Azure ’œ∫¶§»§Œ…œ ÷§ ∏∂§≠∫œ§§∑Ω
?
22 likes?7,279 views

2017/4/22 Japan Azure User Group (JAZUG) Global Azure Bootcamp 2017 @ Tokyo https://jazug.connpass.com/event/52917/











![Redis Cache
åùèͧ«§≠§Î§≥§»
°Ò ÷ÿ“™§ •«©`•ø§œ»Î§Ï§ §§
◊Óêô°¢Ôw§Û§«§‚§Ë§§“ôŒÚ§œ§∑§∆§™§Ø§Ÿ§∑
°Ò •≠•„•√•∑•Â§»§∑§∆§Œ π§§∑Ω
§ƒ§ §¨§È§ §§àˆ∫œ§œ··§Ì§Œ DB §À§»§Í§À––§Ø§ §…§Œòã≥…§Ú”√“‚
°Ò §¢§√§ø§fi§Î§fi§« 30 ∑÷§€§…
¬«∞§À◊˜§√§∆§™§Ø§ §…§‚øºë]§∑§ø§€§¶§¨§Ë§§](https://image.slidesharecdn.com/170422azure-170422035946/85/Azure-13-320.jpg)









Azure ’œ∫¶§»§Œ…œ ÷§ ∏∂§≠∫œ§§∑Ω
- 1. Azure ’œ∫¶§»§Œ…œ ÷§ ∏∂§≠∫œ§§∑Ω ÷ÒæÆ ”∆»À, »fß ∫Õæ√ bitFlyer, Inc. 2017/04/22 Global Azure Bootcamp 2017 @ Tokyo
- 3. C# (∏°ö›§‚§¢§Í§fi§∑§ø§¨) ¥Û∫√§≠ 8ƒÍ –¬ôCƒ‹È_∞k°¢•«©`•ø•Ÿ©`•π±O“ï•fi•Û SNS §œœ¢§∑§∆§fi§ª§Û BTC ÀÕΩ§™¥˝§¡§∑§∆§™§Í§fi§π ÷ÒæÆ ”∆»À »fß ∫Õæ√ C# ¥Û∫√§≠“ªΩÓ 15ƒÍ •ª•≠•Â•Í•∆•£—–æøÈ_∞k Facebook §œÔà•∆•Ì •¢•´•¶•Û•»
- 4. ΩÒ»’§Œ§¢§È§π§∏ °Ò §≥§Ï§fi§«§™∏∂§≠∫œ§§§∑§ø’œ∫¶ °Ò ≤øŒªÑe£° ’œ∫¶§Œ’{¿Ì§Œ À∑Ω °Ò §fi§»§·
- 5. §≥§Ï§fi§«§™∏∂§≠∫œ§§§∑§∆§≠§ø’œ∫¶ °Ò 2016/9/15, 20:48 JST »´ ¿ΩÁ§« DNS ’œ∫¶ °Ò 2017/3/8, 21:42 JST ñ|»’±æ§Œ•π•»•Ï©`•∏’œ∫¶ (Redis) °Ò 2017/3/28, 3:04 JST Œ˜»’±æ§Œ•π•»•Ï©`•∏’œ∫¶ (Redis) °Ò 2017/3/31, 22:28 JST ñ|»’±æ§Œ•π•»•Ï©`•∏’œ∫¶ (VM, DB°≠)
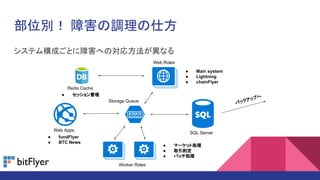
- 8. ≤øŒªÑe£° ’œ∫¶§Œ’{¿Ì§Œ À∑Ω •∑•π•∆•‡òã≥…§¥§»§À’œ∫¶§ÿ§ŒåùèÍ∑Ω∑®§¨Æê§ §Î Redis Cache °Ò Main system °Ò Lightning °Ò chainFlyer °Ò •fi©`•±•√•»ÑI¿Ì °Ò »°“˝ºs∂® °Ò •–•√•¡ÑI¿Ì Web Apps Worker Roles SQL Server Web Roles °Ò fundFlyer °Ò BTC News °Ò •ª•√•∑•Á•Ûπ‹¿Ì Storage Queue •–•√•Ø•¢•√•◊§ÿ
- 9. Storage (Blob, Queue, etc.) •Ï•◊•Í•±©`•∑•Á•Û§Œ∑NÓê °Ò Locally Redundant Storage (LRS) °Ò Zone Redundant Storage (ZRS) °Ò Geo-Redundant Storage (GRS) °Ò Read-Access Geo-Redundant Storage (RA-GRS)
- 10. Storage (Blob, Queue, etc.) åùèͧ«§≠§Î§≥§» °Ò •∏•™»flÈL§Ú§¶§fi§Ø 𧧧fi§∑§Á§¶ ° ( §«§‚ GRS §œåg§œ∞kÑ”§∑§ø§≥§»§œ§ §§§È§∑§§ ) °Ò Õ¨§∏•¢•ª•√•»§ÚÑe§Œ•π•»•Ï©`•∏§À•«•◊•Ì•§§∑§∆§™§Ø ° √Êµπ§¿§´§È•«•◊•Ì•§◊‘Ñ”ªØ§∑§fi§∑§Á§¶§Õ ° Ω”æAŒƒ◊÷¡–§ÚÑ”µƒ§À≧®§È§Ï§Îƒ⁄≤ø§Œ ÀΩM§fl§Ú °Ò CDN §Ú π§√§∆•®•√•∏ •µ©`•–§ÀÕÀ±‹§µ§ª§Î§Œ§‚ ÷
- 11. Cloud Service •–•√•Ø•®•Û•…§œ∆’Õ®§Œ VM°£•π•»•Ï©`•∏§¨µπ§Ï§Î§»À¿§Ã§´§‚ åùèͧ«§≠§Î§≥§» °Ò Ñe•Í©`•∏•Á•Û§À•«•◊•Ì•§§∑÷±§π§∑§´§ §§ •«•◊•Ì•§§À 5 ∑÷§»§´°¢ªÏÎjïr§œ§‚§√§»§´§´§Î§≥§»§Úøó§Ífiz§‡§≥§» °Ò DNS §Œ‘O∂®â‰∏¸§ÚÕ¸§Ï§ §Ø ±ÿ“™§ §»§≥§Ì§œ TTL §Ú∂çا∑§∆§™§Ø§ §…§Œåùèͧ‚§¢§Í
- 12. Azure DNS / §Ω§ŒÀ˚ DNS §¨§È§fl Ω”æA§Ú«–§È§ §§œfi§Í§œÀ¿§ § §§§´§‚£®§¿§¨¥_‘^§œ§ §§£© åùèͧ«§≠§Î§≥§» °Ò DNS ◊‘猻flÈLœµΩy§Ú”√“‚§∑§∆§™§Ø§∑§´§ §§ °Ò Traffic Manager §ÚΩM§fl∫œ§Ô§ª§Î§‚§Ë§∑
- 13. Redis Cache åùèͧ«§≠§Î§≥§» °Ò ÷ÿ“™§ •«©`•ø§œ»Î§Ï§ §§ ◊Óêô°¢Ôw§Û§«§‚§Ë§§“ôŒÚ§œ§∑§∆§™§Ø§Ÿ§∑ °Ò •≠•„•√•∑•Â§»§∑§∆§Œ π§§∑Ω §ƒ§ §¨§È§ §§àˆ∫œ§œ··§Ì§Œ DB §À§»§Í§À––§Ø§ §…§Œòã≥…§Ú”√“‚ °Ò §¢§√§ø§fi§Î§fi§« 30 ∑÷§€§… ¬«∞§À◊˜§√§∆§™§Ø§ §…§‚øºë]§∑§ø§€§¶§¨§Ë§§
- 14. SQL Database åùèͧ«§≠§Î§≥§» °Ò Ω”æAŒƒ◊÷¡–§Ú≧®§È§Ï§Î§Ë§¶§À§π§Î °Ò •–•√•Ø•¢•√•◊§Ú§»§Î °Ò geo •Ï•◊•Í•±©`•∑•Á•Û§ÚΩM§‡
- 15. Geo •Ï•◊•Í•±©`•∑•Á•Û§Ú 𧶧»§≠§Œ◊¢“‚ 1. •π•±©`•Î•¢•√•◊§∑§∆§´§È Failover 2. §»§Í§¢§®§∫ Failover §∑§∆§´§È•π•±©`•Î•¢•√•◊ §…§¡§È§Úflxík§∑§fi§π§´£ø °∏§»§Í§¢§®§∫ Failover §∑§∆§´§È•π•±©`•Î•¢•√•◊°π§¨’˝Ω‚ geo •Ï•◊•Í•±©`•∑•Á•Û§Œ§§§∫§Ï§´§À”∞Ì맨§¢§Î§» À˚∑Ω§‚”∞Ìë§Ú ‹§±§Îø…ƒ‹–‘§¨¡„§«§œ§ §§
- 16. SQL Database §Œ•≥•‘©`§À§ƒ§§§∆—a◊„ °Ò 1 §ƒ§Œ DB §´§ÈÕ¨ïr•≥•‘©`§∑§∆§œ§§§±§ §§£° °Ò •≥•‘©`§Ë§Í geo •Í•π•»•¢Õ∆äX ∫Œ§È§´§Œ¿Ì”…§« Failover ≥ˆ¿¥§ §§àˆ∫œ§‚ geo •Í•π•»•¢ °Ò ÑI¿ÌïrÈg§œ»›¡ø§»•µ©`•”•π •Ï•Ÿ•Î§À”∞Ì맶§±§Î •«©`•ø¡ø§¨∂‡§±§Ï§–ïrÈg§¨§´§´§Î §¢§Ô§ª§∆°¢òã∫B§π§Î•µ©`•”•π•Ï•Ÿ•Î§Œ•µ•§•∫§Àèͧ∏§∆•≥•‘©`ÀŸ∂»§¨â‰§Ô§Î ΩÒªÿ§œ... (3/31) Õ¨“ª•µ©`•–©`ƒ⁄6ïrÈg38∑÷°¢œ„∏€•µ©`•–©`8ïrÈg1∑÷§´§´§√§ø§¨°¢ •≥•‘©`‘™ DB §« reconfiguration §¨∞k…˙§∑°¢ƒ⁄≤øµƒ§À§‰§Í÷±§∑§∑§∆§§§ø
- 17. •fi•Î•¡ •Í©`•∏•Á•Û§À§ƒ§§§∆ §…§≥§À•–•√•Ø•¢•√•◊§Ú¡¢§∆§fi§π§´£ø Ω¸§§§»§≥§Ì£ø •⁄•¢•Í©`•∏•Á•Û§Ú 𧧧fi§∑§Á§¶ °Ò §…§¡§È§´ 1 §ƒ§Œ•Í©`•∏•Á•Û§œ º⁄Ñ”§π§Î§Ë§¶’{’˚§µ§Ï§∆§§§Î °Ò »’±æ§œñ|§»Œ˜§¨•⁄•¢•Í©`•∏•Á•Û (DB §Œòã≥…â‰∏¸§¨◊fl§√§ø§Í§π§Î§Œ§«”Õ∂œΩ˚ŒÔ )
- 18. §Ω§ŒÀ˚§Œ§œ§ §∑
- 19. SLA °Ò ±£‘^§µ§Ï§øº⁄ÉP¬ §À◊¢“‚°£99.9 % § §Œ§´£ø 99.99 % § §Œ§´£ø ° Storage : 99.9 % (RA-GRS §Œàˆ∫œ§œ’i§fl»°§Í 99.99%) ° VM / Cloud Service : 99.95 % ° SQL Database / DNS : 99.99 % °Ò ’˝§∑§§»flÈLòã≥…§«§ §±§Ï§–°¢ø…”√–‘§¨µ£±£§∑§∆§‚§È§®§ §§ ° VM §œø…”√–‘•ª•√•»ΩM§Û§«§fi§π§´ ≤Œøº: •®•Û•ø©`•◊•È•§•∫∆ıºs£®EA£©§Œ SLA ∑µΩ ÷æA§≠§À§ƒ§§§∆ https://blogs.msdn.microsoft.com/dsazurejp/2016/12/12/easla/
- 20. •§•Û•∑•«•Û•»§Œ…œ§≤∑Ω Azure •›©`•ø•Î •ÿ•Î•◊§»•µ•›©`•» §´§È…œ§≤§Î °Ò ª˘±æ ÜñÓ}§Œ∑NÓê°¢•µ•÷•π•Ø•Í•◊•∑•Á•Û°¢•µ©`•”•π •Í•Ω©`•π°¢ •µ•›©`•»•◊•È•Û °Ò ÜñÓ} ÷ÿ“™∂»°¢ÜñÓ}§Œ∑NÓê°¢•´•∆•¥•Í°¢‘îºö°¢ (ÜñÓ}∞k…˙»’)°¢(ÃÌ∏∂•’•°•§•Î) °Ò flBΩjœ»«ÈàÛ §¥œ£Õ˚§ŒflBΩj∑Ω∑®°¢√˚°¢–‘°¢•·©`•Î°¢Îä‘í∑¨∫≈ §Ú»Î§Ï§Ï§–OK! °¢°¢°¢§¶§Û°¢√Êµπ°£ À∑Ω§ §§§±§…°£
- 21. •§•Û•∑•«•Û•»§Œ…œ§≤∑Ω Œ“°©§À§«§≠§Î§≥§» °Ò ¨F‘⁄§Œòã≥…§»°¢Ñ”§§§∆§§§ §§§»§≥§Ì§Ú√˜¥_§À’h√˜§∑§∆“¿Óm§π§Î °Ò ∆⁄¥˝§∑§π§Æ§ §§°£§ §Û§«§‚§´§Û§«§‚åùèͧ∑§∆§Ø§Ï§Î§Ô§±§«§œ§ §§ æoº±∂» A §¿§´§È§»§§§√§∆•π©`•—©` •®•Û•∏•À•¢§¨åùèͧ∑§∆§Ø§Ï§Î§Ô§±§«§œ§ §§ MS §ÿ§Œ“™Õ˚ °Ò •§•Û•∑•«•Û•»…œ§≤§Î§Œ√ʵπ§π§Æ °Ò Ãÿ§À æoº±∂» A §Œàˆ∫œ§œ§ƒ§È§π§Æ °Ò ¥Û“郣’œ∫¶ïr§œ•µ•›©`•»ÃÂ÷∆§‚§√§»ü·§Ø§∑§∆§€§∑§§ (§∑§∆§§§Î§Œ§´§‚§∑§Ï§ §§§¨∏–§∏§È§Ï§ §§...)
- 22. §fi§»§·
- 23. §fi§»§· °Ò §≥§Ï§fi§«§Œ’œ∫¶§ŒΩBΩÈ ° °Æ16/9/15 DNS ’œ∫¶ (»´ ¿ΩÁ) ° °Æ17/3/8 •π•»•Ï©`•∏’œ∫¶ (ñ|»’±æ) ° °Æ17/3/31 •π•»•Ï©`•∏’œ∫¶ (ñ|»’±æ, Œ˜»’±æ) °Ò •∑•π•∆•‡òã≥…≤ø∑÷§¥§»§Œ’œ∫¶åù≤fl ° Storage / Redis °≠ »flÈLòã≥… / Ω”æAŒƒ◊÷¡–â‰∏¸§Œ ÀΩM§fl”√“‚ ° Cloud Service / VM °≠ •«•◊•Ì•§§∑÷±§∑§¨ª˘±æ / Managed Disk Å„”√ ° Database °≠ »flÈLòã≥… / •π•±©`•Î§À◊¢“‚ °Ò §Ω§ŒÀ˚ ° •⁄•¢ •Í©`•∏•Á•Û§À§ƒ§§§∆ ° SLA / •§•Û•∑•«•Û•»ïr§ŒÜñ§§∫œ§Ô§ª ÷Ìò