Azure Data Explorer
?
3 likes?2,147 views

§»§¶§»§¶GA§∑§ø•§•¡•™•∑§Œ◊Óèä◊ÓÀŸ•«©`•ø∑÷Œˆª˘±P Azure Data Explorer §Ú§ƒ§´§√§∆•≤©`•‡§ŒBig Data ∑÷Œˆ§Ú§∑§Ë§¶












Azure Data Explorer
- 1. §»§¶§»§¶GA§∑§ø•§•¡•™•∑§Œ◊Óèä◊ÓÀŸ•«©`•ø∑÷Œˆª˘±P Azure Data Explorer §Ú§ƒ§´§√§∆•≤©`•‡§ŒBig Data ∑÷Œˆ§Ú§∑§Ë§¶ âàúm?›o •≤©`•‡•µ©`•–©`µ£µ± •∆•Ø•À•´•Î•Ω•Í•Â©`•∑•Á•Û•◊•Ì•’•ß•√•∑•Á• •Î Global Black Belt Asia Microsoft
- 2. Azure Data Explorer £®ADX£©§»§œ£ø •”•√•Ø•«©`•ø∑÷Œˆ•µ©`•”•π°£2019ƒÍ§ÀGA°£ TB, PBºâ§Œ?¡ø§Œ•«©`•øó À˜§Ú£±√ΰ¢ ˝√Γ‘ƒ⁄§«èÍ¥°£ •π•»•Í©`•fl•Û•∞§»•–•√•¡§À§Ë§Î•§•Û•∏•ß•Ø•∑•Á•Û§ÀåùèÍ •Í•¢•Î•ø•§•‡§ ≥¨?ÀŸ∑÷Œˆ§Úø…ƒ‹§À§∑§fi§π°£ ?Æb–‘ 10 É|º˛§Œ•Ï•≥©`•…§Ú 1 √ÎŒ¥ú∫§«’’ª·§«§≠§Î íàèà–‘ –‘ƒ‹§¨±ÿ“™§ ïr§À°¢æÄ–Œ•π•±©`•Í•Û•∞§¨ø…ƒ‹ ?§§◊˜òIÑø¬ ◊Ó–¬§Œ•Ø•®•Í?’Z?KQL°¢ 𧧧‰§π§§•∑•Û•ø•√•Ø•π°¢ •§•Û•∆•Í•ª•Û•πôCƒ‹°£ •¢•Œ•fi•Í©`•«•£•∆•Ø•∑•Á•Û§‰ªÿ颧 §…§ŒÿN∏ª§ •È•§•÷•È•Í§¨ §¢§Í§fi§π »·‹õ–‘ òî°©§ °¢•«©`•ø§ŒΩ”æA°¢òî°©§ BI≠hæ≥§»§ŒflB–Ø
- 3. “‘«∞§´§È…Áƒ⁄§« π§Ô§Ï§∆§§§ø£®∫ŒÑI§´§«¬Ñ§§§ø‘í§«§π§¨£© 2016 20182014 AI & ILDC C&E Incubation Friends & Family Exposure 1st Big internal Clint ScottGu Chooses Kusto for C&E Delivering Across Multiple MS Divisions Fund By Brian H POC With Azure SQL DB Growing Customers Base Establishment Telemetry Analytics Internal Analytics Data platform for products Analyticsfor3rdparty Offerunifiedplatform acrossOMS/AI Interactive analytics Big data platform 200customers InitiatingWith1st PartyValidation DevelopingModernAnalytics 2015 IDEATION & CONCEPT VALIDATION SCALE PUBLIC REVIEW Resource Commitment GA 20192017 Foundation Team & Initiate Coding Bing Inferences MS Expansion Success GA SCALE Ideation
- 4. •fi•§•Ø•Ì•Ω•’•»…Áƒ⁄§«§ §ºADX§¨±ÿ“™§»§µ§Ï§∆§≠§ø§Œ§´£ø Cuts down time-to- insight fast-flowing data §Àåù§π§Î §€§‹•Í•¢•Î•ø•§•‡§ ∑÷Œˆ §Úø…ƒ‹§À§∑§fi§π Enables data-driven culture Intuitive §«∫ÜÖg§À π§®§Î •«©`•ø∑÷Œˆ§À◊ÓflmªØ§µ§Ï§ø ◊Ó–¬§Œ•Ø•®•Í©`—‘’ZKQL Fully managed •§•Û•«•√•Ø•π§Œfl\”√§ÚôC§À §π§Î±ÿ“™§¨§¢§Í§fi§ª§Û •§•Û•’•È§‚•™©`•»•π•±©`•Î ø…ƒ‹§«§π Azure £∫»’°©¥Û¡ø§À∞k…˙§π§Î•Ì•∞•«©`•ø§Àåù§π§Î•«©`•øΩ‚Œˆ◊˜òIÑø¬ §Ú…œ§≤§Î±ÿ“™§¨§¢§√§ø Xbox £∫∂‡§Ø§Œ•«©`•ø•µ•§•®•Û•∆•£•π•»§œ°¢SQL§À¥˙§Ô§Î 𧧧‰§π§§•Ø•®•Í©`—‘’Z§Ú±ÿ“™§»§∑§∆§§§ø Office365 £∫•Ω•’•»§´§È•µ©`•”•π§À“∆––§π§ÎÓôøÕ§Œ≤ªú∫§Ú∞—Œ’§∑°¢∏ƒ…∆§À•’•£©`•…•–•√•Ø§π§Î±ÿ“™§¨§¢§√§ø Defender £∫êô“‚§Œ§¢§Îπ•ìƒ’fl§Ú“䧃§±§Î§ø§·ïrœµ¡–•«©`•ø§Àåù§π§ÎôC–µ—ß¡ï∑÷Œˆ§ŒÑø¬ §Ú…œ§≤§Î±ÿ“™§¨§¢§√§ø Azure ÓôøÕ£∫Azure…œ§Œ•¢•◊•Í§‰•∑•π•∆•‡•Ì•∞§Ú•›©`•ø•Î…œ§«Ωy∫œµƒ§À•Í•¢•Î•ø•§•‡§«ø…“ïªØ§π§Î±ÿ“™§¨§¢§√§ø Azure Data Explorer §¨÷ÿ“™“ï§∑§∆§§§ÎÃÿè’
- 5. À˚§Œ•«©`•ø•Ÿ©`•π§»§Œ π§§∑÷§± •≤©`•‡ •µ©`•–©` OLTP DB £®RDB/Doc£© Lightning Fast & Complex Analytics Explorer ÃΩñÀ◊˜òI •”•√•Ø•«©`•ø§Œïr¥˙§À÷ÿ“™§»§ §Î°∏ÃΩñÀ◊˜òI°π§Ú––§¶
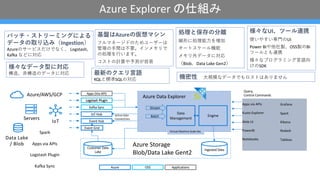
- 7. Azure Explorer §Œ ÀΩM§fl Data Lake / Blob IoT Ingested Data Engine Data Management Azure Data Explorer Azure Storage Blob/Data Lake Gent2 Event Hub IoT Hub Customer Data Lake Kafka Sync Logstash Plugin Event Grid Logstash Plugin Apps (Via API) Stream Batch Query, Control Commands Azure OSS Applications Active Data Connections Virtual Machine Scale Set •–•√•¡?•π•»•Í©`•fl•Û•∞§À§Ë§Î •«©`•ø§Œ»°§Ífiz§fl£®Ingestion£© Azure§Œ•µ©`•”•π§¿§±§«§ §Ø°¢ Logstash, Kafka § §…§ÀåùèÍ ª˘±P§œAzure§ŒÅ¢œÎ•fi•∑•Û •’•Î•fi•Õ©`•∏•…§Œ§ø§·•Ê©`•∂©`§œ π‹¿Ì§Œ?Èg§œ≤ª“™°£•§•Û•·•‚•Í§« §ŒÑI¿Ì§Ú?§§§fi§π°£ •≥•π•»§Œ”ãÀ„§‰”Ëúy§¨»›“◊ òî°©§ •«©`•ø–Õ§ÀåùèÍ òã‘Ï°¢?òã‘ϧŒ•«©`•ø§ÀåùèÍ òî°©§ UI°¢•ƒ©`•ÎflB–Ø π§§§‰§π§§åü?§ŒUI Power BI§‰À˚…Á—u°¢OSS—u§ŒBI •ƒ©`•Î§»§‚flB–Ø òî°©§ •◊•Ì•∞•È•fl•Û•∞?’ZœÚ §±§ŒSDK ÑI¿Ì§»±£¥Ê§Œ∑÷Îx æÄ–Œ§ÀÑI¿Ìƒ‹?§Úâດ •™©`•»•π•±©`•ÎôCƒ‹ •·•‚•ÍÕ‚•«©`•ø§ÀåùèÍ £®Blob°¢Data Lake Gen2£© ◊Ó–¬§Œ•Ø•®•Í?’Z KQL§»òÀú SQL§ŒåùèÍ ôC√‹–‘ ?“郣§ •«©`•ø§«§‚•Ì•π•»§œ§¢§Í§fi§ª§Û
- 8. •≥•π•»∏–§œ???£ø£ø Cost Estimator: http://aka.ms/ADX.CostEstimator Pricing Page: https://azure.microsoft.com/ja-jp/pricing/details/data-explorer/ Å˝∏Ò§ŒÃÿè’ Azure Data Explorer§Œ•Ø•È•π•ø©`§œ°¢Azure Linux VM §»•π•»•Ï©`•∏§ §…°¢—} ˝§Œ Azure •Í•Ω©` •π§Ú π?§π§Î•®•Û•∏•Û •Ø•È•π•ø©`§»•«©`•øπ‹¿Ì•Ø•È•π•ø©`§Œ•⁄•¢§«§π°£flm?ø…ƒ‹§ VM°¢Azure Storage°¢Azure •Õ•√•»•Ô©`•Ø°¢Azure •Ì©`•… •–•È•Û•µ©`§Œ•≥•π•»§œ°¢ÓôøÕ§Œ•µ•÷•π•Ø•Í•◊•∑•Á•Û §À÷±Ω”’à«Û§µ§Ï§fi§π°£ §ƒ§fi§Í°¢Å¢œÎ•fi•∑•Û§¨?§¡…œ§¨§Í§fi§π°£ •»•È•Û•∂•Ø•∑•Á•Û•Ÿ©`•π§Œ∑÷Œˆ•µ©`•”•π§«§œ§ §Ø°¢Å¢œÎ•fi•∑•Û£®•≥•¢?•·•‚•Í£©§Œ’n?§«§π •Ø•È•π•ø©`§Œ÷–§À§œ—} ˝§Œ•«©`•ø•Ÿ©`•π§Ú◊˜≥…§π§Î§≥§»§¨§«§≠§fi§π°££®—} ˝§Œ•≤©`•‡•ø•§•»•Î§«fl\ Ü”§π§Î§≥§»§¨§«§≠§fi§π£© •·•Í•√•»? •Ø•®•Í§Œï¯§≠?§‰•«©`•ø•µ•§•∫§À“¿¥Ê§∑§ §§§ø§·•≥•π•»§Ú’i§fl§‰§π§§ •«•£•·•Í•√•»? •Ì•∞§Œ•µ•§•∫§¨?§≠§Ø§ §§àˆ∫œ§œÅ¢œÎ•fi•∑•Û§Œ•≥•π•»§¨÷ÿ∫…§»§ §Î °∏•”•√•Ø•«©`•ø°π§¨∞k?§π§Î•≤©`•‡•ø•§•»•Î§«§œ°¢•≥•π•»œ˜úp§À?§√§øågøɧ¨§¢§Í§fi§π ?“郣§ •ø•§•»•Î§«§œƒÊ§À∏Ó?§À§ §Îø…ƒ‹–‘§¨§¢§Î§Œ§«“‘œ¬§Œ•µ•§•»§«§¥¥_’J§∑§∆§Ø§¿§µ§§°£
- 9. •Ø•È•§•¢•Û•»•ƒ©`•Î ? Windows •Ø•È•§•¢•Û•»§Œ°∏Kusto Explorer°π°¢Web UI§Œ°∏Azure Data Explorer °π°¢Azure Portal°¢ Client SDK£®C#°¢Python°¢PHP°¢Java§ §…£©°¢§ §…òî°©§ •¢•Ø•ª•π?∑®§¨§¢§Í§fi§π°£ Web UI§Œ°∏Azure Data Explorer °π https://dataexplorer.azure.com Windows •Ø•È•§•¢•Û•»§Œ°∏Kusto Explorer°π
- 10. KQL : Kusto Query Language ? •Ø•®•Í?’ZKQL§À§Ë§Í°∏ÃΩñÀ°π§Œ◊˜òIÑø¬ §¨…œ§¨§Í§fi§π°£ ? ª˘±æµƒ§ ﯧ≠?§œ°¢•∆©`•÷•Î√˚§Ú∆µ„§À•’•£•Î•øÃıº˛§‰ÑI¿Ì§Ú•—•§•◊°∏|°π§«”õ ˆ ? ôC–µ—ߡ柳°¢•∞•È•’√˪≠§ §…§‚?§§§fi§π°£•…•Í•Î•¿•¶•Û§«‘îºö«ÈàÛ§Ú¥_’J§π§Î§≥§»§‚ø…ƒ‹ •∑•Û•◊•Î§´§ƒ•—•Ô•’•Î§ òã? ? •È•∑•Á• •Î•Ø•®•Í©` (filter, aggregate, join, calculated columns, and more) ? ±„¿˚§ •”•Î•»•§•ÛôCƒ‹ full-text search, time series, user analytics, machine learning operators ? Visualization (•Ø•®•Í©`§´§È•∞•È•’±Ì?) ? ∫ÜÖg§ •∑•Û•ø•√•Ø•π£´•§•Û•∆•Í•ª•Û•π ? ø…’i–‘§Œ?§§ •“•®•È•Î•≠©`òã‘ϧŒ•π•≠©`•fi«ÈàÛ Comprehensive ? òã‘Ï•«©`•ø°¢?òã‘Ï•«©`•ø°¢∞Îòã‘Ï•«©`•ø§À§fi§ø §¨§√§ø•Ø•®•Í©`åg? íàèàôCƒ‹ ? In-line Python ? SQL
- 11. § §º?ÀŸ•Ø•®•Í©`§Úåg¨F§«§≠§Î§Œ§´£ø § §º•«©`•ø§ÿ§Œ•¢•Ø•ª•π§¨∫ÜÖg§À§ §Î§Œ§´£ø https://kusto.azurewebsites.net/docs/api/index.html KQL : Kusto Query Language
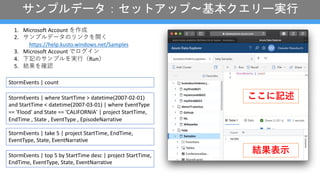
- 12. 1. Microsoft Account §Ú◊˜≥… 2. •µ•Û•◊•Î•«©`•ø§Œ•Í•Û•Ø§ÚÈ_§Ø https://help.kusto.windows.net/Samples 3. Microsoft Account §«•Ì•∞•§•Û 4. œ¬”õ§Œ•µ•Û•◊•Î§Úåg?£®Run£© 5. ΩYπ˚§Ú¥_’J StormEvents | where StartTime > datetime(2007-02-01) and StartTime < datetime(2007-03-01) | where EventType == 'Flood' and State == 'CALIFORNIA' | project StartTime, EndTime , State , EventType , EpisodeNarrative StormEvents | count StormEvents | take 5 | project StartTime, EndTime, EventType, State, EventNarrative StormEvents | top 5 by StartTime desc | project StartTime, EndTime, EventType, State, EventNarrative §≥§≥§À”õ ˆ ΩYπ˚±Ì? •µ•Û•◊•Î•«©`•ø£∫•ª•√•»•¢•√•◊?ª˘±æ•Ø•®•Í©`åg––
- 13. StormEvents | summarize event_count=count() by bin(StartTime, 1d) | render timechart StormEvents | summarize event_count=count(), mid = avg(BeginLat) by State | sort by mid | where event_count > 1800 | project State, event_count | render columnchart •µ•Û•◊•Î•«©`•ø£∫•ª•√•»•¢•√•◊?áÌ–Œ√˪≠
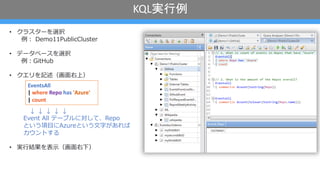
- 14. KQLåg––¿˝ ? •Ø•È•π•ø©`§Úflxík ¿˝? Demo11PublicCluster ? •«©`•ø•Ÿ©`•π§Úflxík ¿˝?GitHub ? •Ø•®•Í§Ú”õ ˆ£®ª≠?”“…œ£© °˝ °˝ °˝ °˝ °˝ Event All •∆©`•÷•Î§Àåù§∑§∆°¢Repo §»§§§¶Ìó?§ÀAzure§»§§§¶?◊÷§¨§¢§Ï§– •´•¶•Û•»§π§Î ? åg?ΩYπ˚§Ú±Ì?£®ª≠?”“œ¬£© EventsAll | where Repo has 'Azure' | count
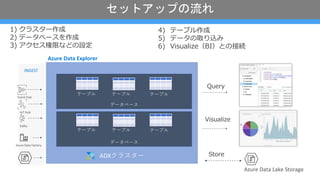
- 15. •ª•√•»•¢•√•◊§Œ¡˜§Ï 1) •Ø•È•π•ø©`◊˜≥… 2) •«©`•ø•Ÿ©`•π§Ú◊˜≥… 3) •¢•Ø•ª•πòÿœfi§ §…§Œ‘O∂® ADX•Ø•È•π•ø©` INGEST Azure Data Factory Kafka IoT Hub Event Hub Azure Data Lake Storage Query Visualize •«©`•ø•Ÿ©`•π Azure Data Explorer •«©`•ø•Ÿ©`•π •∆©`•÷•Î •∆©`•÷•Î •∆©`•÷•Î •∆©`•÷•Î •∆©`•÷•Î •∆©`•÷•Î Store 4) •∆©`•÷•Î◊˜≥… 5) •«©`•ø§Œ»°§Ífiz§fl 6) Visualize£®BI£©§»§ŒΩ”æA
- 16. ? Microsoft Corporation Next steps —u∆∑π´ Ω•µ•§•» π´ Ω•…•≠•Â•·•Û•» ïrœµ¡–∑÷Œˆ°¢MS§Œ•µ•Û•◊•Î •È•§•»•§•Û•∏•ß•π•» Grafana§»§ŒΩy∫œ KQL magic §À§Ë§ÎPython§»§ŒΩy∫œ Logstash§´§È§Œ•«©`•ø»°§Ífiz§fl ?π´ ΩBlog…œ§Œ•µ•Û•◊•Î•Ø•®•Í Ñ”ª≠§À§Ë§ÎKQLüo¡œ—––fi£®”¢’Z£© White Paper