



![Cost function
ŌĆó [VLBM, p.2] An autoencoder takes an input vector Øæź Ōłł 0,1 Øææ
, and first
maps it to a hidden representation y Ōłł 0,1 ØææŌĆ▓
through a deterministic
mapping Øæ” = ØæōØ£ā Øæź = ØæĀ(ØæŖØæź + ØæÅ), parameterized by Ø£ā = {ØæŖ, ØæÅ}.
ØæŖ is a Øææ ├Ś ØææŌĆ▓
weight matrix and ØÆā is a bias vector. The resulting latent
representation Øæ” is then mapped back to a ŌĆ£reconstructedŌĆØ vector
z Ōłł 0,1 Øææ in input space Øæ¦ = Øæö Ø£āŌĆ▓ Øæ” = ØæĀ ØæŖŌĆ▓ Øæ” + ØæÅŌĆ▓ with Ø£āŌĆ▓ = {ØæŖŌĆ▓, ØæÅŌĆ▓}.
The weight matrix ØæŖŌĆ▓ of the reverse mapping may optionally be
constrained by ØæŖŌĆ▓ = ØæŖ Øæć, in which case the autoencoder is said to
have tied weights.
ŌĆó The parameters of this model are optimized to minimize
the average reconstruction error:
Ø£āŌłŚ
, Ø£āŌĆ▓ŌłŚ
= arg min
Ø£ā,Ø£āŌĆ▓
1
Øæø
Øæ¢=1
Øæø
ØÉ┐(Øæź Øæ¢
, Øæ¦ Øæ¢
)
= arg min
Ø£ā,Ø£āŌĆ▓
1
Øæø Øæ¢=1
Øæø
ØÉ┐(Øæź Øæ¢
, Øæö Ø£āŌĆ▓(ØæōØ£ā Øæź Øæ¢
) (1)
where ØÉ┐ Øæź ŌłÆ Øæ¦ = Øæź ŌłÆ Øæ¦ 2.](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-8-320.jpg)
![Cost function
ŌĆó [VLBM,p.2] An alternative loss, suggested by the interpretation of Øæź
and Øæ¦ as either bit vectors or vectors of bit probabilities (Bernoullis) is
the reconstruction cross-entropy:
ØÉ┐ ØÉ╗ Øæź, Øæ¦ = ØÉ╗(ØÉĄØæź||ØÉĄØæ¦)
= ŌłÆ Øæś=1
Øææ
[Øæź Øæś log Øæ¦ Øæś + log 1 ŌłÆ Øæź Øæś log(1 ŌłÆ Øæ¦ Øæś)]
where ØÉĄØ£ć Øæź = (ØÉĄØ£ć1
Øæź , Ōŗ» , ØÉĄØ£ć Øææ
Øæź ) is a Bernoulli distribution.
ŌĆó [VLBM,p.2] Equation (1) with ØÉ┐ = ØÉ┐ ØÉ╗ can be written
Ø£āŌłŚ, Ø£āŌĆ▓ŌłŚ = arg min
Ø£ā,Ø£āŌĆ▓
ØÉĖ Øæ×0 [ØÉ┐ ØÉ╗(Øæŗ, Øæö Ø£āŌĆ▓(ØæōØ£ā Øæŗ ))]
where Øæ×0(Øæŗ) denotes the empirical distribution associated to our Øæø
training inputs.](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-9-320.jpg)

![Denoising Autoencoders
ŌĆó [VLBM,p.3] corrupted input ļź╝ ļäŻņ¢┤ repaired input ņØä ņ░ŠļŖö training
ņØä ĒĢ£ļŗż. ņóĆ ļŹö ņĀĢĒÖĢĒĢśĻ▓ī ļ¦ÉĒĢśļ®┤ input dataņØś dimension ņØ┤ Øææ ļØ╝Ļ│Ā
ĒĢĀ ļĢī ŌĆśdesired proportion Ø£ł of destructionŌĆÖ ņØä ņĀĢĒĢśņŚ¼ Ø£łØææ ļ¦īĒü╝ņØś
input ņØä 0 ņ£╝ļĪ£ ņłśņĀĢĒĢśļŖö ļ░®ņŗØņ£╝ļĪ£ destruction ĒĢ£ļŗż. ņŚ¼ĻĖ░ņä£ Ø£łØææ Ļ░£
components ļŖö random ņ£╝ļĪ£ ņĀĢĒĢ£ļŗż. ņØ┤Ēøä reconstruction error ļź╝
ņ▓┤Ēü¼ĒĢśņŚ¼ destruction ņĀäņØś input ņ£╝ļĪ£ ļ│ĄĻĄ¼ĒĢśļŖö cost function
ņØ┤ņÜ®ĒĢśņŚ¼ ĒĢÖņŖĄņØä ĒĢśļŖö Autoencoder Ļ░Ć Denoising Autoencoder ņØ┤ļŗż.
ņŚ¼ĻĖ░ņä£ Øæź ņŚÉņä£ destroyed version ņØĖ Øæź ļź╝ ņ¢╗ļŖö Ļ│╝ņĀĢņØĆ stochastic
mapping Øæź ~ Øæ× ØÉĘ( Øæź|x) ļź╝ ļö░ļźĖļŗż.](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-11-320.jpg)
![Denoising Autoencoders
ŌĆó [VLBM,p.3] Let us define the joint distribution
Øæ×0
Øæŗ, Øæŗ, Øæī = Øæ×0
Øæŗ Øæ× ØÉĘ Øæŗ Øæŗ Øø┐Øæō Ø£ā Øæŗ
(Øæī))
where Øø┐ Øæó(ØæŻ) is the Kronecker delta. Thus Øæī is a deterministic
function of Øæŗ. Øæ×0(Øæŗ, Øæŗ, Øæī) is parameterized by Ø£ā. The objective
function minimized by stochastic gradient descent becomes:
ØæÄØæ¤Øæö ØæÜØæ¢Øæø
Ø£ā,Ø£āŌĆ▓
ØÉĖ Øæ×0 Øæź, Øæź [ØÉ┐ ØÉ╗(Øæź, Øæö Ø£āŌĆ▓(ØæōØ£ā( Øæź))])
Corrupted Øæź ļź╝ ņ×ģļĀźĒĢśĻ│Ā Øæź ļź╝ ņ░ŠļŖö ļ░®ļ▓Ģņ£╝ļĪ£ ĒĢÖņŖĄ!](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-12-320.jpg)
![Other Autoencoders
ŌĆó [DL book, 14.2.1] A sparse autoencoder is simply an autoencoder
whose training criterion involves a sparsity penalty ╬® ŌäÄ on the
code layer h, in addition to the reconstruction error:
ØÉ┐(Øæź, Øæö Øæō Øæź ) + ╬®(ŌäÄ),
where Øæö ŌäÄ is the decoder output and typically we have ŌäÄ = Øæō(Øæź),
the encoder output.
ŌĆó [DL book, 14.2.3] Another strategy for regularizing an autoencoder
is to use a penalty ╬® as in sparse autoencoders,
ØÉ┐ Øæź, Øæö Øæō Øæź ) + ╬®(ŌäÄ, Øæź ,
but with a different form of ╬®:
╬® ŌäÄ, Øæź = Ø£å
Øæ¢
Øø╗ØæźŌäÄØæ¢
2](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-13-320.jpg)

![Reference
ŌĆó Reference. Auto-Encoding Variational Bayes, Diederik P Kingma,
Max Welling, 2013
ŌĆó [ļģ╝ļ¼ĖņØś Ļ░ĆņĀĢ] We will restrict ourselves here to the common case
where we have an i.i.d. dataset with latent variables per datapoint,
and where we like to perform maximum likelihood (ML) or
maximum a posteriori (MAP) inference on the (global) parameters,
and variational inference on the latent variables.](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-15-320.jpg)



![Cost function
ŌĆó (Eq.3) Øōø Ø£ā, Ø£Ö; Øæź = ŌłÆØÉĘ ØÉŠØÉ┐(Øæ× Ø£Ö(Øæ¦|Øæź)||ØæØ Ø£ā Øæź ) + ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)]
<Proof>
Øōø Ø£ā, Ø£Ö; Øæź = Øæ¦
Øæ× Ø£Ö Øæ¦ Øæź log
ØæØ Ø£ā(Øæ¦,Øæź)
Øæ× Ø£Ö(Øæ¦|Øæź)
ØææØæ¦
= Øæ¦
Øæ× Ø£Ö Øæ¦ Øæź log
ØæØ Ø£ā Øæ¦)ØæØ Ø£ā(Øæź|Øæ¦
Øæ× Ø£Ö (Øæ¦|Øæź)
ØææØæ¦
= Øæ¦
Øæ× Ø£Ö Øæ¦ Øæź log
ØæØ Ø£ā(Øæ¦)
Øæ× Ø£Ö (Øæ¦|Øæź)
ØææØæ¦ + Øæ¦
Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæź Øæ¦ ØææØæ¦
= ŌłÆØÉĘ ØÉŠØÉ┐(Øæ× Ø£Ö(Øæ¦|Øæź)| ØæØ Ø£ā(Øæ¦) + ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)]
Øæ× Ø£ÖņÖĆ ØæØ Ø£āĻ░Ć normal ņØ┤ļ®┤ Ļ│äņé░ Ļ░ĆļŖź!
Reconstruction error](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-20-320.jpg)
![Cost function
ŌĆó Lemma. If ØæØ Øæź ~Øæü Ø£ć1, Ø£Ä1
2
and Øæ× Øæź ~Øæü Ø£ć2, Ø£Ä2
2
, then
ØÉŠØÉ┐(ØæØ(Øæź)||Øæ× Øæź ) = ln
Ø£Ä2
Ø£Ä1
+
Ø£Ä1
2
+ Ø£ć1 ŌłÆ Ø£ć2
2
2Ø£Ä2
2 ŌłÆ
1
2
ŌĆó Corollary. Øæ× Ø£Ö Øæ¦ Øæź ~ Øæü(Ø£ćØæ¢, Ø£ÄØæ¢
2
ØÉ╝) ņØ┤Ļ│Ā ØæØ Øæ¦ ~Øæü 0,1 ņØ┤ļ®┤
ØÉŠØÉ┐ Øæ× Ø£Ö Øæ¦ ØæźØæ¢ ØæØ Øæ¦ =
1
2
(ØæĪØæ¤ Ø£ÄØæ¢
2
ØÉ╝ + Ø£ćØæ¢ Øæ¢
ØæćØ£ć ŌłÆ ØÉĮ + ln
1
ØæŚ=Øæ¢
ØÉĮ
Ø£ÄØæ¢,ØæŚ
2
)
= (╬ŻØæŚ=1
ØÉĮ
Ø£ÄØæ¢,ØæŚ
2
+ ╬ŻØæŚ=1
ØÉĮ
Ø£ćØæ¢,ØæŚ
2
ŌłÆ ØÉĮ ŌłÆ ╬ŻØæŚ=1
ØÉĮ
ln(Ø£ÄØæ¢,ØæŚ
2
))
=
1
2
╬ŻØæŚ=1
ØÉĮ
(Ø£ćØæ¢,ØæŚ
2
+ Ø£ÄØæ¢,ØæŚ
2
ŌłÆ 1 ŌłÆ ln Ø£ÄØæ¢,ØæŚ
2
)
ŌĆó ņ”ē, Øæ× Ø£Ö Øæ¦ Øæź ~ Øæü(Ø£ćØæ¢, Ø£ÄØæ¢
2
ØÉ╝) ņØ┤Ļ│Ā ØæØ Øæ¦ ~Øæü 0,1 ņØ┤ļ®┤ Eq.3 ļŖö ņĢäļלņÖĆ Ļ░Öļŗż.
Øōø Ø£ā, Ø£Ö; Øæź =
1
2
╬ŻØæŚ=1
ØÉĮ
Ø£ćØæ¢,ØæŚ
2
+ Ø£ÄØæ¢,ØæŚ
2
ŌłÆ 1 ŌłÆ ln Ø£ÄØæ¢,ØæŚ
2
+ ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)]](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-21-320.jpg)
![Reconstruction error ĒĢÖņŖĄ ļ░®ļ▓Ģ
ŌĆó ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)]ļŖö sampling ņØä ĒåĄĒĢ┤ Monte-carlo estimation ĒĢ£ļŗż.
ņ”ē, ØæźØæ¢ Ōłł X ļ¦łļŗż Øæ¦ Øæ¢,1
, Ōŗ» , Øæ¦ Øæ¢ ØÉ┐ ļź╝ sampling ĒĢśņŚ¼ log likelihood ņØś meanņ£╝ļĪ£
ĻĘ╝ņé¼ņŗ£Ēé©ļŗż. ļ│┤ĒåĄ ØÉ┐ = 1 ņØä ļ¦ÄņØ┤ ņé¼ņÜ®ĒĢ£ļŗż.
ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)] Ōł╝
1
ØÉ┐
╬ŻØæÖ=1
ØÉ┐
log(ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢,ØæÖ )
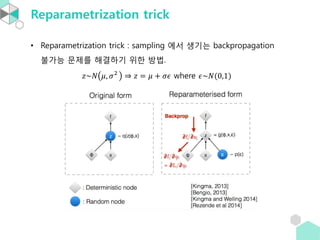
ŌĆó ņØ┤ļĀćĻ▓ī sampling ņØä ĒĢśļ®┤ backpropagation ņØä ĒĢĀ ņłś ņŚåļŗż. ĻĘĖļלņä£ ņé¼ņÜ®
ļÉśļŖö ļ░®ļ▓ĢņØ┤ reparametrization trick ņØ┤ļŗż.
Øæ× Ø£Ö Øæź Øæ¦ ØæØ Ø£ā Øæź Øæ¦](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-22-320.jpg)
![Log Likelihood
ŌĆó ņĢ×ņŚÉņä£ reconstruction error ļź╝ Ļ│äņé░ĒĢĀ ļĢī ĒĢśļéśņö® sampling ņØä ĒĢśļ®┤
ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)] Ōł╝
1
ØÉ┐
╬ŻØæÖ=1
ØÉ┐
log ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢,ØæÖ
= log(ØæØ Ø£ā(ØæźØæ¢|Øæ¦ Øæ¢
)
Ļ░Ć ļÉ£ļŗż. ņŚ¼ĻĖ░ņä£ ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢
ņØś ļČäĒżĻ░Ć Bernoulli ņØĖ Ļ▓ĮņÜ░ņŚÉ ņĢäļלņØś ņŗØņØä
ņ¢╗ņØä ņłś ņ׳ļŗż.
ņČ£ņ▓ś : https://github.com/hwalsuklee/tensorflow-mnist-VAE](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-24-320.jpg)



![References
ŌĆó [VLBM] Extracting and composing robust features with denoising
autoencoders, Vincent, Larochelle, Bengio, Manzagol, 2008
ŌĆó [KW] Auto-Encoding Variational Bayes, Diederik P Kingma, Max
Welling, 2013
ŌĆó [D] Tutorial on Variational Autoencoders - Carl Doersch, 2016
ŌĆó PR-010: Auto-Encoding Variational Bayes, ICLR 2014, ņ░©ņżĆļ▓ö
ŌĆó ņśżĒåĀņØĖņĮöļŹöņØś ļ¬©ļōĀ Ļ▓ā, ņØ┤ĒÖ£ņäØ
https://github.com/hwalsuklee/tensorflow-mnist-VAE](https://image.slidesharecdn.com/auto-encoders-180909040543/85/Auto-Encoders-and-Variational-Auto-Encoders-30-320.jpg)
Auto-Encoders and Variational Auto-Encoders
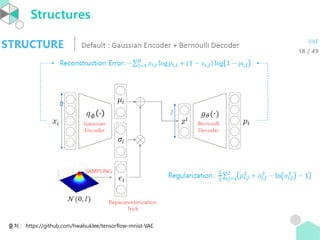
- 2. In this chapter, we will discuss about ŌĆó What is Autoencoder - neural networks whose dimension of input and output are same - if the autoencoder use only linear activations and the cost function is MES, then it is same to PCA - the architecture of a stacked autoencoder is typically symmetrical
- 3. Contents ŌĆó Autoencoders ŌĆó Denoising Autoencoders ŌĆó Variational Autoencoders
- 5. Introduction ŌĆó Autoencoder ļŖö encoder ņÖĆ decoder ļĪ£ ļéśļē£ļŗż. ņśżļźĖņ¬Į diagram ņŚÉņä£ Øæō Ļ░Ć encoder ņØ┤Ļ│Ā, Øæö Ļ░Ć decoder ņØ┤ļŗż. ŌĆó cost function ņØĆ reconstruction error ļź╝ ņé¼ņÜ®ĒĢ£ļŗż: ØÉ┐(Øæź, Øæö Øæō Øæź = Øæź ŌłÆ Øæö Øæō Øæź 2 ŌĆó hidden layer Ļ░Ć 2Ļ░£ ņØ┤ņāüņØĖ AEļź╝ stacked Autoencoder ļØ╝Ļ│Ā ĒĢ£ļŗż. ŌĆó e.g. linear activation ļ¦ī ņé¼ņÜ®ĒĢśĻ│Ā, cost function ņ£╝ļĪ£ MSE ļź╝ ņé¼ņÜ® ĒĢ£ Autoencoder ļŖö PCA ņØ┤ļŗż. Øæź ŌäÄ Øæ¤ Øæō Øæö
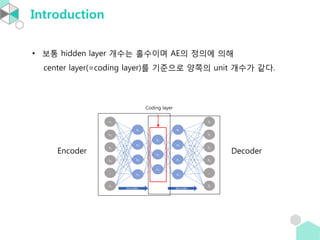
- 6. Introduction ŌĆó ļ│┤ĒåĄ hidden layer Ļ░£ņłśļŖö ĒÖĆņłśņØ┤ļ®░ AEņØś ņĀĢņØśņŚÉ ņØśĒĢ┤ center layer(=coding layer)ļź╝ ĻĖ░ņżĆņ£╝ļĪ£ ņ¢æņ¬ĮņØś unit Ļ░£ņłśĻ░Ć Ļ░Öļŗż. Coding layer Encoder Decoder
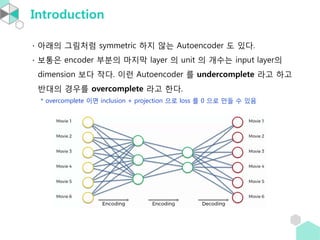
- 7. Introduction ŌłÖ ņĢäļלņØś ĻĘĖļ”╝ņ▓śļ¤╝ symmetric ĒĢśņ¦Ć ņĢŖļŖö Autoencoder ļÅä ņ׳ļŗż. ŌłÖ ļ│┤ĒåĄņØĆ encoder ļČĆļČäņØś ļ¦łņ¦Ćļ¦ē layer ņØś unit ņØś Ļ░£ņłśļŖö input layerņØś dimension ļ│┤ļŗż ņ×æļŗż. ņØ┤ļ¤░ Autoencoder ļź╝ undercomplete ļØ╝Ļ│Ā ĒĢśĻ│Ā ļ░śļīĆņØś Ļ▓ĮņÜ░ļź╝ overcomplete ļØ╝Ļ│Ā ĒĢ£ļŗż. * overcomplete ņØ┤ļ®┤ inclusion + projection ņ£╝ļĪ£ loss ļź╝ 0 ņ£╝ļĪ£ ļ¦īļōż ņłś ņ׳ņØī
- 8. Cost function ŌĆó [VLBM, p.2] An autoencoder takes an input vector Øæź Ōłł 0,1 Øææ , and first maps it to a hidden representation y Ōłł 0,1 ØææŌĆ▓ through a deterministic mapping Øæ” = ØæōØ£ā Øæź = ØæĀ(ØæŖØæź + ØæÅ), parameterized by Ø£ā = {ØæŖ, ØæÅ}. ØæŖ is a Øææ ├Ś ØææŌĆ▓ weight matrix and ØÆā is a bias vector. The resulting latent representation Øæ” is then mapped back to a ŌĆ£reconstructedŌĆØ vector z Ōłł 0,1 Øææ in input space Øæ¦ = Øæö Ø£āŌĆ▓ Øæ” = ØæĀ ØæŖŌĆ▓ Øæ” + ØæÅŌĆ▓ with Ø£āŌĆ▓ = {ØæŖŌĆ▓, ØæÅŌĆ▓}. The weight matrix ØæŖŌĆ▓ of the reverse mapping may optionally be constrained by ØæŖŌĆ▓ = ØæŖ Øæć, in which case the autoencoder is said to have tied weights. ŌĆó The parameters of this model are optimized to minimize the average reconstruction error: Ø£āŌłŚ , Ø£āŌĆ▓ŌłŚ = arg min Ø£ā,Ø£āŌĆ▓ 1 Øæø Øæ¢=1 Øæø ØÉ┐(Øæź Øæ¢ , Øæ¦ Øæ¢ ) = arg min Ø£ā,Ø£āŌĆ▓ 1 Øæø Øæ¢=1 Øæø ØÉ┐(Øæź Øæ¢ , Øæö Ø£āŌĆ▓(ØæōØ£ā Øæź Øæ¢ ) (1) where ØÉ┐ Øæź ŌłÆ Øæ¦ = Øæź ŌłÆ Øæ¦ 2.
- 9. Cost function ŌĆó [VLBM,p.2] An alternative loss, suggested by the interpretation of Øæź and Øæ¦ as either bit vectors or vectors of bit probabilities (Bernoullis) is the reconstruction cross-entropy: ØÉ┐ ØÉ╗ Øæź, Øæ¦ = ØÉ╗(ØÉĄØæź||ØÉĄØæ¦) = ŌłÆ Øæś=1 Øææ [Øæź Øæś log Øæ¦ Øæś + log 1 ŌłÆ Øæź Øæś log(1 ŌłÆ Øæ¦ Øæś)] where ØÉĄØ£ć Øæź = (ØÉĄØ£ć1 Øæź , Ōŗ» , ØÉĄØ£ć Øææ Øæź ) is a Bernoulli distribution. ŌĆó [VLBM,p.2] Equation (1) with ØÉ┐ = ØÉ┐ ØÉ╗ can be written Ø£āŌłŚ, Ø£āŌĆ▓ŌłŚ = arg min Ø£ā,Ø£āŌĆ▓ ØÉĖ Øæ×0 [ØÉ┐ ØÉ╗(Øæŗ, Øæö Ø£āŌĆ▓(ØæōØ£ā Øæŗ ))] where Øæ×0(Øæŗ) denotes the empirical distribution associated to our Øæø training inputs.
- 11. Denoising Autoencoders ŌĆó [VLBM,p.3] corrupted input ļź╝ ļäŻņ¢┤ repaired input ņØä ņ░ŠļŖö training ņØä ĒĢ£ļŗż. ņóĆ ļŹö ņĀĢĒÖĢĒĢśĻ▓ī ļ¦ÉĒĢśļ®┤ input dataņØś dimension ņØ┤ Øææ ļØ╝Ļ│Ā ĒĢĀ ļĢī ŌĆśdesired proportion Ø£ł of destructionŌĆÖ ņØä ņĀĢĒĢśņŚ¼ Ø£łØææ ļ¦īĒü╝ņØś input ņØä 0 ņ£╝ļĪ£ ņłśņĀĢĒĢśļŖö ļ░®ņŗØņ£╝ļĪ£ destruction ĒĢ£ļŗż. ņŚ¼ĻĖ░ņä£ Ø£łØææ Ļ░£ components ļŖö random ņ£╝ļĪ£ ņĀĢĒĢ£ļŗż. ņØ┤Ēøä reconstruction error ļź╝ ņ▓┤Ēü¼ĒĢśņŚ¼ destruction ņĀäņØś input ņ£╝ļĪ£ ļ│ĄĻĄ¼ĒĢśļŖö cost function ņØ┤ņÜ®ĒĢśņŚ¼ ĒĢÖņŖĄņØä ĒĢśļŖö Autoencoder Ļ░Ć Denoising Autoencoder ņØ┤ļŗż. ņŚ¼ĻĖ░ņä£ Øæź ņŚÉņä£ destroyed version ņØĖ Øæź ļź╝ ņ¢╗ļŖö Ļ│╝ņĀĢņØĆ stochastic mapping Øæź ~ Øæ× ØÉĘ( Øæź|x) ļź╝ ļö░ļźĖļŗż.
- 12. Denoising Autoencoders ŌĆó [VLBM,p.3] Let us define the joint distribution Øæ×0 Øæŗ, Øæŗ, Øæī = Øæ×0 Øæŗ Øæ× ØÉĘ Øæŗ Øæŗ Øø┐Øæō Ø£ā Øæŗ (Øæī)) where Øø┐ Øæó(ØæŻ) is the Kronecker delta. Thus Øæī is a deterministic function of Øæŗ. Øæ×0(Øæŗ, Øæŗ, Øæī) is parameterized by Ø£ā. The objective function minimized by stochastic gradient descent becomes: ØæÄØæ¤Øæö ØæÜØæ¢Øæø Ø£ā,Ø£āŌĆ▓ ØÉĖ Øæ×0 Øæź, Øæź [ØÉ┐ ØÉ╗(Øæź, Øæö Ø£āŌĆ▓(ØæōØ£ā( Øæź))]) Corrupted Øæź ļź╝ ņ×ģļĀźĒĢśĻ│Ā Øæź ļź╝ ņ░ŠļŖö ļ░®ļ▓Ģņ£╝ļĪ£ ĒĢÖņŖĄ!
- 13. Other Autoencoders ŌĆó [DL book, 14.2.1] A sparse autoencoder is simply an autoencoder whose training criterion involves a sparsity penalty ╬® ŌäÄ on the code layer h, in addition to the reconstruction error: ØÉ┐(Øæź, Øæö Øæō Øæź ) + ╬®(ŌäÄ), where Øæö ŌäÄ is the decoder output and typically we have ŌäÄ = Øæō(Øæź), the encoder output. ŌĆó [DL book, 14.2.3] Another strategy for regularizing an autoencoder is to use a penalty ╬® as in sparse autoencoders, ØÉ┐ Øæź, Øæö Øæō Øæź ) + ╬®(ŌäÄ, Øæź , but with a different form of ╬®: ╬® ŌäÄ, Øæź = Ø£å Øæ¢ Øø╗ØæźŌäÄØæ¢ 2
- 15. Reference ŌĆó Reference. Auto-Encoding Variational Bayes, Diederik P Kingma, Max Welling, 2013 ŌĆó [ļģ╝ļ¼ĖņØś Ļ░ĆņĀĢ] We will restrict ourselves here to the common case where we have an i.i.d. dataset with latent variables per datapoint, and where we like to perform maximum likelihood (ML) or maximum a posteriori (MAP) inference on the (global) parameters, and variational inference on the latent variables.
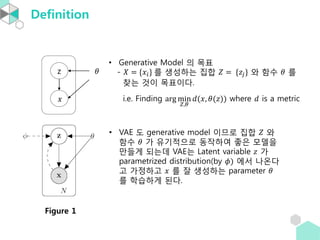
- 16. Definition ŌĆó Generative Model ņØś ļ¬®Ēæ£ - Øæŗ = {ØæźØæ¢} ļź╝ ņāØņä▒ĒĢśļŖö ņ¦æĒĢ® ØæŹ = {Øæ¦ØæŚ} ņÖĆ ĒĢ©ņłś Ø£ā ļź╝ ņ░ŠļŖö Ļ▓āņØ┤ ļ¬®Ēæ£ņØ┤ļŗż. i.e. Finding arg min ØæŹ,Ø£ā Øææ(Øæź, Ø£ā(Øæ¦)) where Øææ is a metric ŌĆó VAE ļÅä generative model ņØ┤ļ»ĆļĪ£ ņ¦æĒĢ® ØæŹ ņÖĆ ĒĢ©ņłś Ø£ā Ļ░Ć ņ£ĀĻĖ░ņĀüņ£╝ļĪ£ ļÅÖņ×æĒĢśņŚ¼ ņóŗņØĆ ļ¬©ļŹĖņØä ļ¦īļōżĻ▓ī ļÉśļŖöļŹ░ VAEļŖö Latent variable Øæ¦ Ļ░Ć parametrized distribution(by Ø£Ö) ņŚÉņä£ ļéśņś©ļŗż Ļ│Ā Ļ░ĆņĀĢĒĢśĻ│Ā Øæź ļź╝ ņל ņāØņä▒ĒĢśļŖö parameter Ø£ā ļź╝ ĒĢÖņŖĄĒĢśĻ▓ī ļÉ£ļŗż. Figure 1 z Øæź Ø£ā
- 17. Problem scenario ŌĆó Dataset Øæŗ = Øæź Øæ¢ Øæ¢=1 Øæü ļŖö i.i.d ņØĖ continuous(ļśÉļŖö discrete) variable Øæź ņØś sample ņØ┤ļŗż. Øæŗ ļŖö unobserved continuous variable Øæ¦ ņØś some random process ļĪ£ ņāØņä▒ļÉśņŚłļŗżĻ│Ā Ļ░ĆņĀĢĒĢśņ×É. ņŚ¼ĻĖ░ņä£ random process ļŖö ļæÉ Ļ░£ņØś step ņ£╝ļĪ£ ĻĄ¼ņä▒ļÉśņ¢┤ņ׳ļŗż: (1) Øæ¦(Øæ¢) is generated from some prior distribution ØæØ Ø£āŌłŚ(Øæ¦) (2) Øæź(Øæ¢) is generated from some conditional distribution ØæØ Ø£āŌłŚ(Øæź|Øæ¦) ŌĆó Prior ØæØ Ø£āŌłŚ Øæ¦ ņÖĆ likelihood ØæØ Ø£āŌłŚ(Øæź|Øæ¦) ļŖö differentiable almost everywhere w.r.t Ø£ā and Øæ¦ ņØĖ parametric families of distributions ØæØ Ø£ā(Øæ¦)ņÖĆ ØæØ Ø£ā(Øæź|Øæ¦) ļōżņØś ņŚÉņä£ ņś© Ļ▓āņ£╝ļĪ£ Ļ░ĆņĀĢĒĢśņ×É. ŌĆó ņĢäņēĮĻ▓īļÅä true parameter Ø£āŌłŚ ņÖĆ latent variables Øæ¦(Øæ¢) ņØś Ļ░ÆņØä ņĢī ņłś ņŚåņ¢┤ņä£ cost function ņØä ņĀĢĒĢśĻ│Ā ĻĘĖĻ▓āņØś lower bound ļź╝ ĻĄ¼ĒĢśļŖö ļ░®Ē¢źņ£╝ļĪ£ ņĀäĻ░£ļÉĀ ņśłņĀĢņØ┤ļŗż.
- 18. Intractibility and Variational Inference ŌĆó ØæØ Ø£ā Øæź = ØæØ Ø£ā Øæź ØæØ Ø£ā Øæź Øæ¦ ØææØæ¦ is intractable(Ļ│äņé░ ļČłĻ░ĆļŖź) ŌłĄ ØæØ Ø£ā Øæ¦ Øæź = ØæØ Ø£ā Øæź Øæ¦ ØæØ Ø£ā(Øæ¦)/ØæØ Ø£ā(Øæź) is intractable ŌĆó ØæØ Ø£ā Øæ¦ Øæź ļź╝ ņĢī ņłś ņŚåņ£╝ļŗł ņÜ░ļ”¼Ļ░Ć ņĢäļŖö ĒĢ©ņłśļØ╝Ļ│Ā Ļ░ĆņĀĢĒĢśņ×É. ņØ┤ļ¤░ ļ░®ļ▓ĢņØä variational inference ļØ╝Ļ│Ā ĒĢ£ļŗż. ņ”ē, ņל ņĢäļŖö ĒĢ©ņłś Øæ× Ø£Ö(Øæ¦|Øæź) ļź╝ ØæØ Ø£ā Øæ¦ Øæź ļīĆņŗĀ ņé¼ņÜ®ĒĢśļŖö ļ░®ļ▓ĢņØä variational inference ļØ╝Ļ│Ā ĒĢ£ļŗż. ŌĆó Idea : prior ØæØ Ø£ā Øæ¦ Øæź ļź╝ Øæ× Ø£Ö(Øæ¦|Øæź) ļĪ£ ņé¼ņÜ®ĒĢ┤ļÅä ļÉśļŖö ņØ┤ņ£ĀļŖö ņŻ╝ņ¢┤ņ¦ä input Øæ¦ Ļ░Ć Øæź ņŚÉ ĻĘ╝ņé¼ĒĢśĻ▓ī ĒĢÖņŖĄņØ┤ ļÉ£ļŗż.
- 19. Then variational bound ŌĆó ņÜ░ļ”¼ļŖö Øæŗ = Øæź Øæ¢ Øæ¢=1 Øæü Ļ░Ć i.i.d ļź╝ ļ¦īņĪ▒ĒĢ£ļŗżĻ│Ā Ļ░ĆņĀĢĒ¢łņ£╝ļ»ĆļĪ£ log ØæØ Ø£ā(Øæź 1 , Ōŗ» , Øæź(Øæü) ) = Øæ¢=1 Øæü log ØæØ Ø£ā(Øæź Øæ¢ ) ņØ┤ļŗż. ŌĆó Ļ░üĻ░üņØś Øæź Ōłł ØæŗņŚÉ ļīĆĒĢ┤ ņĢäļל ņŗØņØä ņ¢╗ņØä ņłś ņ׳ļŗż: log ØæØ Ø£ā Øæź = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā(Øæź) ØææØæ¦ = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæ¦,Øæź ØæØ Ø£ā(Øæ¦|Øæź) ØææØæ¦ = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæ¦,Øæź Øæ× Ø£Ö Øæ¦ Øæź Øæ× Ø£Ö Øæ¦ Øæź ØæØ Ø£ā Øæ¦ Øæź ØææØæ¦ = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæ¦,Øæź Øæ× Ø£Ö Øæ¦ Øæź ØææØæ¦ + Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź Øæ× Ø£Ö Øæ¦ Øæź ØæØ Ø£ā Øæ¦ Øæź ØææØæ¦ = Øōø Ø£ā, Ø£Ö; Øæź + ØÉĘ ØÉŠØÉ┐(Øæ× Ø£ā(Øæ¦|Øæź)||ØæØ Ø£ā Øæ¦ Øæź ) (1) Ōēź Øōø Ø£ā, Ø£Ö; Øæź ņ¢ĖņĀ£ļéś ØÉŠØÉ┐ divergence ļŖö 0 ņØ┤ņāüņØ┤ļ»ĆļĪ£ Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæ¦,Øæź Øæ× Ø£Ö Øæ¦ Øæź ØææØæ¦ ļŖö lower bound Ļ░Ć ļÉ£ļŗż. ņØ┤Ļ▓ā ņØä Øōø Ø£ā, Ø£Ö; Øæź ļØ╝Ļ│Ā ļåōņ×É.
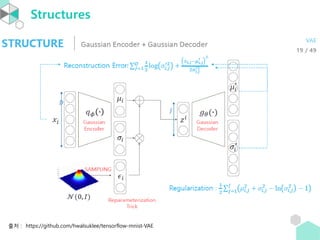
- 20. Cost function ŌĆó (Eq.3) Øōø Ø£ā, Ø£Ö; Øæź = ŌłÆØÉĘ ØÉŠØÉ┐(Øæ× Ø£Ö(Øæ¦|Øæź)||ØæØ Ø£ā Øæź ) + ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)] <Proof> Øōø Ø£ā, Ø£Ö; Øæź = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā(Øæ¦,Øæź) Øæ× Ø£Ö(Øæ¦|Øæź) ØææØæ¦ = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæ¦)ØæØ Ø£ā(Øæź|Øæ¦ Øæ× Ø£Ö (Øæ¦|Øæź) ØææØæ¦ = Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā(Øæ¦) Øæ× Ø£Ö (Øæ¦|Øæź) ØææØæ¦ + Øæ¦ Øæ× Ø£Ö Øæ¦ Øæź log ØæØ Ø£ā Øæź Øæ¦ ØææØæ¦ = ŌłÆØÉĘ ØÉŠØÉ┐(Øæ× Ø£Ö(Øæ¦|Øæź)| ØæØ Ø£ā(Øæ¦) + ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)] Øæ× Ø£ÖņÖĆ ØæØ Ø£āĻ░Ć normal ņØ┤ļ®┤ Ļ│äņé░ Ļ░ĆļŖź! Reconstruction error
- 21. Cost function ŌĆó Lemma. If ØæØ Øæź ~Øæü Ø£ć1, Ø£Ä1 2 and Øæ× Øæź ~Øæü Ø£ć2, Ø£Ä2 2 , then ØÉŠØÉ┐(ØæØ(Øæź)||Øæ× Øæź ) = ln Ø£Ä2 Ø£Ä1 + Ø£Ä1 2 + Ø£ć1 ŌłÆ Ø£ć2 2 2Ø£Ä2 2 ŌłÆ 1 2 ŌĆó Corollary. Øæ× Ø£Ö Øæ¦ Øæź ~ Øæü(Ø£ćØæ¢, Ø£ÄØæ¢ 2 ØÉ╝) ņØ┤Ļ│Ā ØæØ Øæ¦ ~Øæü 0,1 ņØ┤ļ®┤ ØÉŠØÉ┐ Øæ× Ø£Ö Øæ¦ ØæźØæ¢ ØæØ Øæ¦ = 1 2 (ØæĪØæ¤ Ø£ÄØæ¢ 2 ØÉ╝ + Ø£ćØæ¢ Øæ¢ ØæćØ£ć ŌłÆ ØÉĮ + ln 1 ØæŚ=Øæ¢ ØÉĮ Ø£ÄØæ¢,ØæŚ 2 ) = (╬ŻØæŚ=1 ØÉĮ Ø£ÄØæ¢,ØæŚ 2 + ╬ŻØæŚ=1 ØÉĮ Ø£ćØæ¢,ØæŚ 2 ŌłÆ ØÉĮ ŌłÆ ╬ŻØæŚ=1 ØÉĮ ln(Ø£ÄØæ¢,ØæŚ 2 )) = 1 2 ╬ŻØæŚ=1 ØÉĮ (Ø£ćØæ¢,ØæŚ 2 + Ø£ÄØæ¢,ØæŚ 2 ŌłÆ 1 ŌłÆ ln Ø£ÄØæ¢,ØæŚ 2 ) ŌĆó ņ”ē, Øæ× Ø£Ö Øæ¦ Øæź ~ Øæü(Ø£ćØæ¢, Ø£ÄØæ¢ 2 ØÉ╝) ņØ┤Ļ│Ā ØæØ Øæ¦ ~Øæü 0,1 ņØ┤ļ®┤ Eq.3 ļŖö ņĢäļלņÖĆ Ļ░Öļŗż. Øōø Ø£ā, Ø£Ö; Øæź = 1 2 ╬ŻØæŚ=1 ØÉĮ Ø£ćØæ¢,ØæŚ 2 + Ø£ÄØæ¢,ØæŚ 2 ŌłÆ 1 ŌłÆ ln Ø£ÄØæ¢,ØæŚ 2 + ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)]
- 22. Reconstruction error ĒĢÖņŖĄ ļ░®ļ▓Ģ ŌĆó ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)]ļŖö sampling ņØä ĒåĄĒĢ┤ Monte-carlo estimation ĒĢ£ļŗż. ņ”ē, ØæźØæ¢ Ōłł X ļ¦łļŗż Øæ¦ Øæ¢,1 , Ōŗ» , Øæ¦ Øæ¢ ØÉ┐ ļź╝ sampling ĒĢśņŚ¼ log likelihood ņØś meanņ£╝ļĪ£ ĻĘ╝ņé¼ņŗ£Ēé©ļŗż. ļ│┤ĒåĄ ØÉ┐ = 1 ņØä ļ¦ÄņØ┤ ņé¼ņÜ®ĒĢ£ļŗż. ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)] Ōł╝ 1 ØÉ┐ ╬ŻØæÖ=1 ØÉ┐ log(ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢,ØæÖ ) ŌĆó ņØ┤ļĀćĻ▓ī sampling ņØä ĒĢśļ®┤ backpropagation ņØä ĒĢĀ ņłś ņŚåļŗż. ĻĘĖļלņä£ ņé¼ņÜ® ļÉśļŖö ļ░®ļ▓ĢņØ┤ reparametrization trick ņØ┤ļŗż. Øæ× Ø£Ö Øæź Øæ¦ ØæØ Ø£ā Øæź Øæ¦
- 23. Reparametrization trick ŌĆó Reparametrization trick : sampling ņŚÉņä£ ņāØĻĖ░ļŖö backpropagation ļČłĻ░ĆļŖź ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ£ ļ░®ļ▓Ģ. Øæ¦~Øæü Ø£ć, Ø£Ä2 ŌćÆ Øæ¦ = Ø£ć + Ø£ÄØ£¢ where Ø£¢~Øæü(0,1)
- 24. Log Likelihood ŌĆó ņĢ×ņŚÉņä£ reconstruction error ļź╝ Ļ│äņé░ĒĢĀ ļĢī ĒĢśļéśņö® sampling ņØä ĒĢśļ®┤ ØÉĖ Øæ× Ø£Ö Øæ¦ Øæź [log ØæØ Ø£ā(Øæź|Øæ¦)] Ōł╝ 1 ØÉ┐ ╬ŻØæÖ=1 ØÉ┐ log ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢,ØæÖ = log(ØæØ Ø£ā(ØæźØæ¢|Øæ¦ Øæ¢ ) Ļ░Ć ļÉ£ļŗż. ņŚ¼ĻĖ░ņä£ ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢ ņØś ļČäĒżĻ░Ć Bernoulli ņØĖ Ļ▓ĮņÜ░ņŚÉ ņĢäļלņØś ņŗØņØä ņ¢╗ņØä ņłś ņ׳ļŗż. ņČ£ņ▓ś : https://github.com/hwalsuklee/tensorflow-mnist-VAE
- 25. Log Likelihood ŌĆó ØæØ Ø£ā ØæźØæ¢ Øæ¦ Øæ¢ ņØś ļČäĒżĻ░Ć normal ņØĖ Ļ▓ĮņÜ░ņŚÉ ņĢäļלņØś ņŗØņØä ņ¢╗ņØä ņłś ņ׳ļŗż. ņČ£ņ▓ś : https://github.com/hwalsuklee/tensorflow-mnist-VAE
- 28. Examples of VAE ņČ£ņ▓ś : https://github.com/hwalsuklee/tensorflow-mnist-VAE
- 29. Examples of DAE ņČ£ņ▓ś : https://github.com/hwalsuklee/tensorflow-mnist-VAE
- 30. References ŌĆó [VLBM] Extracting and composing robust features with denoising autoencoders, Vincent, Larochelle, Bengio, Manzagol, 2008 ŌĆó [KW] Auto-Encoding Variational Bayes, Diederik P Kingma, Max Welling, 2013 ŌĆó [D] Tutorial on Variational Autoencoders - Carl Doersch, 2016 ŌĆó PR-010: Auto-Encoding Variational Bayes, ICLR 2014, ņ░©ņżĆļ▓ö ŌĆó ņśżĒåĀņØĖņĮöļŹöņØś ļ¬©ļōĀ Ļ▓ā, ņØ┤ĒÖ£ņäØ https://github.com/hwalsuklee/tensorflow-mnist-VAE