BITS - Overview of sequence databases for mass spectrometry data analysis
ŌĆó
1 likeŌĆó948 views

This is the fourth presentation of the BITS training on 'Mass spec data processing'. It review sequences databases and their flaws in light of mass spectrometry data analysis. Thanks to the Compomics Lab of the VIB for their contribution.



















BITS - Overview of sequence databases for mass spectrometry data analysis
- 2. sequence databases lennart martens lennart.martens@ugent.be Computational Omics and Systems Biology Group Department of Medical Protein Research, VIB Department of Biochemistry, Ghent University Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases Ghent, Belgium lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 3. PEPTIDES AND REDUNDANCY IN SEQUENCE DATABASES Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
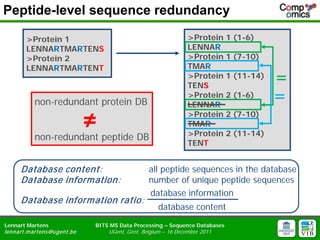
- 4. Peptide-level sequence redundancy >Protein 1 >Protein 1 (1-6) LENNARTMARTENS LENNAR >Protein 2 >Protein 1 (7-10) LENNARTMARTENT TMAR >Protein 1 (11-14) TENS = non-redundant protein DB >Protein 2 (1-6) LENNAR = ŌēĀ >Protein 2 (7-10) TMAR >Protein 2 (11-14) non-redundant peptide DB TENT Database content: all peptide sequences in the database Database inform ation: number of unique peptide sequences database information Database inform ation ratio: database content Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
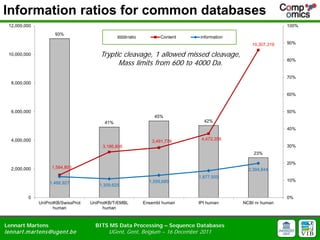
- 5. Information ratios for common databases 12,000,000 100% 93% ratio Content information 10,307,319 90% 10,000,000 Tryptic cleavage, 1 allowed missed cleavage, Mass limits from 600 to 4000 Da. 80% 70% 8,000,000 60% 6,000,000 50% 45% 41% 42% 40% 4,000,000 4,472,356 3,491,778 3,186,806 30% 23% 20% 2,000,000 1,584,806 2,394,844 1,877,500 1,559,685 10% 1,466,927 1,309,625 0 0% UniProtKB/SwissProt UniProtKB/TrEMBL Ensembl human IPI human NCBI nr human human human Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 6. ENRICHING SEQUENCE DATABASES Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
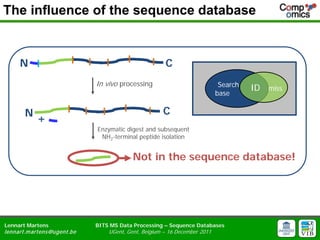
- 7. The influence of the sequence database N C In vivo processing Search ID miss base N C + Enzymatic digest and subsequent NH2-terminal peptide isolation Not in the sequence database! Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 8. An example Mitochondrial Isovaleryl-coA Dehydrogenase MATATRLLGWRVASWRLRPPLAGFVS N -term inal transit peptide (1-29) 30 47 QRAHSLLPVDDAINGLSEEQRQLREŌĆ” I sovaleryl-CoA dehydrogenase (30 ŌĆō 423) ŌĆ”LDGIQCFGGNGYINDFPMGRFLRDA 423 KLYEIGAGTSEVRRLVIGRAFNADFH Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
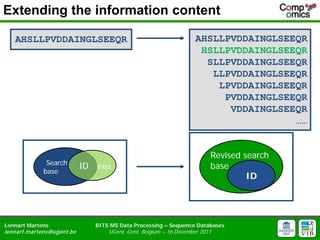
- 9. Extending the information content AHSLLPVDDAINGLSEEQR AHSLLPVDDAINGLSEEQR HSLLPVDDAINGLSEEQR SLLPVDDAINGLSEEQR LLPVDDAINGLSEEQR LPVDDAINGLSEEQR PVDDAINGLSEEQR VDDAINGLSEEQR ŌĆ”ŌĆ” Revised search Search ID miss base base ID Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 10. Another example: in vivo protein cleavage NH 2 COOH R R R D R Caspase cleavage of this protein (for 50%) NH 2 COOH R R R D R NH 2 COOH NH 2 COOH R R RD R NH2-terminal peptide isolation COOH COOH NH 2 NH 2 R R NOT IN DB! Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
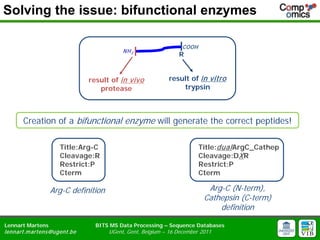
- 11. Solving the issue: bifunctional enzymes COOH NH 2 R result of in vivo result of in vitro protease trypsin Creation of a bifunctional enzyme will generate the correct peptides! Title:Arg-C Title:dual ArgC_Cathep Cleavage:R Cleavage:DX R Restrict:P Restrict:P Cterm Cterm Arg-C definition Arg-C (N-term), Cathepsin (C-term) definition Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 12. DBTOOLKIT AND DATABASE ON DEMAND Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
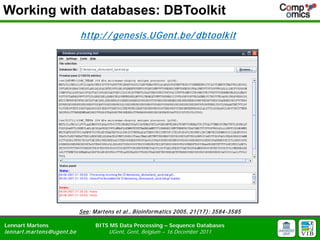
- 13. Working with databases: DBToolkit http:/ / genesis.UGent.be/ dbtoolk it See: M artens et al., Bioinform atics 2005, 21(17): 3584-3585 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 14. Summary of DBToolkit functionalities a) Enzymatic digestion using regular or ŌĆśdualŌĆÖ enzymes ’āĀ proteins to peptides b) N-terminal or C-terminal ragging ’āĀ enhancing the information content of the database c) Non-lossy redundancy clearing ’āĀ raising database information ratio d) Create shuffled and reversed databases ’āĀ false-positives testing e) Extract sequence-based subsets ’āĀ a priori prediction of potential success rate f) Map peptides back to proteins (maximal annotation approach) ’āĀ find all matching proteins, and select primaries etc ŌĆ” Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 15. Database on Demand ŌĆō DBToolkit online http:/ / w w w .ebi.ac.uk/ pride/ dod See: R eisinger et al., P roteom ics 2009, 9(18): 4421-4424 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 16. WHY DOES PROCESSING MATTER? Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
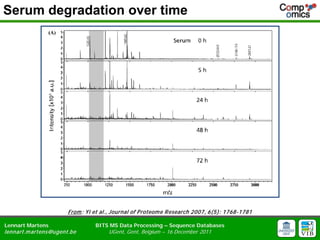
- 17. Serum degradation over time From : Yi et al., Journal of P roteom e R esearch 2007, 6(5): 1768-1781 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
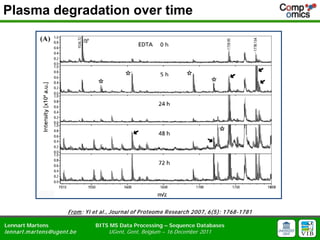
- 18. Plasma degradation over time From : Yi et al., Journal of P roteom e R esearch 2007, 6(5): 1768-1781 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 19. TIME-LABILITY OF SEQUENCE DATABASES Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 20. Example 1: HUPO PPP actualisation Bringing the P P P from I P I 2.21 to I P I 3.13 1555 Total 1048 Unchanged 67% 507 Changed 33% Of which: 338 Propagated 22% 67% (of ŌĆśChangedŌĆÖ) 169 Defunct 11% 33% (of ŌĆśChangedŌĆÖ) Of which 95 Defunct (RFSQ_XP) 6% 56% (of ŌĆśDefunctŌĆÖ) Both exist, 72 Defunct (Ensembl) 5% 43% (of ŌĆśDefunctŌĆÖ) 1 taxonomy now: RAT 1 immunoglobin 2 UniProt 0% 1% (of ŌĆśDefunctŌĆÖ) 1048 + 345 = 1386 recoverable (89.1%) See: M artens and M ueller et al., P roteom ics 2006, 6(18):5059-75 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
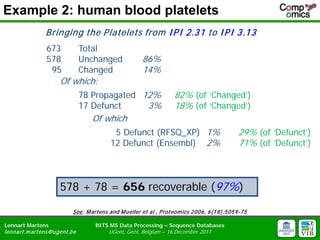
- 21. Example 2: human blood platelets Bringing the P latelets from I P I 2.31 to I P I 3.13 673 Total 578 Unchanged 86% 95 Changed 14% Of which: 78 Propagated 12% 82% (of ŌĆśChangedŌĆÖ) 17 Defunct 3% 18% (of ŌĆśChangedŌĆÖ) Of which 5 Defunct (RFSQ_XP) 1% 29% (of ŌĆśDefunctŌĆÖ) 12 Defunct (Ensembl) 2% 71% (of ŌĆśDefunctŌĆÖ) 578 + 78 = 656 recoverable (97%) See: M artens and M ueller et al., P roteom ics 2006, 6(18):5059-75 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 22. Proteins sometimes age badly Adapted from : http:/ / w w w .ebi.ac.uk/ ipi Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 23. THE PICR MAPPING SERVICE Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
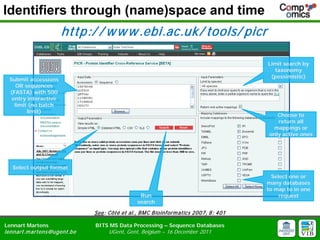
- 24. Identifiers through (name)space and time http:/ / w w w .ebi.ac.uk/ tools/ picr Limit search by taxonomy (pessimistic) Submit accessions OR sequences (FASTA) with 500 entry interactive limit (no batch limit) Choose to return all mappings or only active ones Select output format Select one or many databases to map to in one Run request search See: C├┤t├® et al., BM C Bioinform atics 2007, 8: 401 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
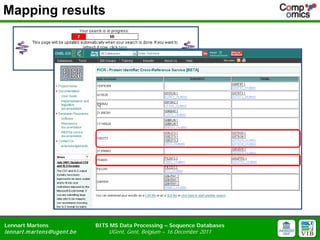
- 25. Mapping results Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 26. ESTIMATING FALSE DISCOVERY RATES THE DECOY DATABASE APPROACH Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 27. Decoy databases, the latest fashion Three main types of decoy DBŌĆÖs are used: - Reversed databases (easy) LENNARTMARTENS ’āĀ SNETRAMTRANNEL - Shuffled databases (slightly more difficult) LENNARTMARTENS ’āĀ NMERLANATERTTN (for instance) - Randomized databases (as difficult as you want it to be) LENNARTMARTENS ’āĀ GFVLAEPHSEAITK (for instance) The concept is that each peptide identified from the decoy database is an incorrect identification. By counting the number of decoy hits, we can estimate the number of false positives in the original database. Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 28. Estimating the FDR (i) 2 ├Ś nbr _ decoy _ hits FDR = nbr _ forward _ hits + nbr _ decoy _ hits FDR is the False Discovery Rate ŌĆō it is a metric that gives you an indication of how many (percent) of your identifications are potentially incorrect. Note that we multiply the number of decoy hits by 2, because we should not only count the actual decoy hits, but also the ŌĆśhiddenŌĆÖ false positives that are present in the forward identifications. The assumption here is that we expect one forward false positive hit per decoy false positive hit, hence the doubling term. From: Elias and Gygi, Nature Methods 2007, 4(3): 207-214 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 29. Estimating the FDR (ii) nbr _ decoy _ hits FDR = nbr _ forward _ hits This metric was proposed by Storey and Tibbs for genomics data, and further investigated by Lukas K├żll for proteomics. It provides a more accurate (and simpler!) estimate of the FDR, but can be extended to also take into account the (suspected) false positives in the forward set. See: Storey and Tibbs, PNAS 2003, 100(16): 9440-9445 See: K├żll et al,., JPR 2008, 7(1): 29-34 Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011
- 30. Thank you! Questions? Lennart Martens BITS MS Data Processing ŌĆō Sequence Databases lennart.m artens@ugent.be UGent, Gent, Belgium ŌĆō 16 December 2011