














Component-Based Entity Systemęģž Data-oriented Design
- 1. Component-based Entity System and Data-oriented Design 2016-11-12 ë°íė ėīėė°
- 2. Component Entity System OOPë ė ëëĶ°ę°? Data-orented Design ęē°ëĄ 01 02 03 04 MAIN TITLE
- 3. Component-based Entity System âĒ ęēė ę°ë° ëķėžėė ėĢžëĄ ėŽėĐëë ėíĪí ėģ íĻíī âĒ ComponentëĪė ėĄ°íĐíėŽ EntityëĨž ė ė âĒ ėŽęļ°ė ė ęđ!! ï§ Entityė Componentë ëŽīėėļę°ė?
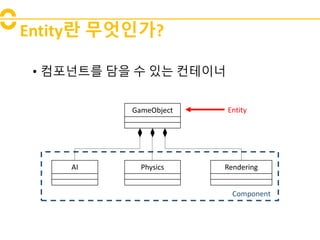
- 4. Entityë ëŽīėėļę°? âĒ ėŧīíŽëíļëĨž ëīė ė ėë ėŧĻí ėīë GameObject AI Physics Rendering Entity Component
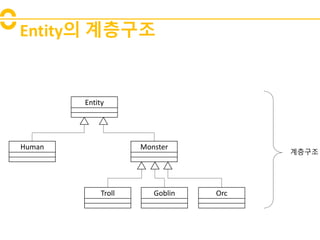
- 6. Entityė ęģėļĩęĩŽėĄ° Entity MonsterHuman Troll Goblin Orc ęģėļĩęĩŽėĄ°
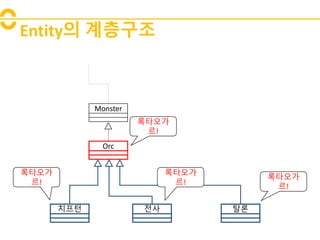
- 7. Entityė ęģėļĩęĩŽėĄ° Orc ėđííī ė ėŽ íëĄ Monster ëĄíėĪę° ëĨī! ëĄíėĪę° ëĨī! ëĄíėĪę° ëĨī! ëĄíėĪę° ëĨī!
- 8. ėžë°ė ėļ CES in OOP âĒ ė―ë ėė âĒ https://github.com/sukwoo22/DataOrientedDesign
- 9. ėžë°ė ėļ CES in OOP ėí°í° ë°°ėī AI ėí°í° ėí°í° ėí°í° ėí°í° 뎞ëĶŽ ë ëë§ AIë ëë§ ëŽžëĶŽ 뎞ëĶŽ 뎞ëĶŽ AI AI ë ëë§ ë ëë§
- 10. OOP is Good? âĒ ėŽėŽėĐíęļ° ėĒëĪ âĒ íėĨėąėī ėĒëĪ âĒ ė ė§ ëģīėę° ėĐėīíëĪ âĒ ę·ļëŽëâĶ.. ėąëĨėī ëëŽī ëëĶŽëĪ
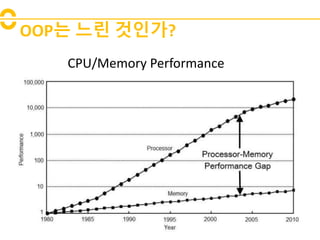
- 11. OOPë ëëĶ° ęēėļę°? CPU/Memory Performance
- 12. OOPë ëëĶ° ęēėļę°? CPU Die CPU L1 Cache L2 Cache fast slower Main RAMslowest d a t a Cache Line
- 13. ėšėĪ ëŊļėĪę° ë°ėëë ėīė ë? ėí°í° ë°°ėī ėí°í° ėí°í° ėí°í° ėí°í°
- 14. ėŽęļ°ė ė ė ėë ėŽėĪ âĒ ęļ°ėĄīė OOPëĄ ęĩŽėąë ėėĪí ė íë íëėĻėīė ė íĐí ėėĪí ėī ėëëĪ!!! âĒ ę·ļëž ėīëŧęē íėĢ ? âĒ Data-oriented Design !!! -> ėšėŽëĨž ėĩëí ėīėĐíė!
- 15. Data-Oriented Design âĒ íëėĻėī ėđíė ėļ ëėėļ íĻíī -> ėšė ëŊļėĪëĨž ėĩėí íė! âĒ DoD = DDD (Data-driven Design) ? NO! âĒ OOP, DDD, ė ė°Ļí and íĻė íëĄę·ļëë° ėīëë ė ėĐę°ëĨíëĪ!
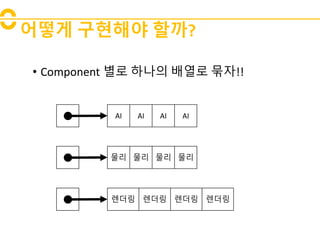
- 16. ėīëŧęē ęĩŽííīėž í ęđ? âĒ Component ëģëĄ íëė ë°°ėīëĄ ëŽķė!! AI AI AI AI 뎞ëĶŽ 뎞ëĶŽ 뎞ëĶŽ 뎞ëĶŽ ë ëë§ ë ëë§ ë ëë§ ë ëë§
- 17. ėīęąļëĄ ë? âĒ ëđė ė ëí° íëę·ļëĨž ėŽėĐíëę°? ï§ ė―ë ėė âĒ ëí° íëę·ļė ëŽļė ė ï§ CPUė ëķęļ° ėėļĄ ėĪíĻ -> íėīíëžėļė ė§ė° âĒ íīęē°ėą (ė―ë ėė ) âĒ https://github.com/sukwoo22/DataOrientedDesign
- 18. ë ėĩė íí ë°Đëēė ėėęđ? âĒ ėŧīíŽëíļę° íŽëĪëĐī ėšėĪ ëŊļėĪę° ë°ėí íëĨ ėī ëëĪ âĒ ëđëēíęē ėŽėĐëë ë°ėīí°ė íė°í ë°ėīí°ëĄ ëëė!!! ï§ (ė―ë ėė ) ï§ https://github.com/sukwoo22/DataOrientedDesign
- 19. ęē°ëĄ âĒ ęļ°ėĄīė OOPë íë íëėĻėīė ėđíė ėīė§ ėëĪ. âĒ íė§ë§ OOP ėĨė ė ëēëĶŽęļ° ėęđëĪ! âĒ ë°ëžė OOPė DoDëĨž íĻęŧ ėīėĐíė!! ï§ ėŧīíŽëíļ ëģëĄ ë°°ėīëĄ ëŽķëëĪ. ï§ ëí° íëę·ļ ėŽėĐė ėė íëĪ ï§ ë°ė ė―ëė íė°í ė―ëëĨž ëķëĶŽíëĪ.
- 20. ė°ļėĄ° âĒ ęēė íëĄę·ļëë° íĻíī â ėŧīíŽëíļ, ë°ėīí° ė§ėėą ï§ ė ė ëĄëēíļ ëėīėĪíļ륎, ëēė ë°ėž âĒ Pitfalls of Object Oriented Programming ï§ ë°í Tony Albech â Sony Technical Consultant âĒ Component Based Engine Design ï§ Randy Gaul â ëļëĄęą° âĒ Entity-systems.wikidot.com ï§ Entity Systems Wiki
- 21. contents 1 / contents 2 / contents 3 / contents 4 Q&A ę°ėŽíĐëëĪ!
Editor's Notes
- Component/Entity ėėĪí ė ęēė ę°ë° ëķėžėė ėĢžëĄ ėŽėĐëë ėíĪí ėģ íĻíīėīëĪ. CESë ėėė ėëĶŽëĨž ėīėĐíėŽ ėí°í°ëĨž ė ėíęģ íīëđ ę°ėēīė íđėąė ë§ęē ėŧīíŽëíļëĪė ėĄ°íĐí ė ėë ė ė°íęģ íĻėĻė ėļ ėėĪí ė ë§íĐëëĪ. ėŽęļ°ė Entityė Componentë ëŽīėėžęđė?
- ėŧīíŽëíļë ėí°í°ė íėí ęļ°ëĨëĪė ë ëĶ―ė ėžëĄ ė ėí ę°ėēīė ëëĪ. ėëĨž ëĪėī, ęēė ėėė íëíë 늎ėĪí°ėęē ėļęģĩė§ëĨęģž 뎞ëĶŽė ėļ íđėą ę·ļëĶŽęģ íëĐīė ëģīėŽėĢžęļ° ėí ë ëë§ėī íėíė§ė. ėí°í°ë ėŧīíŽëíļëĨž ëīë íëė ėŧĻí ėīëė ëëĪ. ėī ėŧīíŽëíļė ėĄ°íĐė íĩíīė íëĄę·ļëĻ ëīėė íđėí ėí ė ę°ė§ ę°ėēīëĄė ėĄīėŽíĐëëĪ.
- ę°ėī ėĪėëė? ėëĨž íëē ëĪėīëģīęē ėĩëëĪ. ęēė ė ėšëĶí°, íđė ėĄ°ęąīė ë§ėĄąėėžėž ë°ėëë ėīëēĪíļ, ëė ęģģęģģė ëėŽëĶŽë íļëĐ, ëĄë§Ļė Eėšęģž ę°ė ėėīí ëą ëŠĻë ėí°í°ę° ë ė ėėĩëëĪ.
- ėĪė ęēėėėë ëĪėíęģ ėļëķė ėļ ęļ°ëĨė ę°ė§ ėí°í°ę° íėëĄ íęļ° ëëŽļė, ėí°í°ë ęģėļĩęĩŽėĄ°ëĨž ėīëĢĻë ęēėī íđė§ė ëëĪ. ę°ėēī ė§íĨ íëĄę·ļëë°ėėë ėīëĨž ėėė íĩíīė ęĩŽííĐëëĪ. ëëķė ė―ëė ėŽíėĐėī ėëđ ëķëķ ę°ëĨíīė§ęģ ę·ļ ęē°ęģž ėííļėĻėīė ėė°ėąėī íĻėŽ ėĶę°íęē ëėĢ . ė ėŽęļ°ė ėīíīëĨž ëęļ° ėíī ėĪíŽëĨž ë ėļëķė ėžëĄ ėīíīëģīęē ėĩëëĪ.
- ėëĨž ëĪėī ėĪíŽ íđėąė ėė ë°ė ę°ėēīëĪė ęļ°ëģļė ėžëĄ íėī ėļęģ ėëė§ę° ë§ėĩëëĪ. ėīęēė ę° ę°ėēī íë íëëĨž ėžėžėī ė ėíë ęē ëģīëĪ ęģĩíĩë ėėąė Orc ėí°í°ė ëŽķėī ëęģ ėīęēė ėėë°ė íėí ėŧīíŽëíļë§ ėķę°íë ęēėī íĻėĻė ėīęļ° ëëŽļė ëëĪ.
- ėīė ė―ëëĨž ëģīëĐīė ėĪëŠ íī ëģīëëĄí ęđė? ëĻžė ėŧīíŽëíļ íīëėĪę° ėėĩëëĪ. ėŽęļ°ėë ë°ëģĩė ėžëĄ ę°ąė ëë ė ë°ėīíļ íĻėę° ėėĩëëĪ. ę·ļëĶŽęģ ėėė íĩíėŽ AIė Physics ę·ļëĶŽęģ ë ëë§ ėŧīíŽëíļëĨž ė ėíėėĩëëĪ. ë ëë§ ėŧīíŽëíļë ėķę°ė ėžëĄ ë ë íĻėę° ėęē ėĢ ? ę·ļëĶŽęģ ëĪėė ėī ėŧīíŽëíļëĪė ëīë ėí°í° íīëėĪ ė ëëĪ. ėí°í° íīëėĪėėë ę·ļ ėŧīíŽëíļė ëīė ë°°ėīėī ėęģ ėīęģģė ė―ė íęģ ė ęą°íë íĻėę° ėėĩëëĪ. ę·ļëĶŽęģ ėí°í°ëĪė ęīëĶŽíë ėí°í° ë§Īëė ļ íīëėĪëĪėī ėėĩëëĪ. ėī ë§Īëė ļė ëí ë°°ėīė ëĐėļ ėė§ėī ę°ė§ęģ ėėĩëëĪ. ėŽęļ°ėë ėė íīëėĪëĪė ėė°Ļė ėžëĄ ėííėŽ ę° ėŧīíŽëíļëĪė ëí ė ë°ėīíļė ë ë íĻėëĨž ëĐėļ ëĢĻíėė íļėķëëëĄ íĐëëĪ. ė, ėī ė―ëė ëŽļė ė ė ëęđė?
- ę·ļëĶžė ëģīëĐīė ėĪëŠ íęē ėĩëëĪ. ėėėė ę°ėī ė íĩė ėļ OOP ë°ĐėėžëĄ ė―ëĐė íëĐī íėīëž ëķëĶŽë ëĐëŠĻëĶŽ ęģĩę°ėė ę·ļëĶžęģž ę°ėī ëëĪíęē ėí°í°ė ėŧīíŽëíļëĪėī ėėąëĐëëĪ. ėëęģ ė? ė°ëĶŽę° ėŽėĐíë new íĪėëė ėėąėëĨž ėīėĐí ę°ėēī ėėą ë°Đėė ę°ėēīëĪė ėėđęđė§ ė ë ŽėėžėĢžė§ ėęļ° ëëŽļėīėĢ . ėīęēė ėšė ëŊļėĪę° ë°ėí íëĨ ė ëėīë ėėļėžëĄ íëĄę·ļëĻ ėąëĨė ėėĒė ėíĨė ëžėđĐëëĪ.
- ė ė ëĶŽíī ëģžęđė?
- ëėēī ė ėīë ęē ëëĶīęđė? ę·ļ ėīė ë ëĐëŠĻëĶŽė CPUė ėąëĨė°Ļėīė ėėĩëëĪ. 1980ë ėë CPUė ëĐëŠĻëĶŽė ėąëĨ ė°Ļėīę° ęą°ė ėėėĩëëĪ. íė§ë§ ė§ęļė ę°ėëĄ ę·ļ ė°Ļėīę° íęēĐíęē ëēėīė§ęģ ėėĢ . ėī ëëŽļė CPUę° ėëŽīëĶŽ ëđ ëĨīëëžë ëĐëŠĻëĶŽëĄëķí° ë°ėīí°ëĨž ė―ėī ėĪęļļ ęļ°ëĪëĶŽëëž CPUė ėĪíėī ëĐėķęē ëë ëģëŠĐ íėėī ėęļ°ęē ëėĢ .
- ëĐėļ RAMėė ë°ėīí°ëĨž ę°ė ļëĪ ė°ë ëđėĐė ėĪėīęļ° ėíīė ėĪëë ė íëĄėļėë ėšėëĨž ėīėĐíĐëëĪ. ėšėë CPU ë°ëĄ ėė ëķėī ėë ęģ ėąëĨ ëĐëŠĻëĶŽė ëëĪ. ėĶ, ëĐėļëĻėė ë°ėīí°ëĨž ė§ė ë°ėėĪëĐī ëëĶŽė§ë§ ėšėëĨž ėīėĐíëĐī íĻėŽ ëđĻëžė§ė§ė. íė§ë§ ėšėėė ë°ėīí°ëĨž ė―ėīėĪęļ° ėíīė ëĻžė ëĐėļëĻėė ėšėŽëĄ ëĐëŠĻëĶŽ ėĄ°ę°ė ėīëėíĪë ęģžė ėī íėíĐëëĪ. ėī ëĐëŠĻëĶŽ ėĄ°ę°ė ėšė ëžėļėīëžęģ íĐëëĪ. ėšė ëžėļė íėŽ íėí ë°ėīí° íëë§ėī ėëëž ę·ļ ë°ėīí° ėĢžëģ ëĐëŠĻëĶŽęđė§ íŽíĻëėĢ .
- ėšėė ë°ėīí°ę° ėėīė ëĐėļ ëĻėė ë°ėīí°ëĨž ė―ėīėĪë ęē―ė°ëĨž ë°ëĄ ėšė ëŊļėĪëž íë ë°ė. ė ëĪė ëĪëĄ ëėę°ė ë°Đęļ ė ė ė―ëë ė ėšė ëŊļėĪëĨž ë°ėėíĪë ęąļęđė? ėí°í° ė°ĻëĄëĄ ė―ėī ėĻëĪęģ ęģžė íī ëī ėëĪ. ė ëĻžė 1ëē ėí°í°ë ėēėėīëęđ ëđė°í ėšėė ėęē ėĢ ? ėšė ëŊļėĪę° ë°ėíĐëëĪ. ëė ėí°í° ėĢžëģ ëĐëŠĻëĶŽ ėĄ°ę°ė ėšėëĄ ėīëėíĩëëĪ. 2ëē ėí°í°ë ėšėė ėėęđė? ėėĢ . ë ėšė ëŊļėĪę° ë°ėíëĪė. ëĪė ėšė ëžėļė ėšėëĄ ėīëėíĩëëĪ. 3, 4ëēë ë§ė°Žę°ė§ëĄ ėšė ëŊļėĪę° ë°ėíĐëëĪ. ėīė ėīíī ëėëė? ėīë ęļ° ëëŽļė ė íĩė ėļ OOP ë°ĐėėžëĄ ė―ëĐíëĐī ëŽļė ę° ëë ęēëëĪ.