Big data ppt
173 likes75,300 views

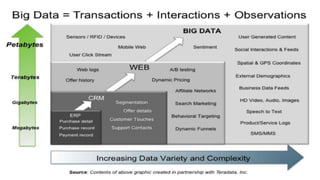
Big data refers to the massive amounts of unstructured data that are growing exponentially. Hadoop is an open-source framework that allows processing and storing large data sets across clusters of commodity hardware. It provides reliability and scalability through its distributed file system HDFS and MapReduce programming model. The Hadoop ecosystem includes components like Hive, Pig, HBase, Flume, Oozie, and Mahout that provide SQL-like queries, data flows, NoSQL capabilities, data ingestion, workflows, and machine learning. Microsoft integrates Hadoop with its BI and analytics tools to enable insights from diverse data sources.


















































More Related Content
What's hot (20)
Viewers also liked (11)









Similar to Big data ppt (20)




















Big data ppt
- 1. Introduction to BIG DATA Thiru
- 2. What is BIG DATA? http://www.forbes.com/sites/oreillymedia/2012/01/19/volume-velocity- variety-what-you-need-to-know-about-big-data
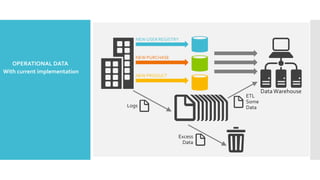
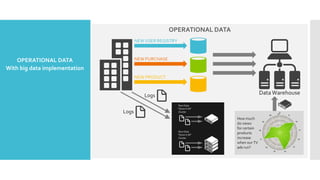
- 4. ď‚– Search Engine Data Scalability ď‚– 10KB / doc * 20B docs = 200TB Problems ď‚– Reindex every 30 days: 200TB/30days = 6 TB/day ď‚– Log Processing / Data Warehousing ď‚– 0.5KB/events * 3B pageview events/day = 1.5TB/day ď‚– 100M users * 5 events * 100 feed/event * 0.1KB/feed = 5TB/day ď‚– Multipliers: 3 copies of data, 3-10 passes of raw data ď‚– Processing Speed (Single Machine) ď‚– 2-20MB/second * 100K seconds/day = 0.2-2 TB/day
- 5. What’s the social sentiment How do I better predict future for my brand or products outcomes? How do I optimize my fleet based on weather and traffic patterns?
- 6. Traditional E-Commerce Data Flow
- 7. New E-Commerce Big Data Flow
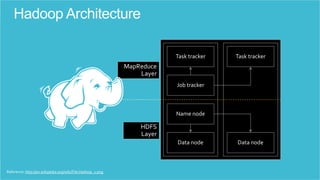
- 9. Hadoop is a framework for running applications on large clusters built of commodity hardware. The Hadoop framework transparently provides applications both reliability and data motion. Hadoop implements a computational paradigm named Map/Reduce, where the application is divided into many small fragments of work, each of which may HADOOP be executed or reexecuted on any node in the cluster. In addition, it provides a distributed file system (HDFS) that stores data on the compute nodes, providing very high aggregate bandwidth across the cluster. Both Map/Reduce and the distributed file system are designed so that node failures are automatically handled by the framework.
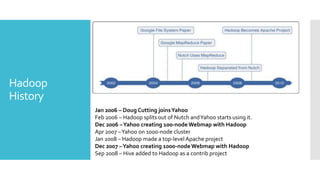
- 10. Hadoop History Jan 2006 – Doug Cutting joins Yahoo Feb 2006 – Hadoop splits out of Nutch and Yahoo starts using it. Dec 2006 –Yahoo creating 100-node Webmap with Hadoop Apr 2007 –Yahoo on 1000-node cluster Jan 2008 – Hadoop made a top-level Apache project Dec 2007 –Yahoo creating 1000-node Webmap with Hadoop Sep 2008 – Hive added to Hadoop as a contrib project
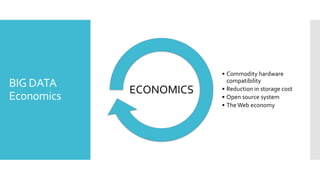
- 11. • Commodity hardware BIG DATA compatibility ECONOMICS • Reduction in storage cost Economics • Open source system • The Web economy
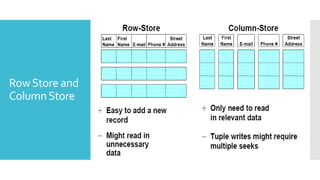
- 13. Row Store and Column Store
- 14. ď‚– Can be significantly faster than row stores for some applications ď‚– Fetch only required columns for a query ď‚– Better cache effects ď‚– Better compression (similar attribute values within a column) Why Column ď‚– But can be slower for other applications ď‚– OLTP with many row inserts, .. Store? ď‚– Long war between the column store and row store camps :-)
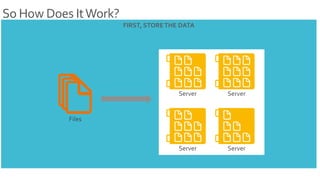
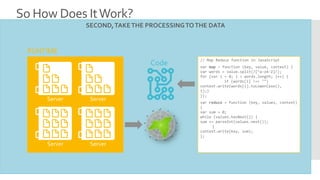
- 15. So How Does It Work?
- 16. So How Does It Work?
- 20. Traditional RDBMS vs. MapReduce Comparisons
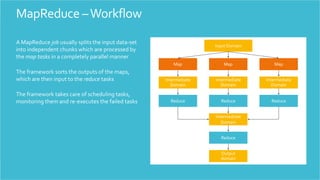
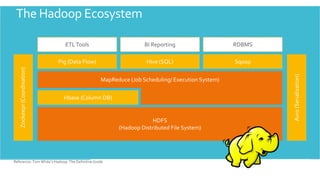
- 21. HDFS, the storage layer of Hadoop, is a distributed, scalable, Java-based file system adept at storing large volumes of unstructured data. MapReduce is a software framework that serves as the compute layer of Hadoop. MapReduce jobs are divided into two (obviously named) parts. The “Map” function divides a query into multiple parts and processes data at the node level. The “Reduce” function aggregates the results of the “Map” function Hadoop to determine the “answer” to the query. Ecosystem Hive is a Hadoop-based data warehouse developed by Facebook. It allows users to write queries in SQL, which are then converted to MapReduce. This allows SQL programmers with no MapReduce experience to use the warehouse and makes it easier to integrate with business intelligence and visualization tools such as Microstrategy, Tableau, Revolutions Analytics, etc. Pig Latin is a Hadoop-based language developed by Yahoo. It is relatively easy to learn and is adept at very deep, very long data pipelines (a limitation of SQL.)
- 22. HBase is a non-relational database that allows for low-latency, quick lookups in Hadoop. It adds transactional capabilities to Hadoop, allowing users to conduct updates, inserts and deletes. EBay and Facebook use HBase heavily. . Flume is a framework for populating Hadoop with data. Agents are populated throughout ones IT infrastructure – inside web servers, application servers and mobile devices, for example – to collect data and integrate it into Hadoop. Hadoop Ecosystem Oozie is a workflow processing system that lets users define a series of jobs written in multiple languages – such as Map Reduce, Pig and Hive -- then intelligently link them to one another. Oozie allows users to specify, for example, that a particular query is only to be initiated after specified previous jobs on which it relies for data are completed Whirr is a set of libraries that allows users to easily spin-up Hadoop clusters on top of Amazon EC2, Rackspace or any virtual infrastructure. It supports all major virtualized infrastructure vendors on the market.
- 23. Avro is a data serialization system that allows for encoding the schema of Hadoop files. It is adept at parsing data and performing removed procedure calls Mahout is a data mining library. It takes the most popular data mining algorithms for performing clustering, regression testing and statistical modeling and implements them using the Map Reduce model Hadoop Ecosystem Sqoop is a connectivity tool for moving data from non-Hadoop data stores – such as relational databases and data warehouses – into Hadoop. It allows users to specify the target location inside of Hadoop and instruct Sqoop to move data from Oracle, Teradata or other relational databases to the target. BigTop is an effort to create a more formal process or framework for packaging and interoperability testing of Hadoop's sub-projects and related components with the goal improving the Hadoop platform as a whole.
- 25. Insights to all users by activating new types of data
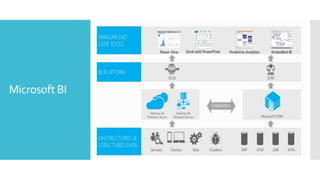
- 26. Microsoft BI
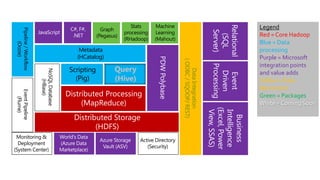
- 27. Stats Machine Legend Graph Pipeline / Workflow processing Learning (Pegasus) Red = Core Hadoop (RHadoop) (Mahout) Blue = Data (Oozie) Metadata processing (HCatalog) Purple = Microsoft ( ODBC / SQOOP/ REST) integration points Scripting Query Data Integration NoSQL Database and value adds (Pig) (Hive) Yellow = Data Microsoft (HBase) Movement Distributed Processing Event Pipeline Hadoop Stack (MapReduce) Green = Packages (Flume) White = Coming Soon Distributed Storage (HDFS) Monitoring & Active Directory Deployment (Security) (System Center)
- 28. Others
- 33. Thank You
Editor's Notes
- #18: ,