Cluster
Download as PPTX, PDF0 likes286 views

This document proposes representing videos using local feature clusters to capture spatial and temporal information ignored by bag-of-features representations. It groups local features into clusters based on their proximity in space and time. Each cluster is represented independently using bag-of-features to localize actions. An experiment on classifying 7 actions from TRECVID videos found the optimal number of clusters varies by action class, with performance generally improving up to 8-16 clusters before declining with more clusters.









Cluster
- 2. Intro âĒ Overview âĒ Video as a cloud of feature points âĒ Clusters of feature points âĒ Video representation âĒ Classification âĒ Decision making âĒ Result
- 3. Overview âĒ In Bag-of-Features (BOF) representation, the spatio- temporal configuration of video is ignored âĒ Proposed approach is to integrate spatio-temporal structure in video representation. â Local features are grouped ( refered as cluster ) based on their spatio-temporal proximity â Each group , or cluster, will be independently represented as BOF, (refered as cluster-level BOF). âĒ It will allow to localize the action in the video segment.
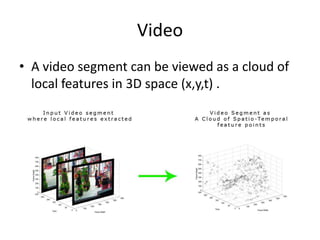
- 4. Video âĒ A video segment can be viewed as a cloud of local features in 3D space (x,y,t) .
- 5. Local feature grouping âĒ Intuition: Closely localized features ( in spatio-temporal domain) are more likely to be correspond to a same object, and far ones are more unlikely. âĒ In order to exploit this idea, a tree cluster is used to group local features based on their spatio-temporal proximity. In this example, local feature points grouped into two clusters ( red & blue )
- 6. Cluster-level BOF âĒ Once local features are grouped as a cluster, each cluster is represented using BOF approach ( will be referred as cluster-level BOF) . â A frequency histogram will be generated over local descriptors which belong to a particular cluster.
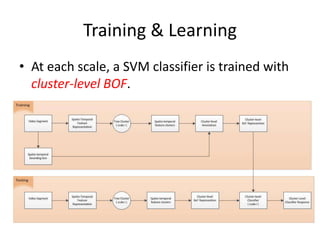
- 7. Training & Learning âĒ At each scale, a SVM classifier is trained with cluster-level BOF.
- 8. Experimental study âĒ Action segments from TRECVID SED is used for training & testing. â 7 action class: CellToEar, Embrace, ObjectPut, PeopleMeet, Peopl eSplitUp, PersonRuns, Pointing. âĒ Training : 210 video segments in total â 30 videos segments per action class âĒ Testing: 138 video segments in total â approx.20 video segments per action class
- 9. Experimental study âĒ The spatio-temporal bounding box is manually drawn for both test & training set segments.
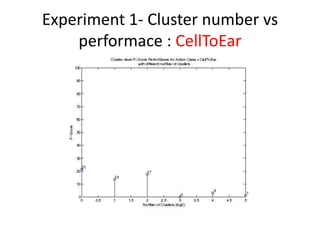
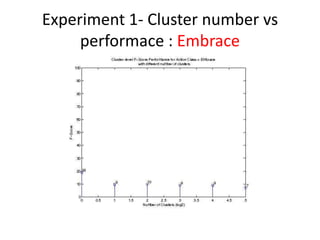
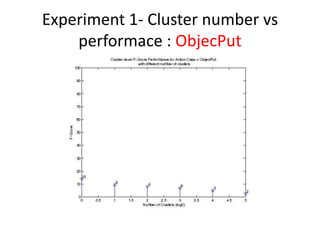
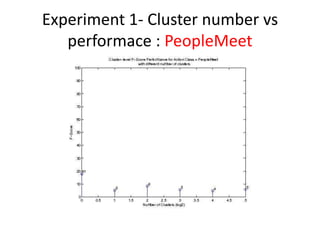
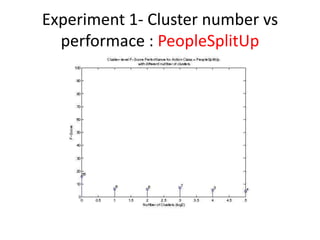
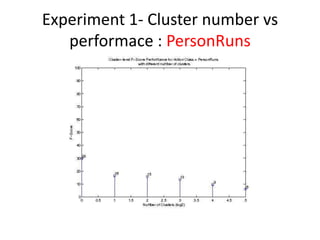
- 10. Experiment 1- Cluster number vs performace âĒ The optimal number of cluster is studied. â In the experiment, 6 different cluster number are chosen: 1,2,4,8,16 and 32. â For example: If the cluster number is 16, then it means that the video segment is divided into 16 sub-regions (cluster) and each has its own BOF histogram ( cluster- BOF) . Based on the bounding box information, the cluster- BOF is annotated.
- 11. Experiment 1- Cluster number vs performace : CellToEar
- 12. Experiment 1- Cluster number vs performace : Embrace
- 13. Experiment 1- Cluster number vs performace : ObjecPut
- 14. Experiment 1- Cluster number vs performace : PeopleMeet
- 15. Experiment 1- Cluster number vs performace : PeopleSplitUp
- 16. Experiment 1- Cluster number vs performace : PersonRuns
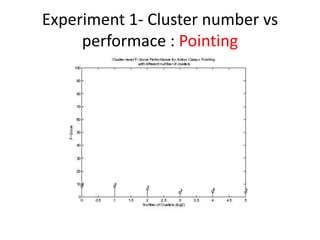
- 17. Experiment 1- Cluster number vs performace : Pointing
- 18. Conclusion âĒ The results is based on cluster-level BOF. âĒ To give segment-based result, the proper aggregation of cluster-BOFs, belong to same video-segment, is required. â The naÃŊve approach is to assign an action class, that has a highest vote from clusters, to its parent segment.