



![±æ’쌃§ÚΩBΩȧπ§Î¿Ì”…¢Ÿ
°Ò Ñ”ª≠§Œ§Ë§¶§ §Ë§Í—}Îj§ •ø•π•Ø§ÿ§ŒDeep Learning§Œþm”√§¨íà¥Û
° ≥ı∆⁄: –°§µ§§°¢∂ç§Ñ”ª≠•Ø•Í•√•◊§Œ∑÷Óê °˙åg”√µƒ§«§ §§
° ◊ÓΩ¸: ¥Û§≠§ ª≠œÒ§«Action§Œïrø’Ègµƒ§ ∂®Œª °˙åg•µ©`•”•π§«¿˚”√§«§≠§Ω§¶
°ˆ AVA Dataset: ÈL§·§ŒÑ”ª≠÷–§Œ»À§Œ Action§ÚÃÿ∂®°¢ïrø’Ègµƒ§À∂®Œª
°Ò 80∑NÓ꧌Action
°Ò 15∑÷§ŒÑ”ª≠ x 430±æ
5
°˙1.62M action labels
[Gu et al., CVPR 2018]](https://image.slidesharecdn.com/cvkantocvpr2019videoactiontransformernetwork-190706045907/85/CV-CVPR2019-Video-Action-Transformer-Network-5-320.jpg)
![±æ’쌃§ÚΩBΩȧπ§Î¿Ì”…¢⁄
°Ò NLPΩÁ⁄Ò§«§œ•π•ø•Û•¿©`•…§ Transformer§Ú§≠§¡§Û§»¿ÌΩ‚§∑§∆§™§≠§ø§§&
CV∑÷“∞§«§ŒRNN/LSTM§Œ¥˙Ãʧ»§∑§∆°¢CV∑÷“∞§«§Œþm”√∑Ω∑®§Ú÷™§Í§ø§§
° Transformer: Attention§Ú¿˚”√§∑§ø•Õ•√•»•Ô©`•Ø§«°¢ôC–µ∑≠‘U§« SOTA§Ú¥Û∑˘§À∏¸–¬
° §Ω§Œ··°¢òî°©§ NLP•ø•π•Ø§Œ•Õ•√•»•Ô©`•Ø§¨ Transformer•Ÿ©`•π§À
6Attention Is All You Need [?ukasz Kaiser et al., arXiv, 2017/06]](https://image.slidesharecdn.com/cvkantocvpr2019videoactiontransformernetwork-190706045907/85/CV-CVPR2019-Video-Action-Transformer-Network-6-320.jpg)
![œ»––—–æø: Two-Stream In?ated 3DConvNet(I3D)
°Ò Video§Œ•¢•Ø•∑•Á•Û∑÷Ó꧌§ø§·§Œ ÷∑®
°Ò Two-Stream: •’•Ï©`•ý§ŒRGB«ÈàÛ§¿§±§«§ §Ø°¢optical ?ow«ÈàÛ§‚»Î¡¶
°Ò 3D ConvNet: Æí§þÞz§þ§Úh, w∑ΩœÚ§¿§±§«§ §Ø°¢t(§‚§∑§Ø§œd)∑ΩœÚ§À§‚
°Ò In?ated: 2D§«°¢ª≠œÒ§Ú»Î¡¶§»§∑§∆—ß¡ï§∑§ø÷ÿ§þ§Ú°¢3D Conv§Œ≥ı∆⁄Ç駻§π§Î
7[Carreira & Zisserman, CVPR 2017]
H
W
T](https://image.slidesharecdn.com/cvkantocvpr2019videoactiontransformernetwork-190706045907/85/CV-CVPR2019-Video-Action-Transformer-Network-7-320.jpg)
![œ»––—–æø: I3D§Œ•¢•Ø•∑•Á•Û§Œïrø’Èg∂®Œª§ÿ§ŒèÍ”√
°Ò Ñ”ª≠•Ø•Í•√•◊§ÚÃÿè’•Þ•√•◊§Àâ‰ìQ
° •”•«•™•Ø•Í•√•◊°¢OpticalFlow§ §…»Î¡¶
° I3Dµ»—} ˝§Œ•Õ•√•»•Ô©`•Ø
°Ò RPN§Ú”√§§§∆»ÀÓI”Ú§Ú≥È≥ˆ
°Ò ≥È≥ˆ§µ§Ï§øÓI”Ú§ŒÃÿè’§Ú≥È≥ˆ
°Ò —ß¡ï•Ÿ©`•π§Œ∑÷Óê∆˜§«BBoxªÿ颰¢•Ø•È•π∑÷Óê
8
[Jiang et al., 2019]](https://image.slidesharecdn.com/cvkantocvpr2019videoactiontransformernetwork-190706045907/85/CV-CVPR2019-Video-Action-Transformer-Network-8-320.jpg)

















CV√„è䪷CVPR2019’i§þª·: Video Action Transformer Network
- 1. ’쌃ΩBΩÈ Video Action Transformer Network 2019/7/6@CV√„è䪷 æ∆æÆ°°ø°ò‰
- 2. ◊‘º∫ΩBΩÈ √˚«∞£∫æ∆æÆ°°ø°ò‰ À˘ Ù£∫NTT•…•≥•‚ À ¬£∫Deep Learning§Ú π§√§øAPI/•µ©`•”•π§Œ—–æøÈ_∞k °Ò ª≠œÒ’J◊R§ŒAPIÈ_∞k °Ò ∑®»ÀòîœÚ§±•Ω•Í•Â©`•∑•Á•ÛÃ·π© °Ò •π•ð©`•ƒÑ”ª≠Ω‚Œˆºº–gÈ_∞k ±æ∞k±Ì§œÇÄ»À§«––§¶§‚§Œ§«§¢§Í°¢À˘ ÙΩMø󧻧œÈvÇS§¢§Í§Þ§ª§Û°£ 2
- 4. ∏≈“™: Spatio-temporal Action Localization§«SOTA °Ò Spatio-temporal Action Localization(•¢•Ø•∑•Á•Û§Œïrø’Èg∂®Œª?) =•”•«•™•Ø•Í•√•◊÷–§ŒKeyFrame§À§ƒ§§§∆°¢»À§ŒÑ”◊˜§Œ’J◊R&∂®Œª§Ú––§¶ °Ò ÷∞∏ ÷∑®§«º»¥Ê ÷∑®§´§È+3.5%, +7.5%§Œæ´∂»œÚ…œ(‘uÅ˝•«©`•ø§Œþ`§§) °Ò NLP∑÷“∞§«•π•ø•Û•¿©`•…§»§ §√§øTransformer§Ú¿˚”√§∑§ø•Õ•√•»•Ô©`•Ø§Ú÷∞∏ 4
- 5. ±æ’쌃§ÚΩBΩȧπ§Î¿Ì”…¢Ÿ °Ò Ñ”ª≠§Œ§Ë§¶§ §Ë§Í—}Îj§ •ø•π•Ø§ÿ§ŒDeep Learning§Œþm”√§¨íà¥Û ° ≥ı∆⁄: –°§µ§§°¢∂ç§Ñ”ª≠•Ø•Í•√•◊§Œ∑÷Óê °˙åg”√µƒ§«§ §§ ° ◊ÓΩ¸: ¥Û§≠§ ª≠œÒ§«Action§Œïrø’Ègµƒ§ ∂®Œª °˙åg•µ©`•”•π§«¿˚”√§«§≠§Ω§¶ °ˆ AVA Dataset: ÈL§·§ŒÑ”ª≠÷–§Œ»À§Œ Action§ÚÃÿ∂®°¢ïrø’Ègµƒ§À∂®Œª °Ò 80∑NÓ꧌Action °Ò 15∑÷§ŒÑ”ª≠ x 430±æ 5 °˙1.62M action labels [Gu et al., CVPR 2018]
- 6. ±æ’쌃§ÚΩBΩȧπ§Î¿Ì”…¢⁄ °Ò NLPΩÁ⁄Ò§«§œ•π•ø•Û•¿©`•…§ Transformer§Ú§≠§¡§Û§»¿ÌΩ‚§∑§∆§™§≠§ø§§& CV∑÷“∞§«§ŒRNN/LSTM§Œ¥˙Ãʧ»§∑§∆°¢CV∑÷“∞§«§Œþm”√∑Ω∑®§Ú÷™§Í§ø§§ ° Transformer: Attention§Ú¿˚”√§∑§ø•Õ•√•»•Ô©`•Ø§«°¢ôC–µ∑≠‘U§« SOTA§Ú¥Û∑˘§À∏¸–¬ ° §Ω§Œ··°¢òî°©§ NLP•ø•π•Ø§Œ•Õ•√•»•Ô©`•Ø§¨ Transformer•Ÿ©`•π§À 6Attention Is All You Need [?ukasz Kaiser et al., arXiv, 2017/06]
- 7. œ»––—–æø: Two-Stream In?ated 3DConvNet(I3D) °Ò Video§Œ•¢•Ø•∑•Á•Û∑÷Ó꧌§ø§·§Œ ÷∑® °Ò Two-Stream: •’•Ï©`•ý§ŒRGB«ÈàÛ§¿§±§«§ §Ø°¢optical ?ow«ÈàÛ§‚»Î¡¶ °Ò 3D ConvNet: Æí§þÞz§þ§Úh, w∑ΩœÚ§¿§±§«§ §Ø°¢t(§‚§∑§Ø§œd)∑ΩœÚ§À§‚ °Ò In?ated: 2D§«°¢ª≠œÒ§Ú»Î¡¶§»§∑§∆—ß¡ï§∑§ø÷ÿ§þ§Ú°¢3D Conv§Œ≥ı∆⁄Ç駻§π§Î 7[Carreira & Zisserman, CVPR 2017] H W T
- 8. œ»––—–æø: I3D§Œ•¢•Ø•∑•Á•Û§Œïrø’Èg∂®Œª§ÿ§ŒèÍ”√ °Ò Ñ”ª≠•Ø•Í•√•◊§ÚÃÿè’•Þ•√•◊§Àâ‰ìQ ° •”•«•™•Ø•Í•√•◊°¢OpticalFlow§ §…»Î¡¶ ° I3Dµ»—} ˝§Œ•Õ•√•»•Ô©`•Ø °Ò RPN§Ú”√§§§∆»ÀÓI”Ú§Ú≥È≥ˆ °Ò ≥È≥ˆ§µ§Ï§øÓI”Ú§ŒÃÿè’§Ú≥È≥ˆ °Ò —ß¡ï•Ÿ©`•π§Œ∑÷Óê∆˜§«BBoxªÿ颰¢•Ø•È•π∑÷Óê 8 [Jiang et al., 2019]
- 9. ÷∞∏ ÷∑® °Ò Ñ”ª≠•Ø•Í•√•◊§ÚÃÿè’•Þ•√•◊§Àâ‰ìQ ° •”•«•™•Ø•Í•√•◊°¢Flow§ §…»Î¡¶•”•«•™•Ø•Í•√•◊§Œ§þ ° I3Dµ»—} ˝§Œ•Õ•√•»•Ô©`•Ø I3D§Œ§þ °Ò RPN§Ú”√§§§∆»ÀÓI”Ú§Ú≥È≥ˆ °Ò ≥È≥ˆ§µ§Ï§øÓI”Ú§ŒÃÿè’§Ú≥È≥ˆTransformer§Ú π§√§∆Ãÿè’¡øªØ °Ò —ß¡ï•Ÿ©`•π§Œ∑÷Óê∆˜§«BBoxªÿ颰¢•Ø•È•π∑÷Óê 9 •”•«•™•Ø•Í•√•◊»Î¡¶ I3D Transformer BBoxªÿé¢ •Ø•È•π∑÷Óê Region Proposal
- 11. Transformer °Ò ◊‘º∫◊¢“‚§Ú”√§§§∆°¢÷ÐÞx§Œ«ÈàÛ(Context)§Úþxíkµƒ§À¿˚”√§∑§∆¥Œ§Œå”§Œ≥ˆ¡¶§Ú”ã À„§π§Î•Õ•√•»•Ô©`•Ø 11 I like cat more than dog embed layer 1§ŒÃÿè’¡ø layer 2§ŒÃÿè’¡ø
- 12. Transformer °Ò ◊‘º∫◊¢“‚§Ú”√§§§∆°¢÷ÐÞx§Œ«ÈàÛ(Context)§Úþxíkµƒ§À¿˚”√§∑§∆¥Œ§Œå”§Œ≥ˆ¡¶§Ú”ã À„§π§Î•Õ•√•»•Ô©`•Ø 12 I like cat more than dog embed layer 1§ŒÃÿè’¡ø ≥ˆ¡¶∫Ú—a§ŒÃÿè’(value) æÄ–Œâ‰ìQ key query softmax = weight layer 2§ŒÃÿè’¡ø ÷ÿ§þ§≈§±∆Ωæ˘§Ú »°§√§ø§¶§®§«æÄ–Œâ‰ìQ æÄ–Œâ‰ìQ æÄ–Œâ‰ìQ …œ”õ§Ú¿R§Í∑µ§∑§∆§Ë§Í…Ó§Ø
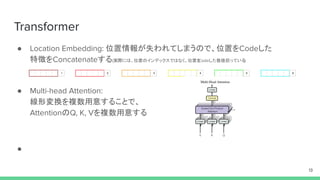
- 13. Transformer °Ò Location Embedding: Œª÷√«ÈàÛ§¨ ߧԧϧ∆§∑§Þ§¶§Œ§«°¢Œª÷√§ÚCode§∑§ø Ãÿè’§ÚConcatenate§π§Î(ågÎH§À§œ°¢Œª÷√§Œ•§•Û•«•√•Ø•π§«§œ§ §Ø°¢Œª÷√§ÚCode§∑§ø ˝Çéµ£§√§∆§§§Î) °Ò Multi-head Attention: æÄ–Œâ‰ìQ§Ú—} ˝”√“‚§π§Î§≥§»§«°¢ Attention§ŒQ, K, V§Ú—} ˝”√“‚§π§Î °Ò 13 1 2 3 4 5 6
- 14. Transformer °Ò RNN§Ë§Í§‚∏þæ´∂» °Ò «∞§Œt§Œ”ãÀ„§Ú¥˝§ø§ §§§Œ§«°¢GPU§«§Œ—ß¡ïÑø¬ §¨¡º§§ ° —ß¡ïïr ° Õ∆’ìïr§Œ•®•Û•≥©`•¿©` °Ò Convolution, RNN§Ë§Í§‚°¢§Ë§Íé⁄πݧ Context§Œ«ÈàÛ§Ú¿˚”√§π§Î§≥§»§¨§«§≠§Î 14
- 15. ÷∞∏ ÷∑®§Œ•Õ•√•»•Ô©`•Ø 15 •”•«•™ •Ø•Í•√•◊»Î¡¶ I3D Transformer(2 head x 3) BBoxªÿé¢ •Ø•È•π∑÷Óê 600x600 64 frame 3channel 25x25 16 frame 128 channel °Ò Ög’Z°˙h, w, t§«∂®¡x§µ§Ï§Î1§ƒ§Œmap…œ§Œµ„ °Ò •Ø•®•Í°˙RPN§«≥È≥ˆ§µ§Ï§øKeyFrame…œ§Œ ÓI”Ú§ŒÃÿè’ RPN§Œ≥È≥ˆÓI”Ú§Ú•Ø•®•Í§»§∑§∆°¢ïrø’Èg…œ§Œµ„§À ◊¢“‚§ÚœÚ§±°¢Ãÿè’¡ø§Ú”ãÀ„§∑§∆§§§Î Resion Proposal
- 16. ≥È≥ˆ§µ§Ï§øÓI”Ú§´§È§Œ•Ø•®•Í§Œ◊˜≥… 1. ≥È≥ˆ§µ§Ï§øÓI”Ú§œRoI•◊©`•Í•Û•∞&Max•◊©`•Í•Û•∞§«7x7x1x128§ŒÃÿè’§Àâ‰ìQ 2. 128¥Œ‘™§Œ•«©`•ø§Àâ‰ìQ °Ò HighRes: Regionƒ⁄§«§ŒÃÿè’§Œ∑÷≤º«ÈàÛ§Ú≤–§ª§Î§Ë§¶§À a. 1x1 ConvÑI¿Ì§Ú§´§±§∆7x7x128§ŒÃÿè’§ÚÀ„≥ˆ b. æÄ–Œâ‰ìQ§À§Ë§Í128¥Œ‘™§ŒÃÿè’§Àâ‰ìQ °Ò LowRes: ÖgºÉ§ •◊©`•Í•Û•∞ a. H, W∑ΩœÚ§À∆Ωæ˘§Ú»°§√§∆ 128¥Œ‘™§ŒÃÿè’§Àâ‰ìQ 16
- 18. ågÚYÃıº˛ °Ò ¬«∞—ß¡ï: I3D§Úkinetics-400•«©`•ø•ª•√•»§«—ß¡ï °Ò —ß¡ï ° Data augmentation: §¢§Í(random ?ip§»crop) ° Optimizer: SGD ° Learning Rate: 0.01-0.1(warm up) ° AVA Dataset °ˆ 80•Ø•È•π °ˆ 430 x 15min video clips °ˆ 211K training °ˆ 57K validation(•«©`•ø§¨25•µ•Û•◊•Î“‘…œ§¢§Î60•Ø•È•π§Œ§þ§Ú¿˚”√) °ˆ 117K testing 18
- 19. ΩYπ˚¢Ÿ: •Ø•È•π∑÷Óê≤ø∑÷§Œæ´∂» °Ò RPN≤ø∑÷§ÚGroundtruth§«¥˙Ãʧπ§Î§≥§»§«°¢Transformer≤ø∑÷§¿§±§ŒÑøπ˚§Úúy∂® ° GT Boxes§Ú 𧶧»°¢I3D§Ë§Í§‚Transformer§Œ∑®§¨°¢µÕFlops§«∏þæ´∂» ° GT Boxes§Ú π§Ô§ §§§»Transformer§«æ´∂»§¨œ¬§¨§Î °ˆ RPN§ŒÃ·∞∏§π§ÎRegion ˝§Ú64§»…Ÿ§ §·§À§∑§ø§≥§»§¨”∞Ìë§∑§∆§§§Î (300§À§∑§ø∞ʧœ·· ˆ) 19
- 20. ΩYπ˚¢⁄: BBox≥È≥ˆ§Œæ´∂» °Ò Action§Œ•Ø•È•π§Ú1§ƒ§À§Þ§»§·§∆‘uÅ˝ ° I3D•ÿ•√•…§Œ∑Ω§¨∏þæ´∂» ° Transformer§œ°¢•Ø•È•π∑÷ÓêÇ»§À¥Û§≠§ æ´∂»œÚ…œ§Ú§‚§ø§È§π∞Î√Ê°¢ Œª÷√§œ’˝¥_§µ§¨Ý◊…¸§À§ §ÎÉAœÚ§¨§¢§Î 20
- 21. ΩYπ˚¢€: »´þ^≥竧Œ±»ð^ °Ò RPN§«∂ý§Ø§ŒRegion§Ú≥È≥ˆ§π§Î§»Transformer§«∏þæ´∂»§À§ §Î°£ °Ò œ»––—–æø§Œ ÷∑®§»±»§Ÿ§∆§‚∏þæ´∂» 21
- 22. ◊¢“‚§Œø…“ïªØ °Ò ◊Û: Key§ŒÇ駌ø…“ïªØ(PCA§«3¥Œ‘™§À¬‰§»§π) ° »À§»§§§¶•´•∆•¥•Í§À◊≈ƒø§∑§∆§§§Î Tx§»»À§Œ•§•Û•π•ø•Û•π§À◊≈ƒø§∑§∆§§§Î Tx °Ò ”“: Attention§ŒœÚ§§§∆§§§Î≤ø∑÷§Œø…“ïªØ ° »À•™•÷•∏•ß•Ø•»§À◊¢“‚§¨œÚ§§§∆§§§Î 22
- 23. °Ò ≥ˆ¨Fªÿ ˝§Œ∂ý§§•Ø•È•π§Œ∑Ω§¨æ´∂»§¨∏þ§§ÉAœÚ§À§¢§Î§¨°¢¿˝Õ‚§‚§¢§Î °Ò ÓI”Ú§¨¥Û§≠§ Action§Œ∑Ω§¨∏þæ´∂» °Ò “ª§ƒ§Œ•Ø•Í•√•◊ƒ⁄§«°¢BBox§¨…Ÿ§ §§∑Ω§¨∏þæ´∂» 23
- 25. ∂®–‘‘uÅ˝: ßî°§∑§ø¿˝ a. À∆§øÑ”◊˜§ÚÜÀüü§»’`Õ∆∂® b. Æê§ §Î»À§À•¢•Ø•∑•Á•Û§Úº~§≈§±§Î c. §Þ§¿Ñ”◊˜§¨ º§Þ§√§∆§§§ §§/ΩK§Ô§√§∆§∑§Þ§√§ø•∑©`•Û§À•¢•Ø•∑•Á•Û§Úº~§≈§± 25
- 26. À˘∏– °Ò œ»––—–æø§Ë§Í§‚òã≥…“™Àÿ§Ú§Ë§Í•∑•Û•◊•Î§À§∑§∆æ´∂»œÚ…œ§∑§∆§§§Îµ„§¨¡º§§ °Ò Ãÿè’•Þ•√•◊…œ§Œx, y, t§«∂®¡x§µ§Ï§Îµ„§Úkey, value§»§∑§∆Attention§Ú§´§±§Îµ„§¨°¢Ñ” ª≠•«©`•ø§«§ŒTransformer§Œ π§§∑Ω§»§∑§∆≤Œøº§À§ §Î ° CV∑÷“∞§«§‚LSTMµ»§´§ÈTransformer§ÿ§Œ÷√§≠ìQ§®§¨þM§ý§´£ø °Ò Ñ”ª≠§ŒÑI¿Ì§«§œ”ãÀ„¡ø§¨’nÓ}§»§§§¶µ„§œ≤–§√§∆§§§Î °Ò 2þLÈg§€§…§«À˚§Œ•¡©`•ý§Àæ´∂»§¨§Ã§´§µ§Ï§∆§§§Î§Œ§«°¢ §Ω§¡§È§Œ•¡©`•ý§Œ ÷∑®§‚öð§À§ §Î 26