Cloud Computing - Geektalk
?Download as PPTX, PDF?
2 likes?2,045 views

This document discusses various considerations for cloud computing applications including scalability, the cloud environment, cloud native applications, common cloud patterns, and challenges. Specifically, it covers: - Achieving horizontal and vertical scalability by adding/increasing compute and storage resources - How the cloud enables on-demand resources and pay-per-use models - Designing applications to leverage cloud services and scale horizontally across nodes - Common patterns for queue-based workflows, auto-scaling, data partitioning, and handling failures - Challenges of network latency, node failures, and transient service unavailability



















Cloud Computing - Geektalk
- 2. Malisa Ncube Developer Evangelist ¨C Microsoft be.com@malisancube inbox@malisancube.com
- 4. What does it take to run an app? Inspired by Steve Marx http://blog.smarx.com/posts/what-is-windows-azure-a-hand-drawn-video
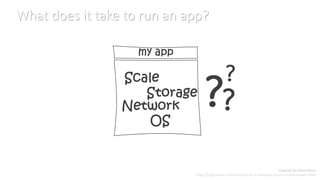
- 5. What does it take to run an app?
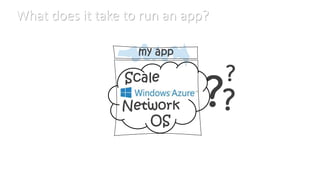
- 6. What does it take to run an app?
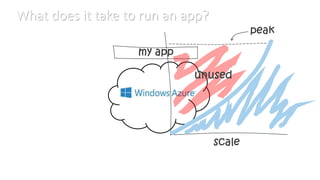
- 7. What does it take to run an app?
- 8. Scalability ? Measured by the number of users that the application can support effectively at the same time. ? Relates to hardware resources needed (CPU,Memory, Disk and network bandwidth. ? Application logic runs on compute nodes and data on data nodes. ? Vertical scaling is achieved by increasing resources within existing nodes. This is limited by hardware. ? Horizontal scaling is achieved by adding more nodes. It is more efficient with homogeneous nodes. ? A scale unit is a combination of resources that needs to be scaled together in horizontal homogeneous nodes. ? Resource contention limits scalability. ? Scalability is business concern. Google noticed a 20% reduction in traffic after introducing 500ms to page response time. Amazon 100ms caused 1% decrease in revenue.
- 9. The cloud ? Gives (illusion) infinite resources and limited by capacity of individual virtual machines. ? Enabled by short term resource rental model ? Enabled by metered pay-for-use model. Usage costs are transparent. ? Enabled by self-service, on-demand, programmatic provisioning and releasing of resources, scaling is automatable. ? Gives an ecosystem of managed platform services such as VMs, data storage, networking, messaging and caching. ? Gives a simplified application development model.
- 10. A cloud native application ? Lets the platform do the hard stuff by leveraging the application services. ? Uses non-blocking asynchronous communication in a loosely coupled architecture. ? Scales horizontally in an elastic mechanism. ? Does not waste resources ? Handles scaling events, node failures, transient failures without downtime or performance degradation. ? Uses geographic distribution to minimize network latency. ? Upgrades without downtime. ? Scales automatically using proactive and reactive actions. ? Monitors and manages application logs as nodes come and go.
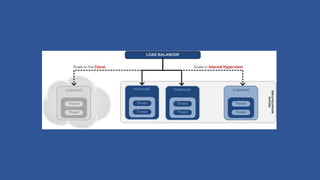
- 12. Horizontal scaling compute Pattern ? Horizontal scaling is reversible. ? Supports scaling out and scaling in ? Stateful nodes ? They keep user session information ? They have single point of failure ? Stateless nodes ? Store session information externally from the nodes.
- 14. Queue-Centric Workflow Pattern ? Used in web applications to decouple communication between web-tier and service tier by focusing on the flow of commands. ? A service tier that is unreliable or slow can affect the web tier negatively. ? All communication is asynchronous as message over a queue ? The sender and receiver are loosely coupled. Neither one knows about the implementation of the other. ? There is some edge cases where the risk of invisibility windows occurs when processing takes longer than allowed. ? Idempotency concerns. Database transactions, compensating transaction. ? Poison messages placed in dead letter queue. ? QCW is not full CQRS as it does not articulate the read model.
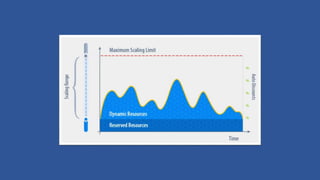
- 15. Autoscaling Pattern ? Assumes horizontal scaling architecture ? Concerns are cost optimization and scalability ? Auto-scaling solutions enable scheduled (proactive and reactive) rules that enable the provisioning of resources as needed. ? Throttling by selectively enabling or disabling features or functionality based on environmental signals.
- 17. Eventual Consistency ? Simultaneous requests for the same data may result in different values. ? Leads to better performance and lower cost. ? Uses BrewerˇŻs CAP theorem (Consistency Availability and Partition tolerance). 3 Guarantees and application an pick only 2. ? Consistency. Everyone get the same answer. ? Availability. Clients have ongoing access (even if there is a partial system failure) ? Partition tolerance. Means correct operation even if some nodes are cut of from the network. ? DNS updates and NoSQL are examples of eventually consistent services.
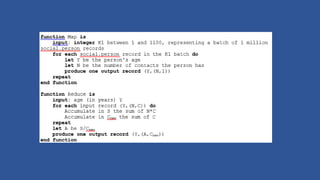
- 18. MapReduce Pattern ? Data processing approach for processing highly parallelized datasets. ? Require a mapper and reducer functions. Accepting data and producing output with subsets of data and output of the mapper aggregated and sent to the reducer. ? Used to process documents, server logs, social graphs. ? Hadoop implements MR as a batch processing system, optimized for large amounts of data than response time. ? Created by Google Inc. ? Most effective to bring compute function to data ? Commonly refered to as BigData. ? Hadoop has abstractions on top that create functions e.g. (Mahout - ML, Hive ¨C SQL like, Pig ¨C dataflow, Sqoop ¨C RDBMs connector)
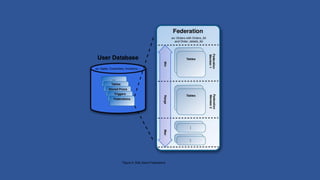
- 20. Database sharding/Federation Pattern ? A database divided into several shards, where each database row exists only on one shard. ? Shards do not reference other shards. ? Slave shard nodes a typically eventually consistent and readonly. ? Programming model is simplified by maintaining a single logical database with horizontal scaling. ? Fan-Out queries used to make updates to dependent federation members. Similar to Windows Azure SQL Data Sync and MapReduce.
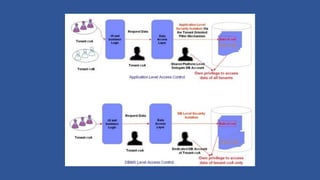
- 22. Multitenancy and commodity Hardware ? Multitenancy ¨C multi companies using the system, usually a software system with an illusion that they are the only tenant. ? Multitenancy in the cloud are standard: DNS Services, Hardware for VMs, Load balancers, Identity management among others. ? Commonly used in SaaS environments where each tenant runs in a secure sandbox (HyperV, RDBMS). ? Perfomance managed by using quotas, running resource hungry service with those less intensive. ? Commodity hardware fails occasionally. Plan on it happening on your compute nodes and plan on handling it.
- 24. Busy Signal Pattern ? Applies to services or resources accessed over a network where a signal response is busy. ? These may include management, data services and more, and periodic transient failure should be expected. E.g. Busy signal on telephones. ? A good application should be able to handle retries and properly handle failures. ? On HTTP. Response 503 Service Unavailable. ? Clearly identify Busy Signal and Errors and retry on Busy state after an interval. Log them for further analysis of patterns.
- 26. Node Failure Pattern ? Concerns availability and graceful handling of unexpected application/hardware failures, reboots or node shutdown. ? Application state should be in reliable storage, not on local disk or individual node. ? Avoid single point of failure by using the N+1 rule. ? AWS & Azure send signals from nodes indicating shutdown and traffic is routed to different tenants. ? An approach would include having the UI code to retry on failures, throttling some of the features while the recovery is taking place. ? Azure runs in two fault domains
- 27. Network latency problem ? Network latency is a function of distance and bandwith ? Consider Data Compression, Background processing, Predictive Fetching. ? Move applications closer to users ? Move application data closer to users ? Ensure nodes within your application are closer together (Colocation) ? WA uses Affinity Groups ? Consider Valet/Key Pattern for public or temporary access. (Blob storage) protected through hashing. ? Consider Content Delivery Network (CDN) ¨C global distributed cache effective for frequently accessed content. Can be inconsistent.
- 28. Feedback, materials and contacts @malisancube
Editor's Notes
- #5: Before I start, lets take a moment to think about what it takes to actually run an app on the internet <<click>> ThereˇŻs a lot to think about, we need to think about the <<click>> operating system that we use and how to keep that patched up <<click>> We need to think about the network, routers, load balancers, and DNS and how there will interact with our system <<click>> We need to think about storage needs for our application and how to manage all that data <<click>> And we need to think about scale, how are we going to scale to our many users, who are geographically distributed <<click>> I need to point out that this applies to any application, not just ours and more importantly, what does all of this have to do with our application?
- #6: But what if there was a different way, What if there was something that would take care of all those other things for us <<click>> All the operating systems, the networking, the storage, the scale <<click>> And let us worry about what we care about the most, OUR APPLICATION! <<click>> With something like that, we could build our application faster and we could keep our users happy <<click>> This is the idea behind Windows Azure. Windows Azure is MicrosoftˇŻs cloud computing platform. That means it is designed to run your application, at scale out on the internet.
- #7: Now letˇŻs talk about scale <<click>> If you are like most application owners, youˇŻre hoping your application scales like this <<click>> Notice, that this is your peak, and if you have to pay upfront for the resources you are going to use at the peak <<click>> YouˇŻll be wasting all of this <<click>> With Windows Azure, instead, you will be paying for the resources only when you need them
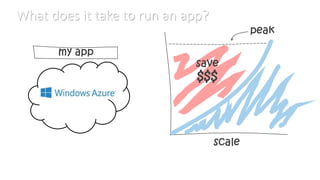
- #8: With that model you can <<click>> stop worrying about what your peak is and save a lot of money And it is more than hosting too, Windows Azure gives you: elasticity scalability economics * pay as you go And self service
- #27: If your application has N upgrade domains, Fabric Controller will manage upgrades such that 1/N role instances will be impacted Azure VIP Swap feature to avoid deploying multiple concurrent versions
- #29: WeˇŻre really excited about what you can do with Azure WeˇŻre really looking forward to seeing what you build with it Sign up for your free 90-day trial using the link above, and make sure to follow me and AfricaApps account on twitter for the latest updates on Azure and other upcoming events. IˇŻd love to hear your feedback on this presentation, so please scan this code and youˇŻll find the feedback form, along with the material presented today. And I want to thank everyone here for coming to the Africa Developer Camp and for this session Thanks, and enjoy the rest of the camp