
























![Pipeline Performance
Total time required is, Tm = [m + (n-1)]t
Speedup factor: non-pipelined processor is
defined as,
Sm = (nm / m +(n-1) )
Where, n = segment/stages
M = no. of ins](https://image.slidesharecdn.com/caunitiii-230802092851-d22cc511/85/CA-UNIT-III-pptx-29-320.jpg)












![Side Effects
âĒ When destination register of the current instruction
is the source register of the next instruction there is
a data dependency. It is explicit and it is identified
by register name.
âĒ The addition of these 2 numbers may be
accomplished as follows:
ADD R1,R3
ADD with carry R2, R4
R2<- [R2]+[R4]+Carry](https://image.slidesharecdn.com/caunitiii-230802092851-d22cc511/85/CA-UNIT-III-pptx-43-320.jpg)











































More Related Content
Similar to CA UNIT III.pptx (20)
More from ssuser9dbd7e (6)




Recently uploaded (20)




















CA UNIT III.pptx
- 2. UNIT III A Basic MIPS implementation â Building a Datapath â Control Implementation Scheme â Pipelining â Pipelined datapath and control â Handling Data Hazards & Control Hazards â Exceptions.
- 3. Basic MIPS Implementation âĒ MIPS - Million Instructions Per Second âĒ Instruction set is divided into three classes: 1. Memory-reference â load word (lw) and store word (sw) 2. Arithmetic-logical â add, sub, AND, OR 3. Branch instruction â branch equal (beq) and jump (j)
- 4. MIPS Instruction Execution : MIPS instructions classically take five steps: ï Fetch instruction from memory ï Read registers while decoding the instruction. The format of MIPS instructions allows reading and decoding to occur simultaneously ï Execute the operation or calculate an address ï Access an operand in data memory ï Write the result into a register
- 6. dfgdfg Basic implementation of MIPS with control signals
- 7. Building a Datapath ï Elements that process data and addresses in the CPU - Memories, registers, Program Counter(PC), ALUs, adders.
- 8. Datapath for different instructions: ï Datapath for arithmetic-logic instructions ï Datapath for Load and Store word instructions ï Datapath for Branch instructions ï Creating a Single Datapath
- 9. 1. Datapath for arithmetic-logic instructions âĒ R-type instructions set. Eg. sub $s1, $s3, $s2
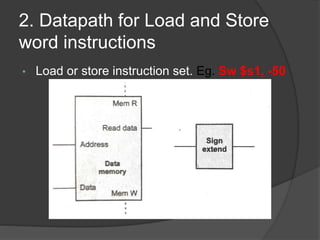
- 10. 2. Datapath for Load and Store word instructions âĒ Load or store instruction set. Eg. Sw $s1, -50
- 11. 3. Datapath for Branch instructions âĒ Conditional statement. Eg. beq $s1, $s2, 25
- 12. 4. Creating a Single Datapath âĒ To execute a instructions at least one clock cycle is required.
- 13. Control implementation Scheme âĒ Designing the main control unit âĒ The ALU control âĒ Operation of the Datapath âĒ Datapath for an R-type instruction âĒ Datapath for Load word instruction âĒ Datapath for Branch-on-equal instruction
- 15. ï ALU control inputs based on the 2 bits ALUOp control and the 6 bits function code.
- 16. Designing the main control unit
- 17. Datapath with all necessary multiplexers and all control unit
- 18. Operation of the Datapath
- 19. Datapath for Load word instruction
- 20. Pipeline âĒ Pipelining is an implementation technique in which multiple instructions are overlapped in execution. Used to increase the speed and performance of the processor. âĒ Two stage methods available for pipeline: 1. Four stage 2. Six Stage
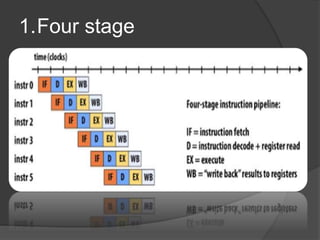
- 21. 1.Four stage
- 22. 2. Six stage
- 23. 2. Six stage
- 24. Pipeline Stages in the MIPS 1. Fetch instruction 2. Decode and read register simultaneously 3. Execute the operation 4. Access an operand in data memory 5. Write result to register/memory
- 25. Pipeline Hazards âĒ A hazards is a condition that prevents an instruction in the pipeline from executing its next scheduled pipeline stage. âĒ Any reason that cause the pipeline to stall is called a hazard. Types of hazards: 1. Structural hazards When two instructions require the use of a given hardware resource at the same time. 2. Data hazards Instructions depends on result of prior computation which is not ready (computed or stored) yet.
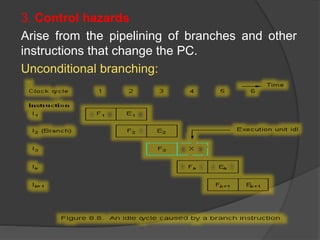
- 26. 3. Control hazards Arise from the pipelining of branches and other instructions that change the PC. Unconditional branching:
- 27. Branch Penalty: Time lost due to branch instruction is known as branch penalty. Factor effecting branch penalty: ïIt is more for complex instructions ïFor a longer pipeline, branch penalty is more.
- 28. Pipeline Performance âĒ Clock cycle â time period for the clock cycle it is necessary to consider stage delay and interstage delay. Time ï (cycle)
- 29. Pipeline Performance Total time required is, Tm = [m + (n-1)]t Speedup factor: non-pipelined processor is defined as, Sm = (nm / m +(n-1) ) Where, n = segment/stages M = no. of ins
- 30. Pipeline Performance Efficiency: The ratio of speedup factor and the number of stages in the pipeline. Em = n / m+(n-1) Performance/Cost Ratio (PCR): Total cost of pipeline is estimated by c + mh, where PCR = 1 / ((t/ m+d)(c+mh)
- 31. Pipeline Datapath and control Pipeline processor consists of a sequence of data processing circuits, called elements, stages or segments Each stage consists of two major blocks: ïMultiword input register ïDatapath circuit R 1 C1 R2 C2 R3 C3âĶâĶRm Cm CONTROL UNIT Data in Data out
- 32. âĒ Implementation of Two stage instruction pipelining Breaks a single instruction into two parts: 1. A fetch stage s1 2. An execute stage s2
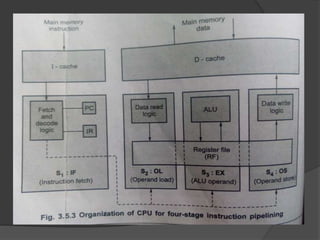
- 33. 4 stage Instruction pipelining with CPU âĒ CPU is directly connected to cache memory and it is represented as I-cache and D-cache. âĒ This permits both instruction and memory data to be accessed with same clock cycle. 1. IF: instruction fetch and decode using I cache.(S1) 2. OL: operand loading from D-cache to register file.(S2) 3. EX: data processing using the ALU and register file.(S3) 4. OS: operand storing to the D-cache from register file.(S4)
- 35. Implementation of MIPS instruction pipeline âĒ Five stage pipeline 1. IF : Instruction Fetch S1 2. ID : Instruction Decode S2 3. EX : Execution S3 4. MEM : Data memory access S4 5. WB : Write Back S5
- 36. Implementation of MIPS instruction pipeline
- 37. Pipeline Control âĒ Signle-cycle datapath. The datapath uses the control logic for PC source, register destination number and ALU control. ï Control Lines into 5 groups. 1. Instruction Fetch: Control signals to read instruction and write PC 2. Instruction decode/register file read: control is not required to this pipeline 3. Execution/address calculation: Control signals are Regdst, ALUop or src. 4. Memory access: Signals are Branch,Memread and Memwrite. 5. Write-back : Mem to reg and RegWrite
- 39. Handling data hazards Operand forwarding âĒ A simple h/w techniques which can handle data hazard is called Operand Forwarding or register by passing. âĒ ALU results are fed back as ALU i/ps. âĒ The forwarding logic detects the previous ALU operation has the operand for current instruction, it forwards ALU o/p instead of register file. âĒ Ex: add $s1,$s2,$s3 mul $s4,$s1,$s5 ï mul $s4, o/p of s2+s3,$s5
- 41. Modified datapath in MIPS implementation
- 42. Handling data hazards in software âĒ S/W detects the data dependencies. âĒ Necessary delay b/w 2 instructions by inserting NOP (no-operation) instructions as follows: I1 : MUL R2, R3, R4 NOP NOP ADD R4, R5, R6 Disadvantages of adding NOP instructions: âĒ It leads to larger code size. âĒ It has several H/W implementation.
- 43. Side Effects âĒ When destination register of the current instruction is the source register of the next instruction there is a data dependency. It is explicit and it is identified by register name. âĒ The addition of these 2 numbers may be accomplished as follows: ADD R1,R3 ADD with carry R2, R4 R2<- [R2]+[R4]+Carry
- 44. Handling Control Hazards Instruction queue and prefetching âĒ Fetch unit fetches and stores instruction queue. âĒ A separate unit called Dispatch unit. âĒ If instruction queue failed to give the instruction to dispatch unit, fetch instruction automatically transfer the instruction for decoding. âĒ Fetch unit always keep the queue full.
- 45. Instruction queue and prefetching
- 46. Instruction queue and prefetching Instruction queue during branch instruction
- 47. Instruction queue and prefetching Branch Folding âĒ Fetch unit executes branch instruction concurrently with the execution of other instruction is known as branch folding. âĒ Branch folding occurs only if there exists at least one instruction in the queue other than the branch instruction.
- 48. Approaches to Deal âĒ The conditional branching is a major factor that affects the performance of instruction pipelining. 1. Multiple streams 2. Prefetch branch target 3. Loop buffer 4. Branch prediction
- 49. 1.Multiple streams - Two stream to Store fetched instruction. 2.Prefetch branch target - Prefetched the target instruction if its recognized 3.Loop buffer - Small/Temporary memory to store recently prefetched instructions
- 50. 4. Branch prediction - To check whether a branch will be valid or not valid. These techniques reduce the branch penalty. Techniques: âĒpredict never taken, âĒpredict always taken, âĒpredict by opcode, âĒtaken and not taken switch, âĒbranch history table
- 51. Branch prediction strategies Static branch strategy: branch can be predicted based on branch code type. Dynamic branch strategy : uses recent branch history during the program execution to predict whether branch should be taken when next time occurs.
- 52. Branch prediction strategies The recent branch information includes branch prediction statistics such as: T â Taken N â Not taken NN - Last two branches not taken NT - Not branch taken and previous taken TT - Both last two branch taken TN - Last branch taken and Previous not taken
- 53. Branch target buffer âĒ The recent branch information is stored in the buffer called BTB. âĒ Stores branch information for prediction
- 54. A typical state diagram used in dynamic branch prediction
- 55. Exception âĒ One of the difficult parts of control is to implement exceptions and interrupts- events other than branches or jumps. Handling exceptions in the MIPS Architecture Types of Exception: 1. Execution of an undefined instruction 2. Arithmetic overflow in the instruction add $1,$2,$2.
- 56. Methods to communicate exceptions 1. Status register method The MIPS architecture uses a status register, which holds a field that indicates the reason for the exception. 2. Vectored interrupts method Vector interrupts are used. The address to which control is transferred is determined by the cause of the exception.
- 57. Exception in a pipelined Implementation ï Multiple exception can occur in a single clock cycle. 1. Imprecise Interrupts or Imprecise exception 2. Precise Interrupts or precise exception
Editor's Notes
- #31: Efficiency - The ratio of the output to the input of any system
- #32: Efficiency - The ratio of the output to the input of any system
- #33: Efficiency - The ratio of the output to the input of any system
- #34: Efficiency - The ratio of the output to the input of any system
- #36: Efficiency - The ratio of the output to the input of any system
- #37: Efficiency - The ratio of the output to the input of any system
- #38: Efficiency - The ratio of the output to the input of any system
- #39: Efficiency - The ratio of the output to the input of any system
- #40: Efficiency - The ratio of the output to the input of any system
- #41: Efficiency - The ratio of the output to the input of any system
- #42: Efficiency - The ratio of the output to the input of any system
- #43: Efficiency - The ratio of the output to the input of any system
- #44: Efficiency - The ratio of the output to the input of any system
- #45: Efficiency - The ratio of the output to the input of any system
- #46: Efficiency - The ratio of the output to the input of any system
- #47: Efficiency - The ratio of the output to the input of any system
- #48: Efficiency - The ratio of the output to the input of any system
- #49: Efficiency - The ratio of the output to the input of any system
- #50: Efficiency - The ratio of the output to the input of any system
- #51: Efficiency - The ratio of the output to the input of any system
- #52: Efficiency - The ratio of the output to the input of any system
- #53: Efficiency - The ratio of the output to the input of any system
- #54: Efficiency - The ratio of the output to the input of any system
- #55: Efficiency - The ratio of the output to the input of any system