Cassandra Table Modeling - an alternate approach
ŌĆóDownload as PPTX, PDFŌĆó
1 likeŌĆó388 views

A new approach to model existing relational data in Cassandra to make it easy-to-search, easy-to-modify









Cassandra Table Modeling - an alternate approach
- 1. Devopam Mittra Transforming RDBMS data model to Apache Cassandra
- 2. ŌĆó Data modeling is pivotal for a successful Data Access Layer in Cassandra. ŌĆó Unlike a traditional RDBMS table, a ŌĆśColumn FamilyŌĆÖ aka Cassandra table has to be modeled based on the usage (and not the storage). ŌĆó ŌĆśSearchabilityŌĆÖ of information becomes a key driving factor in Cassandra data modeling. ŌĆó Schema / structural changes have a huge effort and time impact. ’é¦ Storing structured data in Cassandra typically evades attention and detail as modelers prefer to do an as-is structural copy from the source. ’é¦ This approach works well to suit structured query analytics and not beyond, defeating the basic purpose of self-service analytics. ’é¦ Any changes to the structure / model leads to redoing modeling effort including associated testing and validation ’ā╝ Leveraging ŌĆśCollectionŌĆÖ type to store collated native datatype elements and only retain primary key attributes in main table structure (easier said than done , so letŌĆÖs take a closer look into the approachŌĆ”)
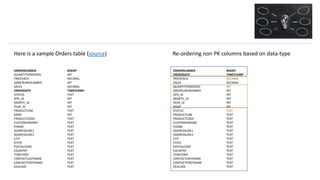
- 3. Here is a sample Orders table (source) Re-ordering non PK columns based on data-type ORDERNUMBER QUANTITYORDERED PRICEEACH ORDERLINENUMBER SALES ORDERDATE STATUS QTR_ID MONTH_ID YEAR_ID PRODUCTLINE MSRP PRODUCTCODE CUSTOMERNAME PHONE ADDRESSLINE1 ADDRESSLINE2 CITY STATE POSTALCODE COUNTRY TERRITORY CONTACTLASTNAME CONTACTFIRSTNAME DEALSIZE BIGINT INT DECIMAL INT DECIMAL TIMESTAMP TEXT INT INT INT TEXT INT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT ORDERNUMBER ORDERDATE PRICEEACH SALES QUANTITYORDERED ORDERLINENUMBER QTR_ID MONTH_ID YEAR_ID MSRP STATUS PRODUCTLINE PRODUCTCODE CUSTOMERNAME PHONE ADDRESSLINE1 ADDRESSLINE2 CITY STATE POSTALCODE COUNTRY TERRITORY CONTACTLASTNAME CONTACTFIRSTNAME DEALSIZE BIGINT TIMESTAMP DECIMAL DECIMAL INT INT INT INT INT INT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT
- 4. CREATE TABLE DDL - Traditional approach CREATE TABLE DDL ŌĆō Proposed Alternate approach CREATE TABLE IF NOT EXISTS etl_schema.orders ( ordernumber BIGINT, quantityordered BIGINT, priceeach DECIMAL, orderlinenumber INT, sales DECIMAL, orderdate TIMESTAMP, status TEXT, qtr_id INT, month_id INT, year_id INT, productline TEXT, msrp INT, productcode TEXT, customername TEXT, phone TEXT, addressline1 TEXT, addressline2 TEXT, city TEXT, state TEXT, postalcode TEXT, country TEXT, territory TEXT, contactlastname TEXT, contactfirstname TEXT, dealsize TEXT, PRIMARY KEY (ordernumber,orderdate) ) WITH CACHING = { 'keys' : 'ALL', 'rows_per_partition' : 200 } AND CDC = TRUE AND COMMENT = 'Orders TableŌĆÖ AND CLUSTERING ORDER BY (orderdate DESC) AND COMPACTION = {'class': 'SizeTieredCompactionStrategy','tombstone_compaction_interval':1800} AND GC_GRACE_SECONDS = 3600; CREATE TABLE IF NOT EXISTS etl_schema.orders_new ( ordernumber BIGINT, orderdate TIMESTAMP, decimal_map MAP <TEXT, DECIMAL>, tinyint_map MAP <TEXT, INT>, text_map MAP <TEXT, TEXT>, PRIMARY KEY (ordernumber,orderdate) ) WITH caching = { 'keys' : 'ALL', 'rows_per_partition' : 200 } AND cdc = TRUE AND comment = 'Orders Key Value Table' AND CLUSTERING ORDER BY (ORDERDATE DESC) AND COMPACTION = {'class': 'SizeTieredCompactionStrategy','tombstone_compaction_interval':1800} AND gc_grace_seconds = 3600; CREATE INDEX idx_orders_new_1 ON orders_new (ENTRIES(decimal_map)); CREATE INDEX idx_orders_new_2 ON orders_new (ENTRIES(int_map)); CREATE INDEX idx_orders_new_3 ON orders_new (ENTRIES(text_map)); Note: DonŌĆÖt use FROZEN maps else structural modification to existing data canŌĆÖt be done at a later moment
- 5. Loading same record into both tables (note the syntax): INSERT INTO etl_schema.orders (ordernumber ,quantityordered ,priceeach ,orderlinenumber ,sales ,orderdate ,status ,qtr_id ,month_id ,year_id ,productline ,msrp ,productcode ,customername ,phone ,addressline1 ,addressline2 ,city ,state ,postalcode ,country ,territory ,contactlastname ,contactfirstname ,dealsize) VALUES (10107,30,95.7,2,2871,'2003-02-24','Shipped',1,2,2003,'Motorcycles',95,'S10_1678','Land of Toys Inc.','2125557818','897 Long Airport Avenue',' ','NYC','NY','10022','USA','NA','Yu','Kwai','SmallŌĆÖ); INSERT INTO etl_schema.orders_new (ordernumber ,orderdate ,decimal_map ,int_map ,text_map ) VALUES (10107,'2003-02-24ŌĆÖ, {'priceeach':95.7,'sales':2871}, {'quantityordered':30,'orderlinenumber':2,'qtr_id':1,'month_id':2,'year_id':2003,'msrp':95}, {'status':'Shipped','productline':'Motorcycles','productcode':'S10_1678','customername':'Land of Toys Inc.','phone':'2125557818','addressline1':'897 Long Airport Avenue','addressline2':'','city':'NYC','state':'NY','postalcode':'10022','country':'USA','territory':'NA','contactlastname':'Yu','contactfirstname':'Kwai','dealsize':'Small'});
- 6. Loading the full data file and trying to search information from the modified structure assures that the additional search capability works as desired ! cqlsh> SELECT COUNT(*) FROM etl_schema.orders_new WHERE text_map CONTAINS 'Michael' ALLOW FILTERING; count ------- 3 (1 rows) Warnings : Aggregation query used without partition key cqlsh> SELECT COUNT(*) FROM etl_schema.orders_new WHERE text_map CONTAINS KEY 'productline' ALLOW FILTERING; count ------- 165 (1 rows) Warnings : Aggregation query used without partition key cqlsh> UPDATE etl_schema.orders_new SET text_map = text_map - {'territory'} WHERE ordernumber=10318 AND orderdate='2004-11- 02ŌĆÖ; /* removes a ŌĆścolumnŌĆÖ from existing row*/ cqlsh> UPDATE etl_schema.orders_new SET text_map = text_map + {'new_territory':'NA'} WHERE ordernumber=10318 AND orderdate='2004-11-02ŌĆÖ; /* adds a ŌĆścolumnŌĆÖ in existing row*/
- 7. ’ü▒ Benefits of this approach are best for the use case where ŌĆśSearchŌĆÖ criteria is not fixed on a table and evolves over a period of time (and yet much desired) ’ü▒ New ŌĆścolumnŌĆÖ addition is a seamless process that requires no changes in the ETL/ELT pipeline ’ü▒ This approach consumes more space than the conventional storage by design ’ü▒ Data ingestion speed slows down as compared to conventional design
- 8. ’ü▒ Tombstones shall continue to be generated for insert/update/deletes as they are for the existing scenarios. ’ü▒ However, Compaction operations are reduced if Values are suitably updated instead of overwriting the entire map (syntax). Similarly, new Keys can be added with minimal impact. ’ü▒ At an average , 2-10 % compaction reduction can be observed with this approach in case your table receives updates
- 9. ’ü▒ Searching columns is quite straightforward with this approach for columns outside the Primary Keys ’ü▒ Maps can be made searchable by enabling the ENTRIES/KEYS to be indexed. This further helps to narrow down the search criteria by suitably using CONTAINS /KEY predicates on otherwise non-searchable columns
- 10. ’ā╝ Flexible data model allows column modification ( DML operations) in the table seamlessly, saving the engineering team time and effort to do so otherwise manually: ’üČ Addition ’üČ Deletion ’üČ Modification of column datatype ’ā╝ Keys are searchable, making other columns than Primary Key also to be used for lookup, while not adding on the effort to build and maintain individual indexes ’ā╝ Model is full compatible with application layer languages (Java, Python etc.) to slice and dice the key-value pairs from maps using de/serialization techniques available in all libraries for json parsing