¯ðý¿°Î°µÝÞûÐú¢£Ã
Download as PPTX, PDF3 likes1,822 views

ËÙËÐËûËñËÍÊùÊáÊÊÊóÊöûÐú¢£ÃæòêüÊúÊ¿

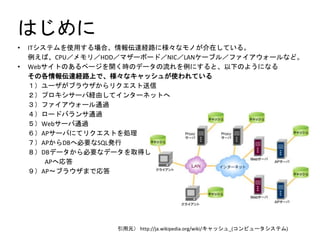






![ËæËÚ˯ËÕËÁÊúò¿ÊÎËÙËÐËûËñËÍÈ¢
? ËæËÚ˯ËÕËÁÈ´Ë°ˋ`ËèÈˋèüÊöËÚË¡ËûË₤èüÊúÊãËÙËÐËûËñËÍÊ·ØãæRÊ¿ÊŠÊà
¡ÔÅåáÉ
? ¤
gÊòjavascriptÊöâ»
[ÔWÊÊ]
for (i = 0; i < elements.length; i++) { ... }
[ùìÊÊ]
for (i = 0, len = elements.length; i < len; i++) { ... }
Ê°ÊöÔ`ÊÊÀÂÊÿʨÊõÊßʿʨȢ](https://image.slidesharecdn.com/cache-170418020756/85/Cache-12-320.jpg)

































More Related Content
What's hot (20)
Viewers also liked (7)

![[20171031 db tech salon] Ë₤ËÕËÎËèØóÅÅÊ·ËìËàËòËÁÊúÈÀÈ¢ by øõò§£ÃèÓËÊ˵ËçËÊËàËóË₤ËöËÚË¡ˋ` èÙ û₤¥o](https://cdn.slidesharecdn.com/ss_thumbnails/20171031cloudmigrationinvietnam-171106090240-thumbnail.jpg?width=560&fit=bounds)



Similar to ¯ðý¿°Î°µÝÞûÐú¢£Ã (20)

![[Basic 7] OS Êö£ªÝƒ / ¡ŸÊõßzÊÔ / ËñË¿ËóËÁ Ë°ˋ`ËŠ / ËÃËãËõ¿ÉâÚ](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=560&fit=bounds)


![[db tech showcase Tokyo 2017] A15: ËšËæËõËÝˋ`ËñËÓ˵ʷò¿ÆûÊñÊ¢Ëúˋ`Ë¢ñøö—£ªÝP¤BÊöËÙËãÈ´òôâ»Èˋby øõò§£ÃèÓËÊ˵ËçËÊËàËó...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=560&fit=bounds)















More from Shinji Miyazato (10)










¯ðý¿°Î°µÝÞûÐú¢£Ã
- 2. ? ITËñË¿ËóËÁÊ·ò¿ÆûÊ¿ÊŠ—¤üÀÂúÕµ£Ô_§UôñÊùÀˋÊòËãËöʘ§ÕåÖÊñÊóÊÊÊŠÀÈ â»Ê´ÊÅÀÂCPUÈ₤ËÃËãËõÈ₤HDDÈ₤ËßËÑˋ`ËÉˋ`ËèÈ₤NICÈ₤LANËÝˋ`ËøËŠÈ₤ËíËÀËÊËÂËÎËˋˋ`ËŠÊòÊèÀÈ ? WebËçËÊËàÊöÊÂÊŠËÖˋ`Ë¡Ê·Õ_Ê₤rÊöËúˋ`Ë¢Êöê¼ÊšÊ·â»ÊùÊ¿ÊŠÊàÀÂØåüôÊöÊÒÊÎÊùÊòÊŠ ʧÊö¡¼úÕµ£Ô_§UôñèüÊúÀÂÀˋÊòËÙËÐËûËñËÍʘò¿ÊÿÊšÊóÊÊÊŠ ÈÝÈˋËÌˋ`ËÑʘËøËÕËÎËÑʨÊÕËõË₤Ë´Ë¿ËàùëÅé ÈýÈˋËæËÚËÙËñËçˋ`ËŧUÆèÊñÊóËÊ˵ˢˋ`ËëËûËàÊÄ È°ÈˋËíËÀËÊËÂËÎËˋˋ`ËŠë´Ô^ ÈÇÈˋËÚˋ`ËèËÅËÕ˵Ëçë´Ô^ ÈçÈˋWebËçˋ`ËÅë´Ô^ ÈÑÈˋAPËçˋ`ËÅÊùÊóËõË₤Ë´Ë¿ËàÊ·IâÚ ÈñÈˋAPʨÊÕDBÊÄÝÄ؈ÊòSQL¯kÅÅ È¡ÈˋDBËúˋ`ˢʨÊÕÝÄ؈ÊòËúˋ`ˢʷàÀçûÊñ APÊÄõÇÞ È¿ÈˋAPÀ¨ËøËÕËÎËÑÊßÊúõÇÞ ÊüÊ¡ÊÃÊù Ø»ÆûåˆÈˋ °µ°ì°ìÝÒ://ôÃý¿.ñèƒÝ¯šƒÝÝÒÝޣ̓Ýý¿.Çú¯ªýç/ñèƒÝ¯šƒÝ/ËÙËÐËûËñËÍ°Í(˰˵ËåËÍˋ`Ë¢ËñË¿ËóËÁ)
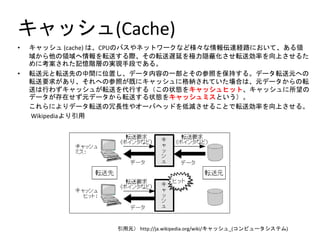
- 3. ËÙËÐËûËñËÍ(Cache) ? ËÙËÐËûËñËÍ (cache) ÊüÀÂCPUÊöËÅË¿ÊðËëËûËàËÿˋ`Ë₤ÊòÊèÀˋÊòúÕµ£Ô_§UôñÊùʈÊÊÊóÀÂÊÂÊŠŸI ƷʨÊÕù«ÊöŸIÆ·ÊÄúյʷÉùëÊ¿ÊŠŠHÀÂʧÊöÉùëÔWîÆÊ·OêΊLÝö£₤ÊçÊ£Éùë¢ôòÊ·ü·èüÊçʣʊʢ ÊÃÊù¢¥¯¡ÊçʚʢƊAÆÊög˜FòøÑöÊúÊÂÊŠÀÈ ? ÉùëåˆÊàÉùëüàÊöøÅÕgÊùö£øûÊñÀÂËúˋ`Ë¢áÖàïÊöØ£ý¢ÊàʧÊöýöííÊ·ÝÈ°øÊ¿ÊŠÀÈËúˋ`Ë¢ÉùëåˆÊÄÊö Éùë؈úµÊ˜ÊÂÊõÀÂʧʚÊÄÊöýöííʘ¥àÊùËÙËÐËûËñËÍÊù¡þ¥{ÊçÊšÊóÊÊÊ¢—¤üÊüÀÂåˆËúˋ`ˢʨÊÕÊöÉ ùëÊüÅÅÊÿʤËÙËÐËûËñËÍʘÉùëʷǺÅÅÊ¿ÊŠÈ´Ê°ÊöæÇBÊ·ËÙËÐËûËñËÍËØËûËàÀÂËÙËÐËûËñËÍÊùùªë«Êö Ëúˋ`ˢʘÇÌåÖʣʤåˆËúˋ`ˢʨÊÕÉùëÊ¿ÊŠæÇBÊ·ËÙËÐËûËñËÍËÔË¿ÊàÊÊÊÎÈˋÀÈ Ê°ÊšÊÕÊùÊÒÊõËúˋ`Ë¢ÉùëÊöàÔÕLÅåÊðˈˋ`ËÅËÄËûËèÊ·çëpÊçʣʊʰÊàÊúÉùë¢ôòÊ·ü·èüÊçʣʊÀÈ WikipediaÊÒÊõØ»Æû Ø»ÆûåˆÈˋ °µ°ì°ìÝÒ://ôÃý¿.ñèƒÝ¯šƒÝÝÒÝޣ̓Ýý¿.Çú¯ªýç/ñèƒÝ¯šƒÝ/ËÙËÐËûËñËÍ°Í(˰˵ËåËÍˋ`Ë¢ËñË¿ËóËÁ)
- 4. ? Ê°Ê°ÊúʈÊçÊÕÊÊÈÀ ËúË¿Ë₤èüÊúÊöæ¼IÊúâ»Ê´ÊŠÊàÀÈ ÈûÈÅÈí??? À¡òùòô?æ¼IÊ·ÊñÊóÊŠàùÀ¿ ´C ê¥ÊÊCPUÊàÊüÀÂòùòô?æ¼IÊ·ÊñÊóÊŠàùÊöáÉêÎʘ¡ÔÊÊÊàÊÊÊÎÊ°ÊàÀÈ ËÃËãËõ???À¡ËúË¿Ë₤À¿ ´C ê¥ÊÊËÃËãËõÊàÊüÀÂËúË¿Ë₤ʘÖÊ₤Êóæ¼IʘÊüʨÊèÊŠÊàÊÊÊÎÊ°ÊàÀÈ ÈàÈáÈá???À¡ËúË¿Ë₤ÊöØ»ÊÙ°—ÊñÀ¿ ´C ê¥ÊÊËüˋ`ËèËúËÈË¿Ë₤ÊàÊüÀÂØ»ÊÙ°—ÊñʘǵÊÙÊ₤ÊóÀÂæ¼ÊûÊ¢öÿʘʢÊ₤ÊçʵàŠÊŠÊàÊÊÊÎÊ°Êà ÀÈ Ø»ÆûåˆÈˋ http://enjoy.sso.biglobe.ne.jp/archives/zukai_pc/ ÊáÊßÊõÀÂÀ¡áÉêÎʘ¡ÔÊÊàùʘÀÂÖÊÊËúË¿ Ë₤Êúæ¼IÊ¿ÊšÊÅòùòôʘÊàÊóÊãÊüʨÊèÊõ ÀÂʧÊö§Y¿«ÊàÊñÊóê¥ÊÊÊãÊöÊ·Ê¢Ê₤Êçʵ æ¼ÊŠÊ°ÊàʘÊúÊÙÊóÀÂÊçÊÕÊùØ»ÊÙ°—Êñʘ ǵÊÙÊÝÊšÊÅÀÂÊèʵÊèʵå֚ʷÝÈ¿ÉÊñÊó ʈÊ₤Ê°ÊàʘÊúÊÙÊŠÀ¿ÊàÊÊÊÎÊ°ÊàÀÈ ÈûÈÅÈíÈ₤ËÃËãËõÈ₤ÈàÈáÈáÊöÔ`ÊÊ
- 6. ÊÊÊÚÊÊÊÚÊòËÙËÐËûËñËÍ ? HWʘäÿˋÊ¿ÊŠËÙËÐËûËñËÍ ´C CPUÀ¨ËÃËãËõÕg ? ÈäÈÝËÙËÐËûËñËÍÀÂÈäÈýËÙËÐËûËñËÍÀÂÈäÈ°ËÙËÐËûËñËÍ ? OSʘäÿˋÊ¿ÊŠËÙËÐËûËñËÍ ´C HDDÀ¨ËÃËãËõÕg ? ËÖˋ`Ë¡ËÙËÐËûËñËÍÈ´ËúËÈË¿Ë₤ËÙËÐËûËñËÍÈˋ ? à¨ÊóÊöËæËÚ˯ËÕËÁÊüÀÂËÃËãËõèüÊúgÅÅÊçʚʊȴʰʚÊãØ£ñNÊöËÙËÐËûËñËÍÈˋ ? SWËšËÊËðÊúäÿˋÊ¿ÊŠËÙËÐËûËñËÍ ´C WebËøËÕËÎËÑ ? ËøËÕËÎËÑËÙËÐËûËñËÍ ´C KeyValueË¿ËàËÂüçËÙËÐËûËñËÍSW ? Memcached ? VarnishCache ´C Ëúˋ`Ë¢Ëìˋ`Ë¿È´ØåüôÊüOracleÊöû«°óÊâʘÀÂù«DBîuóñÊúÊãë˜ÊòCáÉÊ·°øÊáÈˋ ? ËÕËÊËøËÕËõ?ËÙËÐËûËñËÍ ? ËúËÈË₤ËñËÓËòËõ?ËÙËÐËûËñËÍ ? ËÅËûËíËÀ?ËÙËÐËûËñËÍ
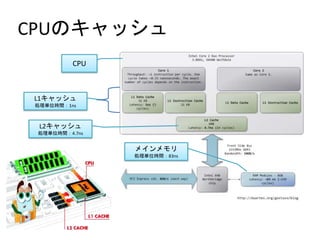
- 7. CPUÊöËÙËÐËûËñËÍ ? CPUÊüÀÂËÙËÐËûËñËÍËÃËãËõÈ´ø¼Ææ¯øûÊàÊüeËãËöÈˋÊशÊÅʚʊËÃËãËõÊ·ò¿ÆûÊñÊóÀ IâÚÊö¡Ôùì£₤Ê·ÚÊûÊóÊÊÊŠ ? ËÙËÐËûËñËÍËÃËãËõÊùÊüÀ¡ÔùìÊòÚÈ´ÈÎàïê¢Ê˜ÅÀÊçÊÊÚÈˋÊùL1ËÙËÐËûËñËÍÀÂL2ËÙËÐËûËñ ËÍÀÂL3ËÙËÐËûËñËÍÈ´ÀªÈˋʘÊÂÊŠÀÈ ÀªL3ÊüÊòÊÊ—¤üÊãÊÂÊŠ ? L1ËÙËÐËûËñËÍ È´1ÇöËÙËÐËûËñËÍÈˋ ´C ËÙËÐËûËñËÍËÃËãËõÊüËÃËÊ˵ËÃËãËõ(RAM)ÊÒÊõÊã¡ÔùìÊùíiÊÔ½ÊÙÊúÊÙʊʘ(»¡þʘ¡ÔÊÊÊ¢ÊÃ)ÇŸïdàïê¢Êöèì ÊòÊÊËÃËãËõæ¯øûÊúÀÂøݧ■Êùò¿ÆûÊñÊ¢Ëúˋ`Ë¢Êðò¿ÆûŸlÑàÊö¡ÔÊÊËúˋ`Ë¢ÊòÊèÊ·¡þ¥{Ê¿ÊŠÊöÊùò¿ÊÿʚʊÀÈ ´C æŸüàÊúËúˋ`Ë¢ÊöíiÊÔ½ÊÙʘÅÅÊÿʚʊÊãÊöÊ·1ÇöËÙËÐËûËñËÍÊàÊÊÊÎÀÈ ? L2ËÙËÐËûËñËÍ È´2ÇöËÙËÐËûËñËÍÈˋ ´C 2ÇöËÙËÐËûËñËÍÊü1ÇöËÙËÐËûËñËÍÊÒÊõÊãçëùìÊâʘǵàïê¢ÊöËÃËãËõæ¯øûÊúÀÂ1ÇöËÙËÐËûËñËÍÊù ÏÊßÊõÊÙÊÕÊò ÊÊËúˋ`Ë¢ÊöòÉÊÝûµÊàÊòÊŠÀÈ ´C 2ÇöËÙËÐËûËñËÍʨÊÕÊãØÓʚʢËúˋ`Ë¢ÊüÀÂ3ÇöËÙËÐËûËñËÍʘÊÂÊŠ—¤üÊü3ÇöËÙËÐËûËñËÍÊùÀÂÊòÊÊ—¤üÊüËÃËÊ ËµËÃËãËõÊù¡þ¥{ÊçʚʊÀÈ Ø»ÆûåˆÈˋ http://e-words.jp/w/1E6ACA1E382ADE383A3E38383E382B7E383A5.html
- 9. HDDÊöËÙËÐËûËñËÍ ? HDDÊüÀÂËÃËÊ˵ËÃËãËõÊàÝàÊìÊóÊãI/O(Read/Write)ÅåáÉʘ¡þÑöÊùÔWÊÊÈÀ ? HDDÊöI/OÇ»ÊêÊ·pÊÕÊ¿Ê¢ÊÃÊùÀÂLinux (ÊùüßÊÕʤù«Êö OS ÊãʧÊÎÊúʿʘ) ÊùÊüËúËÈË¿Ë₤Êö áÖàïÊ·Ø£ÑàíiʵÊâÊÕʧʚʷ˨ˋ`ËëˊʘËÙËÐËûËñËÍÊñÊóÀÂѱÑàá¢Øå§çÊüËÃËãËõʨÊÕíiÊÁ C = ËÖˋ`Ë¡ËÙËÐËûËñËÍʘÊÂÊŠÀÈ ? gîï # dd if=/dev/urandom of=/tmp/test bs=1M count=100 ?100MBÊöËíËÀËÊËŠÊ·æ¼°è # sync;echo 3 > /proc/sys/vm/drop_caches ?ËÖˋ`Ë¡ËÙËÐËûËñËÍÊ·Ë₤ËõË # time cat /tmp/test > /dev/null ?ËÖˋ`Ë¡ËÙËÐËûËñËÍÊ·Ë₤ËõËÂÊ¿ÊŠú¯ÃÃÊú100MBíiÊÔ°—ÊñrÕgÝàï^ÈÀ HDDÈ₤ËÃËãËõÊöÅåáÉÊùÊÒʊʘÀÂËúˋ`Ë¢ÉùëùìÑà100ÝÑ°äÑàÀ ä§ù¼IâÚÊü10ë·ÝÑÀ¨100ë·ÝÑ°äÑàÊöýŸÊ˜ÊÂÊŠ
- 10. CPUÀÂËÃËãËõÀÂHDDÊöËšËÊËó˵Ëñ ? ¡¼ËšËÊËó˵ËñʷˈËíËÈË¿ÊöÝàèÊúÊÔÊóÊÔÊŠÊà??? L1Ȥ£ºÊ¨ÊեʷÈÝûÑÊàÊŠÈ´3ûŠÈˋ L2Ȥ݃éÿʨÊÕ݃ʷàÀÊõ°—Ê¿È´14ûŠÈˋ ËÃËÊ˵ËÃËãËõȤý¢öïÊ·°—ÊóŠAüôÊúʈúæÆÊ·ìIÊÎÈ´4ñøÈˋ Ëüˋ`ËèËúËÈË¿Ë₤ȤˈËíËÈË¿Ê·°—Êóòâ§ÓñéâùÊöôûÊù°—ÊŠÈ´1áõ3ʨåôÈˋ ʰʚʯÊÕÊÊÊöýŸÊ˜ÊÂÊŠÀÂÊàÊÊÊÎâ»ÀÈ gŠHÊùÊüÀÂnanoûŠÀ¨microûŠËšËìËŠÊöåÀÈ ÀªnanoûŠ???10|ñøÊö1ûŠ Ëüˋ`ËèËúËÈË¿Ë₤ʘÀ¯¥ÊÔWÀÝÊúÊÂÊŠÊ°ÊàʘÊÿʨʊÀÈ òâÊöøÅÊö À¯øÄÊÊËñË¿ËóËÁÈ´WebËçËÊËàÈˋÀÝ Êöǵ¯ŠÊüÀÂë£ÊÙåÊÃÊŠÊà ËúËÈË¿Ë₤IOʘÔWÊÊÊ°ÊàÊùåÙطʘÊÂÊŠÀÈ Ø»ÆûåˆÈˋ http://vwxyz.hateblo.jp/entry/20101221/1292923352
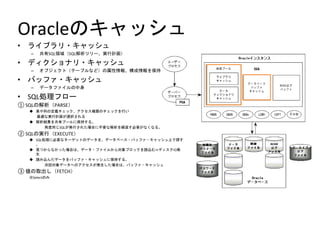
- 11. OracleÊöËÙËÐËûËñËÍ ? ËÕËÊËøËÕËõ?ËÙËÐËûËñËÍ ´C ¿ýÆÅSQLŸIÆ·È´SQL§ãö—ËáËõˋ`ÀÂgÅÅÆ£ÙÈˋ ? ËúËÈË₤ËñËÓËòËõ?ËÙËÐËûËñËÍ ´C ˈËøË¡ËÏË₤ËàÈ´Ëóˋ`ËøËŠÊòÊèÈˋÊöò¶ÅåúÕµÀ°èúյʷÝÈ°ø ? ËÅËûËíËÀ?ËÙËÐËûËñËÍ ´C Ëúˋ`Ë¢ËíËÀËÊËŠÊöøÅèÚ ? SQLIâÚËíËÚˋ` Âì SQLÊö§ãö—È´PARSEÈˋ À¶ ÝÚÊðêÅÊöÑ´êxËêËÏËûË₤ÀÂËÂË₤ˣ˿ÄüßÊöËêËÏËûË₤Ê·ÅÅÊÊ æŸÔmÊògÅÅÆ£ÙʘÔxkÊçʚʊ À¶ §ãö—§Y¿«Ê·¿ýÆÅËæˋ`ËŠÊùÝÈ°øÊ¿ÊŠÀÈ åìÑàë˜Ê¡SQLʘ¯kÅÅÊçʚʢ—¤üÊùý£ØˆÊò§ãö—Ê·âRñçÊ¿ÝÄ؈ʘÊòÊ₤ÊòÊŠÀÈ ÂÖ SQLÊögÅÅÈ´EXECUTEÈˋ À¶ SQLIâÚÊùÝÄ؈ÊòË¢ˋ`ËýËûËàÊöËúˋ`ˢʷÀÂËúˋ`Ë¢Ëìˋ`Ë¿?ËÅËûËíËÀ?ËÙËÐËûËñËÍèüÊúä§Ê¿ ÀÈ À¶ ØÊáʨÊÕÊòʨÊûÊ¢—¤üÊüÀÂËúˋ`Ë¢?ËíËÀËÊˊʨÊÕüµËøËÚËûË₤Ê·íißzÊÁ?ËúËÈË¿Ë₤IO¯k èº À¶ íiÊÔßzʵÊâËúˋ`ˢʷËÅËûËíËÀ?ËÙËÐËûËñËÍÊùÝÈ°øÊ¿ÊŠÀÈ Çö£ÄüµËúˋ`Ë¢ÊÄÊöËÂË₤ˣ˿ʘ¯kèºÊñÊ¢—¤üÊüÀÂËÅËûËíËÀ?ËÙËÐËûËñËÍ ÂÜ ÊöàÀ°—ÊñÈ´FETCHÈˋ ÀªSelectÊöÊÔ
- 12. ËæËÚ˯ËÕËÁÊúò¿ÊÎËÙËÐËûËñËÍÈ¢ ? ËæËÚ˯ËÕËÁÈ´Ë°ˋ`ËèÈˋèüÊöËÚË¡ËûË₤èüÊúÊãËÙËÐËûËñËÍÊ·ØãæRÊ¿ÊŠÊà ¡ÔÅåáÉ ? ¤ gÊòjavascriptÊöâ» [ÔWÊÊ] for (i = 0; i < elements.length; i++) { ... } [ùìÊÊ] for (i = 0, len = elements.length; i < len; i++) { ... } Ê°ÊöÔ`ÊÊÀÂÊÿʨÊõÊßʿʨȢ
- 13. ËÙËÐËûËñËÍËØËûËàôòÝOØÊöøÄ؈Åå ? ËÙËÐËûËñËÍËÔ˿ʘÑÁ¯kÊ¿ÊŠÀÂÊàÊÊÊÎÊ°ÊàÊüÅåáÉêÆ£₤ÊöÝÚÊš ´C ËÃËãËõý£æÐÊðÀÂåOѴʘÔmúÅÊúÊüÊòÊÊ¢èáÉÅåʘÊÂÊŠ ? LinuxËçˋ`ËÅÊö—¤ü ´C iowaitÊ·ÝOØ ? ËÙËÐËûËñËÍCáÉÊ·°øÊáSW ´C OracleÊâÊàÀÂËÅËûËíËÀ?ËÙËÐËûËñËÍÀÂËÕËÊËøËÕËõ?ËÙËÐËûËñËÍÀÂËúËÈË₤ËñËÓËòËõ? ËÙËÐËûËñËÍÊöËØËûËàôòÊ·ÝOØÀÈ99%Øåèüʘë«ÊßÊñÊÊÀÈ95%ØåüôÊüŸ}ÊÂÊõ ´C VarnishCacheÊðmemcachedÊòÊèÊãËÙËÐËûËñËÍËØËûËàôòÊ·ÝOØÊñ ËÔ˿ʘ¥ÆAü·ÊúÊÂÊšÊÅËÙËÐËûËñËÍË¿ËàËšˋ`Ë¡ÀÂËÙËÐËûËñËÍËÊ˵˿ˢ˵˿ÊöåO Ê·òÆÊ¿ÊŠÝÄ؈ʘÊÂÊŠ
- 14. ËÙËÐËûËñËÍʘÊòÊÊÊàÊèÊÎÊòʊʨ ? ˈˋ`ËŠËÊ˵Ëÿ˵ÊúINSUITEʘÆÊ₤òå^Ùhƒ°ÊúgîïÊñÊóÊÔÊßÊ¿ ÂìËøËÕËÎËÑËÙËÐËûËñËÍʘÊòÊÊÊàÊèÊÎÊòÊŠÈ¢ ´C FiddlerÊàÊÊÊÎËáˋ`ËŠÊúÀÂøóçáÊùËÙËÐËûËñËÍÊ·o¢£₤ÊñÊóÊÔÊŠÊàÀÈ ÀÈ ÂÖËçˋ`ËÅèüÊöËÖˋ`Ë¡ËÙËÐËûËñËÍÈÎOracleËÙËÐËûËñËÍʘÊòÊÊ Êà ÊèÊÎÊòÊŠÈ¢ ´C OracleÊ·åìóÞÆÊñÊóËÙËÐËûËñËÍÊ·Ë₤ËõËÂÊñÀÂʨÊáOSèüÊöËÖˋ`Ë¡ËÙËÐ ËûËñËÍÊ·Ë₤ËõËÂÊ¿ÊŠÊàÀÈÀÈ
- 15. ʈÊÿÊõ