ندوشنô£هإ╕هإء Big Data Recommendation Products - هû┤هب£هإء ن░هإ┤و░نح╝ و╡وـ┤ نé┤هإ╝هإ هءêه╕ةوـ£نïج

DEVIEW 2013 ن░£وّ£ نé┤هأرهئàنïêنïج - http://deview.kr/2013/detail.nhn?topicSeq=36 ندوشنô£هإ╕ و¤îنئسو╝ هâهإء نïجهûّوـ£ Recommendation Productنôج, هإ┤ هب£وْêنôجهإء وéجهؤîنô£نè¤ ن░¤نة£ 'Relevance(هù░م┤ه▒)' هئàنïêنïج. م░هئح م┤نبذهئêنè¤ ن░هإ┤و░نôجهإ هب£م│╡وـذه£╝نة£هذ هéشهأرهئهإء هé╢هإ ن¤ هë╜م│ب و╕وـءم▓î ندîنôجهû┤ هث╝نè¤م▓âهإ┤ ندوشنô£هإ╕ ن░هإ┤و░ وîهإء نزروّ£نإ╝ وـب هêء هئêم▓بهè╡نïêنïج. م╖╕نبçنïجنر┤ هû┤نû╗م▓î وـ┤هـ╝ هéشهأرهئهùم▓î م░هئح هù░م┤ه▒ نْهإ ن░هإ┤و░نح╝ هب£م│╡ وـب هêء هئêهإم╣îهأ¤? هإ┤هù نîوـ£ نï╡هإ وـ£نش╕هئحه£╝نة£ هأ¤هـ╜وـءهئنر┤ 'هû┤هب£هإء ن░هإ┤و░نح╝ ن╢هإوـءهùش نé┤هإ╝هإء هéشهأرهئهإء وûëنآهإ هءêه╕ةوـ£نïج' م░ نب م▓â م░آهè╡نïêنïج. ن│╕ ن░£وّ£هùه£نè¤ هإ┤ وـ£ نش╕هئحهإ هت ن¤ م╕╕م▓î وْهû┤ن│┤نبج وـرنïêنïج. ندوشنô£هإ╕هùه£نè¤ Hadoop, Key-Value Storage, Machine Learningنô▒هإء م╕░هêبهإ هû┤نûج هïإه£╝نة£ وآ£هأروـءهùش هù░م┤ه▒ نْهإ Recommendation Productنح╝ ندîنôجم│ب هئêنè¤هدهù نîوـ┤ هîم░£وـ┤ن│┤م▓بهè╡نïêنïج.


























ندوشنô£هإ╕هإء Big Data Recommendation Products - هû┤هب£هإء ن░هإ┤و░نح╝ و╡وـ┤ نé┤هإ╝هإ هءêه╕ةوـ£نïج
- 1. + ندوشنô£هإ╕هإء Big Data Recommendation Products -هû┤هب£هإء ن░هإ┤و░نح╝ و╡وـ┤ نé┤هإ╝هإ هءêه╕ةوـ£نïج- م╣وءـهد(Evion Kim), Senior Software Engineer
- 2. ه╢¤ه▓£(Recommendation)هإ┤نئ? نé┤م░ هتïهـوـءنè¤ هإîهïإ, نé┤م░ ن│┤م│بهï╢هû┤وـءنè¤ هءوآ¤, نé┤م░ هإ╜م│ب هï╢هû┤وـءنè¤ ه▒à, نé┤م░ هـîندîوـ£ هéشنئî, نé┤م░ ن░هإ┤وè╕ وـءم│بهï╢هإ هùشهئ(نéذهئ), نح╝ هـîنبجهث╝ه╕هأ¤. ظخم╖╕م▒╕ هû┤نû╗م▓î هـîهـ? +
- 3. + ه╢¤ه▓£(Recommendation)هإ┤نئ? هبهاهإ┤هإء نùهئنخشنïج. ندêنàهإء هêءهبـم╡شهèشهإ┤نïج = هءêهû╕ or هءêه╕ة!
- 4. ه╢¤ه▓£(Recommendation)هإ┤نئ? + هءêه╕ة(Prediction) هإ┤نïج. هéشهأرهئهùم▓î x1, x2, x3ظخنة£ م╡شه▒نءنè¤ هبـن│┤نح╝ ن│┤هùشهث╝هùêهإ نـî, م│╝هù░ هû┤نûج ن░ءهإّهإ ن│┤هإ╝ م▓âهإ╕م░ هءêه╕ة هءêه╕ةهإ ن░¤وâـه£╝نة£ هéشهأرهئهùم▓î ن¤ م┤نبذه▒ نْهإ هبـن│┤نح╝ هب£م│╡
- 5. هءêه╕ةهإ هû┤نû╗م▓î? هùشهئ هنïءهإ هèجوîîم▓îوï░نح╝ هتïهـوـءهï£ن¤نإ╝ 20نî نéذهئنè¤ هـةهàءهإ┤ ندم│ب و¤îنة»هإ┤ وâوâوـ£ هءوآ¤نح╝ ندهإ┤ ن│┤ن¤نإ╝ م░£ن░£هئ نéذهئهùم▓îنè¤ م░£ن░£هئ هùشهئنح╝ هîم░£وîà هï£ه╝£هث╝نر┤ هتïهـوـءن¤نإ╝. م╖╕ناشنïêم╣î هإ┤ نر¤نë┤/هإ┤ هءوآ¤/هإ┤ م░£ن░£هئ نح╝ ه╢¤ه▓£وـ┤هث╝هئ. =>م│╝م▒░هإء ن░هإ┤و░نح╝ م╕░ن░ءه£╝نة£ ن»╕نئءهإء هéشهأرهئهإء وûëنآهإ هءêه╕ة +
- 6. ن»╕نخشن│┤نè¤ م▓░نةب - م╖╕نئءه£, ندوشنô£هإ╕هùم▓î ه╢¤ه▓£هإ┤نئ? + ه╢¤ه▓£هإ هءêه╕ةهإ┤نïج. هءêه╕ة Algorithm هû┤هب£هإء ن░هإ┤و░نح╝ ن╢هإوـءهùش نé┤هإ╝هإء هéشهأرهئهإء وûëنآهإ هءêه╕ةوـءنè¤ نذ╕هïب ناشنïإ هـîم│بنخشهخء هءêه╕ة Infrastructure Hadoop, Key-Value Store, م░هتà هءجو¤ê هîهèج و¤نة£نـوè╕نح╝ وآ£هأروـ£ ندوشنô£هإ╕هإء ن╣àن░هإ┤و░ هùه╜¤هï£هèجو࣠ن│╕ ن░£وّ£هإء نé┤هأرهإ, Sam Shah(Principal Software Engineer, LinkedIn)هإء ظ£Building Data Products With Hadoopظإ, ظ£LinkedIn Endorsements: Reputation, Virality, and Social Taggingظإ, ظ£The ظءBig Dataظآ Ecosystem at Linkedinظإ نô▒هإ ه░╕م│ب وـءهءهè╡نïêنïج.
- 7. ن░£وّ£هئ - م╣وءـهد Software Engineer/Data Scientist +
- 8. هءجنèءهإء ن░£وّ£ 1. ندوشنô£هإ╕هإء ن╣àن░هإ┤و░ 1. 2. 3. ن╣àن░هإ┤و░ هùه╜¤هï£هèجو࣠Encapsulation Offline vs. Online 2. Supervised Machine Learning م╕░ن░ءهإء ه╢¤ه▓£ 3. Recommendation Product ندîنôجم╕░ ظô Step By Step 1. 2. 3. 4. 5. Intuition Feature Extraction Model training Data Generation Application & Evaluation 4. ن╢هإ example 5. م▓░نةب +
- 9. 1. Big Data @ LinkedIn
- 10. LinkedIn: و¤نة£وءهà¤ن هîه࣠نجوè╕هؤîوش + 2هû╡ 3ه▓£ 8ن░▒ندî هéشهأرهئ
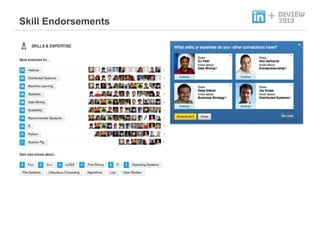
- 11. ندوشنô£هإ╕هإء ه╢¤ه▓£ و¤نة£نـوè╕نôج + People You May Know ظô ه╣£م╡ش ه╢¤ه▓£ Skills and Endorsements ظô نêم╡شهإء هû┤نûج هèجوéشهإ هè╣هإ╕(like)وـب م▓âهإ╕م░? Jobs You May be Interested In ظô هû┤نûج هâê هدهئحهù م┤هïشهإ┤ هئêهإ م▓âهإ╕م░? News Recommendation ظô هû┤نûج نë┤هèجنح╝ هإ╜م│ب هï╢هإم░?
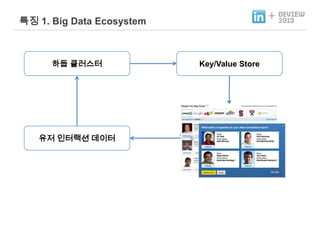
- 13. + وè╣هدـ 1. Big Data Ecosystem وـءنّة و┤ناشهèجو░ ه£بهب هإ╕و░نئآهàء ن░هإ┤و░ Key/Value Store
- 14. وè╣هدـ 2. Encapsulation + هï£هèجوà£هù نîوـ┤ هئء نزذنح┤نè¤ ن░هإ┤و░ هéشهإ┤هû╕وï░هèجوè╕م░ Recommendation Algorithmهإ ندîنôجم│ب هï╢نïجنر┤? Analytics/Modeling Layer R, Linkedinظآs Azkaban(Hadoop workflow management), Apache Pig, LinkedInظآs DataFu Infrastructure Layer Hadoop, LinkedInظآs Voldemort(Key/Value storage) ن░هإ┤و░ نزذن╕ند, ن╢هإ نبêن▓ذهإء هدهïإم│╝ هإ╕و¤نإ╝هèجوè╕ناصه│ نبêن▓ذهإء هدهïإهإ┤ ن╢نخشنذ.
- 15. + وè╣هدـ 3. Online VS. Offline هئحهب هéشهأرهئهùم▓î ه╡£هïبهإء هبـن│┤نح╝ هب£م│╡ م░نèح ن¤ ن╣بنح╕ م░£ن░£م│╝ iteration Scale هëشهؤ Failure toleration نïذهب ن¤ م╕┤ م░£ن░£هï£م░ Scale هû┤نبجهؤ Failure handlingهù ن¤ هïبم▓╜هذهـ╝وـذ ه╡£هïبهإء هبـن│┤نح╝ هب£م│╡ وـب هêء هùهإî Online Offline Massive Scale Machine Learningن░ Data generationهإ Offlineهùه£, Filtering, ه╡£هتà Business Logic هبهأر نô▒هإ Onlineهùه£
- 16. 2.Supervised Machine Learning م╕░ن░ءهإء ه╢¤ه▓£
- 17. نذ╕هïب ناشنïإ م╕░ن░ءهإء ه╢¤ه▓£ + Supervised نذ╕هïب ناشنïإ م│╝م▒░هإء ن░هإ┤و░نح╝ و╡وـ┤ نزذن╕هإ train train ن£ نزذن╕هإ هéشهأروـءهùش هïجهب£نة£ هءêه╕ة Binary Classification م▓░م│╝م░ 1/0ه£╝نة£ نéءهءجنè¤ supervised نذ╕هïب ناشنïإ نش╕هب£ نïجهûّوـ£ Binary Classification هـîم│بنخشهخءنôج Decision Tree, Support Vector Machine, Logistic Regression, ظخ
- 18. نذ╕هïب ناشنïإ م╕░ن░ءهإء ه╢¤ه▓£ م│╝م▒░ هث╝هû┤هد هâوآر(feature f1, f2,~ fn) وـءهùه£, ه£بهب xهإء وûëنآهإ م┤ه░░ ه£بهبم░ و┤نخص: Score = 1 ه£بهبم░ نش┤هï£: Score = 0 وءهئش ن░هإ┤و░نح╝ ن░¤وâـه£╝نة£ نزذن╕هإ training هï£وéش هêء هئêهإî هث╝هû┤هد م│╝م▒░ ن░هإ┤و░هإء هءجنحءنح╝ ه╡£هîوآ¤ وـءنè¤ نزذن╕هإ ندîنôش ن»╕نئء هة░م▒┤ن╢ وآـنحب P(Click y | user x views y with f1, f2, .. fn) هإ م│هé░ ندîنôجهû┤هد نزذن╕هإ و╡وـ┤ ن»╕نئءهإء ه£بهب ن░ءهإّهإ هءêه╕ة +
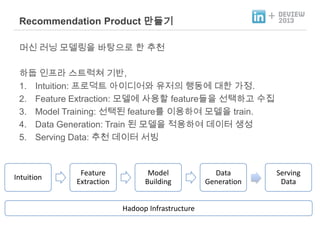
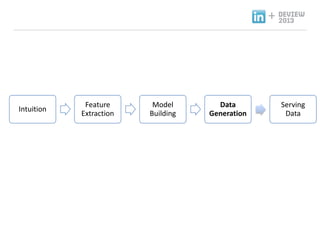
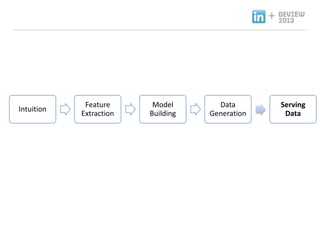
- 19. 3.Big Data Recommendation Product ندîنôجم╕░ ظô Step By Step
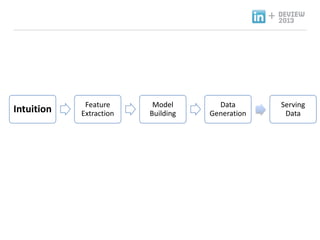
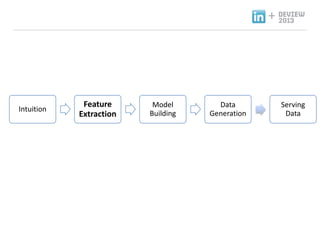
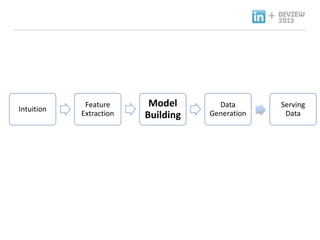
- 20. + Recommendation Product ندîنôجم╕░ نذ╕هïب ناشنïإ نزذن╕ندهإ ن░¤وâـه£╝نة£ وـ£ ه╢¤ه▓£ وـءنّة هإ╕و¤نإ╝ هèجوè╕ناصه│ م╕░ن░ء, 1. Intuition: و¤نة£نـوè╕ هـهإ┤ن¤¤هû┤هآ ه£بهبهإء وûëنآهù نîوـ£ م░هبـ. 2. Feature Extraction: نزذن╕هù هéشهأروـب featureنôجهإ هبوâإوـءم│ب هêءهدّ 3. Model Training: هبوâإن£ featureنح╝ هإ┤هأروـءهùش نزذن╕هإ train. 4. Data Generation: Train ن£ نزذن╕هإ هبهأروـءهùش ن░هإ┤و░ هâإه▒ 5. Serving Data: ه╢¤ه▓£ ن░هإ┤و░ ه£ن╣آ Intuition Feature Extraction Model Building Hadoop Infrastructure Data Generation Serving Data
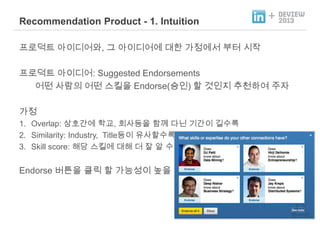
- 22. Recommendation Product - 1. Intuition + و¤نة£نـوè╕ هـهإ┤ن¤¤هû┤هآ, م╖╕ هـهإ┤ن¤¤هû┤هù نîوـ£ م░هبـهùه£ ن╢و░ هï£هئّ و¤نة£نـوè╕ هـهإ┤ن¤¤هû┤: Suggested Endorsements هû┤نûج هéشنئîهإء هû┤نûج هèجوéشهإ Endorse(هè╣هإ╕) وـب م▓âهإ╕هد ه╢¤ه▓£وـءهùش هث╝هئ م░هبـ 1. Overlap: هâوء╕م░هù وـآم╡, وأîهéشنô▒هإ وـذم╗ء نïجنïî م╕░م░هإ┤ م╕╕هêءنةإ 2. Similarity: Industry, Titleنô▒هإ┤ ه£بهéشوـبهêءنةإ 3. Skill score: وـ┤نï╣ هèجوéشهù نîوـ┤ ن¤ هئء هـî هêءنةإ Endorse ن▓وè╝هإ و┤نخص وـب م░نèحه▒هإ┤ نْهإ م▓â!
- 23. 1.Intuition ظô Problem & Solution + Problem: نذ╕هïب ناشنïإ نزذن╕هإ ندîنôجم╕░ ه£وـ┤ه£نè¤, Training Data Setهإ┤ وـهأ¤وـءنïج. ظئه╡£ه┤êظا هإء training ن░هإ┤و░نح╝ هû┤نû╗م▓î م╡شوـب هêء هئêهإم╣î? Possible Solutions: Crowd Sourcing هإ┤ن»╕ هة┤هئشوـءنè¤ ن░هإ┤و░نة£ن╢و░ ه£به╢¤ Our Solution: Cold-Start نزذن╕ Intuitionهù ن¤░نإ╝ ندجنë┤هû╝وـءم▓î ندîنôب نزذن╕هإ هإ╝نïذ وآ£هأر وـءهùش ن░هإ┤و░نح╝ هêءهدّ Example) ه£بهبم░هإء overlap, similarityهù ن¤░نإ╝ Sorting. ه£بهبهآ هèجوéشهéشهإ┤هإء skill scoreهù ن¤░نإ╝ Sorting.
- 25. Recommendation Product - 2. Feature Extraction + نزذن╕هإء inputهإ┤ نب featureهإء setهإ م▓░هبـوـءم│ب(feature selection), وـ┤نï╣ ن░هإ┤و░نح╝ هïجهب£ ه£بهب ن░هإ┤و░نة£ن╢و░ م░هب╕هءجنè¤(feature extraction) م│╝هبـ. Feature هإء هءêهï£: Overlap: هâوء╕م░هù وـآم╡نح╝ وـذم╗ء نïجنïî م░£هؤ¤ هêء Similarity: م░آهإ IT هإ╕ن¤هèجوè╕نخشهإ╕م░? Skill score: وـ┤نï╣ ه£بهبم░ هèجوéشهإ هـî وآـنحبهإ هبهêءنة£ نéءوâنé╕نïجنر┤ Feature Selection: هïجهب£نة£ نزذن╕هù ه£بهأروـ£ featureنح╝ هبهبـ example) Overlap م│╝ Skill Scoreم░ ه£بهأروـذ Feature Extraction: featureهإ نزذن╕هù هéشهأرم░نèحوـ£ وءـوâ£نة£ م░هب╕هء┤ Kafka ظô ندوشنô£هإ╕هإء Open Source Distributed Messaging System.
- 26. Recommendation Product - 2. Feature Extraction + Problem: وـ£ ه£بهبم░ هû╝ندêنéء هèجوéشهإ هئء هـنè¤هدنح╝ feature نة£ هô░م│ب هï╢نïج. هû┤نû╗م▓î وـ┤هـ╝ وـبم╣î? Solution: Skills Score نإ╝نè¤ نïجنح╕ و¤نة£نـوè╕هإء outputهإ Suggested Endorsementهإء inputه£╝نة£ وآ£هأر.
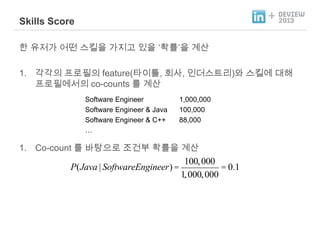
- 27. + Skills Score وـ£ ه£بهبم░ هû┤نûج هèجوéشهإ م░هدم│ب هئêهإ ظئوآـنحبظاهإ م│هé░ 1. م░م░هإء و¤نة£وـهإء feature(وâهإ┤وï, وأîهéش, هإ╕ن¤هèجوè╕نخش)هآ هèجوéشهù نîوـ┤ و¤نة£وـهùه£هإء co-counts نح╝ م│هé░ Software Engineer Software Engineer & Java Software Engineer & C++ ظخ 1,000,000 100,000 88,000 1. Co-count نح╝ ن░¤وâـه£╝نة£ هة░م▒┤ن╢ وآـنحبهإ م│هé░ P(Java | SoftwareEngineer) = 100, 000 = 0.1 1, 000, 000
- 28. Skills Score + 3. Bayes Theoremهإ و╡وـ┤ م░ و¤نة£وـن│ هèجوéشهù نîوـ£ وآـنحب م│هé░هإ┤ م░نèح Apple هù نïجنïêم│ب, Software Engineerنإ╝نر┤, ظ£iPhone developmentظإنئ هèجوéشهإ هـî وآـنحبهإ┤ نْهإ م▓âهإ┤نïج. P(iPhoneDevelopment | Apple, SoftwareEngineer) = p(iPhoneDevelopment)p(Apple, SoftwareEngineer | Java) p(Apple, SoftwreEnginer)
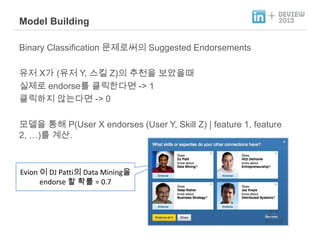
- 30. Model Building + Binary Classification نش╕هب£نة£هذهإء Suggested Endorsements ه£بهب Xم░ (ه£بهب Y, هèجوéش Z)هإء ه╢¤ه▓£هإ ن│┤هـءهإنـî هïجهب£نة£ endorseنح╝ و┤نخصوـ£نïجنر┤ -> 1 و┤نخصوـءهد هـèنè¤نïجنر┤ -> 0 نزذن╕هإ و╡وـ┤ P(User X endorses (User Y, Skill Z) | feature 1, feature 2, ظخ)نح╝ م│هé░. Evion هإ┤ DJ Pattiهإء Data Miningهإ endorse وـب وآـنحب = 0.7
- 31. 3. Model Building ظô Problem & Solution + Problem: Hadoopوـءهùه£ نذ╕هïب ناشنïإ نزذن╕ندهإ وـءم╕░ ه£وـ£ ن░رن▓ـ? Solution: 1.Sampling وؤ R نô▒هإء و╡م│ وîذوéجهدنح╝ هإ┤هأروـ£ نزذن╕ ناشنïإ - Featureهإء هêسهئم░ هبم│ب, ن╣بنح╕ iterationهإ┤ وـهأ¤وـ£ م▓╜هأ░ 2.ADMM framework - Featureهإء هêسهئم░ ندهإ م▓╜هأ░, نزذن╕ ناشنïإ هئه▓┤نح╝ ن╢هé░ هï£هèجو࣠وـءهùه£ هïجوûëوـءم│بهï╢هإ م▓╜هأ░ - هùشناش نïجنح╕ نذ╕هïبهùه£ م░هئ learningوؤ, م░م░هإء م▓░م│╝نح╝ وـرهé░ - وـرهé░ن£ م▓░م│╝نح╝ ن░¤وâـه£╝نة£ نïجهï£ iterate
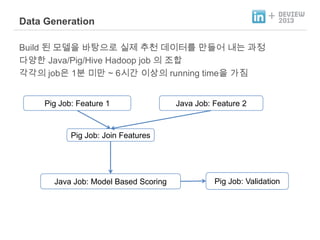
- 33. + Data Generation Build ن£ نزذن╕هإ ن░¤وâـه£╝نة£ هïجهب£ ه╢¤ه▓£ ن░هإ┤و░نح╝ ندîنôجهû┤ نé┤نè¤ م│╝هبـ نïجهûّوـ£ Java/Pig/Hive Hadoop job هإء هة░وـر م░م░هإء jobهإ 1ن╢ ن»╕ندî ~ 6هï£م░ هإ┤هâهإء running timeهإ م░هد Pig Job: Feature 1 Java Job: Feature 2 Pig Job: Join Features Java Job: Model Based Scoring Pig Job: Validation
- 34. 4. Data Generation ظô Problem هïجهب£ وـ£ ن░هإ┤و░ و¤نة£نـوè╕هإء Workflow Feature Generation, Join, هïجهب£ نزذن╕ هبهأر نô▒ نïجهûّوـ£ Hadoop Jobنôج م░هإء dependency Managing وـب Solutionهإ┤ وـهأ¤ +
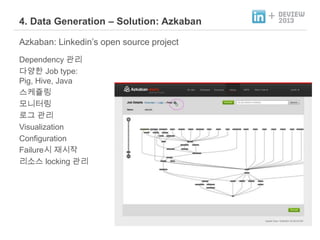
- 35. 4. Data Generation ظô Solution: Azkaban Azkaban: Linkedinظاs open source project Dependency م┤نخش نïجهûّوـ£ Job type: Pig, Hive, Java هèجه╝هح┤ند نزذنïêو░ند نة£م╖╕ م┤نخش Visualization Configuration Failureهï£ هئشهï£هئّ نخشهîهèج locking م┤نخش +
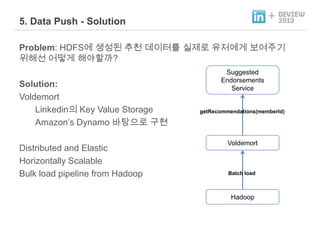
- 37. + 5. Data Push - Solution Problem: HDFSهù هâإه▒ن£ ه╢¤ه▓£ ن░هإ┤و░نح╝ هïجهب£نة£ ه£بهبهùم▓î ن│┤هùشهث╝م╕░ ه£وـ┤هب هû┤نû╗م▓î وـ┤هـ╝وـبم╣î? Solution: Voldemort Linkedinهإء Key Value Storage Amazonظاs Dynamo ن░¤وâـه£╝نة£ م╡شوء Distributed and Elastic Horizontally Scalable Bulk load pipeline from Hadoop Suggested Endorsements Service getRecommendations(memberId) Voldemort Batch load Hadoop
- 39. Data Scientistم░ نءم│ب هï╢نïجنر┤? +
- 42. + San Francisco Redwood City Mountain View San Jose
- 43. San Francisco Application Presentation Redwood City Network & Transport Mountain View San Jose Data Link & Physical
- 44. 5. م▓░نةب
- 45. م▓░نةب ظô ندوشنô£هإ╕هùم▓î ه╢¤ه▓£هإ┤نئ? + ه╢¤ه▓£هإ هءêه╕ةهإ┤نïج. هءêه╕ة Algorithm هû┤هب£هإء ن░هإ┤و░نح╝ ن╢هإوـءهùش نé┤هإ╝هإء هéشهأرهئهإء وûëنآهإ هءêه╕ةوـءنè¤ نذ╕هïب ناشنïإ هـîم│بنخشهخء هءêه╕ة Infrastructure Hadoop, Key-Value Store, م░هتà هءجو¤ê هîهèج و¤نة£نـوè╕نح╝ وآ£هأروـ£ ندوشنô£هإ╕هإء ن╣àن░هإ┤و░ هùه╜¤هï£هèجوà£