
![Checkpoint 101
? ź┴ź¦ź├ź»ź▌źżź¾ź╚: źŪ®`ź┐ź┘®`ź╣ż╬źĻź½źąźĻż╬ż┐żßż╬ÖC─▄
? ▀\ė├ųąż╬żóżļĢrĄŃż╬źżźß®`źĖż“╔·│╔ż╣żļ
? żĮż╬ĢrĄŃż▐żŪż╦ĮKż’ż├ż┐ź╚źķź¾źČź»źĘźńź¾ż╬Ūķł¾ż“╚½żŲĘ┤ė│ż╣żļ
? ĪĖżóżļĢrĄŃĪ╣ż¼żżż─ż╩ż╬ż½źŽź├źŁźĻčįż©ż╩żż(ę╗ž×ąįż¼ż╩żż)ż╚NG
? `Point of consistency [1]` ż╚żĶżążņżŲżżżļ
Thread 1
?1, ??
OK NG
Thread 2
?1 ?2 ?3 ?4
?? ?? ??
?2 ?? ??????????
Checkpoint Image: ?1, ??, ?2, ??
Depends
?? ?? ??????? ?? ?4](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-2-320.jpg)
![Checkpoint ż╬ęŌ┴x
1. źĒź░(WAL)ż╬źĄźżź║ż“ėąĮńż╦ż╣żļ
? Ģ°żŁ▐zż▀ż“ż╣żļ╚½ź╚źķź¾źČź»źĘźńź¾ż¼źĒź░ (WAL) ż“Ģ°ż»ż┐żß
2. źĻź½źąźĻĢrķgż“Ė▀╦┘ż╦ż╣żļ
? WALż“ūŅ│§ż½żķźĻźūźņźżżĘżŲżżżļż╚ķLżżį┬╚šż“ꬿ╣żļż┐żß
? CompactionżĄżņż┐źżźß®`źĖż╦ż╦ūŅĮ³ż╬WALż“▀mė├ż╣żļŻ¼ż╚żżż”ż╬ż¼┴╝żż
3. ź┴ź¦ź├ź»ź▌źżź¾ź╚ź┘®`ź╣ż╬ė└ŠAąįż“╠ß╣®ż╣żļ
? FASTER-CPR [2] ż╚ż½ Redis ż╬ RDB ė└ŠAąįż╚ż½Ż«
? ę╗Č©Ģrķgż¬żŁż╦ę╗ž×ąįż╬żóżļź╣ź╩ź├źūźĘźńź├ź╚ż“╚Īżļż└ż▒Ż¼ż╚żżż”źņź┘źļ
? ūŅĮ³ż╬żŌż╬żŽō]░kżĘżŲżŌįSżĘżŲż»żņżļż═](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-3-320.jpg)
![Checkpointing on Disk-based DBMS
? źŪźŻź╣ź»ź┘®`ź╣ż╬źŪ®`ź┐ź┘®`ź╣
? źŪźŻź╣ź»╔Žż╦źŪ®`ź┐ż¼żŌż”▌dż├żŲżżżļ
? CommittedżŌAbortedżŌDirtyżŌźŪźŻź╣ź»ż╦Ģ°żŁż│ż▐żņżŲżżżļ
? źŪźŻź╣ź»╔Žż╬źŪ®`ź┐ż¼ point of consistency ż“£║ż┐ż╗żąOK
? Aborted/Dirtyż“▀mŪąż╦äI└ĒżŪżŁżņżąCommittedż└ż▒▓ążļż╬żŪŻ¼OK
? Fuzzy Checkpointing ż╚żżż”źóźļź┤źĻź║źÓż¼ėą├¹
? Active transactionsż╬źĻź╣ź╚ż╚ Dirty Page Tableż“ū„ż├żŲ▒Ż┤µżĘżŲż¬żŁŻ¼▀\ė├ųąż╦
╣▄└Ēż╣żļ
? RecoveryĢrż╦ż│ż╬źĻź╣ź╚ż“╩╣ż├żŲdirty/abortż“▀mŪąż╦äI└Ēż╣żļ
? įö╝ÜżŽ ARIES [3] żŪŻ«Į±╚šżŽšZżĻż▐ż╗ż¾](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-4-320.jpg)


![Making Virtual Point of Consistency
? Physical Point of Consistency (PPoC): ╬’└ĒĄ─ż╩╚½═Żų╣ū┤æB
? Logical Point of Consistency (LPoC): šō└ĒĄ─ż╩PoC
1. Copy-On-Update
? Checkpointė├ż╬źąź├źšźĪż“ė├ęŌżĘżŲŻ¼Ė„ź╚źķź¾źČź»źĘźńź¾ż╦▀mę╦═╦▒▄żĄż╗żŲżżż»
2. Zig-Zag, Ping-Pong [4]
? Wait-freeż╩LPoC╔·│╔╩ųĘ©Ż«╣╠Č©ķLźŪ®`ź┐ & ż┐ż▐ż╦PPoCż¼▒žę¬
3. CALC [5]
? ┐╔ēõķLźŪ®`ź┐OK&PPoC▓╗ꬿ╩LPoC╔·│╔╩ųĘ©Ż«ųąčļźŪ®`ź┐śŗįņż¼żóżļ
4. CPR [6]
? ųąčļźŪ®`ź┐śŗįņż╬ż╩żżŻ¼ż½ż─üK┴ą╗»żĄżņż┐LPoC╔·│╔╩ųĘ©
5. Hyper
? źūźĒź╗ź╣ż“forkżĘżŲź│źį®`ż“╚ĪżĻŻ¼checkpointż“żĘżŲżżż»](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-7-320.jpg)
![Zig-Zag [4]
? źŪ®`ź┐ź┘®`ź╣ż¼Ė„źŪ®`ź┐ż╦ż─żŁČ■ż─źąź├źšźĪ (AS) ż“╣▄└Ēż╣żļ
? ź╚źķź¾źČź»źĘźńź¾ż╦Ģ°ż½ż╗żļżŌż╬ż╚Ż¼ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦╩╣ż”żŌż╬
? Ęųż▒żļż│ż╚ż╦żĶż├żŲźĒź├ź»żŪ┼┼╦¹żĘżóż”▒žę¬ż¼ż╩ż»ż╩żļ
? ę¬╝s
? Č■ż─ż╬źąź├źšźĪ ??[2]ż╚Č■ż─ż╬źėź├ź╚ź▐ź├źū??, ??ż“ė├ęŌż╣żļ
? źėź├ź╚ź▐ź├źūż¼Ż¼ĪĖż╔ż┴żķż╬źąź├źšźĪż“╩╣ż”ż┘żŁż½Ī╣ż“╩Šż╣
? MR żŽ ūŅą┬ż╬źŪ®`ź┐ż¼ė¹żĘżżż╚żŁšiżÓż┘żŁżŌż╬ż“Ż¼ MW żŽĢ°ż»ż┘żŁżŌż╬ż“╩ŠżĘżŲżż
żļ
? ź╚źķź¾źČź»źĘźńź¾żŽ źŪ®`ź┐ i ż“šiżÓż╚żŁ AS[MR[i]] [i]ż“╩╣ż”
? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ AS[?MW[i]][i] ż“╩╣ż”
? Č©Ų┌Ą─ż╦switchż╣żļŻ«PPoCż╦ĄĮ▀_żĘż┐ż╚żŁż╦ąąż”](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-8-320.jpg)
![? źŪ®`ź┐ź┘®`ź╣ż¼Ė„źŪ®`ź┐ż╦ż─żŁČ■ż─źąź├źšźĪ (AS) ż“╣▄└Ēż╣żļ
? ź╚źķź¾źČź»źĘźńź¾ż╦Ģ°ż½ż╗żļżŌż╬ż╚Ż¼ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦╩╣ż”żŌż╬
? Ęųż▒żļż│ż╚ż╦żĶż├żŲźĒź├ź»żŪ┼┼╦¹żĘżóż”▒žę¬ż¼ż╩ż»ż╩żļ
? ę¬╝s
? Č■ż─ż╬źąź├źšźĪ ??[2]ż╚Č■ż─ż╬źėź├ź╚ź▐ź├źū??, ??ż“ė├ęŌż╣żļ
? źėź├ź╚ź▐ź├źūż¼Ż¼ĪĖż╔ż┴żķż╬źąź├źšźĪż“╩╣ż”ż┘żŁż½Ī╣ż“╩Šż╣
? MR żŽ ūŅą┬ż╬źŪ®`ź┐ż¼ė¹żĘżżż╚żŁšiżÓż┘żŁżŌż╬ż“Ż¼ MW żŽĢ°ż»ż┘żŁżŌż╬ż“╩ŠżĘżŲżż
żļ
? ź╚źķź¾źČź»źĘźńź¾żŽ źŪ®`ź┐ i ż“šiżÓż╚żŁ AS[MR[i]] [i]ż“╩╣ż”
? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ AS[?MW[i]][i] ż“╩╣ż”
? Č©Ų┌Ą─ż╦switchż╣żļŻ«PPoCż╦ĄĮ▀_żĘż┐ż╚żŁż╦ąąż”
Zig-Zag [4]](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-9-320.jpg)
![(Interleaved) Ping-Pong [4]
? Zig-Zagż╦żŽŪĘĄŃż¼żóżļ
? PPoCż“ū„żķż╩żżż╚┤╬ż╬ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦ęŲąążŪżŁż╩żż
? ź┴ź¦ź├ź»ź▌źżź¾ź╚ųążŽź╬ź¾źųźĒź├źŁź¾ź░ż└ż▒ż╔Ż¼ż▐ż└ūŃżĻż╩żż
? Ping-Pongż“╠ß░Ė
? PPoCż╩żĘŻ«┤·ż’żĻż╦żĄżķż╦┐šķgŽ¹┘M┴┐ż“ēłżõż╣
? AS, Odd, Even ż╬Ż│ż─ż╬ŅIė“ż“ū„ż├żŲĖ„źŪ®`ź┐ż“ź│źį®`ż╣żļ
? ź╚źķź¾źČź»źĘźńź¾
? ASż╚Odd or Evenż╬ż╔ż├ż┴ż½Ż¼ųĖČ©żĄżņżŲżżżļż█ż”ż╦Ģ°żŁ▐zżÓ
? ź┴ź¦ź├ź»ź▌źżź¾ź╚
? Odd or Even ż╬ż╔ż├ż┴ż½Ż¼ź╚źķź¾źČź»źĘźńź¾ż╦┤źżķżņż╩żżĘĮż½żķšiż▀▐zżÓ
? ź╣źżź├ź┴ź¾ź░
? Odd or Even ż╬ųĖČ©ż“ąąż”źėź├ź╚ż“źóź╚ź▀ź├ź»ż╦Ģ°żŁōQż©żļ](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-10-320.jpg)
![(Interleaved) Ping-Pong [4]
? Zig-Zagż╦żŽŪĘĄŃż¼żóżļ
? PPoCż“ū„żķż╩żżż╚┤╬ż╬ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦ęŲąążŪżŁż╩żż
? ź┴ź¦ź├ź»ź▌źżź¾ź╚ųążŽź╬ź¾źųźĒź├źŁź¾ź░ż└ż▒ż╔Ż¼ż▐ż└ūŃżĻż╩żż
? Ping-Pongż“╠ß░Ė
? PPoCż╩żĘŻ«┤·ż’żĻż╦żĄżķż╦┐šķgŽ¹┘M┴┐ż“ēłżõż╣
? AS, Odd, Even ż╬Ż│ż─ż╬ŅIė“ż“ū„ż├żŲĖ„źŪ®`ź┐ż“ź│źį®`ż╣żļ
? ź╚źķź¾źČź»źĘźńź¾
? ASż╚Odd or Evenż╬ż╔ż├ż┴ż½Ż¼ųĖČ©żĄżņżŲżżżļż█ż”ż╦Ģ°żŁ▐zżÓ
? ź┴ź¦ź├ź»ź▌źżź¾ź╚
? Odd or Even ż╬ż╔ż├ż┴ż½Ż¼ź╚źķź¾źČź»źĘźńź¾ż╦┤źżķżņż╩żżĘĮż½żķšiż▀▐zżÓ
? ź╣źżź├ź┴ź¾ź░
? Odd or Even ż╬ųĖČ©ż“ąąż”źėź├ź╚ż“źóź╚ź▀ź├ź»ż╦Ģ°żŁōQż©żļ](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-11-320.jpg)
![Zig-Zag and Ping-Pong [4]](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-12-320.jpg)
![CALC [1]
? Zig-Zag/Ping-Pongż╬Ė─╔Ų
? ╣╠Č©ķL┼õ┴ąż╚żĘżŲżĘż½ AS ż“ė├ęŌżŪżŁż╩ż½ż├ż┐ĄŃż“Ė─╔Ų
? Switchingż╦PPoCż¼▒žę¬ż└ż├ż┐ĄŃż“Ė─╔Ų (Zig-Zagż╬ż▀)
? ź┴ź¦ź├ź»ź▌źżź¾ź╚ż“5-phasesż╦ĘųĖŅ
1. REST: ź┴ź¦ź├ź»ź▌źżź¾ź╚żĘżŲżżż╩żżū┤æB
2. PREPARE: VPoCż“ū„żļ£╩éõż“ż╣żļū┤æB
3. RESOLVE: VPoCż╬ßßż╦╬╗ų├ż╣żļū┤æBŻ«
ż│ż│żŪąąż’żņżļēõĖ³żŽź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦żŽ╚ļżķż╩żżŻ«
╚½åTż¼PREPARE ū┤æBż╦▀węŲżĘż┐ż│ż╚ż“┤_šJżĘż┐żķĖ„ūį RESOLVE ż╦╚ļż├żŲżżż»
4. CAPTURE: źąź├ź»ź░źķź”ź¾ź╔żŪź┴ź¦ź├ź»ź▌źżź¾ź╚ż“Ģ°ż»ū┤æB
╚½åTż¼RESOLVEū┤æBż╦▀węŲżĘż┐ż│ż╚ż“┤_šJżĘż┐żķĖ„ūį CAPTUREż╦╚ļż├żŲżżż»
╚½åTż¼CAPTUREż╦╚ļż├ż┐żķźąź├ź»ź░źķź”ź¾ź╔ż╬checkpointerż¼Ųäėż╣żļ
5. COMPLETE: ź┴ź¦ź├ź»ź▌źżź¾ź╚ż¼═Ļ┴╦żĘż┐ż│ż╚ż“╩Šż╣ū┤æB](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-13-320.jpg)
![CALC [1] ContĪ»d
? CALCż╬┐╝ż©ĘĮ
? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ VPoC (PREPAREż╚ RESOLVEż╬ķg) ż╬ßßż╦īgąążĄżņżļ
REST PREPARE RESOLVE CAPTURE COMPLETE
VPoC
Checkpointer
works
? Checkpointerż¼VPoCĢrĄŃżŪż╬Ė„źŪ®`ź┐ż“šiż▀╚ĪżņżļżĶż”ż╦żĘż┐żż](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-14-320.jpg)
![CALC [1] ContĪ»d
? CALCż╬┐╝ż©ĘĮ
? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ VPoC (PREPAREż╚ RESOLVEż╬ķg) ż╬ßßż╦īgąążĄżņżļ
REST PREPARE RESOLVE CAPTURE COMPLETE
VPoC
Checkpointer
works
Stable versions
(delta)
? Checkpointerż¼VPoCĢrĄŃżŪż╬Ė„źŪ®`ź┐ż“šiż▀╚ĪżņżļżĶż”ż╦żĘż┐żż
? CALCżŪżŽŻ¼ stable versions ż“šiżßżą╚ĪżņżļżĶż”ż╦ż╣żļ
? PREPARE ū┤æBżŪūŅßßż╦źŪ®`ź┐ż“Ė³ą┬żĘż┐╚╦żŽ stable versionsżŌĖ³ą┬ż╣żļ
? RESOLVE ū┤æBżŪūŅ│§ż╦źŪ®`ź┐ż“šiż¾ż└╚╦żŽ stable versionsż╦żŌź│źį®`ż╣żļ](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-15-320.jpg)
![CALC [1] ContĪ»d
? Ė„źŁ®`ż╦źąź├źšźĪż“Č■ż─ (live, stable) ė├ęŌż╣żļ
? `stable_status` ż╚żżż”źėź├ź╚┼õ┴ąż“ė├ęŌż╣żļ
? Checkpointerż½żķęŖżŲŻ¼db[key].stable żŽ stable_status[key] is true ż╬ż╚żŁVPoCż╬żŌż╬
? żĮż”żŪż╩żżł÷║ŽżŽŻ¼live version ż¼Ė³ą┬żĄżņżŲżżż╩żżż╚żżż”ż│ż╚ż╩ż╬żŪŻ¼żĮż╬ż▐ż▐šiżßżļ](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-16-320.jpg)
![CALC [1] ContĪ»d
? ź╩źż®`źųż╩ź╣ź╩ź├źūźĘźńź├ź╚ż╚Fuzzy checkpointż└ż╚ź╣źļ®`źūź├ź╚ż¼ź╝źĒż╦ż╩żļż¼Ż¼Ų┌ķgżŽČ╠żż
? Zig-Zag / Ping-Pong żŽź┴ź¦ź├ź»ź▌źżź¾ź╚ųąż╬ź╣źļ®`źūź├ź╚ż¼┬õż┴żļŻ«
? Ping-Pong żŽźŪ®`ź┐1ż─ż╦ż─żŁ3ż─ż╬źąź├źšźĪ (AS, Odd, Even) ż“ė├ęŌż╣żļż┐żßŻ¼źßźŌźĻ/źŁźŃź├źĘźÕä┐┬╩ż¼ÉÖżż
? ĮYŠų Long Txż¼Į╗żĖżļ (b) ż└ż╚ PPoC ż“ū„żļż┐żßż╦ż▀ż¾ż╩ąį─▄ż¼ÉÖż»ż╩żļż¼Ż¼ CALC żŽżĶż»żõż├żŲżżżļŻ«](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-17-320.jpg)
![CPR [2]
? CALCż╬Ė─╔Ų
? CALCżŽųąčļźŪ®`ź┐śŗįņ commit_log ż¼▒žę¬żŪŻ¼ż│żņż“ijżĘż┐
? commit_log ż╦żŽĖ„ź╣źņź├ź╔ż╬żżżļū┤æB/ż│żņż½żķ╩╝ż▐żļū┤æBż¼Ģ°żżżŲżóż├ż┐
? LineairDBżŪż│żņż“īgū░ & Ė─╔ŲżĘż▐żĘż┐](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-18-320.jpg)
![CPR [2] ContĪ»d
? ū┤æB▀węŲż“ Epoch Framework [5] żŪżõż├żŲżżżļż╬ż¼novelty
? atomic<int> epoch ż╚ atomic<int>[] thread_local_epoch żŪū┤æB▀węŲż╣żļ
? thread_local_epoch ż¼╚½żŲ═¼żĖ╩²éÄż╦ż╩ż├ż┐ż╚żŁ epoch ż“źżź¾ź»źĻźßź¾ź╚ż╣żļ](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-19-320.jpg)
![CPR [2] ContĪ»d
? CPR żŽ 4-phases ż½żķż╩żļ
? VPoCż╬Ū░ßßż╬ū┤æBż“ū„ż├żŲŻ¼żĮż│żŪĖ„ź╚źķź¾źČź»źĘźńź¾ż¼żĶżĘż╩ż╦ stable versionsż“▓┘ū„żĘżŲżż
ż»???ż╚żżż”ż╬żŽCALCż╚ ╚½ż»═¼żĖ
? ū┤æB▀węŲż“ Epoch Framework [5] żŪżõż├żŲżżżļż╬ż¼novelty
? atomic<State> state ż╚ atomic<State>[] thread_local_state żŪū┤æB▀węŲż╣żļ
? thread_local_State ż¼╚½żŲ═¼żĖż╦ż╩ż├ż┐ż╚żŁ ┤╬ż╬ phase ż╦ąąż»Ż«źųźĒź├źŁź¾ź░żĘż╩żżż╬ż¼ēėżĻ
? PREPARE ż¼ IN-PROGRESS ż╬źŪ®`ź┐ż“šiż¾żŪżĘż▐ż”ż╚żŁżŽŻ¼źóź▄®`ź╚ż╣żļ
? ż│ż╬źóź▄®`ź╚żŽ CALC żŪżŌ▒žę¬ż╩źŽź║ż└ż¼Ż¼šō╬─ųąż╦ę╗Ūąėø╩÷ż¼ż╩żż
IN-
PROGRESS
WAIT
FLUSH
REST
PREPARE ? (? + 1)
?
?
?
Aborts some
transactions](https://image.slidesharecdn.com/checkpoint1202-230814023700-53b9b1cc/85/Checkpointing-Algorithms-on-In-memory-DBMS-20-320.jpg)


Checkpointing Algorithms on In-memory DBMS
- 1. Checkpoint Algorithms on In-memory Databases nikezono, 11/25, 2022, system-readings
- 2. Checkpoint 101 ? ź┴ź¦ź├ź»ź▌źżź¾ź╚: źŪ®`ź┐ź┘®`ź╣ż╬źĻź½źąźĻż╬ż┐żßż╬ÖC─▄ ? ▀\ė├ųąż╬żóżļĢrĄŃż╬źżźß®`źĖż“╔·│╔ż╣żļ ? żĮż╬ĢrĄŃż▐żŪż╦ĮKż’ż├ż┐ź╚źķź¾źČź»źĘźńź¾ż╬Ūķł¾ż“╚½żŲĘ┤ė│ż╣żļ ? ĪĖżóżļĢrĄŃĪ╣ż¼żżż─ż╩ż╬ż½źŽź├źŁźĻčįż©ż╩żż(ę╗ž×ąįż¼ż╩żż)ż╚NG ? `Point of consistency [1]` ż╚żĶżążņżŲżżżļ Thread 1 ?1, ?? OK NG Thread 2 ?1 ?2 ?3 ?4 ?? ?? ?? ?2 ?? ?????????? Checkpoint Image: ?1, ??, ?2, ?? Depends ?? ?? ??????? ?? ?4
- 3. Checkpoint ż╬ęŌ┴x 1. źĒź░(WAL)ż╬źĄźżź║ż“ėąĮńż╦ż╣żļ ? Ģ°żŁ▐zż▀ż“ż╣żļ╚½ź╚źķź¾źČź»źĘźńź¾ż¼źĒź░ (WAL) ż“Ģ°ż»ż┐żß 2. źĻź½źąźĻĢrķgż“Ė▀╦┘ż╦ż╣żļ ? WALż“ūŅ│§ż½żķźĻźūźņźżżĘżŲżżżļż╚ķLżżį┬╚šż“ꬿ╣żļż┐żß ? CompactionżĄżņż┐źżźß®`źĖż╦ż╦ūŅĮ³ż╬WALż“▀mė├ż╣żļŻ¼ż╚żżż”ż╬ż¼┴╝żż 3. ź┴ź¦ź├ź»ź▌źżź¾ź╚ź┘®`ź╣ż╬ė└ŠAąįż“╠ß╣®ż╣żļ ? FASTER-CPR [2] ż╚ż½ Redis ż╬ RDB ė└ŠAąįż╚ż½Ż« ? ę╗Č©Ģrķgż¬żŁż╦ę╗ž×ąįż╬żóżļź╣ź╩ź├źūźĘźńź├ź╚ż“╚Īżļż└ż▒Ż¼ż╚żżż”źņź┘źļ ? ūŅĮ³ż╬żŌż╬żŽō]░kżĘżŲżŌįSżĘżŲż»żņżļż═
- 4. Checkpointing on Disk-based DBMS ? źŪźŻź╣ź»ź┘®`ź╣ż╬źŪ®`ź┐ź┘®`ź╣ ? źŪźŻź╣ź»╔Žż╦źŪ®`ź┐ż¼żŌż”▌dż├żŲżżżļ ? CommittedżŌAbortedżŌDirtyżŌźŪźŻź╣ź»ż╦Ģ°żŁż│ż▐żņżŲżżżļ ? źŪźŻź╣ź»╔Žż╬źŪ®`ź┐ż¼ point of consistency ż“£║ż┐ż╗żąOK ? Aborted/Dirtyż“▀mŪąż╦äI└ĒżŪżŁżņżąCommittedż└ż▒▓ążļż╬żŪŻ¼OK ? Fuzzy Checkpointing ż╚żżż”źóźļź┤źĻź║źÓż¼ėą├¹ ? Active transactionsż╬źĻź╣ź╚ż╚ Dirty Page Tableż“ū„ż├żŲ▒Ż┤µżĘżŲż¬żŁŻ¼▀\ė├ųąż╦ ╣▄└Ēż╣żļ ? RecoveryĢrż╦ż│ż╬źĻź╣ź╚ż“╩╣ż├żŲdirty/abortż“▀mŪąż╦äI└Ēż╣żļ ? įö╝ÜżŽ ARIES [3] żŪŻ«Į±╚šżŽšZżĻż▐ż╗ż¾
- 5. Checkpointing on In-Memory DBMS ? źżź¾źßźŌźĻźŪ®`ź┐ź┘®`ź╣ ? źŪźŻź╣ź»╔Žż╦źŪ®`ź┐ż¼ż╩żż ? źŪźŻź╣ź»ż╦żŽźĒź░Ż©WALŻ®żĘż½ż╩żż ? źóźūźĒ®`ź┴żŽżżżĒżżżĒ ? WALż“ź│ź¾źčź»źĘźńź¾ż╣żļ ? Č©Ų┌Ą─ż╦╚½źŪ®`ź┐ż“flushż╣żļ ? Į±╚šżŽż│ż╬źóźūźĒ®`ź┴ż╬įÆż“żĘż▐ż╣
- 6. ╚½źŪ®`ź┐ż“flushż╣żļ ? ż╔ż”żõżļż¾ż└ ? Full-scan ż╬read-only txn ż“ū▀żķż╗żļ? ųžż╣ż«ĪŁĪŁ ? 2PL ż└ż╚╚½źŪ®`ź┐ż╦źĒź├ź»ż½ż▒żļż│ż╚ż╦ż╩żļ ? żŪżŌĪ²ż╬NGźčź┐®`ź¾żŽŲż│żķż╩żż Thread 1 ?1, ?? Thread 2 ?1 ?2 ?3 ?4 ?? ?? ?? ?2 ?? ?????????? Checkpoint Image: ?1, ??, ?2, ?? ?? ?? ??????? ?? ?4 żŌż├ż╚▌X┴┐ż╦ consistent ż╩ŠĆż“ę²ż»ĘĮĘ©ż╩żżż½ż╩???
- 7. Making Virtual Point of Consistency ? Physical Point of Consistency (PPoC): ╬’└ĒĄ─ż╩╚½═Żų╣ū┤æB ? Logical Point of Consistency (LPoC): šō└ĒĄ─ż╩PoC 1. Copy-On-Update ? Checkpointė├ż╬źąź├źšźĪż“ė├ęŌżĘżŲŻ¼Ė„ź╚źķź¾źČź»źĘźńź¾ż╦▀mę╦═╦▒▄żĄż╗żŲżżż» 2. Zig-Zag, Ping-Pong [4] ? Wait-freeż╩LPoC╔·│╔╩ųĘ©Ż«╣╠Č©ķLźŪ®`ź┐ & ż┐ż▐ż╦PPoCż¼▒žę¬ 3. CALC [5] ? ┐╔ēõķLźŪ®`ź┐OK&PPoC▓╗ꬿ╩LPoC╔·│╔╩ųĘ©Ż«ųąčļźŪ®`ź┐śŗįņż¼żóżļ 4. CPR [6] ? ųąčļźŪ®`ź┐śŗįņż╬ż╩żżŻ¼ż½ż─üK┴ą╗»żĄżņż┐LPoC╔·│╔╩ųĘ© 5. Hyper ? źūźĒź╗ź╣ż“forkżĘżŲź│źį®`ż“╚ĪżĻŻ¼checkpointż“żĘżŲżżż»
- 8. Zig-Zag [4] ? źŪ®`ź┐ź┘®`ź╣ż¼Ė„źŪ®`ź┐ż╦ż─żŁČ■ż─źąź├źšźĪ (AS) ż“╣▄└Ēż╣żļ ? ź╚źķź¾źČź»źĘźńź¾ż╦Ģ°ż½ż╗żļżŌż╬ż╚Ż¼ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦╩╣ż”żŌż╬ ? Ęųż▒żļż│ż╚ż╦żĶż├żŲźĒź├ź»żŪ┼┼╦¹żĘżóż”▒žę¬ż¼ż╩ż»ż╩żļ ? ę¬╝s ? Č■ż─ż╬źąź├źšźĪ ??[2]ż╚Č■ż─ż╬źėź├ź╚ź▐ź├źū??, ??ż“ė├ęŌż╣żļ ? źėź├ź╚ź▐ź├źūż¼Ż¼ĪĖż╔ż┴żķż╬źąź├źšźĪż“╩╣ż”ż┘żŁż½Ī╣ż“╩Šż╣ ? MR żŽ ūŅą┬ż╬źŪ®`ź┐ż¼ė¹żĘżżż╚żŁšiżÓż┘żŁżŌż╬ż“Ż¼ MW żŽĢ°ż»ż┘żŁżŌż╬ż“╩ŠżĘżŲżż żļ ? ź╚źķź¾źČź»źĘźńź¾żŽ źŪ®`ź┐ i ż“šiżÓż╚żŁ AS[MR[i]] [i]ż“╩╣ż” ? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ AS[?MW[i]][i] ż“╩╣ż” ? Č©Ų┌Ą─ż╦switchż╣żļŻ«PPoCż╦ĄĮ▀_żĘż┐ż╚żŁż╦ąąż”
- 9. ? źŪ®`ź┐ź┘®`ź╣ż¼Ė„źŪ®`ź┐ż╦ż─żŁČ■ż─źąź├źšźĪ (AS) ż“╣▄└Ēż╣żļ ? ź╚źķź¾źČź»źĘźńź¾ż╦Ģ°ż½ż╗żļżŌż╬ż╚Ż¼ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦╩╣ż”żŌż╬ ? Ęųż▒żļż│ż╚ż╦żĶż├żŲźĒź├ź»żŪ┼┼╦¹żĘżóż”▒žę¬ż¼ż╩ż»ż╩żļ ? ę¬╝s ? Č■ż─ż╬źąź├źšźĪ ??[2]ż╚Č■ż─ż╬źėź├ź╚ź▐ź├źū??, ??ż“ė├ęŌż╣żļ ? źėź├ź╚ź▐ź├źūż¼Ż¼ĪĖż╔ż┴żķż╬źąź├źšźĪż“╩╣ż”ż┘żŁż½Ī╣ż“╩Šż╣ ? MR żŽ ūŅą┬ż╬źŪ®`ź┐ż¼ė¹żĘżżż╚żŁšiżÓż┘żŁżŌż╬ż“Ż¼ MW żŽĢ°ż»ż┘żŁżŌż╬ż“╩ŠżĘżŲżż żļ ? ź╚źķź¾źČź»źĘźńź¾żŽ źŪ®`ź┐ i ż“šiżÓż╚żŁ AS[MR[i]] [i]ż“╩╣ż” ? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ AS[?MW[i]][i] ż“╩╣ż” ? Č©Ų┌Ą─ż╦switchż╣żļŻ«PPoCż╦ĄĮ▀_żĘż┐ż╚żŁż╦ąąż” Zig-Zag [4]
- 10. (Interleaved) Ping-Pong [4] ? Zig-Zagż╦żŽŪĘĄŃż¼żóżļ ? PPoCż“ū„żķż╩żżż╚┤╬ż╬ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦ęŲąążŪżŁż╩żż ? ź┴ź¦ź├ź»ź▌źżź¾ź╚ųążŽź╬ź¾źųźĒź├źŁź¾ź░ż└ż▒ż╔Ż¼ż▐ż└ūŃżĻż╩żż ? Ping-Pongż“╠ß░Ė ? PPoCż╩żĘŻ«┤·ż’żĻż╦żĄżķż╦┐šķgŽ¹┘M┴┐ż“ēłżõż╣ ? AS, Odd, Even ż╬Ż│ż─ż╬ŅIė“ż“ū„ż├żŲĖ„źŪ®`ź┐ż“ź│źį®`ż╣żļ ? ź╚źķź¾źČź»źĘźńź¾ ? ASż╚Odd or Evenż╬ż╔ż├ż┴ż½Ż¼ųĖČ©żĄżņżŲżżżļż█ż”ż╦Ģ°żŁ▐zżÓ ? ź┴ź¦ź├ź»ź▌źżź¾ź╚ ? Odd or Even ż╬ż╔ż├ż┴ż½Ż¼ź╚źķź¾źČź»źĘźńź¾ż╦┤źżķżņż╩żżĘĮż½żķšiż▀▐zżÓ ? ź╣źżź├ź┴ź¾ź░ ? Odd or Even ż╬ųĖČ©ż“ąąż”źėź├ź╚ż“źóź╚ź▀ź├ź»ż╦Ģ°żŁōQż©żļ
- 11. (Interleaved) Ping-Pong [4] ? Zig-Zagż╦żŽŪĘĄŃż¼żóżļ ? PPoCż“ū„żķż╩żżż╚┤╬ż╬ź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦ęŲąążŪżŁż╩żż ? ź┴ź¦ź├ź»ź▌źżź¾ź╚ųążŽź╬ź¾źųźĒź├źŁź¾ź░ż└ż▒ż╔Ż¼ż▐ż└ūŃżĻż╩żż ? Ping-Pongż“╠ß░Ė ? PPoCż╩żĘŻ«┤·ż’żĻż╦żĄżķż╦┐šķgŽ¹┘M┴┐ż“ēłżõż╣ ? AS, Odd, Even ż╬Ż│ż─ż╬ŅIė“ż“ū„ż├żŲĖ„źŪ®`ź┐ż“ź│źį®`ż╣żļ ? ź╚źķź¾źČź»źĘźńź¾ ? ASż╚Odd or Evenż╬ż╔ż├ż┴ż½Ż¼ųĖČ©żĄżņżŲżżżļż█ż”ż╦Ģ°żŁ▐zżÓ ? ź┴ź¦ź├ź»ź▌źżź¾ź╚ ? Odd or Even ż╬ż╔ż├ż┴ż½Ż¼ź╚źķź¾źČź»źĘźńź¾ż╦┤źżķżņż╩żżĘĮż½żķšiż▀▐zżÓ ? ź╣źżź├ź┴ź¾ź░ ? Odd or Even ż╬ųĖČ©ż“ąąż”źėź├ź╚ż“źóź╚ź▀ź├ź»ż╦Ģ°żŁōQż©żļ
- 12. Zig-Zag and Ping-Pong [4]
- 13. CALC [1] ? Zig-Zag/Ping-Pongż╬Ė─╔Ų ? ╣╠Č©ķL┼õ┴ąż╚żĘżŲżĘż½ AS ż“ė├ęŌżŪżŁż╩ż½ż├ż┐ĄŃż“Ė─╔Ų ? Switchingż╦PPoCż¼▒žę¬ż└ż├ż┐ĄŃż“Ė─╔Ų (Zig-Zagż╬ż▀) ? ź┴ź¦ź├ź»ź▌źżź¾ź╚ż“5-phasesż╦ĘųĖŅ 1. REST: ź┴ź¦ź├ź»ź▌źżź¾ź╚żĘżŲżżż╩żżū┤æB 2. PREPARE: VPoCż“ū„żļ£╩éõż“ż╣żļū┤æB 3. RESOLVE: VPoCż╬ßßż╦╬╗ų├ż╣żļū┤æBŻ« ż│ż│żŪąąż’żņżļēõĖ³żŽź┴ź¦ź├ź»ź▌źżź¾ź╚ż╦żŽ╚ļżķż╩żżŻ« ╚½åTż¼PREPARE ū┤æBż╦▀węŲżĘż┐ż│ż╚ż“┤_šJżĘż┐żķĖ„ūį RESOLVE ż╦╚ļż├żŲżżż» 4. CAPTURE: źąź├ź»ź░źķź”ź¾ź╔żŪź┴ź¦ź├ź»ź▌źżź¾ź╚ż“Ģ°ż»ū┤æB ╚½åTż¼RESOLVEū┤æBż╦▀węŲżĘż┐ż│ż╚ż“┤_šJżĘż┐żķĖ„ūį CAPTUREż╦╚ļż├żŲżżż» ╚½åTż¼CAPTUREż╦╚ļż├ż┐żķźąź├ź»ź░źķź”ź¾ź╔ż╬checkpointerż¼Ųäėż╣żļ 5. COMPLETE: ź┴ź¦ź├ź»ź▌źżź¾ź╚ż¼═Ļ┴╦żĘż┐ż│ż╚ż“╩Šż╣ū┤æB
- 14. CALC [1] ContĪ»d ? CALCż╬┐╝ż©ĘĮ ? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ VPoC (PREPAREż╚ RESOLVEż╬ķg) ż╬ßßż╦īgąążĄżņżļ REST PREPARE RESOLVE CAPTURE COMPLETE VPoC Checkpointer works ? Checkpointerż¼VPoCĢrĄŃżŪż╬Ė„źŪ®`ź┐ż“šiż▀╚ĪżņżļżĶż”ż╦żĘż┐żż
- 15. CALC [1] ContĪ»d ? CALCż╬┐╝ż©ĘĮ ? ź┴ź¦ź├ź»ź▌źżź¾ź╚żŽ VPoC (PREPAREż╚ RESOLVEż╬ķg) ż╬ßßż╦īgąążĄżņżļ REST PREPARE RESOLVE CAPTURE COMPLETE VPoC Checkpointer works Stable versions (delta) ? Checkpointerż¼VPoCĢrĄŃżŪż╬Ė„źŪ®`ź┐ż“šiż▀╚ĪżņżļżĶż”ż╦żĘż┐żż ? CALCżŪżŽŻ¼ stable versions ż“šiżßżą╚ĪżņżļżĶż”ż╦ż╣żļ ? PREPARE ū┤æBżŪūŅßßż╦źŪ®`ź┐ż“Ė³ą┬żĘż┐╚╦żŽ stable versionsżŌĖ³ą┬ż╣żļ ? RESOLVE ū┤æBżŪūŅ│§ż╦źŪ®`ź┐ż“šiż¾ż└╚╦żŽ stable versionsż╦żŌź│źį®`ż╣żļ
- 16. CALC [1] ContĪ»d ? Ė„źŁ®`ż╦źąź├źšźĪż“Č■ż─ (live, stable) ė├ęŌż╣żļ ? `stable_status` ż╚żżż”źėź├ź╚┼õ┴ąż“ė├ęŌż╣żļ ? Checkpointerż½żķęŖżŲŻ¼db[key].stable żŽ stable_status[key] is true ż╬ż╚żŁVPoCż╬żŌż╬ ? żĮż”żŪż╩żżł÷║ŽżŽŻ¼live version ż¼Ė³ą┬żĄżņżŲżżż╩żżż╚żżż”ż│ż╚ż╩ż╬żŪŻ¼żĮż╬ż▐ż▐šiżßżļ
- 17. CALC [1] ContĪ»d ? ź╩źż®`źųż╩ź╣ź╩ź├źūźĘźńź├ź╚ż╚Fuzzy checkpointż└ż╚ź╣źļ®`źūź├ź╚ż¼ź╝źĒż╦ż╩żļż¼Ż¼Ų┌ķgżŽČ╠żż ? Zig-Zag / Ping-Pong żŽź┴ź¦ź├ź»ź▌źżź¾ź╚ųąż╬ź╣źļ®`źūź├ź╚ż¼┬õż┴żļŻ« ? Ping-Pong żŽźŪ®`ź┐1ż─ż╦ż─żŁ3ż─ż╬źąź├źšźĪ (AS, Odd, Even) ż“ė├ęŌż╣żļż┐żßŻ¼źßźŌźĻ/źŁźŃź├źĘźÕä┐┬╩ż¼ÉÖżż ? ĮYŠų Long Txż¼Į╗żĖżļ (b) ż└ż╚ PPoC ż“ū„żļż┐żßż╦ż▀ż¾ż╩ąį─▄ż¼ÉÖż»ż╩żļż¼Ż¼ CALC żŽżĶż»żõż├żŲżżżļŻ«
- 18. CPR [2] ? CALCż╬Ė─╔Ų ? CALCżŽųąčļźŪ®`ź┐śŗįņ commit_log ż¼▒žę¬żŪŻ¼ż│żņż“ijżĘż┐ ? commit_log ż╦żŽĖ„ź╣źņź├ź╔ż╬żżżļū┤æB/ż│żņż½żķ╩╝ż▐żļū┤æBż¼Ģ°żżżŲżóż├ż┐ ? LineairDBżŪż│żņż“īgū░ & Ė─╔ŲżĘż▐żĘż┐
- 19. CPR [2] ContĪ»d ? ū┤æB▀węŲż“ Epoch Framework [5] żŪżõż├żŲżżżļż╬ż¼novelty ? atomic<int> epoch ż╚ atomic<int>[] thread_local_epoch żŪū┤æB▀węŲż╣żļ ? thread_local_epoch ż¼╚½żŲ═¼żĖ╩²éÄż╦ż╩ż├ż┐ż╚żŁ epoch ż“źżź¾ź»źĻźßź¾ź╚ż╣żļ
- 20. CPR [2] ContĪ»d ? CPR żŽ 4-phases ż½żķż╩żļ ? VPoCż╬Ū░ßßż╬ū┤æBż“ū„ż├żŲŻ¼żĮż│żŪĖ„ź╚źķź¾źČź»źĘźńź¾ż¼żĶżĘż╩ż╦ stable versionsż“▓┘ū„żĘżŲżż ż»???ż╚żżż”ż╬żŽCALCż╚ ╚½ż»═¼żĖ ? ū┤æB▀węŲż“ Epoch Framework [5] żŪżõż├żŲżżżļż╬ż¼novelty ? atomic<State> state ż╚ atomic<State>[] thread_local_state żŪū┤æB▀węŲż╣żļ ? thread_local_State ż¼╚½żŲ═¼żĖż╦ż╩ż├ż┐ż╚żŁ ┤╬ż╬ phase ż╦ąąż»Ż«źųźĒź├źŁź¾ź░żĘż╩żżż╬ż¼ēėżĻ ? PREPARE ż¼ IN-PROGRESS ż╬źŪ®`ź┐ż“šiż¾żŪżĘż▐ż”ż╚żŁżŽŻ¼źóź▄®`ź╚ż╣żļ ? ż│ż╬źóź▄®`ź╚żŽ CALC żŪżŌ▒žę¬ż╩źŽź║ż└ż¼Ż¼šō╬─ųąż╦ę╗Ūąėø╩÷ż¼ż╩żż IN- PROGRESS WAIT FLUSH REST PREPARE ? (? + 1) ? ? ? Aborts some transactions
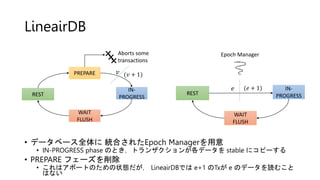
- 21. LineairDB ? źŪ®`ź┐ź┘®`ź╣╚½╠Õż╦ Įy║ŽżĄżņż┐Epoch Managerż“ė├ęŌ ? IN-PROGRESS phase ż╬ż╚żŁŻ¼ź╚źķź¾źČź»źĘźńź¾ż¼Ė„źŪ®`ź┐ż“ stable ż╦ź│źį®`ż╣żļ ? PREPARE źšź¦®`ź║ż“Ž„│² ? ż│żņżŽźóź▄®`ź╚ż╬ż┐żßż╬ū┤æBż└ż¼Ż¼ LineairDBżŪżŽ e+1 ż╬Txż¼ e ż╬źŪ®`ź┐ż“šiżÓż│ż╚ żŽż╩żż IN- PROGRESS WAIT FLUSH REST PREPARE ? (? + 1) ? ? ? Aborts some transactions IN- PROGRESS WAIT FLUSH REST ? (? + 1) Epoch Manager
- 22. Unknowns ? WALż“ź│ź¾źčź»źĘźńź¾żĘżŲź┴ź¦ź├ź»ź▌źżź¾ź╚ż╣żļ╩ųĘ©Ż¼╔┘ż╩ż╣ ż« ? ż╩ż╝Ż┐ ? źšźĪźżźļż“┤źżļż╚üKąąąįż¼Ą═żżŻ©e.g., lock) ż½żķŻ┐
- 23. References 1. Kun Ren, Thaddeus Diamond, Daniel J. Abadi, and Alexander Thomson. 2016. Low-Overhead Asynchronous Checkpointing in Main-Memory Database Systems. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD '16). Association for Computing Machinery, New York, NY, USA, 1539©C1551. https://doi.org/10.1145/2882903.2915966 2. Guna Prasaad, Badrish Chandramouli, and Donald Kossmann. 2020. Concurrent Prefix Recovery: Performing CPR on a Database. SIGMOD Rec. 49, 1 (March 2020), 16©C23. https://doi.org/10.1145/3422648.3422653 3. C. Mohan, Don Haderle, Bruce Lindsay, Hamid Pirahesh, and Peter Schwarz. 1992. ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging. ACM Trans. Database Syst. 17, 1 (March 1992), 94©C162. https://doi.org/10.1145/128765.128770 4. Tuan Cao, Marcos Vaz Salles, Benjamin Sowell, Yao Yue, Alan Demers, Johannes Gehrke, and Walker White. 2011. Fast checkpoint recovery algorithms for frequently consistent applications. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of data (SIGMOD '11). Association for Computing Machinery, New York, NY, USA, 265©C276. https://doi.org/10.1145/1989323.1989352 5. Stephen Tu, Wenting Zheng, Eddie Kohler, Barbara Liskov, and Samuel Madden. 2013. Speedy transactions in multicore in-memory databases. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (SOSP '13). Association for Computing Machinery, New York, NY, USA, 18©C32. https://doi.org/10.1145/2517349.2522713