spark¬Μ –¥–Ψ―¹―²―É–Ω–Ϋ–Α –Ϋ–Α http://www.highload.ru/2016/abstracts/2447.html
- 12. –ß―²–Ψ ―Ö–Ψ―²–Η–Φ –Ψ―² –Φ–Α―²–Β–Φ–Α―²–Η–Κ–Α-–Ω―Ä–Ψ–≥―Ä–Α–Φ–Φ–Η―¹―²–Α? βÄΔ –ö–Α―΅–Β―¹―²–≤–Β–Ϋ–Ϋ―΄–Β ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²―΄ –±―΄―¹―²―Ä–Ψ βÄΔ –î–Ψ–≤–Β–¥–Β–Ϋ–Η–Β ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α –¥–Ψ –Ω―Ä–Ψ–¥–Α–Κ―à–Β–Ϋ–Α βÄΔ –ü–Ψ–¥–¥–Β―Ä–Ε–Κ–Α –Η –±–Α–≥―³–Η–Κ―¹―΄
- 13. WTF is this shit?!
- 14. All my code works! And I didnβÄôt break the build!
- 15. –ö–Α―΅–Β―¹―²–≤–Β–Ϋ–Ϋ―΄–Ι ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―² –±―΄―¹―²―Ä–Ψ βÄΔ –½–Ϋ–Α–Κ–Ψ–Φ–Ψ–Β –Ψ–Κ―Ä―É–Ε–Β–Ϋ–Η–Β βÄΔ –£―¹–Β –Ϋ–Ψ–≤–Ψ–Β –Η –Κ―Ä―É―²–Ψ–Β
- 16. –≠–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―² –≤ –Ω―Ä–Ψ–¥–Α–Κ―à–Β–Ϋ–Β βÄΔ –ü―Ä–Ψ―¹―²–Ψ–Β ―²–Β―¹―²–Η―Ä–Ψ–≤–Α–Ϋ–Η–Β βÄΔ –û–Κ―Ä―É–Ε–Β–Ϋ–Η–Β –Κ–Α–Κ –Ϋ–Α –Ω―Ä–Ψ–¥–Α–Κ―à–Β–Ϋ–Β βÄΔ –ê–≤―²–Ψ–Φ–Α―²–Η–Ζ–Α―Ü–Η―è
- 17. –≠–Κ―¹–Ω–Μ―É–Α―²–Α―Ü–Η―è –Η –±–Α–≥―³–Η–Κ―¹―΄ βÄΔ –ü―Ä–Ψ―¹―²–Ψ–Ι –Η –Ϋ–Α–≥–Μ―è–¥–Ϋ―΄–Ι –Φ–Ψ–Ϋ–Η―²–Ψ―Ä–Η–Ϋ–≥ βÄΔ –ê–¥―Ä–Β―¹–Ϋ―΄–Β –Ψ–Ω–Ψ–≤–Β―â–Β–Ϋ–Η―è βÄΔ –î–Ψ―¹―²―É–Ω–Ϋ–Α―è –Ψ―²–Μ–Α–¥–Κ–Α
- 20. You got a problem with that?!
- 22. –Γ–Ψ ―¹―²―Ä–Η–Φ–Φ–Η–Ϋ–≥–Ψ–Φ –Ψ–¥–Ϋ–Η –Ω―Ä–Ψ–±–Μ–Β–Φ―΄ (
- 23. Diagnostic Messages for this Task: Error: java.lang.RuntimeException: Hive Runtime Error while closing operators SELECT TRANSFORM(*) USING 'python script.pyβÄô FROM table;
- 24. –û―΅–Β–Ϋ―¨ –¥–Ψ–Μ–≥–Ψ –≥–Ψ―²–Ψ–≤–Η―²―¨ –¥–Α–Ϋ–Ϋ―΄–Β
- 25. –Δ–Η–Ω–Η―΅–Ϋ―΄–Ι –Α–Μ–≥–Ψ―Ä–Η―²–Φ ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α βÄΔ –£―΄–≥―Ä―É–Ζ–Η―²―¨ ―¹―ç–Φ–Ω–Μ –Η–Ζ Hive βÄΔ –Γ–Κ–Ψ–Ϋ–≤–Β―Ä―²–Η―Ä–Ψ–≤–Α―²―¨ –≤ Pandas βÄΔ –ü–Ψ–Η–≥―Ä–Α―²―¨ ―¹ –¥–Α–Ϋ–Ϋ―΄–Φ–Η βÄΔ –ü–Ψ–Ϋ―è―²―¨, ―΅―²–Ψ ―΅–Β–≥–Ψ-―²–Ψ –Ϋ–Β ―Ö–≤–Α―²–Α–Β―² βÄΔ –£―΄–≥―Ä―É–Ζ–Η―²―¨ –¥―Ä―É–≥–Ψ–Ι ―¹―ç–Φ–Ω–Μ –Η–Ζ HiveβÄΠ
- 28. –ü–Ψ―΅–Β–Φ―É ?
- 29. It is in-memory and there is a Python API!
- 30. Pandas vs Spark Dataframe import pandas as pd !hive -e "select * from users" > dt.csv df = pd.read_csv("dt.csv") counts = df[df.age > 30] .groupby("sex") .count() from pyspark.sql import HiveContext ctx = HiveContext(sc) df = ctx.sql("select * from users") counts = df[df.age > 30] .groupby("sex") .count()
- 31. –ê –Ϋ–Α ―¹–Α–Φ–Ψ–Φ –¥–Β–Μ–ΒβÄΠ
- 32. SPARK-15139 PySPark TreeEnsemble missing methods SPARK-18177 Add missing βĉsubsamplingRateβÄô of pyspark GBTClassifier SPARK-17025 Cannot persist PySpark ML Pipeline model that includes custom Transformer SPARK-15194 Add Python ML API for MultivariateGaussian
- 33. Use XGBoost, Luke © Unknown Kaggler
- 34. –ü–Ψ―΅–Β–Φ―É –Φ―΄ –Ϋ–Β –Η―¹–Ω–Ψ–Μ―¨–Ζ―É–Β–Φ Spark.ML?
- 35. –ü―Ä–Η―΅–Η–Ϋ–Α ⳕ1 βÄΔ Vowpal Wabbit –Η XGBoost –≤ ―¹―²–Α―Ä–Ψ–Φ –Ω–Α–Ι–Ω–Μ–Α–Ι–Ϋ–Β βÄΔ –ù–Ψ–≤―΄–Ι –Κ–Ψ–¥ –¥–Μ―è –Ϋ–Α–Ω–Η–Μ–Κ–Η ―³–Η―΅
- 36. –ü―Ä–Η―΅–Η–Ϋ–Α ⳕ2 SPARK-14374 PySpark ml GBTClassifier, Regressor support export/import (Resolved: 15/Apr/16) SPARK-13034 PySpark ml.classification support export/import (Resolved: 16/Mar/16)
- 37. –ü―Ä–Η―΅–Η–Ϋ–Α ⳕ3–ö–Α―΅–Β―¹―²–≤–Ψ–Ϋ–Α–Ψ–±―É―΅–Β–Ϋ–Η–Η –û–±―ä–Β–Φ –Ψ–±―É―΅–Α―é―â–Β–Ι –≤―΄–±–Ψ―Ä–Κ–Η
- 38. –ù–Ψ –Φ―΄ –≤–Β―Ä–Η–Μ–Η, ―΅―²–Ψ –≤―¹–Β –Η–Ζ–Φ–Β–Ϋ–Η―²―¹―è :)
- 39. –Γ–ü–ê–Γ–‰–ë–û!