




















Building and Scaling a WebSockets Pubsub System
- 1. Building and Scaling a WebSockets Pubsub System Kapil Reddy @ Helpshift
- 2. About me - Kapil Staff Engineer @ Helpshift Clojure Distributed Systems Games Music Books/Comics Football
- 3. Helpshift is a Mobile CRM SaaS product. We help connect app developers with their customers. Since everything is now on mobile.
- 4. Scale ? ~2 TB data broadcast / day ? Outgoing - 75 k msg/sec ? Incoming - 1.5 k msg/sec ? Concurrency - 3.5k Here are some scale numbers for the Platform we have built
- 5. PubSub Platform We built a generic Pubish and Subscribe platform. Subscribers of these messages are Javascript clients listening on Websockets connection and Publishers are any backend server using ZMQ to publish the messages
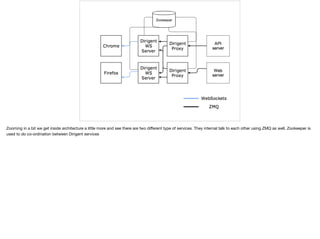
- 6. A simpli?ed version of the platformˇŻs architecture. Again browsers (Subscribers) connect to Dirigent using WebSockets and Backend servers (Publishers) connect to Diligent using ZMQ. ItˇŻs a simpli?ed view right now.
- 7. Zooming in a bit we get inside architecture a little more and see there are two di?erent type of services. They internal talk to each other using ZMQ as well. Zookeeper is used to do co-ordination between Dirigent services
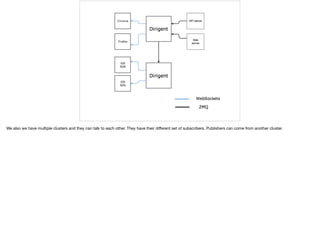
- 8. We also we have multiple clusters and they can talk to each other. They have their di?erent set of subscribers. Publishers can come from another cluster.
- 9. Evolution
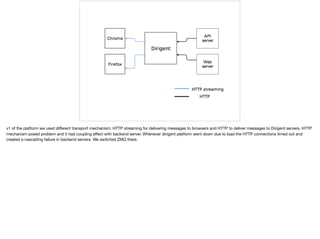
- 10. v1 of the platform we used di?erent transport mechanism. HTTP streaming for delivering messages to browsers and HTTP to deliver messages to Dirigent servers. HTTP mechanism posed problem and it had coupling e?ect with backend server. Whenever dirigent platform went down due to load the HTTP connections timed out and created a cascading failure in backend servers. We switched ZMQ there.
- 11. Problems with HTTP streaming Browser client needs only a subset of data but unsubscribing and subscribing to new topics was not possible over HTTP streaming since itˇŻs unidirectional channel. The only option was push everything to all clients for a speci?c subdomain. Initially it sounded like a good idea but once we hit scale we were running out of network bandwidth per machine. We switched to web sockets where client can ask for speci?c information based on UI actions.
- 12. Under the hood ? Clojure (JVM) ? Http-kit (NIO based web sockets server) ? ZMQ ? Zookeeper
- 13. Monitoring All the messages we are publishing is important data and needs to rendered in time. The nature of this data is ephemeral. We donˇŻt store it anywhere so auditing is hard. So utilising monitoring was crucial for us.
- 14. Under the hood ? StatsD protocol ? Graphite - Storage ? Grafana - Frontend
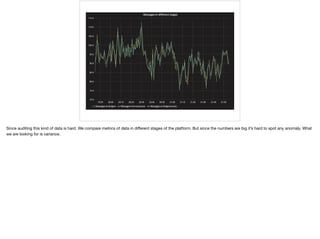
- 15. *example of monitoring comparison different stages* Since auditing this kind of data is hard. We compare metrics of data in di?erent stages of the platform. But since the numbers are big itˇŻs hard to spot any anomaly. What we are looking for is variance.
- 16. Message variance is easy to parse visually. If variance is low some stage of the platform is dropping data. In fact we also have setup alerts on this same query.
- 17. Another important metric is time taken to publish a message to WebSocket connection. Since near real time SLA is so important we look at p99s for anomalies. We have setup alerts on these as well.
- 18. Cost saving Costs are a concern for us always! There are two important factors that add up to the cost. Outgoing bandwidth usage and number of machines
- 19. Compression First we started using gzip compression for websockets. ItˇŻs a standard compression mechanism supported by browsers but as with browsers there are quirks here.
- 20. Re-visiting features Biggest change you can do to save costs is to re-visit the features/business logic itself and try to optimise there. This reduced the bandwidth usage by signi?cant amount.
- 21. Auto scaling To save up on number of machines used. We started investigating in how to do auto scaling. Auto scaling was not a straight forward thing since all the connections are long running and usually can stay alive for as long as 8 hours.
- 22. HAProxy with least conn We went with the obvious choice of least connection with HAProxy doing the load balancing.
- 23. Least load connection works. Sometimes The problem with least load connection is assumption that number of connections a server is handling is directly proportional to amount of work itˇŻs doing. This was a wrong assumption and it just lead us to uneven distribution. Server crashes and just bad sleepless nights.
- 24. Feedback load balancing Feedback load balancing is something we started to do with Herald an internal tool we built at Helpshift. This helps HAProxy decide which server to choose when routing a new connection. All the servers can expose the current load they are under to Herald which in turns tells HAproxy which server to choose. If all servers are loaded we scale out. If all servers are under loaded we scale in.
- 25. Summary ? Building a web sockets infrastructure on EC2 is possible but it has quirks ? Use feedback load balancing for WebSockets / Long running connection traf?c ? ZMQ, JVM are solid building blocks for building a realtime pubsub platform ? Instrumentation in multiple stages of platform is a good way to keep track of a real time system