“”³Õ³ŻĆüĮī¤ņÓƤ¤¤æ³¢“³¤ĪĮ¦¼ĘĖć¤Ī³§±õ²Ń¶Ł»Æ
?
0 likes?1,729 views

“”³Õ³ŻĆüĮī¤ņŹ¹¤Ć¤Ę³¢±š²Ō²Ō²¹°ł»å-“³“Ē²Ō±š²õ„Ż„Ę„ó„·„ć„ė¤ĪĮ¦¼ĘĖć¤Ī³§±õ²Ń¶Ł»Æ¤ņŹŌ¤ß¤ė











![University of Tokyo
14/29
„ģ„ø„¹„æ¤Č„į„ā„ź
A[2]
Č«¤Ę¤ĪÓĖć¤ĻŌt¤Č¤·¤Ę„ģ„ø„¹„æÉĻ¤ĒŠŠ¤¦
”øC = A + B”¹¤ņÓĖć¤¹¤ėĄż£ŗ
(1)? „į„ā„ź¤«¤éA¤ČB¤ņ„ģ„ø„¹„æ¤Ė„ķ©`„É
(2)? „ģ„ø„¹„æ¤ĒA+B¤ņÓĖć
(3)? ½Y¹ūC¤ņ„ģ„ø„¹„椫¤é„į„ā„ź¤Ė„¹„Č„¢
A[1]
SIMD
SIMD: Ń}Źż¤Ī„Ē©`„æ¤Ė¤·¤Ę”¢Ņ»¶Č¤ĖĶ¬¤ø„愤„פĪŃŻĖć¤ņŠŠ¤¦ŹĖ½M¤ß
SIMDÓĆ„ģ„ø„¹„æ£ŗŃ}Źż¤Ī¤ņĶ¬r¤Ė±£³Ö”¢ŃŻĖć¤Ē¤¤ė„ģ„ø„¹„æ
C[1] = A[1]+B[1]
C[2] = A[2]+B[2]
A
B
C
1
2
„į„ā„ź
„ģ„ø„¹„æ
3
1
2
+
3
„ķ©`„É
„¹„Č„¢
B[2]
B[1]
+
C[2]
C[1]
=
¶ž¤ÄŅŌÉĻ¤ĪŃŻĖć¤ņŅ»¶Č¤ĖŠŠ¤¦¤³¤Č¤¬¤Ē¤¤ė
x86„ģ„ø„¹„æ (1/3)](https://image.slidesharecdn.com/ljavx-161031083209/85/AVX-LJ-SIMD-14-320.jpg)






![University of Tokyo
21/29
¤ä¤Ć¤æ¤³¤Č
„Ē©`„æ¤ņĮ£×ÓŹż*4³É·Ö¤Ī¶ž“ĪŌŖÅäĮŠ¤ĒŠūŃŌ
double q[N][4], p[N][4];
z
y
x
z
y
x
„į„ā„ź
z
y
x
0
1
2
z
y
x
3
Į£×Ó·¬ŗÅ
¤¦¤ģ¤·¤¤¤³¤Č
(x,y,z)¤Ī3³É·Ö¤Ī„Ē©`„æ¤ņymm„ģ„ø„¹„æ¤ĖŅ»°k„ķ©`„É
¤æ¤Ą¤·”¢1³É·Ö(64bit) ¤Ļońj¤Ė¤Ź¤ė
z
y
x
z
y
x
„į„ā„ź
z
y
x
0
1
2
z
y
x
3
Į£×Ó·¬ŗÅ
z
y
x
movupd/movapd
ymm0
Į¦ÓĖć¤ĪSIMD»Æ (1/5)](https://image.slidesharecdn.com/ljavx-161031083209/85/AVX-LJ-SIMD-21-320.jpg)








“”³Õ³ŻĆüĮī¤ņÓƤ¤¤æ³¢“³¤ĪĮ¦¼ĘĖć¤Ī³§±õ²Ń¶Ł»Æ
- 1. University of Tokyo 1/29 “”³Õ³ŻĆüĮī¤ņÓƤ¤¤æ³¢“³¤ĪĮ¦¼ĘĖć¤Ī³§±õ²Ń¶Ł»Æ 2016Äź10ŌĀ31ČÕ ¶ÉŽxÖęÖ¾ ¶«¾©“óѧĪļŠŌŃŠ¾æĖł
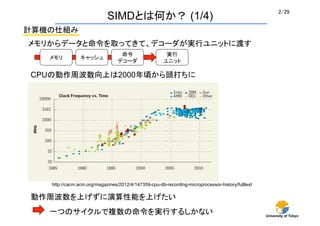
- 2. University of Tokyo 2/29 SIMD¤Č¤ĻŗĪ¤«£æ (1/4) Ņ»¤Ä¤Ī„µ„¤„Æ„ė¤ĒŃ}Źż¤ĪĆüĮī¤ņgŠŠ¤¹¤ė¤·¤«¤Ź¤¤ ÓĖćC¤ĪŹĖ½M¤ß ĆüĮī „Ē„³©`„Ą gŠŠ „ę„Ė„Ć„Č „„ć„Ć„·„å „į„ā„ź „į„ā„ź¤«¤é„Ē©`„æ¤ČĆüĮī¤ņČ”¤Ć¤Ę¤¤Ę”¢„Ē„³©`„Ą¤¬gŠŠ„ę„Ė„ƄȤĖ¶É¤¹ Ó×÷ÖÜ²ØŹż¤ņÉĻ¤²¤ŗ¤ĖŃŻĖćŠŌÄܤņÉĻ¤²¤æ¤¤ CPU¤ĪÓ×÷ÖÜ²ØŹżĻņÉĻ¤Ļ2000Äźķ¤«¤éī^“ņ¤Į¤Ė http://cacm.acm.org/magazines/2012/4/147359-cpu-db-recording-microprocessor-history/fulltext
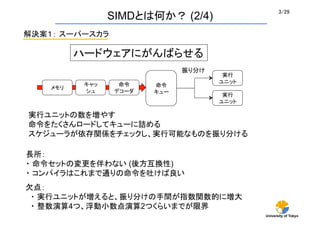
- 3. University of Tokyo 3/29 ½āQ°ø£±£ŗ „¹©`„Ń©`„¹„«„é ĆüĮī „Ē„³©`„Ą gŠŠ „ę„Ė„Ć„Č „„ć„Ć „·„å „į„ā„ź gŠŠ „ę„Ė„Ć„Č Ē·µć£ŗ ””? gŠŠ„ę„Ė„ƄȤ¬¤Ø¤ė¤Č”¢Õń¤ź·Ö¤±¤ĪŹÖég¤¬ÖøŹżévŹżµÄ¤Ė“ó ””? ÕūŹżŃŻĖć4¤Ä”¢ø”ÓŠ”ŹżµćŃŻĖć2¤Ä¤Æ¤é¤¤¤Ž¤Ē¤¬ĻŽ½ē SIMD¤Č¤ĻŗĪ¤«£æ (2/4) gŠŠ„ę„Ė„ƄȤĪŹż¤ņ¤ä¤¹ ĆüĮī¤ņ¤æ¤Æ¤µ¤ó„ķ©`„ɤ·¤Ę„„å©`¤ĖŌ¤į¤ė „¹„±„ø„å©`„餬ŅĄ“ęévS¤ņ„Į„§„Ć„Æ¤·”¢gŠŠæÉÄܤŹ¤ā¤Ī¤ņÕń¤ź·Ö¤±¤ė éLĖł£ŗ ? ĆüĮī„»„ƄȤĪäøü¤ņ°é¤ļ¤Ź¤¤ (įį·½»„QŠŌ) ? „³„ó„Ń„¤„é¤Ļ¤³¤ģ¤Ž¤ĒĶؤź¤ĪĆüĮī¤ņĶĀ¤±¤ŠĮ¼¤¤ „Ļ©`„É„¦„§„¢¤Ė¤¬¤ó¤Š¤é¤»¤ė ĆüĮī „„å©` Õń¤ź·Ö¤±
- 4. University of Tokyo 4/29 ½āQ°ø2£ŗ VLIW ĆüĮī „Ē„³©`„Ą gŠŠ „ę„Ė„Ć„Č „„ć„Ć „·„å „į„ā„ź gŠŠ „ę„Ė„Ć„Č „³„ó„Ń„¤„é¤Ė¤¬¤ó¤Š¤é¤»¤ė ĆüĮīA ĆüĮīB gŠŠ„ę„Ė„ƄȤĪŹż¤ĻŃ}ŹżÓĆŅā¤·¤Ę¤Ŗ¤Æ „³„ó„Ń„¤„餬Óč¤įKĮŠgŠŠæÉÄܤŹĆüĮī¤ņK¤Ł¤Ę¤Ŗ¤”¢¤½¤Ī¤Ž¤ŽgŠŠ„ę„Ė„ƄȤĖĮ÷¤¹ éLĖł£ŗ ? ŅĄ“ęévS„Į„§„Ć„Æ¤¬²»ŅŖ¤Ė¤Ź¤ė¤æ¤į”¢„Ļ©`„É„¦„§„¢¤Ļŗ g¤Ė¤Ź¤ė ? „³©`„ÉČ«Ģå¤ņÕ{¤Ł¤ė¤æ¤į”¢¤č¤ź·eOµÄ¤Ź×īßm»Æ¤¬æÉÄÜ ¶ĢĖł£ŗ ? „³„ó„Ń„¤„é×÷¤ė¤Ī¤¬ĖĄ¤Ģ¤Ū¤É“óä ? įį·½»„QŠŌ¤ņŹ§¤¦ (ĆüĮī„»„ƄȤ¬ä¤ļ¤ė¤æ¤į) SIMD¤Č¤ĻŗĪ¤«£æ (3/4)
- 5. University of Tokyo 5/29 SIMD¤Č¤ĻŗĪ¤«£æ (4/4) ĆüĮī „Ē„³©` „Ą gŠŠ „ę„Ė„Ć„Č „„ć„Ć „·„å „į„ā„ź ½āQ°ø3£ŗ SIMD „ׄķ„°„é„Ž¤Ė¤¬¤ó¤Š¤é¤»¤ė gŠŠ„ę„Ė„ƄȤĪŹż¤Ļ¤ä¤µ¤Ź¤¤ Ń}Źż¤Ī„Ē©`„æ¤Ė”¢Ķ¬¤øŃŻĖć¤ņŅ»¶Č¤ĖŠŠ¤¦ éLĖł£ŗ ? „Ļ©`„É„¦„§„¢¤¬ŗ g¤Ė¤Ź¤ė ? SIMD¤ĻĆüĮī„»„ƄȤĪ¤Č¤¤¤¦ŠĪ¤ĒČė¤ė¤æ¤į”¢įį·½»„QŠŌ¤ā¤½¤ģ¤Ź¤ź ¶ĢĖł£ŗ ? „³„ó„Ń„¤„餬SIMDĆüĮī¤ņæĀŹµÄ¤ĖĶĀ¤Æ¤Ī¤Ļėy¤·¤¤ ? „ׄķ„°„é„Ž¤¬Ć÷Ź¾µÄ¤ĖSIMDĆüĮī¤ņŹ¹¤¦±ŲŅŖ¤¬¤¢¤ė ¬FŌŚ¤Ļ„¹©`„Ń©`„¹„«„飫SIMD¤¬Ö÷Į÷ gŠŠ„ę„Ė„ƄȤĪŹż¤Ļ¤Ø¤ŗ”¢SIMD·ł¤¬¤Ø¤Ę¤¤¤ÆAĻņ
- 6. University of Tokyo 6/29 http://news.mynavi.jp/photo/articles/2016/09/08/hc28_arm2/images/009l.jpg „Ż„¹„Č¾© „½„Õ„Č„¦„§„¢: ””? SVE (Scalable Vector Extension) ””? 512?2048bit¤ĪæÉäéL„Ł„Æ„Č„ėĆüĮī „Ļ©`„É„¦„§„¢£ŗ ””?512bit (±¶¾«¶Č64bit ”Į 8)¤Ēg×° ¤Ź¤ó¤ĒSIMD»Æ¤¹¤ė¤Ī£æ A: SIMD»Æ¤·¤Ź¤¤¤ČŠŌÄܤ¬³ö¤Ź¤Æ¤Ź¤Ć¤Ę¤¤¤Æ¤«¤é „·„¹„Ę„ąB Haswell”¢AVXĆüĮī ?256bit (±¶¾«¶Č64bit ”Į 4) (2016Äź8ŌĀ¹«±ķ@Hot Chips 28) ¾© SPARC-VIIIxfx, HPC-ACE ?128bit (±¶¾«¶Č64bit ”Į 2) 128bit¤Æ¤é¤¤¤Ž¤Ē¤Ź¤é„¹„ė©`¤Ē¤¤æ¤¬”¢512bit¤Ą¤ČÕęĆęÄæ¤Ė¤ä¤é¤Ź¤¤¤Čæą¤·¤¤£æ
- 9. University of Tokyo 9/29 „Ś„¢„ź„¹„ȤČBookkeeping·Ø (1/2) Ļą»„×÷ÓĆ„Ś„¢„ź„¹„Č „«„Ć„Č„Ŗ„Õ¾ąėxŅŌÄŚ¤Ė¤¢¤ėĻą»„×÷ÓĆŌ×Ó„Ś„¢¤ņĢ½¤¹ Č«Ģ½Ė÷¤¹¤ė¤ČO(N^2)¤Č¤Ź¤ė¤Ī¤Ē”¢æÕég¤ņ„»„ė¤ĖĒųĒŠ¤Ć¤ĘO(N)¤ĖĀä¤Č¤¹ æÕég¤ņ„»„ė¤ĖĒŠ¤ė Ō×Ó¤ņ„»„ė¤ĖµĒåh¤¹¤ė „»„ėÄŚ”¢ėO½Ó„»„ė¤ĒĻą»„×÷ÓĆ„Ś„¢¤ņĢ½Ė÷¤¹¤ė „»„ė¤Ī“󤤵¤Ļ”¢Ļą»„×÷ÓƤ¬“Ī½ü½Ó¤Ī„»„ė¤Ė½ģ¤«¤Ź¤¤¤č¤¦¤Ė¤Č¤ė
- 10. University of Tokyo 10/29 Bookkeeping¤Ė¤č¤ė„Ś„¢„ź„¹„ČŌŁĄūÓĆ „Ś„¢„ź„¹„ȤČBookkeeping·Ø (2/2) Ļą»„×÷ÓĆ„Ś„¢Ģ½Ė÷¤ĻÖŲ¤¤IĄķ ”ś Ģ½Ė÷¾ąėx¤ņéL¤į¤Ė¤Č¤Ć¤ĘŗĪ„¹„ʄƄפ«ŌŁĄūÓƤ¹¤ė Ō×Ó¤¬„Ž©`„ø„ó¤ņŗįĒŠ¤ė¤Ž¤Ē¤³¤Ī„Ś„¢„ź„¹„ȤĻŌŁĄūÓƤĒ¤¤ė Ļą»„×÷ÓĆ¾ąėx Ģ½Ė÷¾ąėx „Ž©`„ø„ó ? „Ž©`„ø„ó¤ņ”ø„Ś„¢„ź„¹„ȤĪŹŁĆü”¹¤Č¤¹¤ė ? Ļµ¤Ī×īĖŁ¤ĪŌ×Ó¤ņĢ½¤·”¢¤½¤ĪĖŁ¶Č¤ņv¤Č¤¹¤ė ? „Ž©`„ø„󤫤é v*2*dt¤Ą¤±Ņż¤Æ (dt¤ĻrégæĢ¤ß) ? ¤Ž¤Ą„Ž©`„ø„󤬲Š¤Ć¤Ę¤¤¤ģ¤Š„Ś„¢„ź„¹„ȤņŌŁĄūÓĆ ? „Ž©`„ø„ó¤¬o¤Æ¤Ź¤Ć¤æ¤é„Ś„¢„ź„¹„ČŌŁŗB Ļą»„×÷ÓĆ¾ąėx „Ž©`„ø„ó ×ī¤Ī„±©`„¹ ×īĖŁ¤Č“Ī×īĖŁ¤ĪŌ×Ó¤¬”¢¤Ŗ»„¤¤¤Ė½ü¤Å¤Ær ”ś Ļµ¤Ī×īĖŁ¤ĪŌ×Ó¤¬„Ž©`„ø„ó¤Ī°ė·Ö¤ņ ””””ŗįĒŠ¤ė¤Ž¤Ē¤Ļ„Ś„¢„ź„¹„Ȥ¬ÓŠæ ÓŠæĘŚĻŽÅŠ¶Ø
- 11. University of Tokyo 11/29 Ļą»„×÷ÓĆ„Ś„¢„½©`„Č (1/2) Į¦¤ĪÓĖć¤Č„Ś„¢„ź„¹„Č Į¦¤ĪÓĖć¤Ļ„Ś„¢¤“¤Č¤ĖŠŠ¤¦ Ļą»„×÷ÓĆ¹ ģÄŚ¤Ė¤¢¤ė„Ś„¢¤ĻÅäĮŠ¤Ėøń¼{ „Ś„¢¤Ī·¬ŗŤĪČō¤¤·½¤ņiĮ£×Ó”¢ĻąŹÖ¤ņjĮ£×Ó¤Čŗō¤Ö µĆ¤é¤ģ¤æĻą»„×÷ÓĆ„Ś„¢ Ļą»„×÷ÓĆ„Ś„¢¤ĪÅäĮŠ±ķ¬F 1 0 0 2 3 3 1 1 2 3 0 2 9 2 1 7 9 5 2 4 8 4 5 6 ¤³¤Ī¤Ž¤ŽÓĖć¤¹¤ė¤Č 2¤ĪĮ£×Ó¤Ī׳Ė¤ņČ”µĆ (48Byte) ß\ÓĮæ¤ĪÕi¤ßų¤ (96Byte) Į¦¤ĪÓĖ椬50ŃŻĖć³Ģ¶Č¤Č¤¹¤ė¤Č”¢B/F?3.0¤ņŅŖĒó 1 9 0 2 0 1 2 7 3 9 3 5 1 2 1 4 2 8 3 4 0 5 2 6 iĮ£×Ó jĮ£×Ó iĮ£×Ó jĮ£×Ó
- 12. University of Tokyo 12/29 Ļą»„×÷ÓĆĻąŹÖ¤Ē„½©`„Č Ļą»„×÷ÓĆ„Ś„¢ Ļą»„×÷ÓĆ„Ś„¢„½©`„Č (2/2) 1 9 0 2 0 1 2 7 3 9 3 5 1 2 1 4 2 8 3 4 0 5 2 6 iĮ£×Ó¤Ē„½©`„Č 1 2 5 2 4 9 6 7 8 4 5 9 Sorted List 0 1 2 5 1 2 4 9 2 6 7 8 3 4 5 9 ÅäĮŠ±ķ¬F 0 1 2 3 iĮ£×Ó¤ĪĒé󤬄ģ„ø„¹„æ¤Ė¤Ī¤ė ”ś Õi¤ßŽz¤ß”¢ų¤Žz¤ß¤¬jĮ£×Ó¤Ī¤ß ”ś „į„ā„ź„¢„Æ„»„¹¤¬°ė·Ö¤Ė „„ć„Ć„·„å¤Ė\¤ėīIÓņ¤Ē¤ā10%Ē°įį¤ĪøßĖŁ»Æ iĮ£×Ó jĮ£×Ó iĮ£×Ó jĮ£×Ó
- 13. University of Tokyo 13/29 AVXĆüĮī¤Ė¤č¤ėSIMD»Æ Ē°ĢįĢõ¼ž£ŗ ””? Ļą»„×÷ÓĆĻąŹÖ¤Ļ„Ś„¢„ź„¹„ȤĖ¤č¤źég½Ó²ĪÕÕ”¢„¤„ó„Ē„Ć„Æ„¹¤Ļ²»ßB¾A ””? Bookkeeping·Ø¤Ė¤č¤ź”¢Ļą»„×÷ÓƤ·¤Ę¤¤¤Ź¤¤„Ś„¢¤āŗ¬¤Ž¤ģ¤ė
- 14. University of Tokyo 14/29 „ģ„ø„¹„æ¤Č„į„ā„ź A[2] Č«¤Ę¤ĪÓĖć¤ĻŌt¤Č¤·¤Ę„ģ„ø„¹„æÉĻ¤ĒŠŠ¤¦ ”øC = A + B”¹¤ņÓĖć¤¹¤ėĄż£ŗ (1)? „į„ā„ź¤«¤éA¤ČB¤ņ„ģ„ø„¹„æ¤Ė„ķ©`„É (2)? „ģ„ø„¹„æ¤ĒA+B¤ņÓĖć (3)? ½Y¹ūC¤ņ„ģ„ø„¹„椫¤é„į„ā„ź¤Ė„¹„Č„¢ A[1] SIMD SIMD: Ń}Źż¤Ī„Ē©`„æ¤Ė¤·¤Ę”¢Ņ»¶Č¤ĖĶ¬¤ø„愤„פĪŃŻĖć¤ņŠŠ¤¦ŹĖ½M¤ß SIMDÓĆ„ģ„ø„¹„æ£ŗŃ}Źż¤Ī¤ņĶ¬r¤Ė±£³Ö”¢ŃŻĖć¤Ē¤¤ė„ģ„ø„¹„æ C[1] = A[1]+B[1] C[2] = A[2]+B[2] A B C 1 2 „į„ā„ź „ģ„ø„¹„æ 3 1 2 + 3 „ķ©`„É „¹„Č„¢ B[2] B[1] + C[2] C[1] = ¶ž¤ÄŅŌÉĻ¤ĪŃŻĖć¤ņŅ»¶Č¤ĖŠŠ¤¦¤³¤Č¤¬¤Ē¤¤ė x86„ģ„ø„¹„æ (1/3)
- 15. University of Tokyo 15/29 ø”ÓŠ”Źżµć„ģ„ø„¹„æ ĻĀĪ» ÉĻĪ» xmm0 ymm0 ø”ÓŠ”ŹżµćŃŻĖćÓƤĖ256bit¤Ī„ģ„ø„¹„椬16±¾ÓĆŅā¤µ¤ģ¤Ę¤¤¤ė ¤½¤Ī¤¦¤ĮĻĀĪ»128bit¤ņxmm„ģ„ø„¹„æ”¢Č«Ģå¤ņymm„ģ„ø„¹„æ¤Čŗō¤Ö ±¶¾«¶ČgŹż¤Ļ64bit¤Ź¤Ī¤Ē”¢±¶¾«¶ČgŹż4¤Ä·Ö¤Ī¤ņ±£³Ö¤Ē¤¤ė ųÓĆ„ģ„ø„¹„æ 64bit¤ĪųÓĆ„ģ„ø„¹„椬¤¢¤ė ĻĀĪ»32bit, 16bit, 8bit¤ņeĆū¤Ē¹²ÓŠ „¢„É„ģ„Ć„·„ó„°¤äÕūŹżŃŻĖć¤ĖŹ¹¤¦ ĻĀĪ» ÉĻĪ» 64bit RAX EAX AX AH AL x86„ģ„ø„¹„æ (2/3)
- 16. University of Tokyo 16/29 xmm„ģ„ø„¹„æ¤Ļ±¶¾«¶ČgŹż¶ž¤Ä·Ö±£³Ö¤Ē¤¤ė¤¬”¢ĻĀĪ»64bit¤ņĘÕ¶ĪŹ¹¤¤¤ĖŹ¹¤¦ double func(double a, double b){ return a+b; } func(double, double): addsd %xmm1, %xmm0 ret „½©`„¹ „¢„»„ó„Ö„ź évŹż¤ĪŅżŹż¤Īdouble¤Ļ”¢ķ·¬¤Ėxmm0,xmm1¤Ė¤ņČė¤ģ¤ė ·µ¤ź¤¬double¤Īr¤Ļxmm0¤Ė¤ņČė¤ģ¤ė (xmm„ģ„ø„¹„æ¤ĪĻĀĪ»64bit¤Ą¤±Ź¹¤¦) ø”ÓŠ”ŹżµćŃŻĖć ÕūŹżŃŻĖć int func(int a, int b){ return a+b; } func(int, int): addl %esi, %eax ret ”ł gėH¤Ė¤Ļleal¤¬Ź¹¤ļ¤ģ¤ė „½©`„¹ „¢„»„ó„Ö„ź évŹż¤ĪŅżŹż¤Īint(32bit)¤Ļ”¢ķ·¬¤Ėeax, esi, edx, ecx, ...¤Ė¤ņČė¤ģ¤ė ·µ¤ź¤¬int¤Īr¤Ļeax¤Ė¤ņČė¤ģ¤ė x86„ģ„ø„¹„æ (3/3)
- 17. University of Tokyo 17/29 Lennard-Jones¤ĪĮ¦ÓĖć (1/2) V (r) = 4 r 12 r 6 f(r) = 48 r13 24 r7 r dx dy „Ż„Ę„ó„·„ć„ė Į¦ Į¦·e Ix = f ? dx r ? dt ? df ? dx df = ? 48 r14 24 r8 ”ō dt ¤³¤³¤ņ¤Ž¤Č¤į¤ė ÓĖ椷¤æ¤¤Įæ ~r = (dx, dy, dz)Ļą×łĖ r = |~r|Ļą¾ąėx
- 18. University of Tokyo 18/29 Lennard-Jones¤ĪĮ¦ÓĖć (2/2) ~qi = (qi x, qi y, qi z) ~qj = (qj x, qj y, qj z) ~dq = ~qj ~qi r2 = ~dq 2 r6 = r2 ? r2 ? r2 r14 = r6 ? r6 ? r2 pĖć*3 \Ėć*3 + ¼ÓĖć*2 \Ėć*2 \Ėć*2 df = (48 24 ? r6 ) ? dt r14 \Ėć*2 + pĖć*1 + ³żĖć1 \Ėć*3 + ¼ÓĖć*3 \Ėć*3 + ¼ÓĖć*3 ~pi = ~pi df ? ~dq ~pj = ~pj + df ? ~dq ¼Óp\Ėć * 27 + ³żĖć*1 LJ¤ĪĮ¦ÓĖć¤ĻŻX¤¤
- 19. University of Tokyo 19/29 Į¦ÓĖć¤Ī g¼SIMD»Æ (1/2) „Ź„¤©`„Ö¤Źg×° ?qi x qi x ŅŌĻĀ”¢SIMD„Ł„Æ„Č„ė„ģ„ø„¹„æ¤ņ„Ļ„ƄȤĒ±ķ¬F¤¹¤ė ?qj x qj xqj+1 xqj+2 xqj+3 x qi+1 xqi+2 xqi+3 x 4¤Ä¤Ī׳Ė„Ē©`„æ¤ņymm„ģ„ø„¹„æ¤Ė„ķ©`„ɤ¹¤ė 4¤Ä¤Ī׳Ė„Ē©`„æ¤ņymm„ģ„ø„¹„æ¤Ė„ķ©`„ɤ¹¤ė ”ł y, z¤āĶ¬ ”ł y, z¤āĶ¬ ?dx = ?qj x ?qi x ?r2 = ?dx 2 + ?dy 2 + ?dz 2 ¤¢¤Č¤ĻĶ¬¤ĖÓĖć¤¹¤ė¤³¤Č¤Ē”¢4¤ĪĮ£×Óég¤ĪĮ¦¤ņĶ¬r¤ĖÓĖć¤Ē¤¤ė
- 20. University of Tokyo 20/29 Ļą»„×÷ÓĆĮ£×Ó¤Ī„¤„ó„Ē„Ć„Æ„¹¤ĻßB¾A¤Ē¤Ļ¤Ź¤¤ ”ś 4¤Ä¤Ī„Ē©`„æ¤ņ„Š„é„Š„é¤Ė„ķ©`„É D C B A D C B A „į„ā„ź „ģ„ø„¹„æ D C B A A „į„ā„ź xmm0 D C B A B A „į„ā„ź xmm0 vmovsd vmovhpd D C B A C „į„ā„ź D C B A D C „į„ā„ź vmovsd vmovhpd B A ymm0 xmm1 xmm1 D C D C xmm1 (1) A¤ņxmm0ĻĀĪ»¤Ė„ķ©`„É (2) B¤ņxmm0ÉĻĪ»¤Ė„ķ©`„É (3) C¤ņxmm1ĻĀĪ»¤Ė„ķ©`„É (4) D¤ņxmm1ÉĻĪ»¤Ė„ķ©`„É (5) xmm1Č«Ģå¤ņymm0ÉĻĪ»128bit¤Ė„³„Ō©` vinsertf128 gėH¤ĖĘš¤¤ė¤³¤Č ī}µć ”ł ¤³¤ģ¤ņx,y,z׳Ė¤½¤ģ¤¾¤ģ¤Ē¤ä¤ė ”ł „Ē©`„æ¤Īų¤ų¤·¤āĶ¬ Į¦ÓĖć¤Ī g¼SIMD»Æ (2/2) ”ł vgatherdpd¤Ē¤Ź¤ó¤Č¤«¤Ē¤¤ė¤«¤ā¤·¤ģ¤Ź¤¤¤¬???
- 21. University of Tokyo 21/29 ¤ä¤Ć¤æ¤³¤Č „Ē©`„æ¤ņĮ£×ÓŹż*4³É·Ö¤Ī¶ž“ĪŌŖÅäĮŠ¤ĒŠūŃŌ double q[N][4], p[N][4]; z y x z y x „į„ā„ź z y x 0 1 2 z y x 3 Į£×Ó·¬ŗÅ ¤¦¤ģ¤·¤¤¤³¤Č (x,y,z)¤Ī3³É·Ö¤Ī„Ē©`„æ¤ņymm„ģ„ø„¹„æ¤ĖŅ»°k„ķ©`„É ¤æ¤Ą¤·”¢1³É·Ö(64bit) ¤Ļońj¤Ė¤Ź¤ė z y x z y x „į„ā„ź z y x 0 1 2 z y x 3 Į£×Ó·¬ŗÅ z y x movupd/movapd ymm0 Į¦ÓĖć¤ĪSIMD»Æ (1/5)
- 22. University of Tokyo 22/29 Į¦¤ĪÓĖć(1„Ś„¢) qj xqj yqj z qi xqi yqi z ?qj ?qi ?dq = ?qj ?qi ?dq 2 dx2dy2 dz2 dxdydz ¤³¤³¤«¤é r2 = dx2 + dy2 + dz2 ¤ņ×÷¤ź¤æ¤¤ SIMD¤Ī„·„ć„Ć„Õ„ėĆüĮī¤ņŹ¹¤¦ Į¦ÓĖć¤ĪSIMD»Æ (2/5)
- 23. University of Tokyo 23/29 „·„ć„Ć„Õ„ėĻµĆüĮī „ģ„ø„¹„æ©`„į„ā„źég¤ĪÜĖĶ¤ĻO¤į¤Ę„³„¹„Ȥ¬øߤ¤ ¤Ź¤Ī¤Ē”¢„ģ„ø„¹„æ¤ĪÖŠ¤Ē„Ē©`„æ¤ņK¤ÓĢę¤Ø¤æ¤¤ ”ś ŲNø»¤Ź„·„ć„Ć„Õ„ėĻµĆüĮī¤¬ÓĆŅā¤µ¤ģ¤Ę¤¤¤ė D C B A „Ł„Æ„Č„ė¤ĪK¤ÓĢę¤Ø (vpermpd) A B D B Ķ¬¤øŅŖĖŲ¤ĪÖŲŃ}æÉ ¶ž¤Ä¤Ī„Ł„Æ„Č„ė¤ĪŅŖĖŲ¤ņ»ģ¤¼¤ė (blendpd) D2 C2 B2 A2 D1 C1 B1 A1 D1 C2 B2 A1 ¤É¤Į¤é¤ĪŅŖĖŲ¤ņ„³„Ō©`¤¹¤ė¤«ßxk»Æ Į¦ÓĖć¤ĪSIMD»Æ (3/5)
- 24. University of Tokyo 24/29 Į¦¤ĪÓĖć(1„Ś„¢) cont. dx2dy2 dz2 dx2 dx2 dy2 dz2 dy2 dz2 Ļą„Ł„Æ„Č„ė¤Ī×Ō\¤ņK¤ÓĢę¤Ø¤ė Č«²æ×ć¤¹ r2 r2 r2 Į¦¤ĪÓĖć(4„Ś„¢) ¤³¤ģ¤ņ4¤Ä¤Ī„Ś„¢¤Ė¤Ä¤¤¤ĘŠŠ¤¦ r2 A r2 B r2 C r2 D r2 Ar2 A r2 Br2 B r2 Cr2 C r2 Dr2 D r2 Ar2 A r2 Cr2 C r2 Br2 B r2 Dr2 D unpacklpd vshufpd r2 Ar2 C r2 Br2 D ¤¢¤Č¤Ļ4„Ś„¢Ķ¬r¤ĖĮ¦¤ĪÓĖ椬¤Ē¤¤ė vpermpd Į¦ÓĖć¤ĪSIMD»Æ (4/5)
- 25. University of Tokyo 25/29 Į¦·e¤Īų¤ų¤· dfAdfBdfCdfD dfAdfAdfAdfA ~pi = ~pi df ? ~dq dxAdyAdzA (1) A„Ś„¢¤ĪĮ¦¤Ą¤±Č”¤ź³ö¤¹ vpermpd dfAdfAdfAdfApi xpi ypi z pi x pi ypi z= - ”Į (2) ß\ÓĮæ¤ņ„ķ©`„É (3) Į¦·e„Ł„Æ„Č„ė¤ĪÓĖć pi xpi ypi z pi xpi ypi z „į„ā„ź ymm„ģ„ø„¹„æ (4) ß\ÓĮæ¤Īų¤ų¤· pi xpi ypi z pi xpi ypi z „į„ā„ź ymm„ģ„ø„¹„æ ¤³¤ģ¤ņ4„Ś„¢¤Ė¤Ä¤¤¤ĘŠŠ¤¦ vfnmadd213pd vmovupd vmovupd Į¦ÓĖć¤ĪSIMD»Æ (5/5)
- 26. University of Tokyo 26/29 „Ž„¹„ÆIĄķ Bookkeeping·Ø¤Ė¤č¤ź”¢Ļą»„×÷ÓĆ¹ ģĶā¤Ī„Ś„¢¤ā¤¤¤ė”ś„Ž„¹„ÆIĄķ D2 C2 B2 A2 D1 C1 B1 A1 Ų Õż Õż Ų src1 src2 mask D2 C1 B1 A2 vblendvpd: „Ž„¹„ƤĪŅŖĖŲ¤ĪÕżŲ¤Ė¤č¤źŅŖĖŲ¤ņßx¤Ö ”ł gėH¤Ė¤Ļmask¤Ī×īÉĻĪ»bit¤¬0¤«1¤«¤ĒÅŠ¶Ø¤·¤Ę¤¤¤ė Ļą»„×÷ÓĆ¾ąėx¤Č„«„Ć„Č„Ŗ„Õ¾ąėx¤Ē„Ž„¹„Ƥņ×÷³É¤·”¢Į¦¤ņ„¼„ķ„Æ„ź„¢ dfAdfBdfCdfD 0 0 0 0 src1 src2 dfBdfC0 0 „Ś„¢A¤ČD¤¬Ļą»„×÷ÓĆ¹ ģĶā „«„Ć„Č„Ŗ„Õ¤Ī„Ž„¹„ÆIĄķ
- 27. University of Tokyo 27/29 1 9 0 2 0 1 2 7 3 9 3 5 1 2 1 4 2 8 3 4 0 5 2 6 0 1 2 5 1 2 4 9 2 6 7 8 3 4 5 9 pair: „Ś„¢°¤ĖĮ¦ÓĖć sorted: Ļą»„×÷ÓĆĻąŹÖ¤Ē„½©`„Č next: ŹÖ¤Ē¶ž¶Ī„½„Õ„Č„¦„§„¢ „Ń„¤„ׄ鄤„Ė„ó„° intrin: ŹÖ¤ĒSIMD»Æ ÓĖćĢõ¼ž£ŗ ?ĆܶČ1.0 ?„«„Ć„Č„Ŗ„Õ3.0 ?Ģ½Ė÷¹ ģ3.3 ?12ĶņĮ£×Ó, 100»Ų¤ĪĮ¦ÓĖć¤Ė¤«¤«¤Ć¤ærég 86% 83% 70% 47% gŠŠ½Y¹ū „½©`„¹„Õ„”„¤„ė https://github.com/kaityo256/lj_simd
- 28. University of Tokyo 28/29 SIMD»ÆĒ° (33ŠŠ) SIMD»Æįį (98ŠŠ) „Ū„Ć„Č„¹„Ż„ƄȤĪ„Į„å©`„Ė„󄰤Ȥ·¤Ę¤ĻŌSČŻ¹ ģ???£æ gėH¤Ī„½©`„¹„³©`„É ŠŠŹż¤Ļ£³±¶¤Ė ¤³¤³¤ņ4±¶Õ¹é_
- 29. University of Tokyo 29/29 ¤Ž¤Č¤į¤ČøŠĻė ? AVXĆüĮī¤ņŹ¹¤Ć¤ĘLennard-JonesĻµ¤ĪĮ¦ÓĖć¤ņSIMD»Æ¤·¤æ ? „ģ„ø„¹„æ¤Č„į„ā„ź¤Īég¤Ī¤ä¤źČ”¤ź¤Ļøß„³„¹„Č ”””ś „ķ©`„É/„¹„Č„¢¤ņp¤é¤¹¤æ¤į”¢„Ē©`„æŌģ¤ņ¹¤·ņ ”””ś ¤Ź¤ė¤Ł¤Æ„ģ„ø„¹„æ¤ĒIĄķ¤ņ¤¹¤ė¤æ¤į”¢„·„ć„Ć„Õ„ėĆüĮī¤ņ»īÓĆ ? SIMD»Æo¤·¤Ī×īĖŁ„³©`„ɤĖ±Č¤Ł¤ĘĖŁ¶ČĻņÉĻ¤Ļ33% ¤Ž¤Č¤į øŠĻė ? ¤ä¤ķ¤¦¤ČĖ¼¤¤Į¢¤Ć¤Ę¤«¤é”¢SIMD»Æ¤¬Ķź³É¤¹¤ė¤Ž¤Ē1„öŌĀ¤Į¤ē¤Ć¤Č ? gP2ßLég³Ģ¶Č£æ ? ėy¤·¤Æ¤Ļ¤Ź¤¤¤¬O¤į¤ĘĆęµ¹¤Æ¤µ¤¤ ”””ś gėH¤ĖŌē¤Æ¤Ź¤ė¤«¤Ļ¤ä¤Ć¤Ę¤ß¤Ź¤¤¤Č¤ļ¤«¤é¤Ź¤¤ ? ”ø¾©”¹¤Ē¤Ļ128bit SIMD»Æ¤Ė¤č¤ź10?15%³Ģ¶Č¤ĪŠŌÄÜĻņÉĻ ? Intel Xeon¤Ē¤Ļ256bit SIMD»Æ¤Ė¤č¤ź 30?40%³Ģ¶Č¤ĪŠŌÄÜĻņÉĻ ? 512bit SIMD¤Ē¤Ļ¶ž±¶³Ģ¶Č¤Ļ²ī¤¬¤Ē¤ė¤Ī¤Ē¤Ļ¤Ź¤¤¤«£æ