Building a Streaming Analytics Pipeline with Kafka and Druid - Big Data Europe, 2023
•Download as PPTX, PDF•
0 likes•30 views

Have you ever wondered how a modern event analytics pipeline is different from a classical ETL setup? In a presentation and live demo, this session shows how to design and set up an analytics pipeline in just a few minutes, using Kafka for delivery, ksqlDB for preprocessing, and Apache Druid for real-time OLAP.











Building a Streaming Analytics Pipeline with Kafka and Druid - Big Data Europe, 2023
- 1. ©2022, Imply ©2022, imply Building an Event Analytics Pipeline with Kafka, ksqlDB, and Druid Hellmar Becker, Senior Sales Engineer 1
- 2. ©2022, Imply About Me 2 hellmar.becker@imply.io https://www.linkedin.com/in/hellmarbec ker/ https://blog.hellmar-becker.de/ Hellmar Becker Sr. Sales Engineer at Imply Lives near Munich
- 3. ©2022, Imply Agenda ● The Case for Streaming Analytics ● How to Prepare Your Data: Streaming ETL ● How to Analyze Your Data: Streaming Analytics ● Apache Druid - A Streaming Analytics Database ● K2D - A Streaming Analytics Architecture ● Live Demo ● Q&A
- 4. ©2022, Imply The Case for Streaming Analytics ● Analytics - "the process of discovering, interpreting, and communicating significant patterns in data." ● OLAP = Online Analytical Processing ● Classical: But that's not enough anymore! Transaction al Database (OLTP) Analytical Database (OLAP) Source Data Batch ETL Client
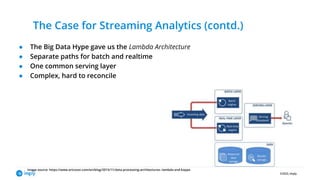
- 5. ©2022, Imply The Case for Streaming Analytics (contd.) ● The Big Data Hype gave us the Lambda Architecture ● Separate paths for batch and realtime ● One common serving layer ● Complex, hard to reconcile Image source: https://www.ericsson.com/en/blog/2015/11/data-processing-architectures--lambda-and-kappa
- 6. ©2022, Imply The Case for Streaming Analytics (contd.) ● 2014 Jay Krepps: Kappa Architecture ● Avoids having separate code paths for batch and streaming Image source: https://www.ericsson.com/en/blog/2015/11/data-processing-architectures--lambda-and-kappa
- 7. ©2022, Imply How to prepare your Data: Streaming ETL ETL = Extract, Transform, Load Let's focus on the Transform part Simple Event Processing = 1 event at a time ● Filter ● Transform ● Cleanse Complex Event Processing = Relate events to each other ● Windowing ● Aggregations ● Joins ● Enrichment ksqlDB is a tool by Confluent that does streaming ETL using streaming SQL
- 8. ©2022, Imply How to analyze your data: Streaming Analytics with Druid Sub-second queries at any scale Interactive analytics on TB-PBs of data High concurrency at the lowest cost 100s to 1000s QPS via a highly efficient engine Real-time and historical insights True stream ingestion for Kafka and Kinesis Plus, non-stop reliability with automated fault tolerance and continuous backup 1 2 3 For analytics applications that require:
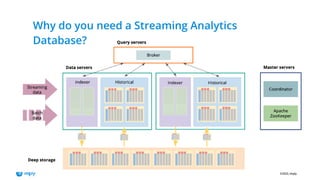
- 9. ©2022, Imply Why do you need a Streaming Analytics Database?
- 10. Files App data Data sources µService Database Event Streaming Infrastructure Databases Data Lake Stream ETL Stream Processor Messaging CDC Streams Realtime Analytics Event Analytics Infrastructure Custom visualizations Dashboards & reports Root-cause analysis Data/Event driven Apps BI tools K2D Architecture - Kafka to Druid
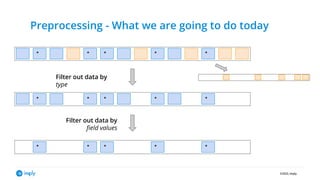
- 11. ©2022, Imply Preprocessing - What we are going to do today * * * * * * * * * * * * * * * Filter out data by type Filter out data by field values
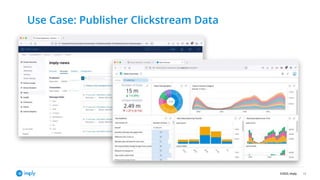
- 12. ©2022, Imply Use Case: Publisher Clickstream Data 12
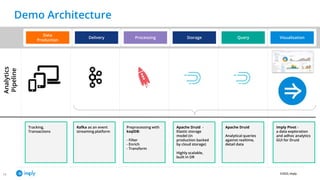
- 13. ©2022, Imply 13 Visualisation Query Storage Processing Delivery Data Production Analytics Pipeline Kafka as an event streaming platform Preprocessing with ksqlDB: - Filter - Enrich - Transform Apache Druid - Elastic storage model (in production backed by cloud storage) Highly scalable, built in DR Apache Druid Analytical queries against realtime, detail data Imply Pivot - a data exploration and adhoc analytics GUI for Druid Tracking, Transactions Delivery Demo Architecture
- 15. ©2022, Imply Learnings 15 ● Kafka and Druid complement each other ● Use ksqlDB for ● Preprocessing ● Enrichment ● Materialized views ● Use Druid for ● Scalable analytical applications ● Adhoc data exploration ● OLAP style analysis ● Integration is easy with native integration APIs
Editor's Notes
- #3: Today we're going to talk about how to set up a streaming analytics pipeline with Apache Kafka and Apache Druid. My name is Hellmar, I am a Developer Advocate at Imply, the company that offers enterprise services and products based on Apache Druid. I live in Munich in Germany, and I blog about Druid on a regular basis. The QR code on this slide will take you directly to my blog.
- #4: Here's what I am going to cover in today's session. First of all, I am going to compare streaming analytics to more traditional ways of doing analytics. I will show how streaming analytics evolved over the last 10 or so years. I will then proceed to the components of a streaming analytics pipeline, namely the ETL and the analytics proper. I assume that many people in this room have an idea what Kafka is about [or do a hands-up survey here, who knows Kafka?] But Druid is a bit less known so I am going to give you a very quick description of what Druid is and how it works. I am then going to describe to you a streaming analytics architecture pipeline template built out of Apache Kafka, Apache Druid, and Confluent's ksqlDB which is a streaming SQL engine that is available under a community license. Finally, I will demonstrate this approach in practice by building a clickstream analytics pipeline right in front of you. All the components I am using are open source or community licensed, so you can try this at home for free!
- #5: This is how we used to do analytics, roughly 20 years ago. You would have your operational systems that collected data into transactional, or OLTP, databases. OLTP databases are built to process single updates or inserts very quickly. In traditional relational modeling this means you have to normalize your data model, ideally to a point where every item exists only once in a database. The downside is when you want to run an analytical query that aggregates data from different parts of your database, these queries require complex joins and can become very expensive, hurting query times and interfering with the transactional performance of your database. Hence another type of databases was conceived which is optimized for these analytical queries: OLAP databases. These come in different shapes and flavours, but generally a certain amount of denormalization and possibly preaggregation is applied to the data. The process that ships data from the transactional system to the OLAP database is called ETL - Extract, Transform, Load. It is a batch process that would run on a regular basis, for instance once a night or once every week. The frequency of the batch process determines how "fresh" your analytical data is. In the old world, where analytical users would be data analysts inside the enterprise itself, that was often good enough. But nowadays, in the age of connectivity, everyone is an analytics user. If you check your bank account balance and the list of transactions in your banking app on your smartphone, you are an analytics user. And if someone transfers funds to your account, you expect to see the result now and not two days later. A better way of processing data for analytics was needed. And we'll look at that now.
- #6: About ten years ago, the big data craze came up around the Hadoop ecosystem. Hadoop brought with it the ability to handle historical data to a previously unknown scale, but it also already had real time [note: this is not hard real time like in embedded systems! If necessary elaborate] capability, with tooling like Kafka, Flume, and HBase. The first approach to getting analytics more up to date was the so called lambda architecture, where incoming data would be sent across two parallel paths: A realtime layer with low latency and limited analytical capabilities A highly scalable but slower batch layer. This way, you would be able to retrieve at least some of the analytics results immediately, and get the full results the next day. A common serving layer would be the single entry point for clients. This architectural pattern did the job for a while but it has an intrinsic complexity that is somewhat hard to master. Also, when you have two different sources of results, you need to go through an extra effort to make sure that the results always match up.
- #7: A better way needed to be found. It was created in the form of the kappa architecture. In the kappa architecture, there is only one data path and only one result for a given query. The same processing path gives (near) real time results and also fills up the storage for historical data. The kappa architecture handles incoming streaming data and historical data in a common, uniform way and is more robust than a lambda architecture. Ideally you still want to encapsulate the details of such an architecture and not concern the user with it. We will come to that in a moment.
- #8: But first a few words about the part that I didn't cover in the last two slides: How to get the data out of the transactional systems into whatever analytics architecture you have. Instead of processing batches of data, streaming ETL has to be event driven. There are two ways of processing event data in a streaming ETL pipeline: Simple event processing looks at one event at a time. Simple event processing is stateless which makes it easy to implement but limite the things you can do with it. This is used for format transformations, filtering, or data cleansing, for instance. An example for simple event processing is Apache NiFi. Complex event processing looks at a collection of events over time, hence it is stateful and has to maintain a state store in the background. With that you can do things like windows aggregations, such as sliding averages or session aggregations. You can also join various event streams (think orders and shipments), or enrich data with lookup data that is itself event based. Complex event processing is possible using frameworks like Spark Streaming, Flink, or Kafka Streams. In this demo, I will use ksqlDB. ksqlDB is a community licensed SQL framework on top of Kafka Streams, by Confluent. With ksqlDB, you can write a complex event streaming application as simple SQL statements. ksqlDB queries are typically persistent: unlike database queries, they continue running until they are explicitly stopped, and they continue to emit new events as they process new input events in real time. ksqlDB abstracts away for the most part the detail of event and state handling.
- #9: Apache Druid is a high-performance, real-time analytics database purpose-built for powering analytics apps at massive scale and concurrency on streaming and batch data. Devs build with Druid because of at least 1 of these 3 differentiators: Sub-second query response at any scale: Druid’s unique distributed architecture and storage engine delivers consistent very fast response times for simple to complex (ie. aggregation, groupby) queries on trillions of rows. High concurrency at the best value. Druid is designed with a highly-efficient engine that minimizes CPU cycles for queries to support high concurrency at 100s to 1000s of queries per second - at a fraction of the cost of other databases Real-time and historical insights. Druid is built natively for true stream ingestion with historical context. It’s native integration with Kafka and Kinesis enables event-by-event ingestion, query-on-arrival and guaranteed consistency at massive scale north of millions of events ingested per second. Big Bonus: non-stop reliability. Druid is built for mission-critical use cases where HA and durability are paramount. It supports automated fault tolerance with auto-rebalancing nodes and continuous backup for zero data loss.
- #10: Let's take a look at the internal architecture of the Druid database. Druid is heavily distributed and exceptionally scalable, and here is how that works. In Druid, there are three type of servers: master, query, and data servers. Also there is deep storage (typically object storage, such as S3), and a relational database for metadata. Master servers handle data coordination, metadata processing, and service discovery. They know which bit of data lives where in the Druid cluster, and which processes and compute resources are available. Query servers serve as the entry point for clients. They receive a query, chop it up into partial queries that can be handled by a single machine independently, and assign each partial query to a process on a data server. When the partial results come back, the query server assembles them, applies final processing such as sorting and aggregations, and returns the result to the caller. The heavy lifting is mostly done by machines called data servers. A data server handles both data ingestion and partial queries. Let's look at streaming ingestion. An indexer process consumes data directly from a Kafka stream. These data are stored in memory as a realtime segment. They are already queryable. When a configurable time interval has been passed, the segment is closed off and a new segment is started. The finished segment is transformed into a columnar format. Within the segment, data is ordered by time. All alphanumeric data are dictionary compressed and bitmap indexed. The final result is binary compressed again, and written to deep storage. Deep storage serves as an archive and the source of truth. From deep storage, segments are then loaded to the local storage of the data servers, typically twice replicated for resiliency and performance. Then they are available for querying by the historical processes. A query's result is collected from the realtime segments (via the indexers) and the historical segments. This encapsulates the kappa architecture and hides most of its detail from the database user.
- #11: With that, we have everything we need. Kafka provides event delivery, and the framework for event processing. Event processing itself is done with ksqlDB applications. The curated result lands in Druid, where we can query the data and get fresh results at all times.
- #12: Let's take a look at what I am going to show in the demo. I have a stream of clickstream data in Kafka. This stream contains events that have a different format - click and session events. The first step will be to filter out one specific type of event. This shows how to handle semi-structured data in ksqlDB. After that, we have a defined schema to work with, so the next step is to reinterpret the result stream as structured data. And finally I will apply a data based filter to that stream, to create the curated stream that goes into Druid.
- #14: Red - open to changing Green - its working, no need or ability to replace