































Computer Vision and GenAI for Geoscientists.pptx
- 1. Computer Vision and GenAI in Geoscience YOHANES NUWARA PETROLEUM ENGINEERS ASSOCIATION (PEA) Trondheim, 28.07.2024
- 2. Yohanes Nuwara Career: ˇń Data scientist at Prores AS, Norway (2024-) ˇđ Computer vision for porosity and permeability prediction from core images ˇń Lead data analyst at APP Sinarmas, Indonesia (2022-2023) ˇđ Sustainability dashboard for management ˇń Expert data scientist at APP Sinarmas, Indonesia (2022-2023) ˇđ LiDAR, computer vision for remote sensing UAV ˇń Research engineer at OYO Corporation, Japan (2020-2022) ˇđ Distributed Acoustic Sensing (DAS) for earthquake seismology Education: ˇń Politecnico di Milano, Italy (2023-) ˇđ MasterˇŻs in Business Analytics and Big Data ˇń Bandung Institute of Technology, Indonesia (2015-2019) ˇđ BachelorˇŻs in Geophysical Engineering
- 3. Outline ˇń What is computer vision? ˇń Computer vision methods and models ˇń Use case 1: Automatic rock typing using segmentation model ˇń Use case 2: Boulder detection for seabed mapping ˇń Challenges in computer vision ˇń What is Generative AI? ˇń Generative vision models ˇń Conclusion
- 5. What is computer vision? Computer vision is a scientific field which task is to understand image based on its pixel information using traditional image analysis and artificial intelligence 1 2 3 4
- 6. Why computer vision is so growing??? 6 Rapid growth of computers and hardware chips Bigger, modern, and more secure data storage Rapid evolution of AI computer vision models More and more advanced optics and camera technologies
- 7. Computer Vision in geoscience Seismic interpretation Petrophysics Geology Remote sensing
- 8. Methods of computer vision
- 9. How computers see images? ˇń Computers see image as Pixels(unit of image that has 3 color channels: Red, Green, Blue) ˇń Color is represented as the value intensity of each color channel (0<Intensity<255) ˇń Therefore, image is a 3-D array ˇú (Pixel width, pixel height, channels) ˇń In remote sensing, image can be composed of more than 3 color channels Illustration of pixel representation on the LCD screen Color channels of an image Pixel width Pixel height
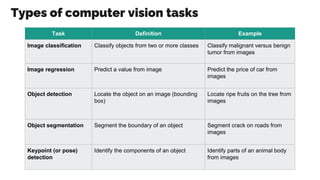
- 10. Types of computer vision tasks Task Definition Example Image classification Classify objects from two or more classes Classify malignant versus benign tumor from images Image regression Predict a value from image Predict the price of car from images Object detection Locate the object on an image (bounding box) Locate ripe fruits on the tree from images Object segmentation Segment the boundary of an object Segment crack on roads from images Keypoint (or pose) detection Identify the components of an object Identify parts of an animal body from images
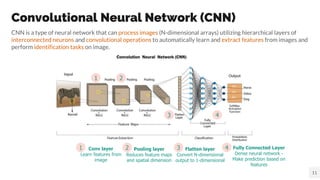
- 11. Convolutional Neural Network (CNN) CNN is a type of neural network that can process images (N-dimensional arrays) utilizing hierarchical layers of interconnected neurons and convolutional operations to automatically learn and extract features from images and perform identification tasks on image. 11 Fully Connected Layer Dense neural network - Make prediction based on features Conv layer Learn features from image Pooling layer Reduces feature maps and spatial dimension Flatten layer Convert N-dimensional output to 1-dimensional 1 2 3 4 1 2 3 4
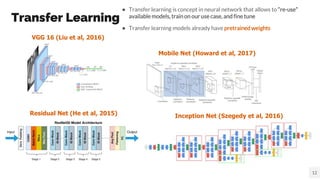
- 12. Transfer Learning ˇń Transfer learning is concept in neural network that allows to ˇ°re-useˇ± available models, train on our use case, and fine tune ˇń Transfer learning models already have pretrained weights 12 Residual Net (He et al, 2015) Inception Net (Szegedy et al, 2016) VGG 16 (Liu et al, 2016) Mobile Net (Howard et al, 2017)
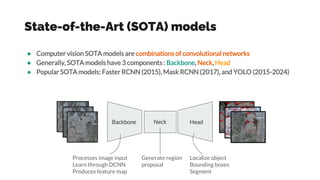
- 13. State-of-the-Art (SOTA) models ˇń Computer vision SOTA models are combinations of convolutional networks ˇń Generally, SOTA models have 3 components : Backbone, Neck, Head ˇń Popular SOTA models: Faster RCNN (2015), Mask RCNN (2017), and YOLO (2015-2024) Backbone Head Neck Processes image input Learn through DCNN Produces feature map Generate region proposal Localize object Bounding boxes Segment
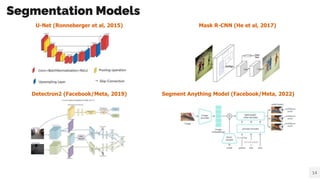
- 14. Segmentation Models Detectron2 (Facebook/Meta, 2019) Segment Anything Model (Facebook/Meta, 2022) 14 U-Net (Ronneberger et al, 2015) Mask R-CNN (He et al, 2017)
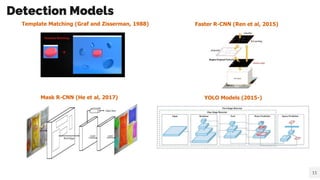
- 15. Detection Models Mask R-CNN (He et al, 2017) YOLO Models (2015-) 15 Template Matching (Graf and Zisserman, 1988) Faster R-CNN (Ren et al, 2015)
- 16. Keypoint Detection ˇń Objects consists of a predefined set of keypoints and connections between them ˇń Very popular in human movement analysis (pose detection) ˇń Popular model such as the 8th version YOLO (YOLOv8 Pose) ˇ°Objects as keypointsˇ± Human movement analysis (Source: OpenVino)
- 17. Use case 1: Automatic rock typing from core
- 18. Core image interpretation Drilling activity Core sample Lithology description done by petrophysicists ˇń Drilling core presents geological evidence that is used to find the oil in the rocks underneath ˇń The drilling core is then brought to the lab to be analysed ˇń Lithology description is done by petrophysicists in the lab ˇń ItˇŻs a very lengthy process!
- 19. Automatic rock typing from core image? Instead of human conducting lithology description, how about teaching Neural Networks to describe the lithology (later can be supervised by humans) ?
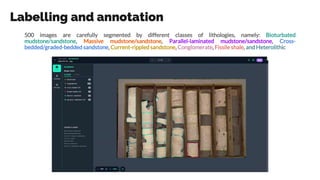
- 20. Labelling and annotation 500 images are carefully segmented by different classes of lithologies, namely: Bioturbated mudstone/sandstone, Massive mudstone/sandstone, Parallel-laminated mudstone/sandstone, Cross- bedded/graded-bedded sandstone, Current-rippled sandstone, Conglomerate, Fissile shale, and Heterolithic
- 21. Distribution of lithology classes Samples are too few ˇń Imbalance between number of instances of classes can severely affect the performance of computer vision model ˇń Imbalance makes high accuracy biased to class which has more instances than the others
- 22. Data augmentation ˇńA strategy to solve imbalanced class is called data augmentation ˇńData augmentation consists of different manipulations of image by rotation, flipping, and color space shifting ˇńAugmentation can also be used to improve the model generalization by training model on different image conditions Note: Only some augmentations are useful for particular use case. ? In core facies segmentation where color is important, the red box cannot be used WHY ?????
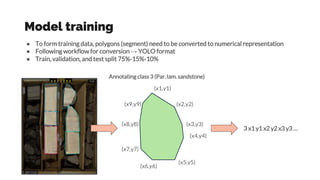
- 23. Model training (x1,y1) (x2,y2) (x3,y3) (x4,y4) (x5,y5) (x6,y6) (x7,y7) (x8,y8) (x9,y9) Annotating class 3 (Par. lam. sandstone) 3 x1 y1 x2 y2 x3 y3 ˇ ˇń To form training data, polygons (segment) need to be converted to numerical representation ˇń Following workflow for conversion ˇú YOLO format ˇń Train, validation, and test split 75%-15%-10%
- 24. Model evaluation ˇń How good and accurate our model is? ˇń Important metrics for instance segmentation: ˇđ Classification metrics: Precision, Recall, F1-score ˇđ Loss: Dice loss, IoU loss ˇđ Accuracy: Mean Average Precision (mAP50) ˇń Confusion matrix to show False Positives and False Negatives of model result
- 25. Segmentation result ˇń After the best model is achieved, model is used to predict lithologies from core image ˇń Inference time is very fast -> milliseconds per core image ˇń Can be used as ˇ°Quick QCˇ± for petrophysicists to review the automatic rock typing result Original core image Segmented core
- 26. Use case 2: Boulder detection for seabed mapping
- 27. Seabed mapping for offshore oil infrastructure ˇń Offshore oil rig or infrastructure need careful planning for its structural stability ˇń Side scan sonar survey is used to map the structure of the seabed and identify obstacles such as boulders Side scan sonar capturing the Port (P) and Starboard (S) side of the seabed mapping
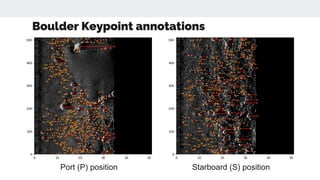
- 28. Keypoint Model for Seabed boulders ˇń Boulders are big rocks sedimented on the seabed, with dimension Length, Width, and Height ˇń The Length, Width are calculated as Length (oL) and Width (oW) of object ˇń How tall is the boulder???? ˇú calculated from Shadow (oS) ˇń Keypoint representation ˇú Object as head, while shadow as tail of keypoint Boulder center (Head) Shadow center (Tail) (Savini, 2010)
- 29. Boulder Keypoint annotations Port (P) position Starboard (S) position
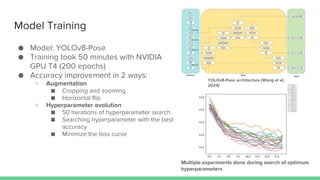
- 30. Model Training ˇń Model: YOLOv8-Pose ˇń Training took 50 minutes with NVIDIA GPU T4 (200 epochs) ˇń Accuracy improvement in 2 ways: ˇđ Augmentation ˇö Cropping and zooming ˇö Horizontal flip ˇđ Hyperparameter evolution ˇö 50 iterations of hyperparameter search ˇö Searching hyperparameter with the best accuracy ˇö Minimize the loss curve Multiple experiments done during search of optimum hyperparameters YOLOv8-Pose architecture (Wang et al, 2024)
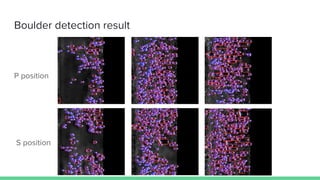
- 31. Boulder detection result P position S position
- 33. Generative adversarial networks (GAN) ˇń Generating (synthetic) image which has never exist, based on image input ˇń Pioneered by Ian Goodfellow (2014) Image to Image
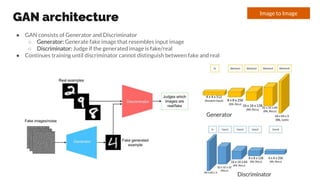
- 34. GAN architecture ˇń GAN consists of Generator and Discriminator ˇđ Generator: Generate fake image that resembles input image ˇđ Discriminator: Judge if the generated image is fake/real ˇń Continues training until discriminator cannot distinguish between fake and real Image to Image Generator Discriminator
- 35. Applications of GAN Image to Image Reconstruction of 3D model of tight sandstone (Zhao et al, 2021) Outcrop to seismic generation
- 36. Diffusion models ˇń Generating (synthetic) image from text input by human ˇń Examples: DALL-E by OpenAI, Imagen by Google Text to Image
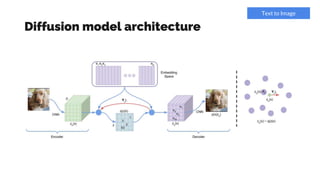
- 37. Diffusion model architecture Text to Image
- 38. Vision transformer (ViT) ˇń Generating texts or tasks based on image input by human ˇń Sample tasks: ˇđ Generating captions from image ˇđ Locate object in the photo ˇđ Question and answering based on photo Image to Text
- 39. Applications of ViT Image to Text Identifying mineral from thin section Prompt: What minerals are in this sandstone? Locating fault from seismic image Prompt: Where are the faults in this seismic image?
- 40. Challenges in computer vision My paper in SpringerˇŻs Lecture Notes on Computer Science (2024)
- 41. Image quality issues ˇńImage can suffer from quality issues, for example ˇđResolution reduction: blurred image due to camera movement or haze ˇđOcclusion: shadowed image due to object obstacles blocking the light ˇđOver-exposure: appearance looks too bright due to excessive light exposure ˇđColour constancy: false colour of image tendency towards a certain colour Shadow Overexposure Yellow constancy (Nuwara and Trinh, 2024)
- 42. Model generalization issues ˇńMost model is trained on image with ideal quality ˇńWhen tested on image with quality issues, model performance reduces ˇńModel cannot generalize on image with different quality issues Image with ideal quality Image with shadow Performance degradation (Nuwara and Trinh, 2024)
- 43. Histogram Matching ˇń Histogram matching is an algorithm to transform the image based on its histogram ˇń Steps: ˇđ Select a normal image as Reference image ˇđ Extract the histogram of Reference image ˇđ Select the image that needs to be transformed (as Source image) ˇđ Extract the histogram of Source image ˇđ Match the histogram of Source ˇú Reference ˇń Result: Improved quality and balance of lighting (Nuwara and Trinh, 2024)
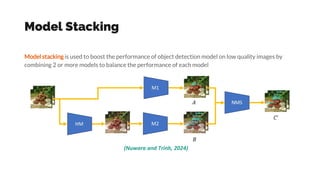
- 44. Model Stacking Model stacking is used to boost the performance of object detection model on low quality images by combining 2 or more models to balance the performance of each model (Nuwara and Trinh, 2024)
- 45. Improved result on low-quality images Shadowon object Light exposure (Nuwara and Trinh, 2024) BEFORE AFTER
- 46. Conclusion ˇń Computer vision makes huge impact in broad areas of geoscience ˇń Two use cases are presented using segmentation and object detection workflows ˇń Generative AI shape the future of AI implementation in geoscience
- 47. Thank you!