Data science inspiratie_sessie
ŌĆó
3 likesŌĆó371 views

Data Science inspiratie sessie, ludieke voorbeelden die enkele machine learning technieken illustreren. Voorspellen van huizenprijzen, soap analytics, auto's, Ikea, de nederlandse film wereld
































































































![IENS RESTAURANT VIRTUELE ITEMS: MAAK HET NOG PERSOONLIJKER
Transactie set met klanten en items
klant ITEM
1 A
1 X
2 A
2 B
2 C
3 E
3 T
4 S
Mogelijke rules
{ A, B } ŌåÆ { C }
{ X } ŌåÆ { Z }
Voeg klant kenmerken toe als virtuele items
Mogelijke rules
{ Male, (18, 25], A, B } ŌåÆ { C }
{ Female, (40,45], X } ŌåÆ { Z }
klant ITEM
1 A
1 X
1 Male
1 (18, 25]
2 A
2 B
2 C
2 Male
2 (45, 65]
3 E
3 T
3 Male
4 (30, 35]
4 S
4 Male
4 (30, 35]](https://image.slidesharecdn.com/datascienceinspiratiesessie-181102065823/85/Data-science-inspiratie_sessie-98-320.jpg)








Data science inspiratie_sessie
- 1. HUIZENPRIJZEN, SOAP, IKEA, AUTOŌĆÖS, RESTAURANTS EN DE FILMWERELD ZOMAAR WAT TOEPASSINGEN VAN MACHINE LEARNING https://longhowlam.wordpress.com @longhowlam https://www.linkedin.com/in/longhowlam Freelance data scientist: Just contact me if you need me :-) Longhow Lam
- 2. AGENDA ’āś INTRODUCTIE ’āś JAAP.NL HUIZEN ANALYTICS (REGRESSIE ANALYSE, TEXT MINING) ’āś SOAP ANALYTICS: GTST EN THE BOLD (TEXT MINING, TOPIC MODELING, WORD EMBEDDINGS) ’āś IKEA ANALYTICS (COMPUTER VISION, TIME SERIES) ’āś BMWŌĆÖS, PEUGEOTS, AUTO'S (COMPUTER VISION, SPLINE REGRESSIE ANALYSE) ’āś RESTAURANTS ANALYTICS, NEDERLANDSE FILM WERELD (ASSOCIATION RULES MINING, GRAPH ANALYSIS)
- 3. INTRODUCTIE ŌŚÅ Een overzicht van verschillende data science (machine learning) technieken ŌŚÅ Toegepast op ludieke hobby projecten ŌŚÅ Ik mag nooit data van bedrijven in het openbaar laten zien ŌåÆ Scrape data ŌŚÅ Maar alle technieken heb ik ook in ŌĆ£het echtŌĆØ toegepast ŌŚÅ Mijn data science toolset:
- 5. HUISPRIJZEN VOORSPELLEN MET DATAIKU Data van jaap.nl gescraped 130K huizen
- 8. PREDICTIVE MODEL EEN PAAR KLIKKEN EN JE BENT ER
- 9. PREDICTIVE MODEL EEN PAAR KLIKKEN EN JE BENT ER
- 10. PREDICTIVE MODEL EEN PAAR KLIKKEN EN JE BENT ER
- 11. Parameter Prijs effect (Ōé¼) Intercept 24,006 Eerste 2 cijfers postcode 10 240,839 96 ŌłÆ 103,000 12 204,591 79 ŌłÆ 49,002 ŌĆ”... ŌĆ”... Type huis Villa 173,000 Tussen woning ŌłÆ 41,000 vrijstaand 73,000 ŌĆ”. ŌĆ”. Oppervlakte per m2 2,064 Aantal Kamers elke extra kamer 4,500 LINEAIRE REGRESSIE Simpel model maar niet meest accuraat model
- 12. PREDICTIVE MODEL RESULTATEN VOOR ANDERE MODEL TYPES Variable importance plot
- 13. PREDICTIVE MODEL RESULTATEN VOOR ANDERE MODEL TYPES Decision trees
- 14. PREDICTIVE MODEL RESULTATEN VOOR ANDERE MODEL TYPES Voorspelling versus waargenomen prijs
- 15. K Nearest Neighbor regressie
- 16. K-NEAREST NEIGHBOR METHODE Ō£ö Is geen echt model eigenlijk. Ō£ö Gegeven een huis x0 , Ō£ö Vind de k huizen x1, x2,..., xk die het dichts bij x0 liggen Ō£ö Voorspel voor huis x0 de prijs als gemiddelde van de k huizen x0 5 nearest neighbors van x0
- 17. K-NN METHOD, WELKE K NEEM JE 1 nearest neighbor 15 nearest neighbor
- 18. K-NN METHOD Gebruik verschillende K en bekijk fout die je op een test set maakt Ondanks zijn eenvoud is, k-nearest-neighbors succevol toegpast in problems zoals: ŌĆó Recognizing handwritten digits, ŌĆó Analyzing satellite image scenes ŌĆó Discovering EKG patterns
- 19. K-NN VOORBEELD Neem de locatie (long/lat co├Črdinaten van een huis) Bekijk huizen in de buurt JAAP HUIZEN Voor elk huis waarvan je de prijs (nog) niet weet kan je nu de k-nn voorspeller uitrekenen
- 20. K-NN VOORBEELD JAAP HUIZEN Voor mijn huizen in JAAP set blijkt k = 5, de beste waarde te zijn Grootste R2 op de test set
- 22. Model deployment
- 23. OK EN NU? WIE WIL MIJN MODEL GEBRUIKEN? Je kan mij je droomhuis mailen met de huiskenmerken en ik reken een huisprijs uit. Elke applicatie die een huisprijs voorspelling nodig heeft Liever niet ! Maak een REST API van het model en zet hem op een server online Dataiku stroomlijnt het proces van model deployment
- 24. OK EN NU? WIE WIL MIJN MODEL GEBRUIKEN? curl -X POST http://188.166.112.55:12000/public/api/v1/house_xgboost/pc2model/predict --data '{ "features" : { "HouseType": "Tussenwoning", "kamers": 6, "Oppervlakte": 134, "VON": 0, "PC": "16" }}' {"prediction":241287.40,"ignored":false} Voor PC: "10" {"prediction":607246.62,"ignored":false}
- 25. Text mining
- 26. https://github.com/longhowlam/jaap https://www.linkedin.com/pulse/huis-te-koop-zet-beleggingsobject-je-huisomschrijving-longhow-lam/ HUISPRIJZEN VOORSPELLEN OP BASIS VAN OMSCHRIJVINGEN
- 27. HUISPRIJS VOORSPELLEN MET LASSO REGRESSIE OF XGBOOST TERM DOCUMENT MATRIX Super sparse: 65.000 rijen en 50.000 kolommen maar heeeeeeel veeeeeeel nullen! huis vraagprijs aanrecht grote_tuin garage ..(heel veel meer termen).. zwembad Huis 1 235.000 1 0 1 ... 0 Huis 2 450.000 0 1 0 ... 0 Huis 3 376.000 1 0 0 ... 0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... Huis 65.000 621.000 1 1 ... ... 1 DUS: Elke huisbeschrijving is nu een lange vector van 50.000 getallen We spreken over een punt in de 50.000 dimensionale ruimte! ŌäØ 50000
- 28. TERM DOCUMENT MATRIX Voor elke term (kolom) proberen we een ╬▓ (beta) parameter te schatten Te veel kolommen voor normale lineaire regressie, regularization is nodig! Bijvoorbeeld: ŌĆ£lassoŌĆØ regression HUISPRIJS VOORSPELLEN MET LASSO REGRESSIE OF XGBOOST
- 29. MANAGED NOTEBOOKS ENVIRONMENT FOR MORE ADVANCED CODE ANALYSIS
- 30. R TEXT2VEC PACKAGE MIJN FAVORIETE PACKAGE VOOR SIMPELE TEXT MINING
- 31. LASSO REGRESSION NEGATIEVE EN POSITIEVE BETA PARAMETERS R2 = 0.66 Intercept Ōé¼ 238.260 parkkosten Ōé¼ 39.644- familiehuis Ōé¼ 60.168 recreatiebungalow Ōé¼ 32.614- vrijstaande_villa Ōé¼ 48.180 bungalowpark Ōé¼ 31.801- belegging Ōé¼ 45.814 limburgse Ōé¼ 23.483- beleggingsobject Ōé¼ 42.543 2_kamer Ōé¼ 23.034- entree_vestibule Ōé¼ 41.674 plinten Ōé¼ 22.510- rijksmonument Ōé¼ 39.379 overdekt_zwembad Ōé¼ 21.971- recreatief Ōé¼ 39.142 2_kamerappartement Ōé¼ 20.625- verhuurd Ōé¼ 36.171 aannemer Ōé¼ 20.314- detaillering Ōé¼ 35.000 recreatiewoning Ōé¼ 19.748- visgraat Ōé¼ 33.589 proeven Ōé¼ 19.631- eigen_badkamer Ōé¼ 33.454 betaalbaar Ōé¼ 19.621- woningen_1 Ōé¼ 33.321 starterswoning Ōé¼ 19.502- toiletten Ōé¼ 32.836 volwassen Ōé¼ 19.476- rietgedekte Ōé¼ 32.096 kunststofkozijnen Ōé¼ 18.775- representatieve Ōé¼ 31.904 helder Ōé¼ 18.594- alarm Ōé¼ 31.841 verbeterd Ōé¼ 18.488- toplocatie Ōé¼ 31.821 eigen_gebruik Ōé¼ 18.430- gezinshuis Ōé¼ 31.297
- 32. XGBOOST BETERE VOORSPELBAARHEID! XGBOOST wordt een black box model, Maar uitlegbaarheid is te doen via LIME Local Interpretable Model agnostic Explanations Fit lokaal een lineair regressie model!
- 34. ANALYTICS SOAP
- 35. SOAP ANALYTICS TEXT ANALYTICS Business pain Kijkend naar GTST waar gaat dit allemaal over? Zijn er trends in de serie? Is het niet alemaal hetzelfde? Aanpak Neem 5000 samenvattingen en pas text mining topics toe
- 36. SOAP ANALYTICS TOPICS VINDEN De 5000 samenvattingen zijn weer in een Term Document Matrix te zetten Elke samenvatting is weer een punt in de 50.000 dimensionale ruimte: In plaats van voorspellen, kunnen we nu clusteren of ook wel TOPICS ŌĆśuitrekenenŌĆÖ ŌäØ 50000
- 37. Alle samenvatting op elkaar Cluster algoritme Topic 1 Beschreven door sleutelwoorden Topic 3 Beschreven door sleutelwoorden Topic 2 Beschreven door sleutelwoorden Topic 4 Beschreven door sleutelwoorden
- 38. SOAP ANALYTICS MAIN TOPICS Main topics in 5000 episodes
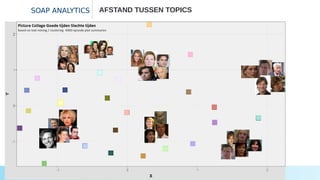
- 39. SOAP ANALYTICS AFSTAND TUSSEN TOPICS
- 40. SOAP ANALYTICS IN ZOOMEN OP EEN TOPIC
- 41. SOAP ANALYTICS INZOMEN OP EEN TOPIC Sub-topics: topic 16 (Ludo, Isabelle, Martine, Janine) ’éĘ Harmsen voelt zich alleen. ’éĘ Plan van Jack, gevaarlijk ’éĘ Afscheidsbrief schrijven ’éĘ Paniek, angst ’éĘ Vragen over kinderen ’éĘ Geld betalen Geld terug krijgen
- 42. SOAP┬ĀANALYTICS TRENDS OVER TIME
- 43. ┬ĀSOAP ANALYTICS ZIJN ALLE AFLEVERINGEN NIET GEWOON HET ZELFDE? Een 3D UMAP Uniform Manifold Approximation and Projection van alle 5000 GTST episodes Elke GTST aflvering is een hoog dimensionale vector die je naar een lagere dimensie kan projecteren Zo kan je makkelijk zien of afleveringen dicht bij elkaar liggen
- 45. WORD EMBEDDINGS IN BOLD & BEAUTIFUL SAMENVATTINGEN Term Document Matrix Elk document / samenvatting is een vector van getallen Word embedding Elk word is een vector van getallen Een word embedding moet getrained worden met een collectie van documenten / samenvattingen Amsterdam = (0.83, 0.89, 0.34, ŌĆ” , 0.63, 0.19) Steffy = (0.33, 0.19, 0.79, ŌĆ” , 0.13, 0.01) Germany = (0.72, 0.65, 0.43, ŌĆ” , 0.36, 0.57) Laugh = (0.85, 0.77, 0.24, ŌĆ” , 0.88, 0.29) ŌĆ” ŌĆ” https://github.com/longhowlam/TBATB
- 46. WORD EMBEDDINGS LINGUISTIC REGULARITIES Closest words Word relations 250 dimensional space president trump car media press house man woman king queen vector(ŌĆ£man") ŌłÆ vector(ŌĆ£woman") is roughly vector(ŌĆ£kingŌĆØ) ŌłÆ vector(ŌĆ£queen") Trump speaks with the press The president talks to the media
- 47. WORD EMBEDDINGS BOLD & BEAUTIFUL VOORBEELD 4000 dagelijkse samenvattingen gescraped van de laatste 15 jaar. We hebben ruim 10.000 unieke woorden in deze samenvattingen.
- 48. WORD EMBEDDINGS BOLD & BEAUTIFUL VOORBEELD Ik maak van elk woord een 250 dimensionale vector (kost 1 uur rekentijdŌĆ”)
- 49. WORD EMBEDDINGS BOLD & BEAUTIFUL VOORBEELD 1 steffy steffy 1.00 2 steffy liam 0.82 3 steffy hope 0.79 4 steffy said 0.78 5 steffy wyatt 0.76 6 steffy bill 0.69 7 steffy asked 0.68 8 steffy quinn 0.67 9 steffy agreed 0.65 10 steffy rick 0.65
- 50. WORD EMBEDDINGS BOLD & BEAUTIFUL VOORBEELD death furious lastly excused frustration onset 0.223 0.2006 0.1963 0.1958 0.1950 0.1937 Word vectors voor: Steffy ŌłÆ Liam
- 51. WORD EMBEDDINGS BOLD & BEAUTIFUL VOORBEELD liam katie wyatt steffy quinn said 0.5550 0.4845 0.4829 0.4645 0.4491 0.4201 Word vectors voor: Bill ŌłÆ anger
- 52. BELANGRIJK: Business validation! IK heb mijn vrouw gevraagd, een trouwe GTST en TBTB kijker Ze herkent zich helemaal in mijn analyses!
- 53. Kunnen jullie de hand schudden van je twee buren? EEN STATISTISCH EXPERIMENTJE DOEN Twee statistieken die ik met jullie wil delen:
- 54. 50.1% van de mensen wast hun handen niet na een toilet bezoek EEN STATISTISCH EXPERIMENTJE DOEN
- 55. 84.6% van alle statistieken worden ter plekke verzonnen!! EEN STATISTISCH EXPERIMENTJE DOEN
- 56. analytics
- 57. THE BILLY INDEX
- 58. IKEA WEBSITE HOUD DE BILLY VOORRAAD BIJ De IKEA Billy Index Verandering van de voorraad over tijd
- 59. IKEA ANALYTICS THE IKEA BILLY INDEX
- 60. IKEA WEBSITE Start van nieuwe jaar THE IKEA BILLY INDEX
- 61. IKEA WEBSITE Zomer gevolgd door nieuw schooljaar THE IKEA BILLY INDEX
- 62. IKEA BILLY VERKOOP FORECASTEN IN DE TOEKOMST Forecast model y(t) = g(t) + s(t) + h(t) + e(t) g trend term s seasonality terms h holiday en events e error term
- 63. IKEA BILLY VERKOOP FORECASTEN IN DE TOEKOMST
- 64. IKEA BILLY VERKOOP FORECASTEN IN DE TOEKOMST
- 65. IKEA BILLY INDIVIDUELE COMPONENTEN
- 66. THE BILLY INDEX CORRELATIES MET WAT ŌĆśWEERŌĆÖ VARIABELEN
- 67. THE BILLY INDEX CORRELATIES MET WAT ŌĆśWEERŌĆÖ VARIABELEN
- 68. Elke 1 m/s toename in windsnelheid resulteert in 19 minder BillyŌĆÖs verkocht :-)
- 70. DEEP LEARNING PRE-TRAINED NETWORKS Deep learning: neurale netwerken met veel hidden layers De zogenaamde deep convolutional netwerken zijn heel toepasbaar voor plaatjes Classificatie VGG16 netwerk bevat miljoenen parameters, en is al getraind op miljoenen gelabelde plaatjes met veel rekenkracht. 1. Dog 2. Cat 3. Car 4. House 5. Plane 6. tree ŌĆ” ŌĆ” ŌĆ” 999. Castle 1000. chair We gaan dit gewoon hergebruiken!!
- 71. DEEP LEARNING PRE-TRAINED NETWORKS 25.008 dimensional space
- 72. IKEA PRODUCT IMAGES HACKATON BIJ IKEA DECEMBER 2017 ŌĆó Scrape 9000 product plaatjes van de Ikea website ŌĆó Score elk plaatje met het pre-trained VGG netwerk ŌĆó Maak een R shiny app om een plaatje te uploaden ŌĆó Bepaal welke Ikea plaatjes dicht bij jouw plaatje zijn
- 76. IMAGE CLASSIFIER Maak zelf een Peugeot / BMW classifier model 1) Download 150 BMW plaatjes 2) Download 150 Peugeot plaatjes 3) Pak een bestaand pre-trained netwerk 4) train een nieuwe top laag Flatten 8192 Dense 256 PEUGEOT BMW
- 77. IMAGE CLASSIFIER Maak zelf een model
- 78. IMAGE CLASSIFIER Maak zelf een model Na een uur trainen op mijn laptop wordt een accuracy van ~80% gehaald op nieuw test plaatjes. Niet super goed, mijn zoon doet het beter!
- 79. IMAGE CLASSIFIER Laat Google AutoML Vision het maar doen!
- 80. IMAGE CLASSIFIER Laat Google AutoML Vision het maar doen!
- 81. IMAGE CLASSIFIER Voordelen Google AutoML Vision ŌŚÅ Geen enkele code vereist ŌŚÅ Alleen gelabelde plaatjes uploaden ŌŚÅ Veel sneller, traint in de Google cloud ŌŚÅ Veel accurater, jaren Google research onder de motorkap ŌŚÅ Model staat klaar voor ŌĆśiedereenŌĆÖ om te gebruiken!
- 82. WAT KOST EEN AUTO Per kilometer rijden? www.gaspedaal.nl: 435.000 autoŌĆÖs Vraagprijs en KM stand per Merk en Model
- 83. NIET LINEAIR RELATIE Splines kunnen je helpen! Splines fit: Stuksgewijze polynomen die ŌĆ£gladŌĆØ aan elkaar geplakt zijn Continue afgeleide!! P P PP KM KM KM KM Gewone lineaire fit Simple: helling is prijs per KM Maar is niet accuraat Step-wise fit: Sprongen Piecewise lineair fit: Sprongen in afgeleide
- 84. WAT KOST EEN AUTO Per kilometer rijden? Renault CLIO Aantal KM gereden 0 50K 100K 200K150K 250K VraagPrijs Aardig verschil in nieuw waarde
- 85. WAT KOST EEN AUTO Per kilometer rijden? Renault CLIO Aantal KM gereden CentperKM
- 86. WAT KOST EEN AUTO Per kilometer rijden? BMW 3-SerieVraagPrijs Aantal KM gereden 0 50K 100K 200K150K 300K250K
- 87. WAT KOST EEN AUTO Per kilometer rijden? BMW 3-Serie Klein web appje in R Shiny voor andere merken: Have fun CentperKM Aantal KM gereden
- 88. WELKE AUTO Gaat het meeste olie lekken? RDW stelt open data beschikbaar: ŌŚÅ 9 mln. autoŌĆÖs met kenmerken op kenteken ŌŚÅ 21 mln. APK meldingen op kenteken datum gebrek auto merk ouderdom 13-04-17 Olie lek 1-abc-12 Peugeot 12 19-05-18 Rem 2-xyz-32 Opel 9 23-02-17 Verlichting 3-klm-34 Kia 7 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 03-10-17 Versnelling 5-qwe-45 BMW 8 Makkelijk af te leiden: Hoeveel autoŌĆÖs van merk ABC zijn er van ouderdom X Hoeveel autoŌĆÖs van merk ABC zijn er van ouderdom X en met een olie lekkage
- 91. IENS RESTAURANT PATH ANALYTICS Business pain Ik heb Chinees gegeten, OK leuk! Maar waar moet ik de volgende keer heen? Aanpak Kijk naar wat anderen hebben gedaan. Op basis van IENS restaurant reviewers!
- 92. A FEW FACTSŌĆ” IENS DATA (TRADITIONELE BI) Meest voorkomende restaurant naam (39 times) Onder Nederlandse restaurants (6 keer) % Sustainable kitchens Biological (67%) French (58%) Fish (44%) Vegetarian (39%) ŌĆ” ŌĆ” ŌĆ” Chinese (3%) 700 reviews op een ŌĆ£normaleŌĆØ zaterdag Valentijn 2015 had 1200 reviews (1.7 times) 23 keer 12 keer
- 93. ASSOCIATION RULES MINING OOK WEL MARKET BASKET ANALYSIS GENOEMD Identificeer frequent item sets (rules) in transactie data: ALS items A and B DAN item C {A, B} ŌåÆ {C} ALS items X DAN item Y and Z {X} ŌåÆ {Y, Z} Wanneer is een rule frequent? Als de ŌĆśsupportŌĆÖ > een drempel # trxs. {X ŌåÆ Y} Total # trxs. Support {X ŌåÆ Y} = Support Chips ŌĆō> Bier 0.823% Chips ŌĆō> Dreft 0.002%
- 94. Lift {X ŌåÆ Y} = Support {X ŌåÆ Y} Support (X) * Support(Y) Lift & Confidence Bijvoorbeeld: Een lift van 8 voor {Chips} ŌåÆ {Bier} betekend Als ik weet dat iemand Chips al heeft gekocht dan is het 8 keer waarschijnlijker dat hij ook Bier gaat kopen. Andere statistics die een rule kunnen ŌĆśbeoordelenŌĆÖ Conf {X ŌåÆ Y} = Support {XŌåÆ Y} Support (X) ASSOCIATION RULES MINING OOK WEL MARKET BASKET ANALYSIS GENOEMD
- 95. IENS RESTAURANT ASSOCIATION RULES MINING / MARKET BASKET ANALYSE
- 96. IENS RESTAURANT LENGTE TWEE RULES AŌåÆ B Interactieve netwerk Wat generieke rules Lift is nog niet super hoog
- 97. IENS RESTAURANT LENGTE DRIE RULES A, BŌåÆ C Interactief plaatje Specifiekere rules, maar veel hogere lift
- 98. IENS RESTAURANT VIRTUELE ITEMS: MAAK HET NOG PERSOONLIJKER Transactie set met klanten en items klant ITEM 1 A 1 X 2 A 2 B 2 C 3 E 3 T 4 S Mogelijke rules { A, B } ŌåÆ { C } { X } ŌåÆ { Z } Voeg klant kenmerken toe als virtuele items Mogelijke rules { Male, (18, 25], A, B } ŌåÆ { C } { Female, (40,45], X } ŌåÆ { Z } klant ITEM 1 A 1 X 1 Male 1 (18, 25] 2 A 2 B 2 C 2 Male 2 (45, 65] 3 E 3 T 3 Male 4 (30, 35] 4 S 4 Male 4 (30, 35]
- 99. De Nederlandse film wereld in een graph
- 100. GRAPH BASICS Node of Vertex een knooppunt in het netwerk Edge of Link een relatie tussen twee nodes (kan directional zijn) EEN PAAR TERMEN A B C D E F G
- 101. GRAPH BASICS Node Centraliteit Hoe centraal is een node * Degree (aantal connecties) * Betweenness (aantal kortste paden door een node) * Eigencentrality (GoogleŌĆÖs page rank is een variant hiervan) Community detection Zijn er nodes die meer bij elkaar horen dan anderen? EEN PAAR TERMEN 5 6 7 4 3 2 1 8 9 10 1112 Degree 5 Degree 6 Degree 2 3a Degree 2 Node 6 en 3 hebben een zelfde Degree, Maar node 6 heeft een hogere Betweennes dan node 3
- 102. WWW.IMDB.COM INTERNET MOVIE DATABSE Download film data: * Nederlandse films afgelopen 25 jaar * Per film weten we de spelers en crew * Een node is een persoon * Node X linkt met node Y als X en Y in dezelfde film hebben gewerkt
- 103. NEDERLANDSE FILM WERELD IN EEN GRAPH Interactive graph
- 104. CENTRALITEIT
- 105. COMMUNITIES Er zijn 1257 personen Zijn ingedeeld in 191 community's Neem community 6: 54 personen in een wordcloud (Centrality based)
- 106. Bedankt voor jullie aandacht! VRAGEN? Als Freelancer data scientist sta ik open om eens een kop koffie te drinken https://www.linkedin.com/in/longhowlam https://longhowlam.wordpress.com/ @longhowlam